





去中心化人工智能Decentralized Artificial Intelligence
关于去中心化加密安全神经代理On Decentralized Cryptographically Secure Neural Agents

当然,任何考虑使用算术方法产生随机数字的人都处于犯罪状态。Anyone who considers arithmetical methods of producing random digits is, of course, in a state of sin.

它比你想象的更像这样。It’s more like this than you’d think.
生成模型和 ChatGPT 的一个聪明之处在于,它们对于相同的提示(或输入)会给出不同的结果。据推测,这是通过在计算大量A clever thing about generative models and ChatGPT is that they give you different results for the same prompt (or input). This is done, presumably, by setting the random seed to the computer’s current system clock time just before computing an 矩阵extraordinary乘法之前将随机种子设置为计算机当前的系统时钟时间来完成的(或者当所有这些参数不适合单个计算机的 RAM 时,分布式意义上的一些等效项) )。 number of matrix multiplications (or some equivalent in a distributed sense when all of those parameters do not fit in the RAM of a single computer).
感谢您阅读混沌工程!免费订阅以接收新帖子并支持我的工作。
这个琐碎的细节给人一种 ChatGPT 不确定性的错觉,但事实并非如此。This trivial detail gives the illusion that ChatGPT is non-deterministic, but it’s not.
您可以You can 在 HuggingFace 的开源 ChatGPT 替代方案:HuggingChat中亲自看到这一点see this for yourself。 in HuggingFace’s open source ChatGPT alternative: HuggingChat.
大型语言模型(LLM)——就像所有机器学习模型一样——是一个估计的静态方程,这意味着对于固定的输入,您将收到固定的输出。生成模型进行一些概率加权随机抽样,以提供一点天赋和感知力的幻觉。Large Language Models (LLMs)—just like all machine learning models—are an estimated static equation, which means that for a fixed input you will receive a fixed output. Generative models do some probability weighted random sampling to provide a little flair and the mirage of sentience.
但法学硕士只不过是一堆数字、乘法、求和以及一些伪随机抽样。But LLMs are nothing more than a bunch of numbers, multiplications, sums, and a splash of pseudo-random sampling.
集中式人工智能Centralized Artificial Intelligence
OpenAI 最近遇到了OpenAI encountered 一些some 麻烦,他们做了一些令人难以置信的工作来troubles recently, and they’ve done some incredible work to 克服这些麻烦overcome them。.
但 OpenAI、MetaAI、Google Research、DeepMind 或其他任何人都无法解决核心问题,即真正的通用人工智能(AGI)需要But OpenAI, MetaAI, Google Research, DeepMind, or anyone else can’t solve the core problem, which is that true Artificial General Intelligence (AGI) needs 真正的truly开放 AI;也就是说,任何单一实体或研究实验室都不应被信任拥有通用人工智能的力量。 Open AI; that is to say that no single entity or research lab should be trusted with the power of AGI.
经过几个月的思考,我只得出一个结论:After several months of reflection, I’ve come to only one conclusion: 加密安全的去中心化账本是让人工智能更安全的唯一解决方案。a cryptographically secure, decentralized ledger is the only solution to making AI safer.
我很长一段时间以来一直认为区块链和加密I’ve thought for quite some time that blockchain and crypto 技术the technologies(不一定是数字货币)具有令人难以置信的影响,但我不知道其用途……事实证明答案隐藏在下一个炒作周期中。—not necessarily the digital currency—had incredible implications but I didn’t know what for…and it turns out the answer was hiding in the next hype cycle.
我既不是加密货币最大化主义者,也不一定是加密货币倡导者。然而,我是一名技术专家,看到了大多数加密货币所使用的技术的价值。I am neither a crypto maximalist, nor even necessarily a crypto advocate. I am, however, a technologist who sees the value of the technology used by most crypto currencies.
顺便说一句,我对加密货币最大的怀疑是,他们的大部分支持者似乎将其视为一种长期的价值储存手段,这会抑制交易的经济性,从而使其成为一种糟糕的交换媒介。无论如何,这就是很多人对待比特币、以太坊和其他代币的方式。As a brief aside, my biggest skepticism with cryptocurrencies is that a non-trivial share of their advocates seem to treat it as a long term store of value which creates an economic disincentive to transact, which then renders it a poor medium of exchange. Regardless, that’s how lots of people have treated Bitcoin, Ethereum, and other tokens.
