







1. Ceph用户的权限管理及授权流程
- Ceph使用Ceph X协议对客户端进行身份的认证。
- 客户端与Mon节点的通讯均需要通过Cephx认证,可在Mon节点关闭Cephx认证,关闭认证后将允许所有访问,数据安全性无法保证。
1.1 授权流程
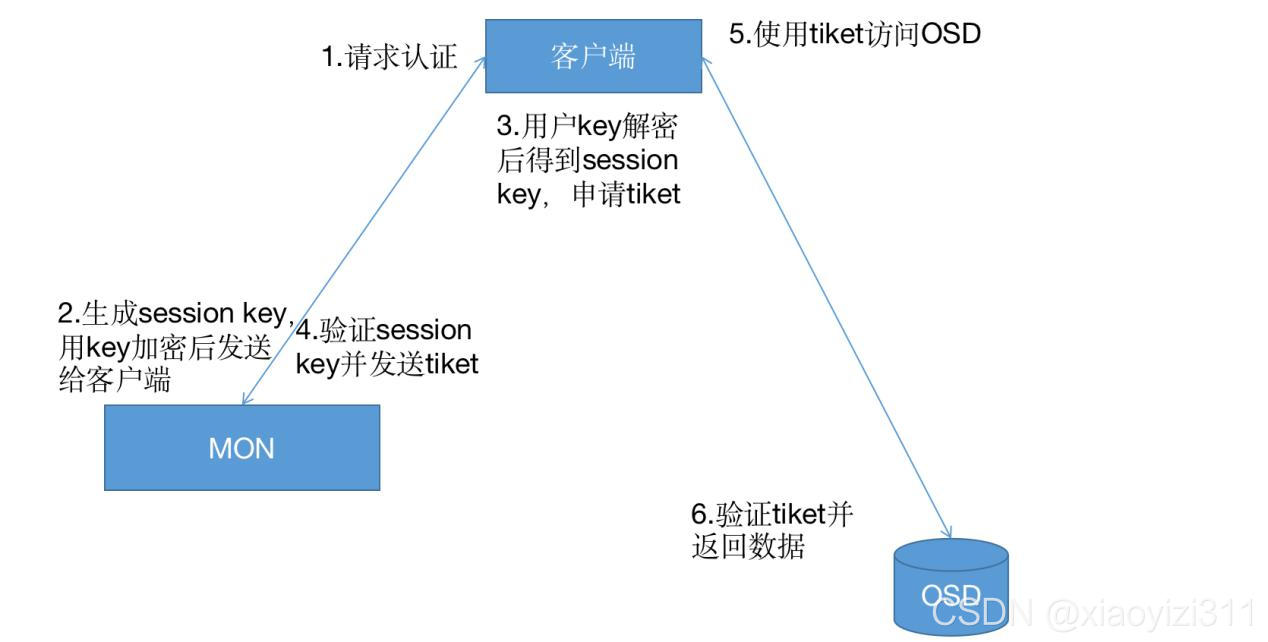
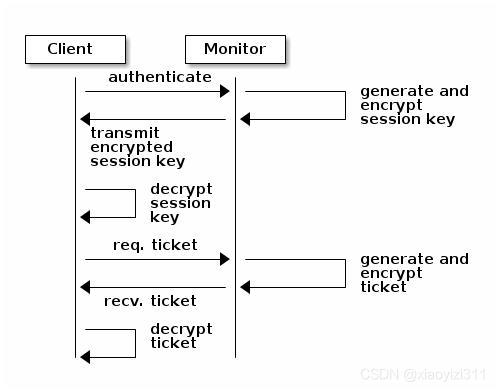
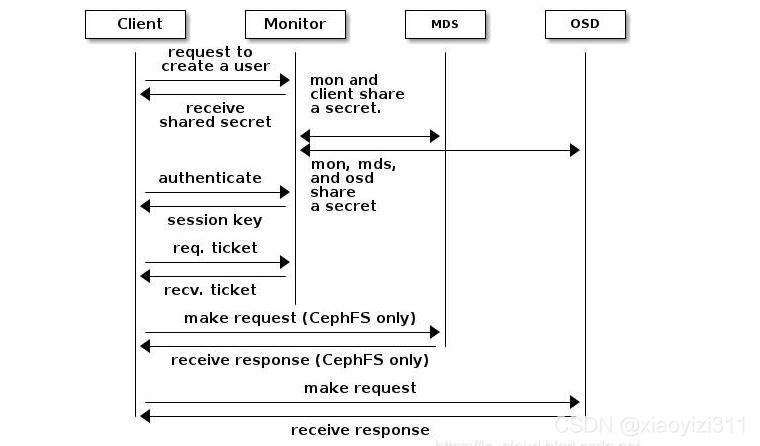
- 客户端发起认证请求到Mon节点
- Mon节点返回用户身份认证的数据结构,包括Ceph服务的Session Key,通过客户端密钥对Session Key 数据进行加密,此密钥是客户端提前配置好的,在/etc/ceph/ceph.client.admin.keyring中
- 客户端解密后得到Session Key, 向Mon端申请Ticket
- Mon端验证Session Key后,给客户端发送Ticket,此Ticket存在有效期限制
- 客户端得到Ticket后直接向OSD请求数据(Mon和OSD共享一个Secret,因此OSD会信任Mon发放的所有Ticket)
注意:
- 每个Mon节点均可以对客户端进行认证并分发密钥,因此不存在单点和性能问题
- CephX只用于Ceph的内部认证,不能扩展到Ceph以外的非Ceph组件
- Ceph只提供认证,并不能解决数据传输的加密问题。
1.2 访问流程
- Ceph将所有数据均以对象的形式存储(无论哪种类型的客户端:块设备、对象存储、文件系统)
- Ceph的用户需要有对应存储池的访问权限(rw),才能写入和读取数据
- Ceph用户必须拥有执行权限(x),才能对集群使用管理命令
1.3 Ceph用户
1.3.1 用户的查询
- 列出所有用户:
ceph@ceph_deploy:~/ceph_deploy$ ceph auth list
osd.0
key: AQA2pBthopmhJBAAgYm2VXUcyCYJWYoIVG03jA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBBpBth6ThODRAA6/TjGOox4sDMpYKVbjNmbA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQChpBthkfRNJRAAgcKnK+XJivOpZBjaepTjHA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
...
- 列出指定用户:
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.admin
[client.admin]
key = AQBTkRthqT3HFBAAySzWVXaR9QtqRkb5fTYSAQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
exported keyring for client.admin
注意:
- Type.ID 表示法:
- 例如:
- osd.0 指定osd类的ID为0的用户(节点)
- client.admin是client类型,其ID为admin
- 例如:
- 每一个项包含一个key:XXX和多个caps
- 使用 -o 选项可以将ceph auth list结果保存到文件
ceph@ceph_deploy:~/ceph_deploy$ ceph auth list -o 1.key
1.3.2 用户添加及其授权的增删改查
-
用户权限
- r:向用户授予读取权限。访问监视器(mon)以检索 CRUSH 运行图时需具有此能力。
- w:向用户授予针对对象的写入权限。
- x:授予用户调用类方法(包括读取和写入)的能力,以及在监视器中执行 auth 操作的能 力。
- *:授予用户对特定守护进程/存储池的读取、写入和执行权限,以及执行管理命令的能力
- class-read:授予用户调用类读取方法的能力,属于是 x 能力的子集。 class-write:授予用户调用类写入方法的能力,属于是 x 能力的子集。
- profile osd:授予用户以某个 OSD 身份连接到其他 OSD 或监视器的权限。授予 OSD 权限, 使 OSD 能够处理复制检测信号流量和状态报告(获取 OSD 的状态信息)。
- profile mds:授予用户以某个 MDS 身份连接到其他 MDS 或监视器的权限。
- profile bootstrap-osd:授予用户引导 OSD 的权限(初始化 OSD 并将 OSD 加入 ceph 集群),授权给部署工具,使其在引导 OSD 时有权添加密钥。
- profile bootstrap-mds:授予用户引导元数据服务器的权限,授权部署工具权限,使其在引导 元数据服务器时有权添加密钥。
-
能力
- MON 能力:
- 包括 r/w/x 和 allow profile cap(ceph 的运行图)),例如:
- mon ‘allow rwx’
- mon ‘allow profile osd’
- 包括 r/w/x 和 allow profile cap(ceph 的运行图)),例如:
- OSD 能力:
- 包括 r、w、x、class-read、class-write(类读取))和 profile osd(类写入),另外 OSD 能力还允 许进行存储池和名称空间设置。
