






作者:超人阿亚
来源:公众号:dify实验室
1、系统背景
你不会还在用书签管理自己的文章吧。有没有很痛苦,明明添加书签的网页,当你想阅读的时候,总是找不到或者好不容易找到了,发现网页404了。如果有个小工具,直接能把你输入的链接内容抓取下来,并且加入到你的知识库中,你说他香不香。
2、需求分析
核心需求分析
网页抓取,通过蜘蛛抓取网页内容、解析出网页标题和内容、调用知识库接口存入个人知识库。
3、流程设计
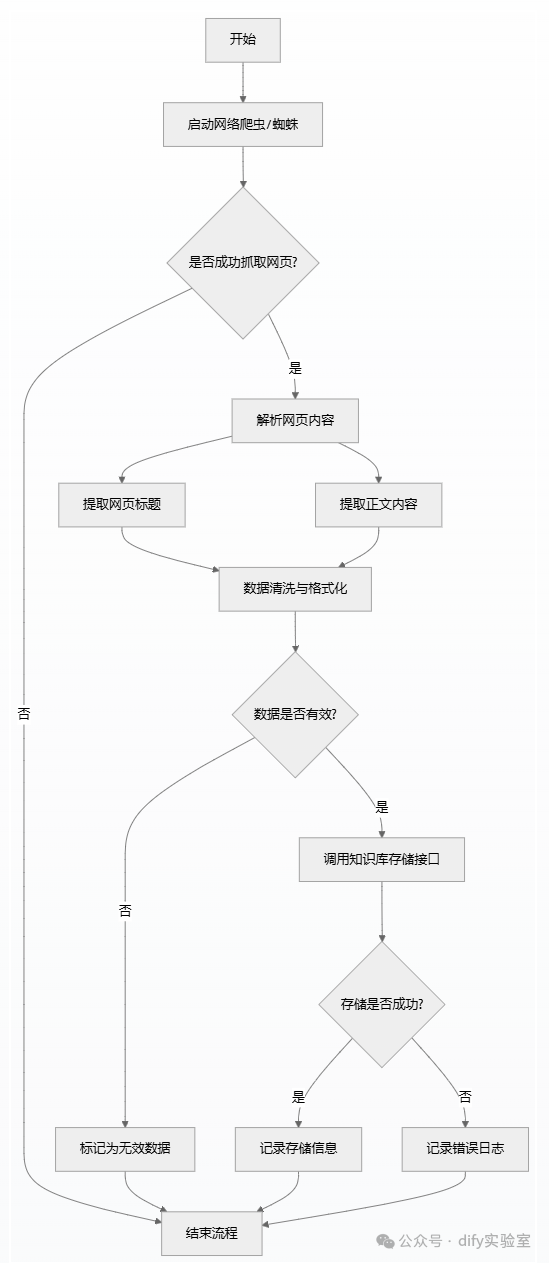
4、网页抓取
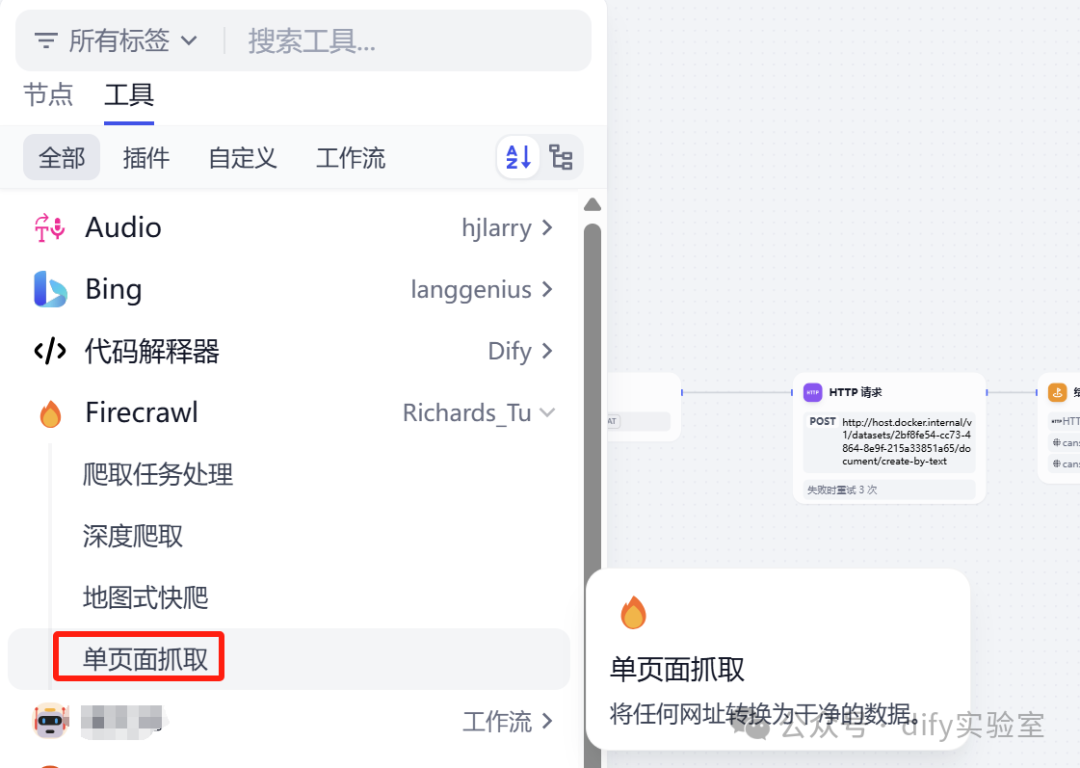
使用Firecrawl 工具,在工具中找到Firecrawl,点击单页面抓取,添加到画布。
