







目录
第2章 数据预处理
数据预处理分类及方法详解
2.1 归一化
算法在寻找最优值的时候,由于图像“细长”,所以要来回找垂直线,两个特征的取值区间相差越大,图像就越“细长”,梯度下降就越慢,还可能永远无法收敛,如下图所示。因此需要使用归一化的方法将特征的取值区间缩放到某个特定的范围,例如[0, 1]等,常用方法有区间缩放和标准化:

-
区间缩放(Min-Max scaling)
又称为线性函数归一化,归一化公式子如下:
x n o r m = x − x m i n x m a x − x m i n . x_{norm}=\frac{x-x_{min}}{x_{max}-x_{min}}. xnorm=xmax−xminx−xmin.
该方法实现对原始数据的等比例缩放,其中 x x x为原始数据, x n o r m x_{norm} xnorm为归一化后的数据, x m a x x_{max} xmax和 x m i n x_{min} xmin分别为原始数据的最大值和最小值。使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:from sklearn.preprocessing import MinMaxScaler #区间缩放,返回值为缩放到[0, 1]区间的数据 MinMaxScaler().fit_transform(iris.data) -
标准化(standardization)
该方法又称为0均值标准化,归一化公式如下:
x n o r m = x − μ σ . x_{norm}=\frac{x-\mu}{\sigma}. xnorm=σx−μ.
该方法将原始数据归一化成均值为0、方差为1的数据, μ \mu μ、 σ \sigma σ分别为原始数据集的均值和方法。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:from sklearn.preprocessing import StandardScaler #标准化,返回值为标准化后的数据 StandardScaler().fit_transform(iris.data)
以上为两种比较普通但是常用的归一化技术,那这两种归一化的应用场景是怎么样的呢?什么时候第一种方法比较好、什么时候第二种方法比较好呢?下面做一个简要的分析概括:
- 在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
- 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
2.2 特征二值化
特征二值化的方法是将特征的取值转化为0或1。例如,在房价预测问题中对于“是否为学区房”这一特征,取值为1表示该房是学区房,反之则为0。在sklearn中可以设置一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)
2.3 独热编码
对于离散特征,例如,性别:{男,女},可以采用one-hot编码的方式将特征表示为一个m维向量,其中m为特征的取值个数。在one-hot向量中只有一个维度的值为1,其余为0。以“性别”这个特征为例,我们可以用向量 “1,0”表示“男”,向量 “0,1”表示“女”。独热编码更适合于取值较多的离散特征,以文本分析为例,每个单词可以看作一个特征,采用one-hot编码的方式将每个单词用m维向量表示,其中m为不同单词的个数。使用one-hot编码可将离散特征的取值扩展到了欧式空间,便于进行相似度计算。使用preproccessing库的OneHotEncoder类对数据进行one-hot编码的代码如下:
from sklearn.preprocessing import OneHotEncoder
#对IRIS数据集的目标值进行one-hot编码
OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
在利用神经网络做文本分析时,神经网络的Embedding层可以自动实现这一过程,具体可参考另一篇学习笔记 第1章 Embedding 层:
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
2.4 缺失值计算
在实际应用中,我们得到的数据往往不完整,可以用以下方法进行处理:
- 最简单直接的方法是删除含有缺失值的数据删,这种做法的缺点是可能会导致信息丢失;
- 通过已有数据计算相应特征的平均数、中位数、众数等来补全缺失值
- 建立一个模型来“预测”缺失的数据。(KNN, Matrix completion等方法),决策树中的方法也有一定参考价值 DecisionTree;
- 引入虚拟变量(dummy variable)来表征是否有缺失,是否有补全。
用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
from numpy import vstack, array, nan
from sklearn.preprocessing import Imputer
#缺失值计算,返回值为计算缺失值后的数据
#参数missing_value为缺失值的表示形式,默认为NaN
#对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失
#参数strategy为缺失值填充方式,默认为mean(均值)
Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))
2.5 数据变换
当遇到如下四种情况,需进行数据变换:
- 方便置信区间分析或者可视化 (缩放数据, 对称分布);
- 为了获取更容易解释的特征 (获取线性特征);
- 降低数据的维度或者复杂度;
- 方便使用简单的回归模型.
数据变换的流程一般如下:
- 初步数据可视化和数据均值方差分析结果;
- 选择数据变换方法;
- 变换后数据可视化和数据均值方差分析;
- 假设验证;
- 确认数据变换是否有效.
数据变换一般分为单变量变换和多变量变换,一般来说多变量变换就成为了特征抽取(Feature Extraction),维度压缩(Dimension Reduction),
数据分解(Decomposition)等, 譬如主成分分析(PCA)。这里主要介绍单变量的变换。
单变量的变换又分为线性变换和非线性变换, 非线性变换是获取合适数据分布的常见方法。常见的变换方法如下图:
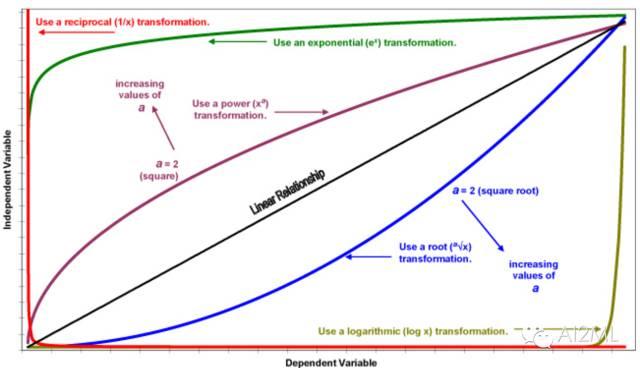
单变量变换可以使用一个统一的方式完成,使用preproccessing库的FunctionTransformer对数据进行对数函数转换的代码如下(这里使用了对数变换):
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
#自定义转换函数为对数函数的数据变换
#第一个参数是单变元函数
FunctionTransformer(log1p).fit_transform(iris.data)
2.6 样本不均衡
样本不均衡指的是数据集中的正样本数量与负样本数量的比例失衡。例如,实际应用中,负样本的数量通常远远大于正样本。样本不均衡的危害:造成分类器在多数类精度较高,少数类的分类精度很低,甚至造成分类器失效。解决方案分为以下三种:
- 欠采样:通过减少多数类样本来提高少数类的分类性能
- 随机地去掉一些多数类样本来减小多数类的规模,该方法的缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息
- 通过一定规则有选择的去掉对分类作用不大的多数样本(保留与正样本较为接近的负样本)
- 过抽样:通过改变训练数据的分布来消除或减小数据的不平衡
- 对少数类样本进行复制,该方法的缺点是可能导致过拟合,因为没有给少数类增加任何新的信息
- 算法层面
- 改进损失函数的权重,加大少数样本的权值
- 采用集成学习(bagging, boosting)















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