- osd 'allow capability [pool=poolname] [namespace=namespace-name]‘
- MDS 能力:
- 只需要 allow 或空都表示允许。 mds ‘allow’
- MON 能力:
-
添加用户和对应的权限和能力
- 可以创建不具备能力的ceph用户,但只能进行身份认证,无法进行其他操作。可使用ceph auth caps 再添加能力
创建用户&生成密钥&添加能力
#创建
ceph@ceph_deploy:~/ceph_deploy$ ceph auth add client.test1 mon 'allow r' osd 'allow rwx pool=mypool'
added key for client.test1
#验证
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test1
[client.test1]
key = AQDBDyZh4BT2BxAAb7dBod/0Gvq2mseP4IV/KQ==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.test1
获取/创建用户&生成密钥&添加能力
#创建test2用户,可以使用-o 选项指定文件输出
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get-or-create client.test2 mon 'allow r' osd 'allow rwx pool=mypool'
[client.test2]
key = AQDQDyZhjme/MRAA5+nB6Rwu5Yj7Rb9r98pJKw==
#验证
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test2
[client.test2]
key = AQDQDyZhjme/MRAA5+nB6Rwu5Yj7Rb9r98pJKw==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.test2
#在次创建test2用户,因已经存在,返回用户名和对应的key
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get-or-create client.test2 mon 'allow r' osd 'allow rwx pool=mypool'
[client.test2]
key = AQDQDyZhjme/MRAA5+nB6Rwu5Yj7Rb9r98pJKw==
获取/创建用户&生成密钥&添加能力&返回key
#创建test3 用户,并返回key, 可以使用-o 选项指定文件输出
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get-or-create-key client.test3 mon 'allow r' osd 'allow rwx pool=mypool'
AQDwDyZh0TatGhAABKrvnztqUw8WKgVWyYADSQ==
- 修改用户能力
ceph@ceph_deploy:~/ceph_deploy$ ceph auth add client.test4
added key for client.test4
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test4
[client.test4]
key = AQCxEyZhNTrwMRAAwxS6e/HVblX1CQ5kononnw==
exported keyring for client.test4
ceph@ceph_deploy:~/ceph_deploy$ ceph auth caps client.test4 mon 'allow r' osd 'allow rw pool=mypool'
updated caps for client.test4
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test4
[client.test4]
key = AQCxEyZhNTrwMRAAwxS6e/HVblX1CQ5kononnw==
caps mon = "allow r"
caps osd = "allow rw pool=mypool"
exported keyring for client.test4
- 删除用户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test4
[client.test4]
key = AQCxEyZhNTrwMRAAwxS6e/HVblX1CQ5kononnw==
caps mon = "allow r"
caps osd = "allow rw pool=mypool"
exported keyring for client.test4
ceph@ceph_deploy:~/ceph_deploy$ ceph auth del client.test4
updated
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.test4
