







一、长宽表的变形
长表和宽表的概念一下子就有点晕,我试着自己理解一遍。
“一个表中把性别存储在某一个列中,那么它就是关于性别的长表;如果把性别作为列名,列中的元素是某一其他的相关特征数值,那么这个表是关于性别的宽表。”
关于“性别”的长表:就是想要储存和展现性别这一特征。(性别是主体)
关于“性别”的宽表:性别只是其他某一特征进行分类的一个标准,还是想要储存和展现其他的这个特征。(性别不是主体,其他的这一个特征才是主体)
例子:
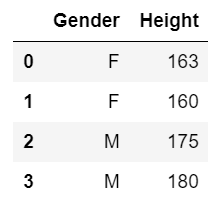
pd.DataFrame({'Gender':['F','F','M','M'], 'Height':[163, 160, 175, 180]})
output:
pd.DataFrame({'Height: F':[163, 160], 'Height: M':[175, 180]})
output:
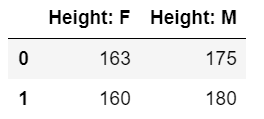
只是呈现的方式不同啦~
1. pivot
pivot是一种典型的长表变宽表的函数。
df = pd.DataFrame({'Class':[1,1,2,2],
'Name':['San Zhang','San Zhang','Si Li','Si Li'],
'Subject':['Chinese','Math','Chinese','Math'],
'Grade':[80,75,90,85]})
df
output:

长变宽的操作而言,最重要的有三个要素,分别是变形后的行索引、需要转到列索引的列,以及这些列和行索引对应的数值,它们分别对应了pivot方法中的index, columns, values参数。新生成表的列索引是columns对应列的unique值,而新表的行索引是index对应列的unique值,而values对应了想要展示的数值列。
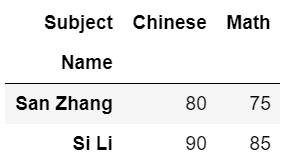
例子:
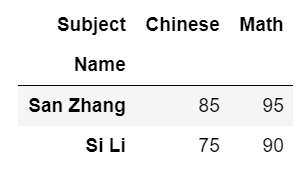
df.pivot(index='Name', columns='Subject', values='Grade')
output:
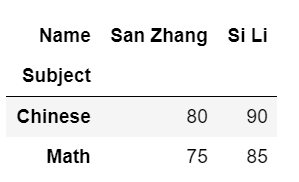
换一下行和列的位置:
Subject
output:
要求:利用pivot进行变形操作需要满足唯一性的要求!
必须使得行和列的组合都是唯一的,不然不知道该选哪个数值啦~
!多级索引:
pivot相关的三个参数允许被设置为列表,这也意味着会返回多级索引。这里构造一个相应的例子来说明如何使用:下表中六列分别为班级、姓名、测试类型(期中考试和期末考试)、科目、成绩、排名。
df = pd.DataFrame({'Class':[1, 1, 2, 2, 1, 1, 2, 2],
'Name':['San Zhang', 'San Zhang', 'Si Li', 'Si Li',
'San Zhang', 'San Zhang', 'Si Li', 'Si Li'],
'Examination': ['Mid', 'Final', 'Mid', 'Final',
'Mid', 'Final', 'Mid', 'Final'],
'Subject':['Chinese', 'Chinese', 'Chinese', 'Chinese',
'Math', 'Math', 'Math', 'Math'],
'Grade':[80, 75, 85, 65, 90, 85, 92, 88],
'rank':[10, 15, 21, 15, 20, 7, 6, 2]})
df
output:

把测试类型和科目联合组成的四个类别(期中语文、期末语文、期中数学、期末数学)转到列索引,并且同时统计成绩和排名:
pivot_multi = df.pivot(index = ['Class', 'Name'],
columns = ['Subject','Examination'],
values = ['Grade','rank'])
pivot_multi
output:

变换一下:
pivot_multi = df.pivot(index = ['Subject','Examination'],
columns = ['Class', 'Name'],
values = ['Grade','rank'])
pivot_multi
报错了,输出的形状不对······
2.pivot_table
pivot的使用依赖于唯一性条件,那如果不满足唯一性条件,那么必须通过聚合操作使得相同行列组合对应的多个值变为一个值。例如,张三和李四都参加了两次语文考试和数学考试,按照学院规定,最后的成绩是两次考试分数的平均值,此时就无法通过pivot函数来完成。
df = pd.DataFrame({'Name':['San Zhang', 'San Zhang',
'San Zhang', 'San Zhang',
'Si Li', 'Si Li', 'Si Li', 'Si Li'],
'Subject':['Chinese', 'Chinese', 'Math', 'Math',
'Chinese', 'Chinese', 'Math', 'Math'],
'Grade':[80, 90, 100, 90, 70, 80, 85, 95]})
df
output:

利用pandas的pivot_table,其中的aggfunc参数就是使用的聚合函数,算平均数。
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = 'mean')
aggfunc参数还可以传入以序列为输入标量为输出的聚合函数来实现自定义操作~
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = lambda x:x.mean())
上面两段代码的output都是:















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