那么,为什么我相信“So why do I believe “加密安全的去中心化账本是a cryptographically secure, decentralized ledger is the only solution” 真正开放人工智能的唯一解决方案”?to truly Open AI?
因为它解决了一些核心问题。Because it solves some core problems.
人工智能的一些问题Some of AI’s Problems
正如我所说,任何单一实体都不应成为任何真正 AGI 的唯一所有者。As I said, no single entity should be the sole owner of any true AGI. It creates far too much power in the hands of only well-capitalized institutions (i.e., those that can afford the compute necessary to train a 它在只有资本充足的机构(即那些能够负担训练巨型giganto模型所需的计算费用的机构)手中创造了太多的权力。 model).
除此之外,还存在其他挑战。There are other challenges outside of this, too.
再现性Reproducibility
学术文献中充斥着不可重现的最先进(SOTA)模型的例子,尽管人们一直在努力The academic literature is ridden with examples of state of the art (SOTA) models that weren’t reproducible and while there’s an 改进这一点,ongoing effort to improve this但足以说明很多模型(甚至可能是大多数)都是不可重现的。 suffice it to say that a lot of models aren’t reproducible (maybe even most).
这是糟糕的科学,但学术界的动机就是如此。That’s bad science, but the incentives in academia are what they are.
机器学习行业从业者在模型可重复性(即模型版本控制)方面已经取得了很大的进步,但在早期,许多人忘记了ML industry practitioners have come quite a long way in model reproducibility (i.e., model version control) but in the early days many forgot about 数据版本控制data version control。.
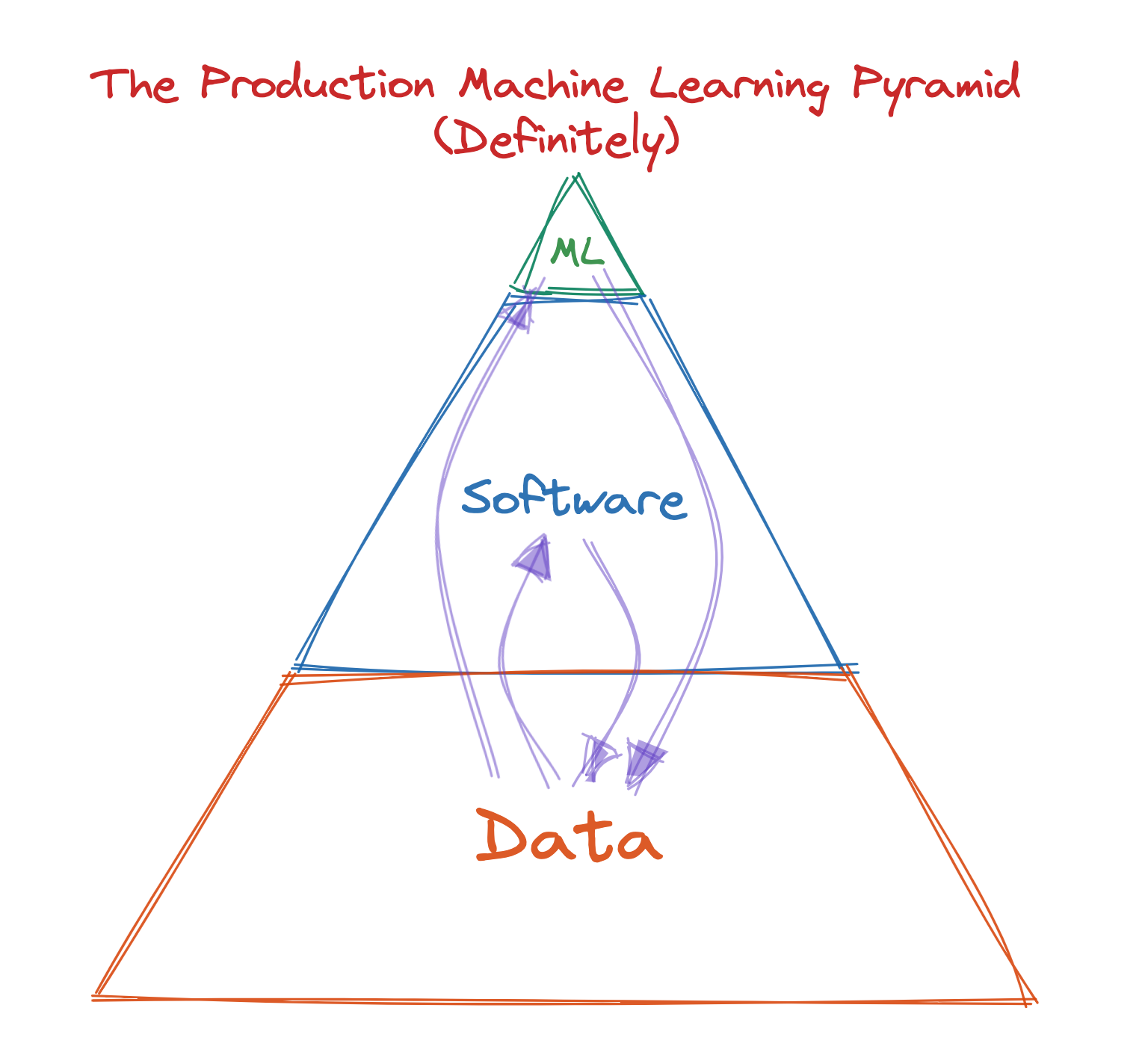
数据是基础;软件提供高质量的数据;机器学习有望产生更多数据。最重要的是,优秀的软件会产生更多数据。Data is the foundation; software provides high quality data; and ML, hopefully, produces more data. Most importantly, great software begets more data.
