







Step 1: Importing the libraries
import numpy as np import pandas as pd
Step 2: Importing dataset
- 数据集通常在.csv 文件中
- csv文件储存 表格式数据
- 用 pandas 库里面的read_csv 读取本地csv文件 作为 数据桢(dataframe)
- 从数据帧中创建独立的矩阵和独立变量和因变量
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values ## 创建独立变量---选取前三列
Y = dataset.iloc[ : , 3].values ## 创建依赖变量-----选取最后一列 返回值的类型仍为 dataframe
ps : iloc 选取特定的列

Step 3: Handling the missing data
- 为了不影响机器学习模型效果,需要处理缺失的数据
- 使用整列的中位数或者平均值表示缺失值
- 使用sklearn.preprocessing 中的 Imputer类
from sklearn.preprocessing import Imputer imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0) imputer = imputer.fit(X[ : , 1:3]) X[ : , 1:3] = imputer.transform(X[ : , 1:3]) ## 将其应用到数据
运行结果:

Step 4: Encoding categorical data
- 分类数据:有标签值 而不是数字值---例如国家,性别
- 分类数据具有有限的可能值
- 编码这些变量 使得其具有 数字值
- 需要sklearn.preprocessing 中的 LabelEncoder类, OneHotEncoder
因为不同国家的地位相同,不能设置1,2,3 而是将不同的类别(如不同国家)另外分为一个列,属于这个国家的设置为1,不属于的设置为0.:
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) onehotencoder = OneHotEncoder(categorical_features = [0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_Y = LabelEncoder() //处理依赖变量 Y = labelencoder_Y.fit_transform(Y)
运行结果:

Step 5: Splitting the datasets into training sets and Test sets
- 数据集分成训练集和测试集
- 分的比例通常 8:2
- 使用sklearn.cross_validation 中 train_test_split 类
from sklearn.cross_validation import train_test_split X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
Step 6: Feature Scaling---特征缩放
- 使用欧几里得距离
- 特征与 标度有关,一个特征比其他的特征范围更大 该特征值成为主导
- 使用“特征标准化”-特征等同
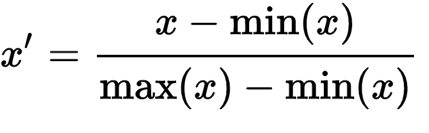
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.fit_transform(X_test)
小问题:
1 pip安装sklearn
Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/Library/Python/2.7/site-packages/sklearn' Consider using the
--useroption or check the permissions. Consider using the--useroption or check the permissions.
解决: 尝试
sudo pip install sklearn
2 run 代码的时候 出现小问题:
runfile('/Users/liuchuang/.spyder-py3/Data_preprocessing.py', wdir='/Users/liuchuang/.spyder-py3') /Users/liuchuang/anaconda3/lib/python3.6/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning)
- 解决:将 cross_validation 换成 model_selection















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









