






使用阿里云flink实时计算平台,全新启动flink作业后,作业不报错,无任何异常,也不拉取数据.
更换最新vvr引擎版本再次启动后,作业task manager报错java heap space
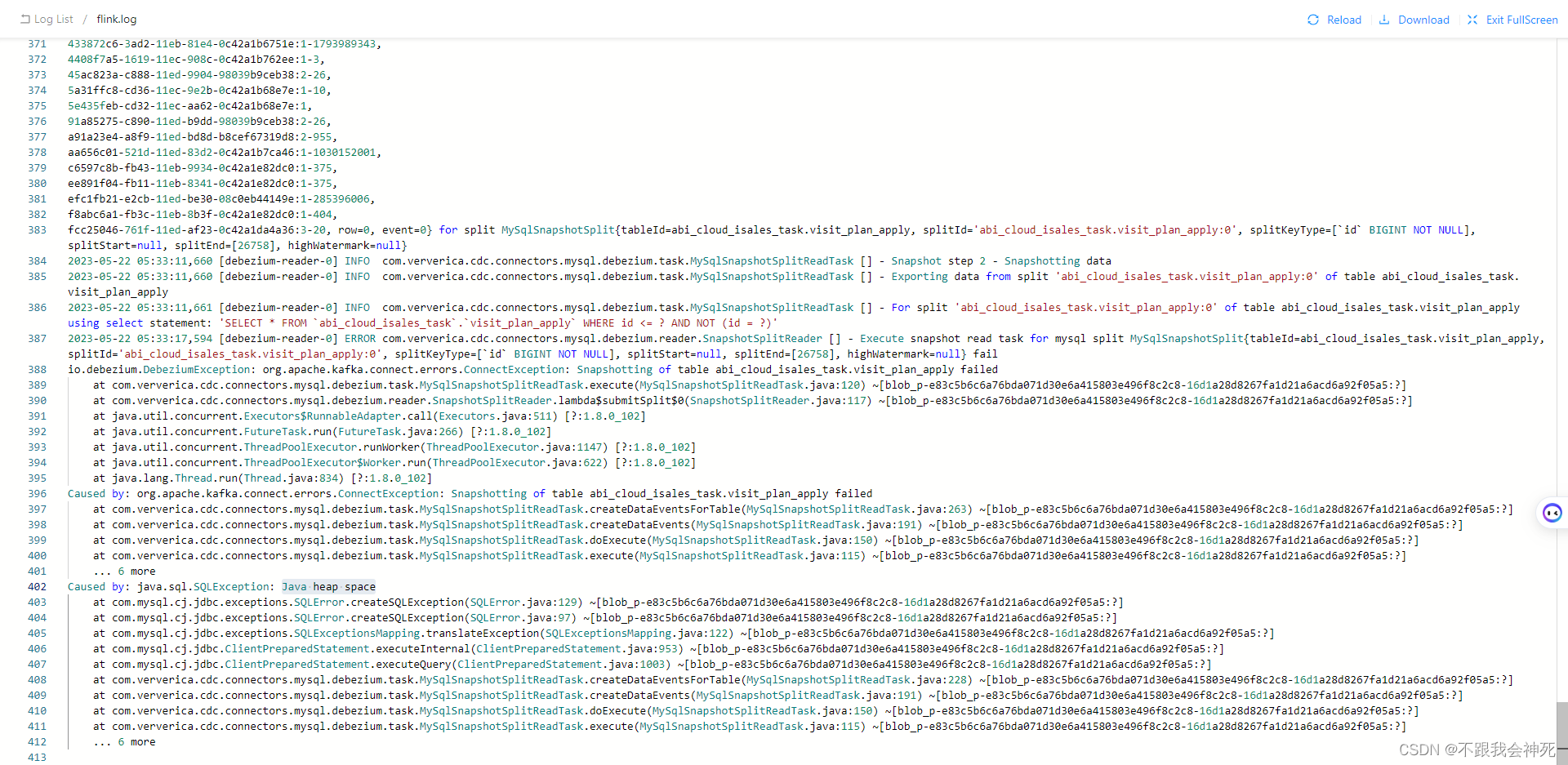
排查到这张表的单条数据非常大,有个字段时text类型,而flink cdc 拉取数据是用select *去拉取的,导致查出来的数据非常多,且这些数据全部在内存中
于是调整tm内存到16g后再次全新启动,这次就正常拉取数据了.
实际启动的时候可以根据表的相关数据计算内存应该给到多少,也可以缩小chunk的size.
chunk size = 数据因数 * 基数
基数默认是8096,这个值可以进行配置
数据因数=(主键最大值 - 最小值) / 估算的数据行数,注意,这里数据行数是用 SHOW TABLE STATUS 查出来的,取得是Rows字段















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