很明显,Quite obviously, 除非数据和构建模型和数据的代码也受版本控制,否则模型无法受版本控制a model cannot be version controlled unless the data and the code that constructed both the model and the data are version controlled, too。.
否则就是愚蠢的Thinking otherwise is dumb(记住,那不是你!)。 (and, remember, that’s not you!).
因此,为了总体上具有可重复性,我们需要模型和数据可重复性,事实证明,记录发布到某个链的每个版本的去中心化数据库是一个非常好的候选者。So in order to have reproducibility in general we need model and data reproducibility, and it turns out that a decentralized database that records every version posted to some chain is a very good candidate for that.
数据隐私Data Privacy
大多数人并不Most people don’t 真正really关心您是否将他们的数据用于其他用途,只要它 (1) 提供正确的产品体验并且 (2) 不是恶意的。 care that you use their data for things so long as it (1) serves the right product experience and (2) isn’t malicious.
但有些人却很在意!一些国家(例如意大利或欧洲国家)的关心程度要高出 100 倍。But some people care a lot! And some countries (e.g., Italy or European countries) care 100x more than that.
密码学和去中心化的好处是,您可以在不发送数据的情况下估计“本地”模型,并且仍然将估计的梯度贡献给网络。此外,您还可以加密数据以确保其安全。这称为A benefit of cryptography and decentralization is that you can estimate “local” models without sending data and still contribute back the estimated gradient to the network. Additionally, you could encrypt the data as well to secure it. This is known as 联邦学习Federated Learning,是一个活跃的研究领域。 and is an active area of research.
也就是说,这种方法实际上并不是我认为应该存在的,它是两个独立的分类账:一个用于数据,另一个用于学习。That said, this approach isn’t actually what I think should exist, which are two separate ledgers: one for data and another for learning.
过时的信息Stale Information
ChatGPT 用户经常抱怨的是,该模型仅使用截至 2021 年 9 月的数据进行训练,这意味着数据和模型已经过时。因为它使用大规模网络数据,这作为一个实际限制很有意义,但为了让 AGI 发挥作用,我们需要A frequent complaint that users of ChatGPT have is that the model was only trained on data up to September 2021, which means that the data and model are stale. Because it used large scale web data this makes a lot of sense as a practical limitation but for AGI to work, we need 流数据streaming data 和and持续学习 continuous learning。.
这两个问题都很重要,需要相当复杂的大规模分布式计算和流数据基础设施……或者可以通过去中心化和Both of these problems are non-trivial and require quite sophisticated large scale distributed computing and streaming data infrastructure...or they can be solved through decentralization and 梯度gradient挖掘来解决。 mining.
海量计算需求Massive Compute Requirements
我想强调“大型语言模型”中的“大”,它们非常大且运行成本高昂。这是技术行业之外的人员或实验室无法真正构建这些最先进模型的主要原因之一I would like to underscore the “Large” in “Large Language Models”, they are very big and costly to run. Which is one of the main reasons why people or labs outside of the technology industry can’t really build these state of the art models
。.顺便说一句,学者们在尝试开发新颖的算法时,大多数都会迭代新颖的架构,而不是尝试更新现有模型,这可能会浪费大量计算。As a brief aside, academics, in their attempt to develop novel algorithms, most iterate on novel-ish architectures rather than try to update existing models, which is arguable a lot of wasted compute. LoRALoRA是一个与此完全相反的非凡例子。 is an an extraordinary example of the exact opposite of this.
