







title: JDK源码分析之Hashtable
date: 2020-03-04 11:09:00
tags:
- Hashtable
- jdk源码
categories: - 源码分析
源码
C:\ProgramFiles\Java\jdk1.8.0_181\jre\lib\rt.jar!\java\util\Hashtable.java
简介
本类是java.util.Map接口的一个线程安全实现,自JDK1.0时就被添加进来。任何非空对象都可以用作键或值。为了保证从哈希表存储和检索对象,用作键的对象必须实现hashCode方法和equals方法。
类图结构
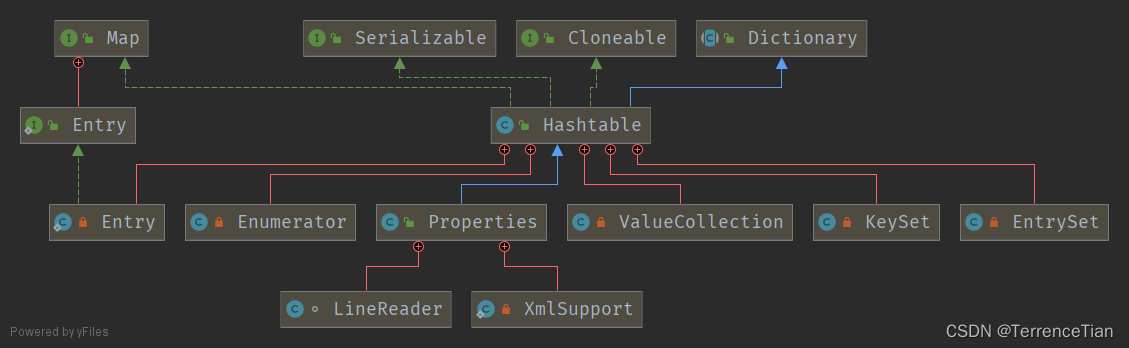
下面介绍一下它里面这些内部类的情况:
- Entry:表示KV整体的对象。
- ValueCollection:实现Collection接口,为了让值可以被迭代。
- Enumerator:为了实现元素可迭代
- EntrySet:条目列表
- KeySet:键列表
实现思路
方法实现
初始化
在初始化时有两个重要参数:初始容量(int initialCapacity)和负载因子(float loadFactor),前者控制初始化Entry数组的大小,后者控制当容量不足时进行扩容的时机。
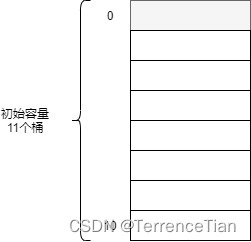
Hashtable(int, float)按照指定的容量和因子进行初始化。Hashtable(int)按照指定的容器和75%因子进行初始化,默认负载因子(.75)在时间和空间成本之间提供了一个很好的折衷方案。Hashtable()如果不提供参数,那么默认初始容量11,负载因子75%。Hashtable(Map)从给定的Map中复制数据,初始容量最小11,最大2倍Map.size(),负载因子75%。
根据负载因子*初始容量计算扩容阈值(threshold),最大不超过Integer.MAX_VALUE - 7。
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
添加键值对
以
put(K key, V value)为例
- 值不能为null,否则抛出NPE。
if (value == null) {throw new NullPointerException();} - 计算键的hash code值,再根据它计算值应该放置到hash表中的索引位置。先将hash值变成正数,再与hash表的长度取模。
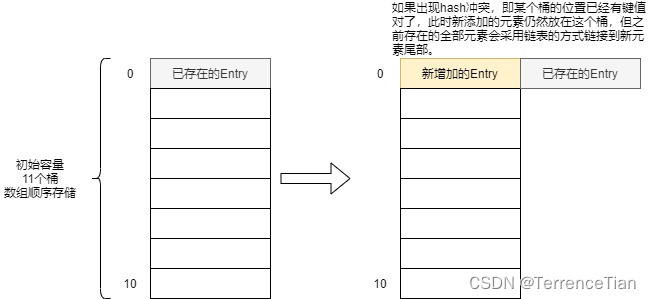
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; - 根据第2步计算出来的索引位置查询hash表,如果结果不为null则表示这个桶的位置已经有值了,也就是遇到hash冲突了。对于这种情况的处理是采用单向链表的方式,把新添加的键值放到已找到的键值对象头部。如果发现要添加的键值已经存在,则更新值,并返回旧的值。
Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } - 添加新键值对。传递键hash code、键、值和按计算出的索引找到的Entry对象来初始化Entry对象,将这个初始化对象赋给hash表中的索引位置(第2步计算出来的索引位置)。累计hash表中的条目(Entry)数量。
Entry<K,V> e = (Entry<K,V>) tab[index]; tab[index] = new Entry<>(hash, key, value, e); count++; - 扩容判断。判断是否达到阈值,如果已经达到阈值则先扩容,再计算落到哪个桶里面。
if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF) % tab.length; } - 真正扩容。创建新has表,并将旧hash表的数据复制过来。
protected void rehash() { //记录当前hash表及长度数据 int oldCapacity = table.length; Entry<?,?>[] oldMap = table; // 计算新hash表的容量,2倍原容量+1 int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) return; newCapacity = MAX_ARRAY_SIZE; } //根据新的容量创建新的Entry数组 Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++; threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); //将新数组替换原来的hash表 table = newMap; //把旧hash表的数据复制到新hash表 for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; //如果发现当前节点有后继,则进行下一次处理 old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; //把原有的节点附加到当前新加入节点后面 e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
根据键获取对应值
以
get(Object key)为例
- 计算传进来的键对象hash code,再计算它落桶的索引,方法同上。
- 通过for循环Entry数组(即所谓hash表),逐一判断每项Entry对象是否匹配到传入键,如果匹配到则返回对应值,否则返回null。
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } }
总结
- 为什么说Hashtable是线程安全的呢?因为它里面的方法均加上了synchronized,在保证多线程并发修改时的安全性同时也降低了程序性能。
- 建议构造Hashtable时明确指出初始容量和负载因子,如果触发扩容动作会增加程序无谓消耗,所以对于已知容量的情况下一定要指定这两个参数。
- 如果不需要线程安全的实现,建议使用HashMap代替Hashtable。如果需要线程安全的高并发实现,则建议使用ConcurrentHashMap代替Hashtable。















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