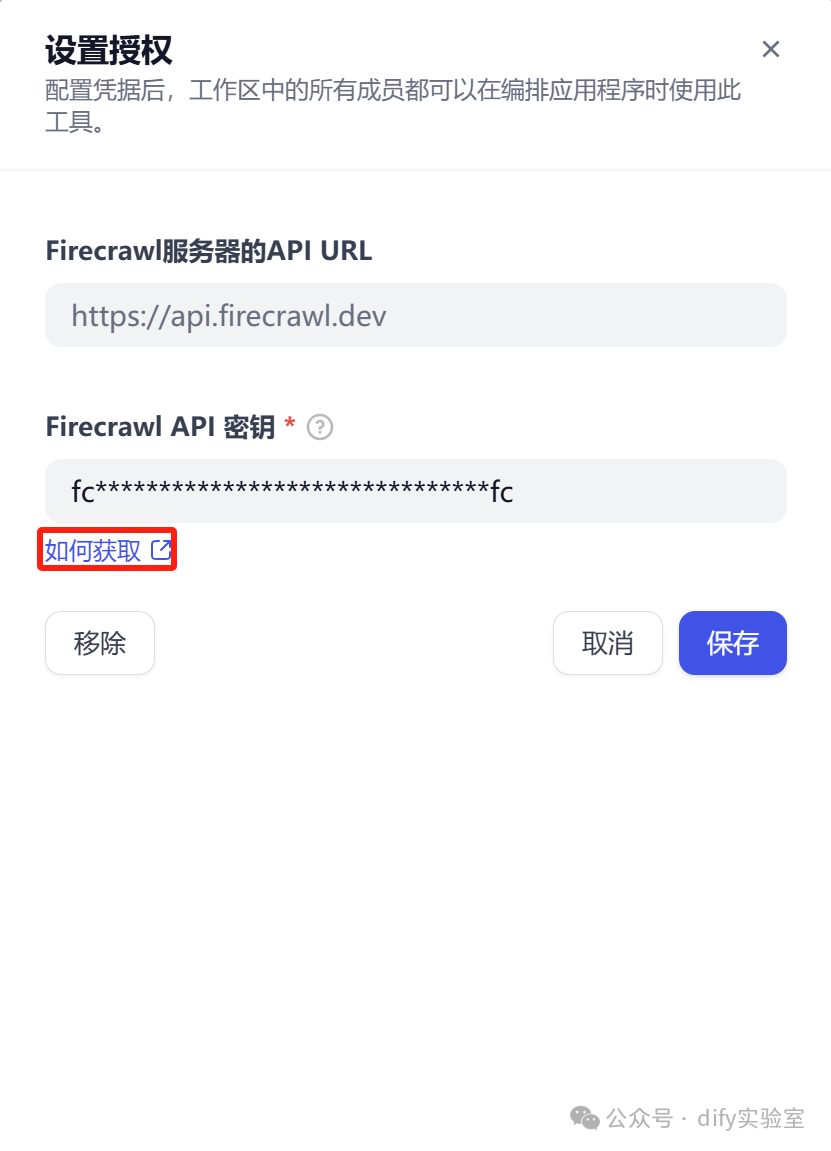
首次使用需要授权。点击获取按钮,按照帮助说明,获取API密钥。
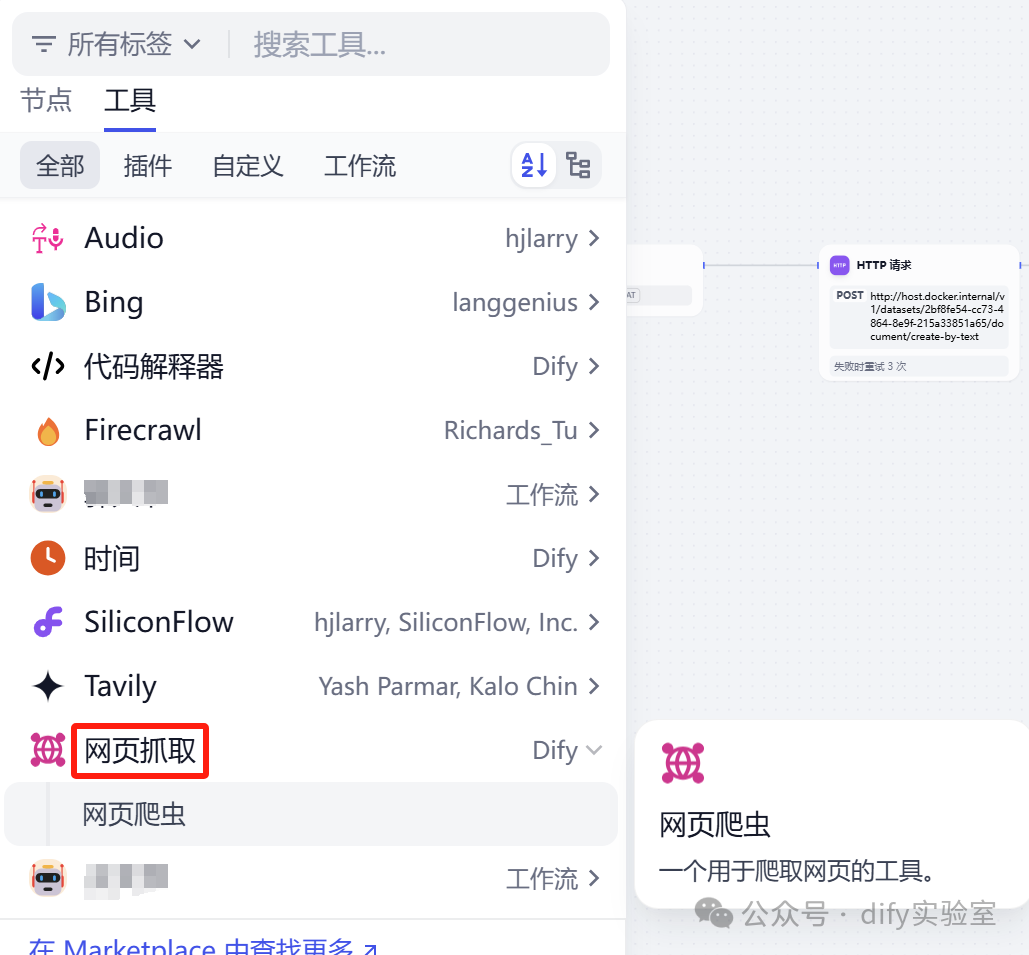
无法获取授权的,也可以使用网页抓取工具,这个是免费的,抓取效果也可以。
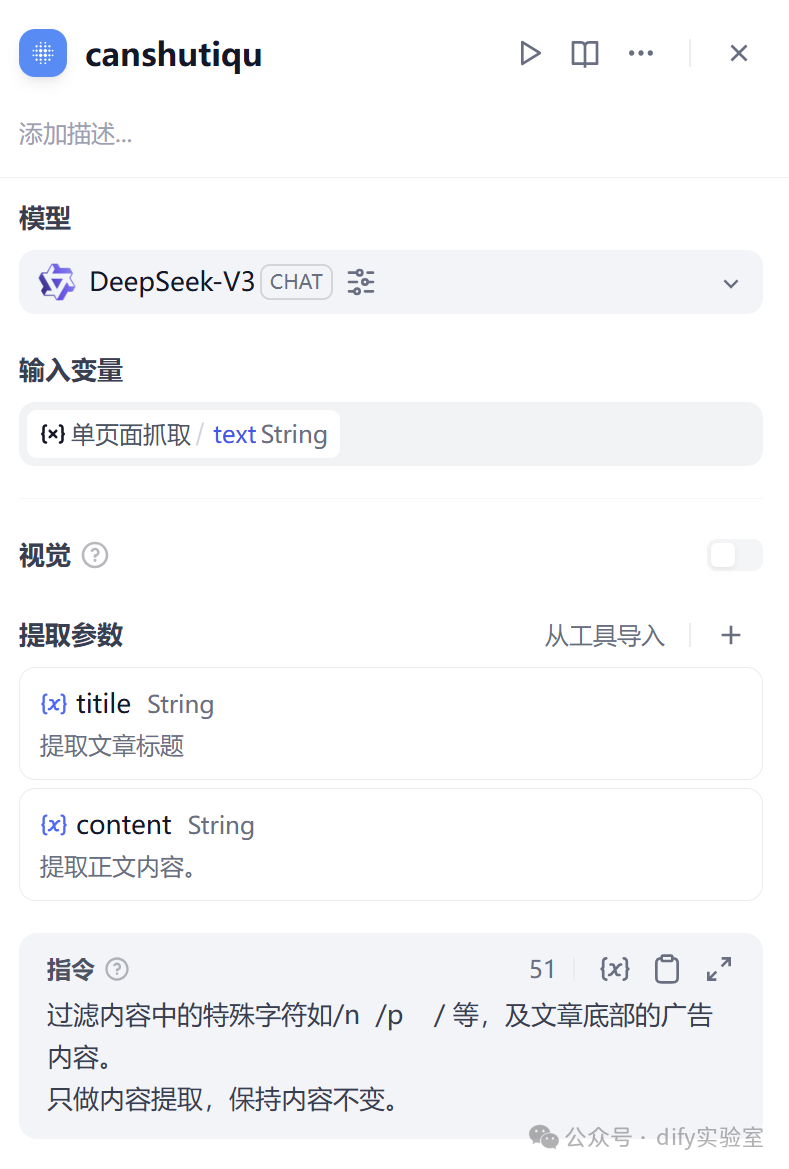
5、参数提取
使用参数提取器,提取网页标题和内容,新增两个提取参数,分别为title、content
6、构造http请求,更新知识库
使用http请求节点,请求知识库API。
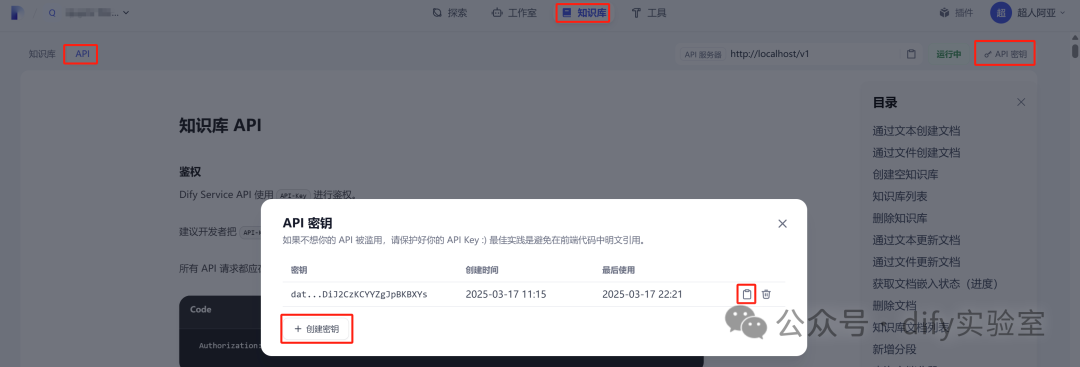
6.1 创建API秘钥。创建成功后,我们把他保存下来。
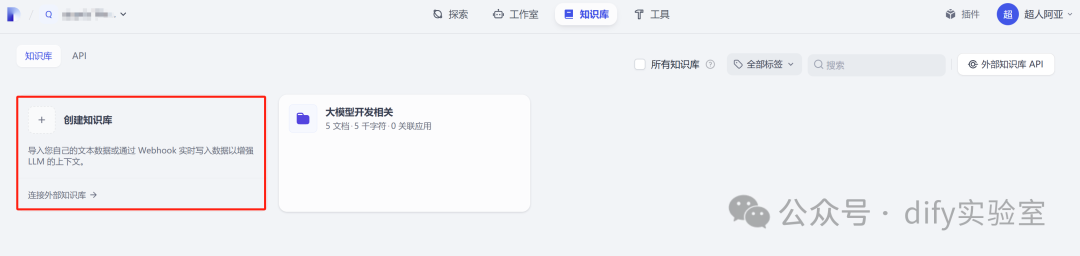