Error ENOENT: failed to find client.test4 in keyring
1.3.3 密钥环的管理
Ceph 密钥环是一个保存了secret、keys、certificates且能够让客户端通过访问ceph的keyring file(集合文件),一个keyring file可以包含一个或多个认证信息,每一个key都有一个实体名称+权限组成,形式为:{client\mon\mds\osd}.name
客户端访问ceph时会使用如下4个密钥环设置:
/etc/ceph/<$cluster name>.<user $type>.<user $id>.keyring #保存单个用户的 keyring /etc/ceph/cluster.keyring #保存多个用户的 keyring
/etc/ceph/keyring #未定义集群名称的多个用户的 keyring
/etc/ceph/keyring.bin #编译后的二进制文件
- 通过密钥环备份与恢复用户
#创建keyring文件
ceph-authool --create-keyring <File Name>
#创建密钥环文件,并对用户信息进行备份:
#创建用户:
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get-or-create client.user1 mon 'allow r' osd 'allow * pool=mypool'
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
#验证用户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.user1
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
exported keyring for client.user1
#创建keyring文件(创建出来后文件是空的)
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool --create-keyring ceph.client.user1.keyring
creating ceph.client.user1.keyring
ceph@ceph_deploy:~/ceph_deploy$ cat ceph.client.user1.keyring
#导出用户keyring到keyring文件
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.user1 -o ceph.client.user1.keyring
exported keyring for client.user1
#验证导出结果
ceph@ceph_deploy:~/ceph_deploy$ cat ceph.client.user1.keyring
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
#采用用户备份keyring,对用户及其能力进行恢复(好处是:用户被误删除后,进行恢复后key不会变化)
#验证用户的keyring文件
ceph@ceph_deploy:~/ceph_deploy$ cat ceph.client.user1.keyring
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
#模拟误删除client.user1 用户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth del client.user1
updated
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.user1
Error ENOENT: failed to find client.user1 in keyring
#使用keyring文件恢复用户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth import -i ceph.client.user1.keyring
imported keyring
#验证用户,且key没有变化
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.user1
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
exported keyring for client.user1
- 多用户密钥环
#创建keyring文件
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool --create-keyring ceph.client.user.keyring
creating ceph.client.user.keyring
#向user的keyring文件导入admin的keyring信息
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool ./ceph.client.user.keyring --import-keyring ./ceph.client.admin.keyring
