






前言
如果你刚开始接触这个强大的 AI 应用开发平台,那么“知识库”功能绝对是你需要首先了解和掌握的核心特性之一。简单来说,知识库就像是给你的 AI 应用外挂了一个专属的、可以随时更新的“大脑”或“资料库”。下面,让我们一起详细探索它是什么、为什么重要以及如何使用。
(文章出自微信公众号:dify实验室)
一、 什么是 Dify 知识库?它解决了什么问题?
想象一下,通用的大语言模型(比如 DeepSeek 背后的模型)就像一个学识渊博但知识截止于某个时间点的学者。他们知道很多事情,但可能不知道你公司最新的产品规格,也不了解你团队内部的特定流程。
这就是 Dify 知识库发挥作用的地方。
- 核心概念:
Dify 知识库是一个让你能够上传、管理和组织你自己的信息(文档、数据、网页内容等)的地方。这些信息将被结构化处理,以便 AI 能够理解和检索。
- 可视化管理:
Dify 提供了一个非常友好的界面,让你能直观地看到知识库的构建过程(背后其实是复杂的 RAG 技术,但你无需深入了解技术细节就能使用),轻松管理你的知识资产。
- 解决的问题:
- 信息滞后:
AI 大模型的知识是静态的,无法获取最新信息。知识库允许你随时添加、更新内容,确保 AI 回答基于最新情况。
- 缺乏个性化/领域知识:
通用模型不了解你公司或特定领域的细节。知识库让你能“喂”给 AI 这些专属知识。
- AI “幻觉”:
有时 AI 会“编造”事实,尤其是在信息不足时。通过知识库提供准确依据,可以大大减少这种情况,让回答更可靠。
- 信息滞后:
二、 知识库是如何工作的?
当你向集成了知识库的 Dify 应用提问时,过程大致是这样的:
- 用户提问:
你向 AI 应用提出问题。
- 知识库检索:
Dify 不会立刻让大模型直接回答。它会先分析你的问题,提取关键词,然后在你配置的知识库里搜索相关内容。
- 筛选与排序:
知识库会找到与关键词最匹配的一些信息片段(称为“内容区块”或“Chunks”),并按相关度排序。
- 提供上下文:
Dify 将这些最相关的信息片段作为“背景资料”或“上下文”提供给大语言模型。
- 精准回答:
大语言模型结合你提供的问题和知识库里的精确上下文,生成一个更加准确、相关、且基于事实的回答。
简单比喻: 就像你问一个历史学家问题,他不仅凭记忆回答,还会先去书架(知识库)上查阅最相关的几本书(内容区块),然后结合书里的信息给你一个更详尽、准确的答案。

三、 知识库的核心优势
- 实时性 :
