







简介
当前许多图像分类的研究可以归功于训练过程的改进,例如改进数据增强和优化方法。然而在一些文献中,许多改进仅仅在实验细节中有简短的描述活在源码中才会出现。本文使用了这些小技巧将原始ResNet-50在ImageNet上的准确率从75.3%提升到79.29%。复现结果可以在GluonCV中找到,https://github.com/dmlc/gluon-cv。这篇文章可以看作是一群经验丰富的工程师介绍炼丹技巧,帮助大家可以练出更好的丹药。
首先可以看一下作者训练的ResNet-50的网络效果。下表对比了目前比较常用的分类网络的效果,最后一行是作者通过添加各种训练技巧后复现的ResNet-50的效果,和原论文的结果对比提升非常明显(top-1准确率从75.3%提升到79.29%)。
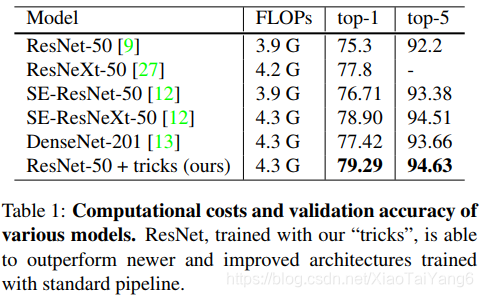
既然要做对比实验,首先要有一个baseline就是作者复现相关算法的结果,这个baseline的复现细节包括数据预处理的方式和顺序,网络层参数初始化方式,迭代次数,学习率变化策略等。
Baseline训练过程
在训练阶段的做法如下:
(1)随机采样图像,将其从【0,255】原始像素值解码为32位浮点数。
(2)随机裁剪纵横比在[3/4,4/3]之间,面积在[8%,100%]之间的矩形区域,然后将裁剪区域调整为224 * 224的方形图像。
(3)用0.5的概率做水平翻转。
(4)从[0.6,1.4]之间均匀采样系数来缩放色调,饱和度,亮度。
(5)增加PCA噪声,系数为正态分布N(0,0.1)中的采样。
(6)归一化RGB通道。
测试阶段调整图像的短边为256,同时保留其纵横比。之后从中间裁剪出224 * 224,用训练阶段的方式归一化RGB通道,不做其他数据增强。
下图是作者采用baseline方式复现的三个常用分类网络的结果,可以看出效果和原论文差不多,这里的baseline也将作为后续的实验对比对象。
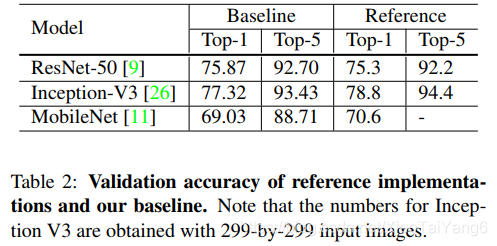
介绍完baseline后,接下来就是这篇论文的重点:怎么优化?整篇论文从加快模型训练,网络结构优化和训练调优三个部分分别介绍如何提升模型效果。
一、加快模型训练部分:
一共有两块内容,一块是选择更大的batch size,另一块是采用16为浮点型进行训练。
选用更大的batch size能够在整体上加快模型的训练,但是一般来说只增大batch size效果不太理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