importing contents of ./ceph.client.admin.keyring into ./ceph.client.user.keyring
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool -l ./ceph.client.user.keyring
#验证
[client.admin]
key = AQBTkRthqT3HFBAAySzWVXaR9QtqRkb5fTYSAQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
#再向user的keyring文件导入user1的keyring信息
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool ./ceph.client.user.keyring --import-keyring ./ceph.client.user1.keyring
importing contents of ./ceph.client.user1.keyring into ./ceph.client.user.keyring
#验证:
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool -l ./ceph.client.user.keyring
[client.admin]
key = AQBTkRthqT3HFBAAySzWVXaR9QtqRkb5fTYSAQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[client.user1]
key = AQAHGiZhOBs1DhAACNEwYJ+eV96zDJhwg3W4tQ==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
2. 使用普通用户挂载RBD和Cephfs
2.1 RBD
2.1.1 RBD基本架构

- RBD块设备类似磁盘可以被挂载
- RBD设备具有快照、多副本、克隆和一致性等特性
- 数据以条带化的形式存储在Ceph集群的多个OSD中
- 条带化就是一种自动将IO的负载均衡到多个物理磁盘上
- 是将一块连续的数据分成很多小部分并把其分别存储到不同磁盘上
- 使多个进程同时访问数据的多个不同部分,且不会造成磁盘冲突
- 在需要对数据进行顺序访问的时候获得最大程度的IO并行能力
2.1.3 创建RBD的存储池
#创建存储池
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool create rbd-data 32 32
pool 'rbd-data' created
#验证存储池
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool ls
device_health_metrics
testpool
mypool
rbd-data
#启用存储池的rbd
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool application enable rbd-data rbd
enabled application 'rbd' on pool 'rbd-data'
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool application --help
osd pool application enable <pool> <app> [--yes-i-really-mean-it] enable use of an application <app> [cephfs,rbd,rgw] on pool <poolname>
#初始化rbd
ceph@ceph_deploy:~/ceph_deploy$ rbd pool init -p rbd-data
2.1.3 创建img镜像
#命令格式
ceph@ceph_deploy:~/ceph_deploy$ rbd help create
usage: rbd create [--pool <pool>] [--namespace <namespace>] [--image <image>]
[--image-format <image-format>] [--new-format]
[--order <order>] [--object-size <object-size>]
[--image-feature <image-feature>] [--image-shared]
[--stripe-unit <stripe-unit>]
[--stripe-count <stripe-count>] [--data-pool <data-pool>]
[--mirror-image-mode <mirror-image-mode>]
[--journal-splay-width <journal-splay-width>]
[--journal-object-size <journal-object-size>]
[--journal-pool <journal-pool>]
[--thick-provision] --size <size> [--no-progress]
<image-spec>
Create an empty image.