6.2 创建一个知识库,后续将文章存入到哪个知识库中,就可以创建这个知识库。
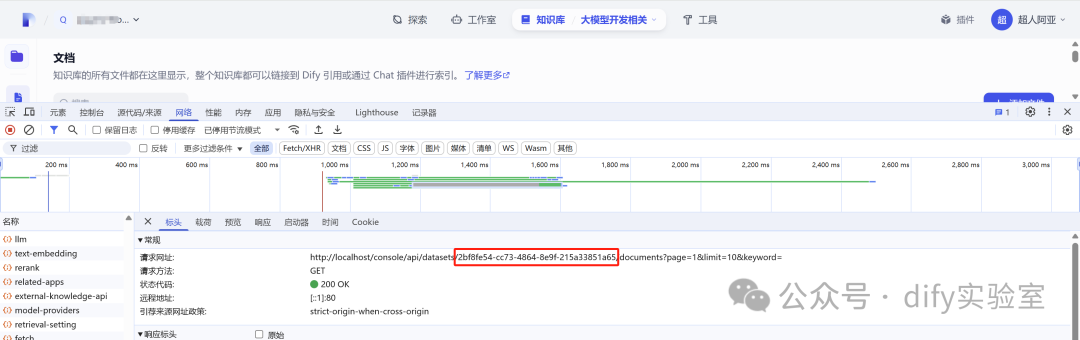
6.3 获取知识库的id
方法1,使用浏览器抓包。具体方法为,点击进入到这个知识库,右键-检查,刷新页面,然后找到 documents?page=1&limit=10&keyword=,点击后如下图。红框中的即为当前知识库的id,把他保存下来,后面会用到。
方法2,构造请求,使用知识库API接口获取知识库id
get http://host.docker.internal/v1/datasets?page=1&limit=20,配置好识库的APIkey。点击运行此步骤。获得知识库id,有多个知识库时,请根据name来判断。