你的数据可以随时更新,知识库内容变了,AI 的回答依据也会立刻改变。
- 精准性:
基于你上传的真实文档进行回答,大大减少 AI “瞎猜”或“编造”的可能性,提升回答质量。
- 灵活性 :
你可以完全自定义知识库的内容,决定 AI 需要了解哪些信息,覆盖哪些范围。
四、 如何开始使用知识库?
-
准备你的“知识”:
- 文本文件:
最常见的形式,可以是
.txt,.md(Markdown),.docx(Word),.html,.json, 甚至.pdf文件。内容可以是长篇文章、FAQ 列表、产品手册等。 - 结构化数据:
如
.csv,.xlsx(Excel) 文件,适合表格类数据。 - 在线数据:
Dify 也支持直接从网页(通过爬虫功能)或 Notion 等在线服务导入数据。
- 文本文件:
-
上传与处理:
-
在 Dify 平台中找到“知识库”部分。
-
点击“创建知识库”,给它起个名字。
-
将你准备好的文件直接上传。Dify 会自动进行数据清洗、分段、向量化等处理(这些复杂的步骤 Dify 都帮你简化了,你只需上传即可)。
-
-
(可选)连接外部知识库:
-
如果你的团队已经有了自己的数据库或知识管理系统(比如内部 Wiki、数据库等),并且不希望重复上传,Dify 提供了“连接外部知识库”的功能。通过配置,你的 Dify 应用可以直接查询这些外部数据源,无需将数据本体导入 Dify。
五、建议的知识库配置策略
-
万能的最佳配置,需要根据你的具体应用场景、数据特点和性能要求来调整。以下是一些常见的场景和建议:
1. 场景:构建精准问答的 AI 客服/文档助手目标:
对用户具体问题给出精确、基于文档的回答。
数据准备:优先使用结构清晰的 FAQ 文档、产品手册(如果是 PDF,确保是文本可选的)、Markdown 文件。尽量保证文本质量高,无冗余信息。
配置建议:
分段:采用较小的分段长度(如 300-500 字符/Token)和适中的重叠(如 50-100 字符/Token)。目的是让每个分段聚焦于一个具体的问题或知识点。如果文档结构本身很好(如问答对),自动模式可能也足够。
嵌入模型:选择高质量的嵌入模型,确保语义理解准确。(知道你心疼token,文末提供免费embedding模型token资源)
索引模式:高质量模式,确保信息提取完整。
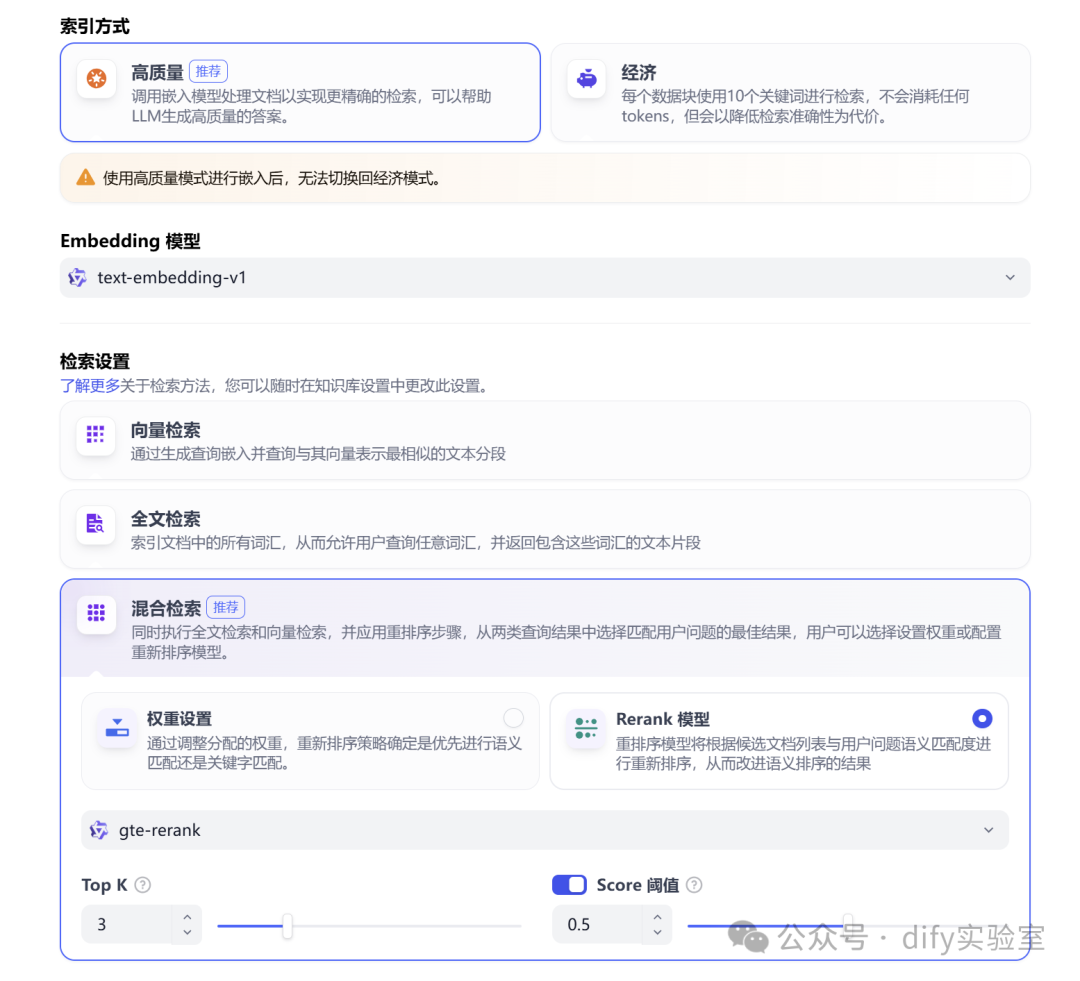
检索设置。Top K :设置较小的值(如 2-4),避免引入过多不相关信息干扰 LLM。Score阈值:设置较高的值(如 0.5 或更高,需要测试调整),过滤掉低相关度的内容。Rerank:强烈建议开启,可以显著提升最终召回内容的精准度。