Positional arguments
<image-spec> image specification
(example: [<pool-name>/[<namespace>/]]<image-name>)
Optional arguments
-p [ --pool ] arg pool name
--namespace arg namespace name
--image arg image name
--image-format arg image format [default: 2]
--object-size arg object size in B/K/M [4K <= object size <= 32M]
--image-feature arg image features
[layering(+), exclusive-lock(+*), object-map(+*),
deep-flatten(+-), journaling(*)]
--image-shared shared image
--stripe-unit arg stripe unit in B/K/M
--stripe-count arg stripe count
--data-pool arg data pool
--mirror-image-mode arg mirror image mode [journal or snapshot]
--journal-splay-width arg number of active journal objects
--journal-object-size arg size of journal objects [4K <= size <= 64M]
--journal-pool arg pool for journal objects
--thick-provision fully allocate storage and zero image
-s [ --size ] arg image size (in M/G/T) [default: M]
--no-progress disable progress output
Image Features:
(*) supports enabling/disabling on existing images
(-) supports disabling-only on existing images
(+) enabled by default for new images if features not specified
#创建两个镜像
ceph@ceph_deploy:~/ceph_deploy$ rbd create data-img1 --size 3G --pool rbd-data --image-format 2 --image-feature layering
ceph@ceph_deploy:~/ceph_deploy$ rbd create data-img2 --size 5G --pool rbd-data --image-format 2 --image-feature layering
#验证镜像
ceph@ceph_deploy:~/ceph_deploy$ rbd ls --pool rbd-data
data-img1
data-img2
#列出镜像多个信息
ceph@ceph_deploy:~/ceph_deploy$ rbd ls --pool rbd-data -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2
data-img2 5 GiB 2
#查看镜像详细信息
ceph@ceph_deploy:~/ceph_deploy$ rbd --image data-img2 --pool rbd-data info
rbd image 'data-img2':
size 5 GiB in 1280 objects
order 22 (4 MiB objects) #对象大小,每个对象是 2^22/1024/1024=4MiB
snapshot_count: 0
id: 1c11621d1febe #镜像id
block_name_prefix: rbd_data.1c11621d1febe #size 里面的1280个对象名称前缀
format: 2 #镜像文件格式版本
features: layering #特性,layering 支持分层快照以写时复制
op_features:
flags:
create_timestamp: Wed Aug 25 22:57:56 2021
access_timestamp: Wed Aug 25 22:57:56 2021
modify_timestamp: Wed Aug 25 22:57:56 2021
#以json格式显示镜像信息
ceph@ceph_deploy:~/ceph_deploy$ rbd ls --pool rbd-data -l --format json --pretty-format
[
{
"image": "data-img1",
"id": "1bef8758b1e29",
"size": 3221225472,
"format": 2
},
{
"image": "data-img2",
"id": "1c11621d1febe",
"size": 5368709120,
"format": 2
}
]
#镜像的其它特性
ceph@ceph_deploy:~/ceph_deploy$ rbd help feature enable
usage: rbd feature enable [--pool <pool>] [--namespace <namespace>]
[--image <image>]
[--journal-splay-width <journal-splay-width>]
[--journal-object-size <journal-object-size>]
[--journal-pool <journal-pool>]
<image-spec> <features> [<features> ...]
Enable the specified image feature.
Positional arguments
<image-spec> image specification
(example: [<pool-name>/[<namespace>/]]<image-name>)
<features> image features
[exclusive-lock, object-map, journaling]
Optional arguments
-p [ --pool ] arg pool name
--namespace arg namespace name
--image arg image name
--journal-splay-width arg number of active journal objects
--journal-object-size arg size of journal objects [4K <= size <= 64M]
--journal-pool arg pool for journal objects
#特性简介
layering: 支持镜像分层快照特性,用于快照及写时复制,可以对 image 创建快照并保护,然 后从快照克隆出新的 image 出来,父子 image 之间采用 COW 技术,共享对象数据。
striping: 支持条带化 v2,类似 raid 0,只不过在 ceph 环境中的数据被分散到不同的对象中, 可改善顺序读写场景较多情况下的性能。
exclusive-lock: 支持独占锁,限制一个镜像只能被一个客户端使用。
object-map: 支持对象映射(依赖 exclusive-lock),加速数据导入导出及已用空间统计等,此特 性开启的时候,会记录 image 所有对象的一个位图,用以标记对象是否真的存在,在一些场 景下可以加速 io。
fast-diff: 快速计算镜像与快照数据差异对比(依赖 object-map)。 deep-flatten: 支持快照扁平化操作,用于快照管理时解决快照依赖关系等。
journaling: 修改数据是否记录日志,该特性可以通过记录日志并通过日志恢复数据(依赖独 占锁),开启此特性会增加系统磁盘 IO 使用。
jewel 默认开启的特性包括: layering/exlcusive lock/object map/fast diff/deep flatten
#启用特定存储池中的指定镜像特性
