







使用smo算法实现svm
以下代码涉及到的公式推导参照于以下两篇文章,数学推导的部分写的非常好!(如果不了解数学推导过程,代码中的一些部分很可能看不懂)
http://www.thebigdata.cn/JieJueFangAn/12661.html
http://www.wengweitao.com/zhi-chi-xiang-liang-ji-smoxu-lie-zui-xiao-zui-you-hua-suan-fa.html#fnref:calculate
对svm的简要理解可以参见我之前写的http://blog.csdn.net/xiaonannanxn/article/details/52352207
首先我们建立一个SVM.py
# coding:utf-8
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(filename):
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
def selectJrand(i, m):
j = i
while j == i:
j = int(random.uniform(0, m))
return j
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if aj < L:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
b = 0
m, n = dataMatrix.shape
alphas = mat(zeros((m, 1)))
Iter = 0
while Iter < maxIter:
alphaPairsChanged = 0
for i in xrange(m):
# y = wx + b, w = ∑αyx
fXi = float(multiply(alphas, labelMat).T * dataMatrix * dataMatrix[i, :].T) + b
Ei = fXi - float(labelMat[i])
# if α needs to be adjusted or it does not satisfy the ktt
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i, m)
fXj = float(multiply(alphas, labelMat).T * dataMatrix * dataMatrix[j, :].T) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
if labelMat[i] != labelMat[j]:
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print "L == H"
continue
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T \
- dataMatrix[i, :] * dataMatrix[i, :].T \
- dataMatrix[j, :] * dataMatrix[j, :].T
if eta >= 0:
print "eta >= 0"
continue
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
alphas[j] = clipAlpha(alphas[j], H, L)
if abs(alphas[j] - alphaJold) < 0.00001:
print "j not moving enough"
continue
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
b1 = b - Ei \
- labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T \
- labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[i, :].T
b2 = b - Ej \
- labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T \
- labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
if 0 < alphas[i] < C:
b = b1
elif 0 < alphas[j] < C:
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (Iter, i, alphaPairsChanged)
if alphaPairsChanged == 0:
Iter += 1
else:
Iter = 0
print "iteration number: %d" % Iter
return b, alphas
def show(dataArr, labelArr, alphas, b):
for i in xrange(len(labelArr)):
if labelArr[i] == -1:
plt.plot(dataArr[i][0], dataArr[i][1], 'or')
elif labelArr[i] == 1:
plt.plot(dataArr[i][0], dataArr[i][1], 'Dg')
# print alphas.shape, mat(labelArr).shape, multiply(alphas, mat(labelArr)).shape
c = sum(multiply(multiply(alphas.T, mat(labelArr)), mat(dataArr).T), axis=1)
minY = min(m[1] for m in dataArr)
maxY = max(m[1] for m in dataArr)
print minY, maxY
plt.plot([sum((- b - c[1] * minY) / c[0]), sum((- b - c[1] * maxY) / c[0])], [minY, maxY])
plt.plot([sum((- b + 1 - c[1] * minY) / c[0]), sum((- b + 1 - c[1] * maxY) / c[0])], [minY, maxY])
plt.plot([sum((- b - 1 - c[1] * minY) / c[0]), sum((- b - 1 - c[1] * maxY) / c[0])], [minY, maxY])
plt.show()以及一个main.py用来测试程序
import SVM
from numpy import *
dataArr, labelArr = SVM.loadDataSet('testSet.txt')
b, alphas = SVM.smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
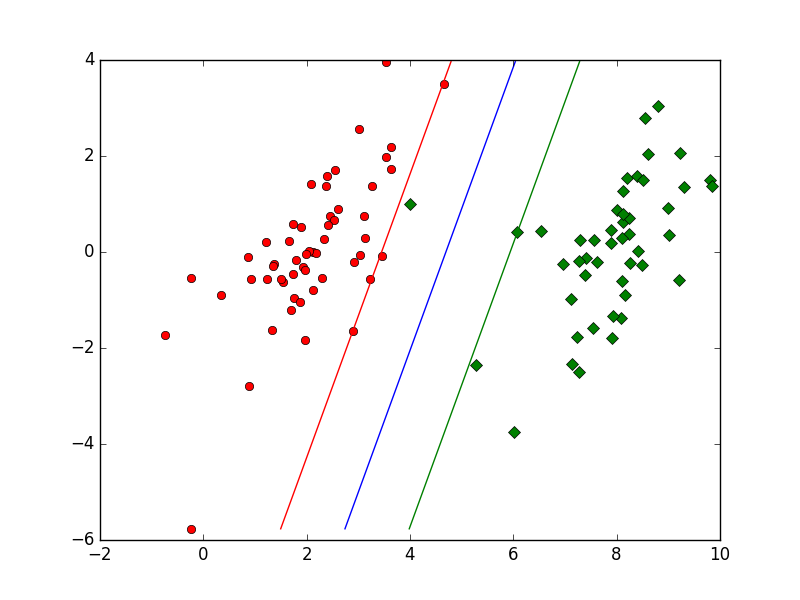
SVM.show(dataArr, labelArr, alphas, b)最后可以得到svm的分类结果
我特意增加几个离群的点,以显示出松弛变量对整个分类的影响
蓝线即为分割的超平面,绿线和红线上的点即我们所说的“支持向量”,绿线红线之间的点为离群的点
训练的数据见
http://download.csdn.net/detail/xiaonannanxn/9618859
这次的代码实现了最基本的smo算法,选择αi和αj时分别遍历和随机选择,但是训练100个数据需要14s左右,在增大数据集后这种方法会变得很慢,接下来我会再实现一个优化的smo的算法,并加入核函数














 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