2. 场景:对长文档进行摘要、分析或进行开放式对话
理解文档的整体或大段内容,进行总结或基于广泛上下文的讨论。
数据准备:长篇报告、文章、书籍章节等。
配置建议:
分段:采用较大的分段长度(如 800-1500 字符/Token)和较大的重叠(如 150-300 字符/Token)。目的是在每个分段中保留更完整的上下文。
嵌入模型: 依然推荐高质量模型,但如果文档量巨大且成本敏感,可以考虑性价比更高的选项。(知道你心疼token,文末提供免费embedding模型token资源)
索引模式:高质量模式。
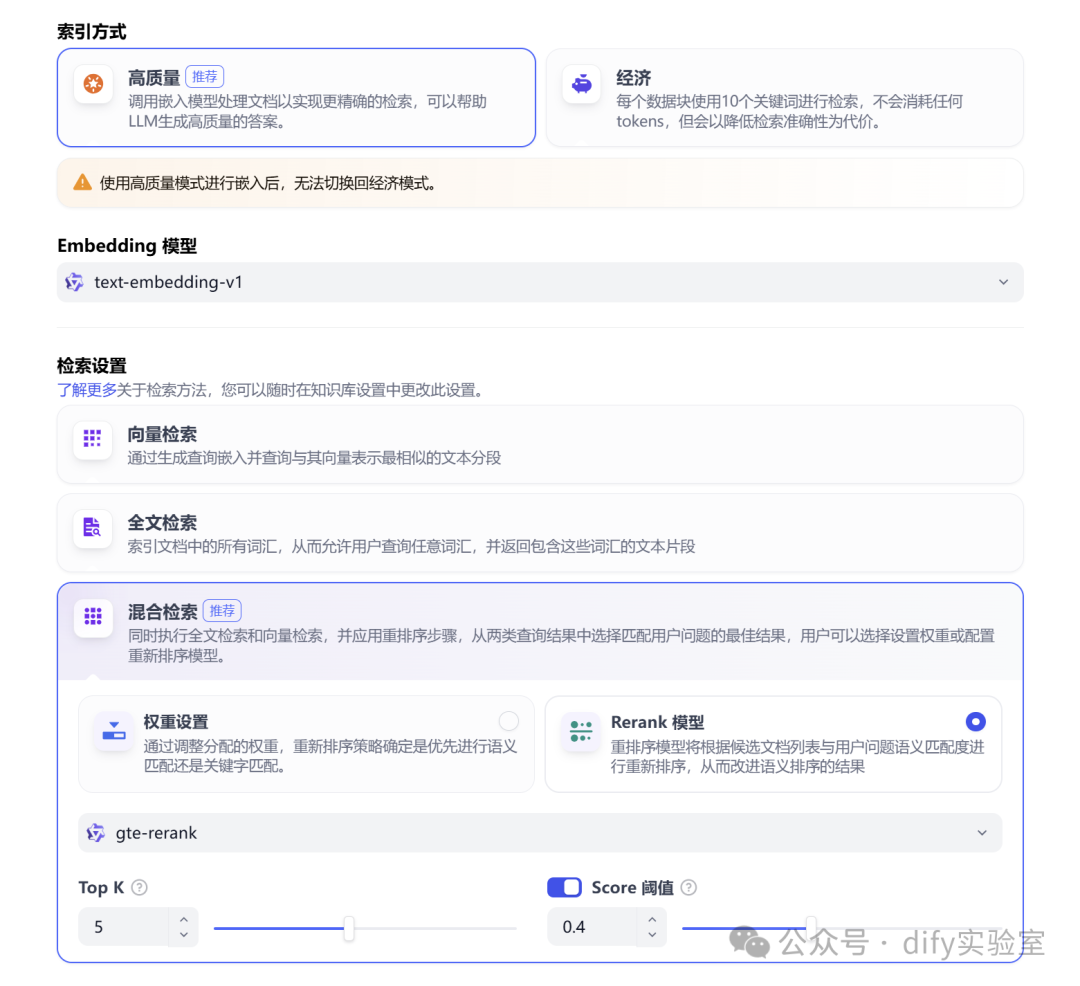
检索设置。Top K:设置较大的值(如 5-10),以便 LLM 能接触到更广泛的相关信息。Score阈值:可以设置稍低的值(如 0.3-0.5),允许更多潜在相关的上下文进入。Rerank:依然推荐开启,帮助从较多的候选项中筛选出最精华的部分。
六、 一个典型的应用场景:AI 客服助手
假设你想为你的产品创建一个 AI 客服,能够回答用户的常见问题和使用指南。
- 传统方式:
可能需要收集数据、训练模型、开发接口,耗时数周甚至更长,后续维护更新也很麻烦。
- 使用 Dify 知识库:
可能只需几分钟,你就拥有了一个基于你产品资料的 AI 客服雏形,可以立即开始测试和收集反馈了。
-
将你的产品文档、FAQ 列表、用户手册等上传到 Dify 的一个新建知识库中。
-
创建一个“对话型应用”。
-
在该应用的“上下文”设置中,选择你刚刚创建的知识库。
-
(可选)调整提示词(Prompt),引导 AI 更好地扮演客服角色。
-
参照案例:20分钟从零到一构建Dify智能客服工作流教程(附DSL文件下载)
总结
Dify 的知识库功能是其强大能力的基石之一。它让开发者和运营人员能够轻松地将特定、实时、准确的信息注入到 AI 应用中,极大地提升了 AI 应用的实用性和可靠性。
往期工作流文章
更多文章请到公众号主页查看
dify相关资源
如果对你有帮助,欢迎点赞收藏备用。
回复 DSL 获取公众号DSL文件资源
回复 入群 获取二维码,我拉你入群
回复 tk 获取免费token资源
你又不打算赞赏,就点赞、在看吧

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