Over the last decade, large scale machine learning models benefited greatly from using GPUs instead of CPUs because they are much more efficient at executing matrix multiplications (在过去的十年中,大规模机器学习模型从使用 GPU 而不是 CPU 中受益匪浅,因为它们在执行矩阵乘法(一种令人尴尬的可并行数学运算an embarrassingly parallelizable mathematical operation)方面更加高效。).
事实证明,它们对于比特币挖矿也非常有用。They also turned out to be incredibly useful for Bitcoin mining.
矿工Miners 可以could决定计算梯度(即训练模型)而不是区块链上的交易,理论上,这将是一个简单的迁移。 decide to compute gradients (i.e., train a model) instead of transactions on the blockchain and, theoretically, this would be a straightforward migration.
激励措施Incentives
矿工挖矿不是为了增加碳排放——他们挖矿是为了赚钱。因此,需要有经济激励来让矿工想要开采梯度。Miners don’t mine for the sake of increasing our carbon emissions—they mine to make money. Therefore, there needs to be an economic incentive to make miners want to mine Gradients.
这可以是数字货币或其他任何东西。This could be a digital currency or whatever.
还需要激励贡献培训数据。当人们选择贡献他们的数据时(There also needs to be an incentive to contribute training data. People should be rewarded when they choose to contribute their data (DeSo 正在这样做DeSo is doing this),并且为他们的数据添加标签,他们应该得到奖励。) and even more so for labeling their data.
货叉模型Model Forks
加密货币经常Crypto currencies are often 为了不同的目标而被分叉和扩展。forked如果我们有一个去中心化系统,其中计算的模型权重被发布到去中心化账本,那么我们不仅可以在任何时间点恢复模型,而且还可以分叉它们并以不同的目标(例如新架构)训练它们。 and expanded upon for different goals. If we have a decentralized system where computed model weights are published to a decentralized ledger, then we can not only recover models at any point in time but we can also fork them and train them with different goals in mind (e.g., new architectures).
除了创造非凡的模型谱系之外,在模型行为不当的极端情况下(即人类的末日)Beyond creating an extraordinary lineage of models, in an extreme case of models misbehaving (i.e., humanity’s doom
),我们可以找到导致混沌 AGI 的时间点和数据。), we could find the point in time and the data that led to a chaotic AGI.企业价值Enterprise Value
谁会从去中心化的 AGI 中受益?Who would benefit from a decentralized AGI?
首先,也是最重要的,呃,人性。First and foremost, uh, humanity.
其次,我认为嵌入这些新的去中心化模型会有很多实施机会,就像 ChatGPT 插件现在风靡一时一样。如果您进行加密类比,那么交易所对用户有用,因此人们可能会认为使用这些模型的交易所最终可能是答案。Secondly, I think there would be a lot of implementation opportunities in embedding these new decentralized models, similar to how ChatGPT plugins are now all the rage. If you make the crypto analogy it was exchanges that were useful to users, so one might think an exchange for the usage of these models could ultimately be the answer.
随着未来几年技术世界的快速发展,我实际上认为不同类型 AGI 的市场可能会成为一件事。我知道这里明显的缺陷是“真正的 AGI 能够在广泛的用例中拥有智能”,虽然这在未来可能是正确的,但现在却不是这样,我想从现在开始会有很多可捕获的价值当那个未来到来时。As the world of technology evolves rapidly over the coming years, I actually think a marketplace for different types of AGI could be a thing. I know the obvious flaw here is “A true AGI would be able to have intelligence across a broad set of use cases” and while maybe that’s true in the future, it’s not true now and I imagine there will be lots of capturable value between now and when that future comes.
加密解决了这个问题Crypto Fixes This

但确实如此。For real though.
正如本文所述,需要采取一种新方法来更广泛地分散法学硕士和人工智能,以便我们可以尝试控制不可避免的“奇点As mentioned throughout this article, a new approach needs to be taken to decentralize LLMs and AI more broadly so that we can attempt to control the inevitable “” singularity。我提出的方法类似于”. The approach I propose is analogous to 工作量证明Proof of Work,但我们可以使用计算来估计梯度,而不是任意浪费计算。 but instead of arbitrarily wasting compute, we can use the compute to estimate gradients.