ceph@ceph_deploy:~/ceph_deploy$ rbd feature enable exclusive-lock --pool rbd-data --image data-img1
ceph@ceph_deploy:~/ceph_deploy$ rbd feature enable object-map --pool rbd-data --image data-img1
ceph@ceph_deploy:~/ceph_deploy$ rbd feature enable fast-diff --pool rbd-data --image data-img1
rbd: failed to update image features: (22) Invalid argument
2021-08-25T23:06:52.809+0800 7f1005f8c1c0 -1 librbd::Operations: one or more requested features are already enabled
#验证镜像特性
ceph@ceph_deploy:~/ceph_deploy$ rbd --image data-img1 --pool rbd-data info
rbd image 'data-img1':
size 3 GiB in 768 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1bef8758b1e29
block_name_prefix: rbd_data.1bef8758b1e29
format: 2
features: layering, exclusive-lock, object-map, fast-diff
#禁用镜像特性
ceph@ceph_deploy:~/ceph_deploy$ rbd feature disable fast-diff --pool rbd-data --image data-img1
#验证
ceph@ceph_deploy:~/ceph_deploy$ rbd --image data-img1 --pool rbd-data info
rbd image 'data-img1':
size 3 GiB in 768 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1bef8758b1e29
block_name_prefix: rbd_data.1bef8758b1e29
format: 2
features: layering, exclusive-lock
op_features:
flags:
create_timestamp: Wed Aug 25 22:57:31 2021
access_timestamp: Wed Aug 25 22:57:31 2021
modify_timestamp: Wed Aug 25 22:57:31 2021
op_features:
flags: object map invalid, fast diff invalid
create_timestamp: Wed Aug 25 22:57:31 2021
access_timestamp: Wed Aug 25 22:57:31 2021
modify_timestamp: Wed Aug 25 22:57:31 2021
2.1.4使用普通用户挂载RBD
#创建普通用户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth add client.rbduser mon 'allow r' osd 'allow rwx pool=rbd-data'
added key for client.rbduser
#验证用户信息
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.rbduser
[client.rbduser]
key = AQD3ZiZhEQNUMRAAjTQomqQKfeFbq40997mkxQ==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data"
exported keyring for client.rbduser
#创建keyring文件
ceph@ceph_deploy:~/ceph_deploy$ ceph-authtool --create-keyring ceph.client.rbduser.keyring
creating ceph.client.rbduser.keyring
#导出用户keyring
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.rbduser -o ceph.client.rbduser.keyring
exported keyring for client.rbduser
#验证用户的keyring文件
ceph@ceph_deploy:~/ceph_deploy$ cat ceph.client.rbduser.keyring
[client.rbduser]
key = AQD3ZiZhEQNUMRAAjTQomqQKfeFbq40997mkxQ==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data"
#安装ceph客户端
Ubuntu:
~# wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
~# vim /etc/apt/sources.list
~# apt install ceph-common
Centos:
[root@client ~]# yum install epel-release
[root@client ~]# yum https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
[root@client ~]# yum install ceph-common
#同步普通用户认证文件
ceph@ceph_deploy:~/ceph_deploy$ scp ceph.conf ceph.client.rbduser.keyring root@192.168.6.74:/etc/ceph
#在客户端验证权限
ceph --user rbduser -s
#映射rbd
rbd --user rbduser -p rbd-data map data-img1
#格式化并使用rbd镜像
mkfs.ext4 /dev/rbd0
#管理端验证镜像状态
ceph@ceph_deploy:~$ rbd ls -p rbd-data -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2 excl #施加锁文件,已经被客户端映射
data-img2 5 GiB 2
#验证ceph内核模块
Ubuntu:
root@client:/rbd# lsmod | grep ceph
libceph 315392 1 rbd
libcrc32c 16384 3 xfs,raid456,libceph
Centos:
[root@client ~]# lsmod | grep ceph
libceph 306750 1 rbd
dns_resolver 13140 1 libceph
libcrc32c 12644 2 xfs,libceph
#rbd镜像空间拉伸
ceph@ceph_deploy:~$ rbd ls -p rbd-data -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2 excl
data-img2 5 GiB 2
ceph@ceph_deploy:~$ rbd resize --pool rbd-data --image data-img1 --size 8G
Resizing image: 100% complete...done.
ceph@ceph_deploy:~$ rbd ls -p rbd-data -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 8 GiB 2
data-img2 5 GiB 2
ceph@ceph_deploy:~$ rbd help resize
usage: rbd resize [--pool <pool>] [--namespace <namespace>]
[--image <image>] --size <size> [--allow-shrink]
[--no-progress]
<image-spec>
Resize (expand or shrink) image.