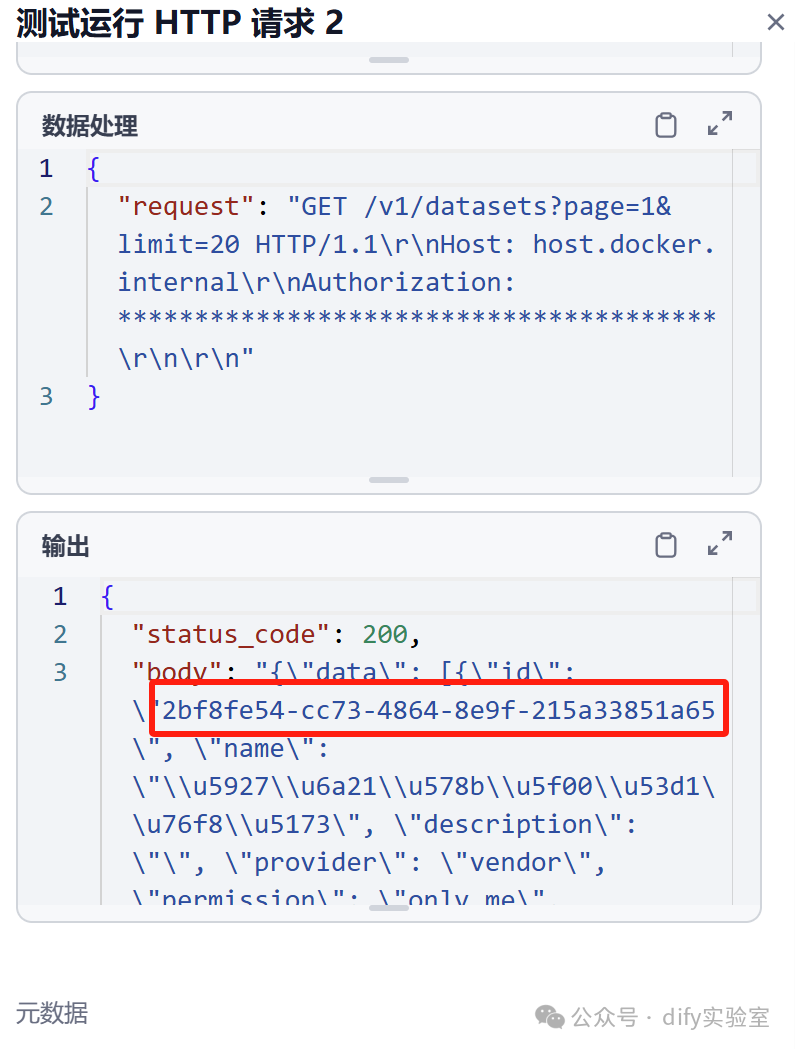
6.4构造请求, 更新知识库内容
API:
post http://host.docker.internal/v1/datasets/{你的知识库id}/document/create-by-text
HEADERS:
Content-Type : application/json
BODY-raw:
{"name": "{新建的title变量}","text": "新建的content变量","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}
7、http请求节点常见报错处理
a、 报错内容为:
Reached maximum retries (0) for URL http://localhost/v1/datasets/2bf8fe54-cc73-4864-8e9f-215a33851a65/document/create-by-text
解决方案:将localhost替换为 host.docker.internal
原因 当 Dify 需要访问宿主机上运行的服务(如数据库、API 或其他依赖服务)时,必须通过宿主机的真实 IP 进行通信。host.docker.internal 是 Docker 提供的特殊 DNS 名称,自动映射到宿主机的内部 IP。
b、Request failed with status code 400
解决方案:检查请求方式、构造的参数是否正确,往往是构造参数错误导致的。
c、"status_code": 400,
"body": "{\"code\": \"bad_request\", \"message\": \"The browser (or proxy) sent a request that this server could not understand.\", \"status\": 400}\n"
解决方案:检查输入的文本中是否包含/n /p / 等特殊字符,需要将特殊字符去掉,或者转义。
8、改进余地
这个工作流还可以继续改进,例如加入 问题分类器 节点,判断网页知识的内容类型,以存入到不同的知识库中。
获取DSL文件(微信公众号:dify实验室)
DSL文件分享公众号回复 DSL ,获取工作流DSL文件。目前我建立了一个dify学习交流群。可以在微信公众号回复 入群,我拉你进群。

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