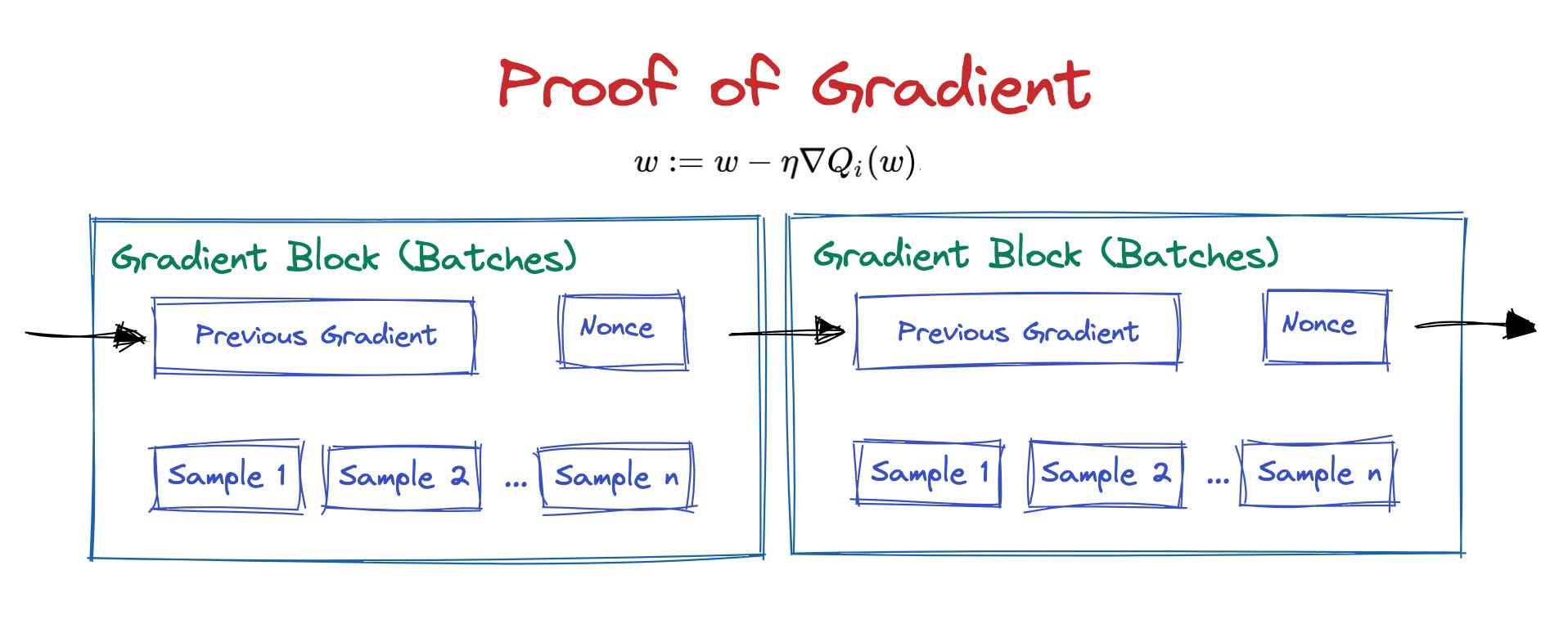
对梯度证明的非常粗略的描述。A very crude depiction of Proof of Gradient.
我还提到,我们需要两个分类账:(1)用于模型权重,(2)另一个用于训练这些权重的数据。这些可以以与添加到区块链中的候选交易相同的方式处理,其中签名用于验证交易链。I also mentioned that we would need two ledgers: (1) for the model weights and (2) another for the data used for training those weights. These could be treated in the same way as candidate transactions being added to the Blockchain where signatures are used to verify the chain of transactions.