Positional arguments
<image-spec> image specification
(example: [<pool-name>/[<namespace>/]]<image-name>)
Optional arguments
-p [ --pool ] arg pool name
--namespace arg namespace name
--image arg image name
-s [ --size ] arg image size (in M/G/T) [default: M]
--allow-shrink permit shrinking
--no-progress disable progress output
#开机自动挂载
~#vim /etc/rc.d/rc.local
rbd --user rbduser -p rbd-data map data-img1
~#mount /dev/rbd0 /data
~#chmod a+x /etc/rc.d/rc.local
#查看映射
~#rbd showmapped
id pool image snap device
0 rbd-data data-img1 - /dev/rbd0
#卸载rbd镜像
~# umount /rbd
~# rbd --user rbduser -p rbd-data unmap data-img1
#删除rbd镜像
~# rbd rm --pool rbd-data --image data-img1 #慎用
#rbd 镜像回收机制
ceph@ceph_deploy:~$ rbd help trash
trash list (trash ls) List trash images.
trash move (trash mv) Move an image to the trash.
trash purge Remove all expired images from trash.
trash purge schedule add Add trash purge schedule.
trash purge schedule list (... ls)
List trash purge schedule.
trash purge schedule remove (... rm)
Remove trash purge schedule.
trash purge schedule status Show trash purge schedule status.
trash remove (trash rm) Remove an image from trash.
trash restore Restore an image from trash.
ceph@ceph_deploy:~$ rbd status --pool rbd-data --image data-img1 #查看镜像状态
ceph@ceph_deploy:~$ rbd trash move --pool rbd-data --image data-img1 #移动到回收站
ceph@ceph_deploy:~$ rbd trash list --pool rbd-data #查看回收站镜像
1bef8758b1e29 data-img1
ceph@ceph_deploy:~$ rbd trash restore --pool rbd-data --image data-img1 --image-id 1bef8758b1e29 #还原镜像
ceph@ceph_deploy:~$ rbd ls --pool rbd-data -l #验证镜像
NAME SIZE PARENT FMT PROT LOCK
data-img1 8 GiB 2
data-img2 5 GiB 2
#镜像快照
ceph@ceph_deploy:~$ rbd help snap create
usage: rbd snap create [--pool <pool>] [--namespace <namespace>]
[--image <image>] [--snap <snap>] [--skip-quiesce]
[--ignore-quiesce-error] [--no-progress]
<snap-spec>
ceph@ceph_deploy:~$ rbd snap create --pool rbd-data --image data-img1 --snap img1-snap-1 #创建快照
Creating snap: 100% complete...done.
ceph@ceph_deploy:~$ rbd snap list --pool rbd-data --image data-img1 #验证快照
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 img1-snap-1 8 GiB Thu Aug 26 10:20:30 2021
ceph@ceph_deploy:~$ rbd help snap rollback
usage: rbd snap rollback [--pool <pool>] [--namespace <namespace>]
[--image <image>] [--snap <snap>] [--no-progress]
<snap-spec>
ceph@ceph_deploy:~$ rbd snap rollback --pool rbd-data --image data-img1 --snap img1-snap-1 #回滚快照
Rolling back to snapshot: 100% complete...done.
ceph@ceph_deploy:~$ rbd snap remove --pool rbd-data --image data-img1 --snap img1-snap-1 #删除快照
Removing snap: 100% complete...done.
ceph@ceph_deploy:~$ rbd snap limit set --pool rbd-data --image data-img1 --limit 30
#设置快照数量
ceph@ceph_deploy:~$ rbd snap limit clear --pool rbd-data --image data-img1
#清除快照数量限制
2.2 CephFS
2.2.1 Cephfs的基本架构
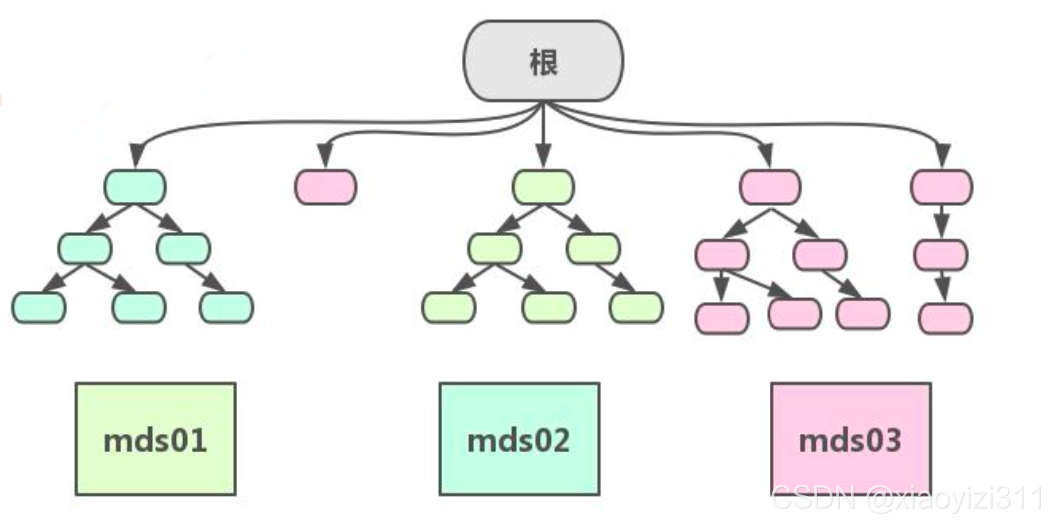
