







Fast RCNN比RCNN主要的优点就是速度快。
因为:在RCNN中,在region proposal的forward中,每一个候选区域都需要单独计算,而在fast中,候选区域的计算过程是共享的,可以减少很多重复的计算。另外,fast的训练过程是端到端的。
一、介绍
基础:RCNN
简单来说,RCNN使用以下四步实现目标检测:
a. 在图像中确定约1000-2000个候选框
b. 对于每个候选框内图像块,使用深度网络提取特征
c. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
d. 对于属于某一特征的候选框,用回归器进一步调整其位置
改进:Fast RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
总之,其贡献在于以下4点:
Fast RCNN的大致步骤如下:

主要步骤描述为:
- 经过多层的卷积和pooling得到一组feature map
- 通过SPP net中的ROI projection在这层feature map上找到原图的proposal对应的区域(ROI)
- 利用spatial pooling的思路,对每个ROI做pooling。具体来说就是把h×w的ROI划分为H×W个grid/sub-window,每个grid大小是h/H × w/W,在每个grid内取max。
- 把ROI pooling layer对每个ROI(对应回原图就是每个proposal)输出的H×W长的max pooling feature vector接全连接层
- 全连接层之后有两个输出层,一个softmax分类器,输出该ROI对应的proposal的object类别,一个是bounding box回归层,输出category specific bounding box
2.1 ROI pooling层
每一个 RoI 都有两个 label, 一个是类别 , 另外一个是 bounding box regression target v . Multi-task loss 定义为:
另外一部分,


2.5 小批量取样
每个mini-batch来自于N=2张图片,mini-batch size取R=128,也就是从每张图片中取64个ROIs。25%的ROIs来自于候选区域中和标注边界框有至少0.5(IoU)重叠,这些ROIs包含标记有前景对象类的示例,也就是u>=1的那些具体物体,剩下75%的ROIs取自最大IoU在[0.1,0.5)之间的候选区域,代表u=0的背景样例。训练时,图片以0.5概率采用水平翻转,不采用其他的数据增强技术。
2.6 ROI pooling层的反向传播
首先考虑普通max pooling层。设
xi
为输入层的节点,
yj
为输出层的节点。
其中判决函数 δ(i,j) 表示i节点是否被j节点选为最大值输出。不被选中有两种可能: xi 不在 yj 范围内,或者 xi 不是最大值。
对于roi max pooling,一个输入节点可能和多个输出节点相连。设
xi
为输入层的节点,
yrj
为第
r
个候选区域的第
j
个输出节点。
判决函数 δ(i,r,j) 表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于 xi 的梯度等于所有相关的后一层梯度之和。
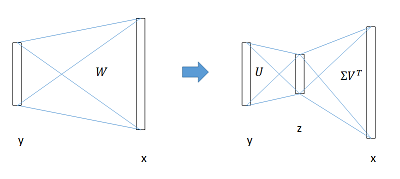
3 全连接层提速(没搞懂)
分类和位置调整都是通过全连接层(fc)实现的,设前一级数据为
x
后一级为
y
,全连接层参数为
W
,尺寸
u×v
。一次前向传播(forward)即为:
计算复杂度为 u×v 。
将
W
进行SVD分解,并用前t个特征值近似:
原来的前向传播分解成两步:
计算复杂度变为 u×t+v×t 。
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
4.实验与结论
实验过程不再详述,只记录结论
- 网络末端同步训练的分类和位置调整,提升准确度
- 使用多尺度的图像金字塔,性能几乎没有提高
- 倍增训练数据,能够有2%-3%的准确度提升
- 网络直接输出各类概率(softmax),比SVM分类器性能略好
- 更多候选窗不能提升性能















 1571
1571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