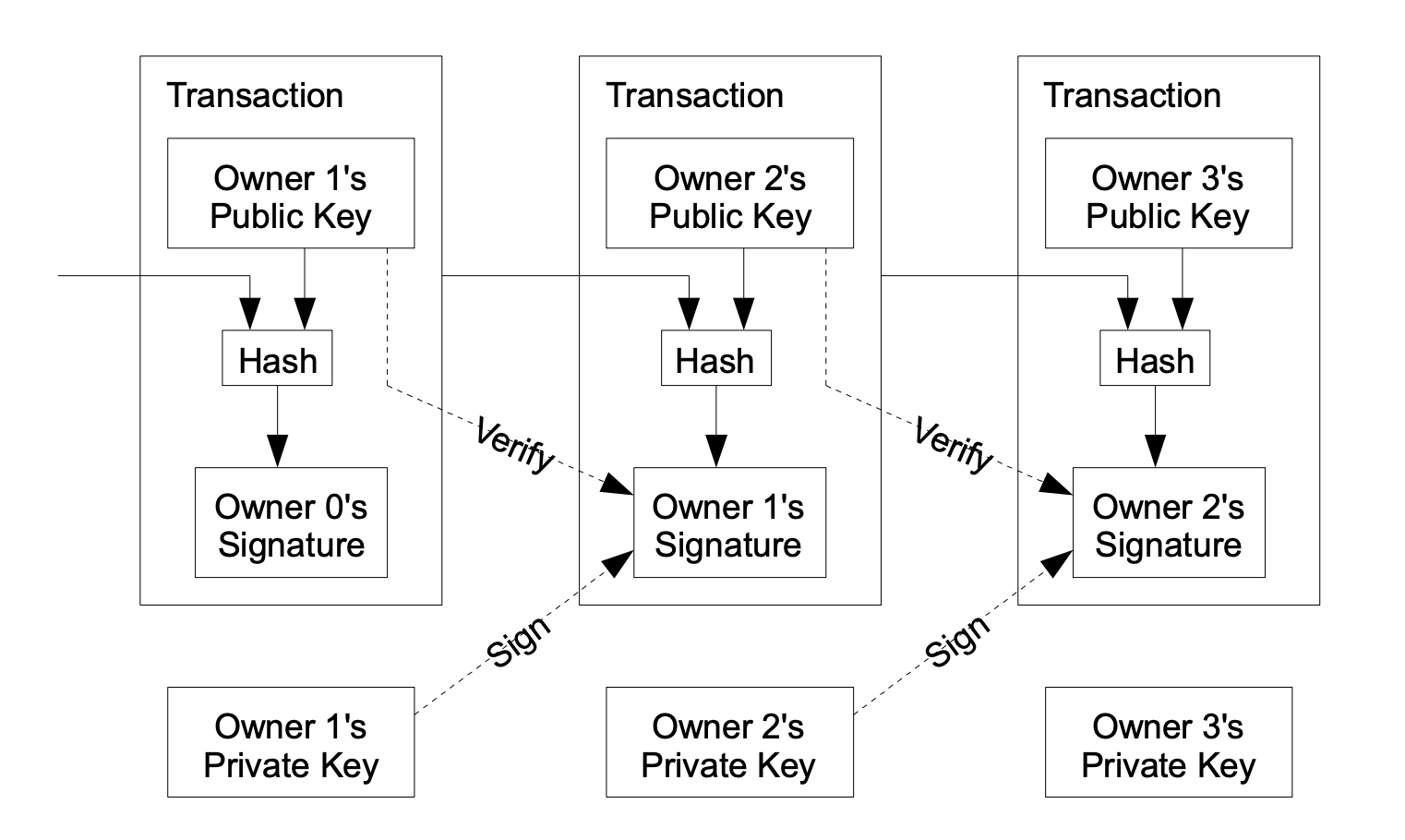
在这种情况下,我们将用增量数据集或更新的模型权重替换交易。In this case we would replace transactions with an incremental set of data or updated model weights.
结束语Closing Thoughts
所有这些听起来可能有点荒谬,但事实并非如此。事实上,All of this may sound a little ridiculous but it’s not. In fact, 这项工作已经由the work has already begunOpenSea前 CTO开始了 by the former CTO of 。OpenSea.
目前,在最近加密货币价格下跌之后,许多人(尤其是在 Twitter 上)都在指指点点并嘲笑加密货币爱好者,这可能表明人们在思考该领域时已经走得太远了。At the moment, many people (especially on Twitter) are pointing and laughing at crypto enthusiasts after the recent fall in cryptocurrency prices and that is a potential indicator that people have gone too far the other direction in their thinking about the space.
一般来说,最好不要跟风。In general, it’s good to not jump on the bandwagon.
快乐挖矿!Happy mining!
-弗朗西斯科🤠-Francisco 🤠















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