Cephfs的元数据使用动态子树分区,把元数据划分名称空间对应到不同的mds,写入元数据的时候,将元数据按照名称保存到不同的mds上,类似nginx 中的缓存目录分层一样。
http://docs.ceph.org.cn/cephfs/
2.2.2 部署MDS服务
#MDS节点
Ubuntu
root@ceph_mgr1:~# apt-cache madison ceph-mds
root@ceph_mgr1:~# apt install ceph-mds
CentOS:
~# yum install ceph-mds
#Deploy上部署MDS
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mds create ceph_mgr1
2.2.3 创建Cephfs Metadata和Data存储池
使用Cephfs要先创建元数据和数据相关的存储池
#保存metadata的pool
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool create cephfs-metadata 32 32
pool 'cephfs-metadata' created
#保存数据的pool
ceph@ceph_deploy:~/ceph_deploy$ ceph osd pool create cephfs-data 64 64
pool 'cephfs-data' created
#创建Cephfs
ceph@ceph_deploy:~/ceph_deploy$ ceph fs new mycephfs cephfs-metadata cephfs-data
new fs with metadata pool 5 and data pool 6
#查看Cephfs状态
ceph@ceph_deploy:~/ceph_deploy$ ceph mds stat
mycephfs:1 {0=ceph_mgr1=up:active}
ceph@ceph_deploy:~/ceph_deploy$ ceph fs ls
name: mycephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
ceph@ceph_deploy:~/ceph_deploy$ ceph fs status mycephfs
mycephfs - 0 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph_mgr1 Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 96.0k 502G
cephfs-data data 0 502G
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
2.2.4 普通用户使用Cephfs
#创建账户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth add client.mdsuser mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data'
added key for client.mdsuser
#验证账户
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.mdsuser
[client.mdsuser]
key = AQD7AidhYwkjCRAA1OxEH/M0RBd8c++25lfS7g==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
exported keyring for client.mdsuser
#创建keyring文件
ceph@ceph_deploy:~/ceph_deploy$ ceph auth get client.mdsuser -o ceph.client.mdsuser.keyring
exported keyring for client.mdsuser
#导出key,并传到client端
ceph@ceph_deploy:~/ceph_deploy$ ceph auth print-key client.mdsuser > mdsuser.key
ceph@ceph_deploy:~/ceph_deploy$ scp ceph.client.mdsuser.keyring mdsuser.key root@192.168.6.74:/etc/ceph
#通过keyring文件挂载
mount -t ceph 192.168.204.14:6789:,192.168.204.15:6789:,192.168.204.16:6789:/ /mds -o name=mdsuser,secretfile=/etc/ceph/mdsuser.key
#通过key挂载
mount -t ceph 192.168.204.14:6789:,192.168.204.15:6789:,192.168.204.16:6789:/ /mds -o name=mdsuser,secret=AQD7AidhYwkjCRAA1OxEH/M0RBd8c++25lfS7g==
#挂载点状态
root@client:/mds# stat -f /mds
File: "/mds"
ID: 27791b19ec21d1e3 Namelen: 255 Type: ceph
Block size: 4194304 Fundamental block size: 4194304
Blocks: Total: 128555 Free: 128555 Available: 128555
Inodes: Total: 0 Free: -1
#开机自动挂载
root@client:/mds# cat /etc/fstab
192.168.204.14:6789:,192.168.204.15:6789:,192.168.204.16:6789:/ /mds ceph defaults,name=mdsuser,secretfile=/etc/ceph/mdsuser.key,_netdev 0 0
#用户空间挂载ceph-fs,需安装ceph-fuse,性能较差
3. Ceph MDS 高可用设置
https://docs.ceph.com/en/latest/cephfs/add-remove-mds/
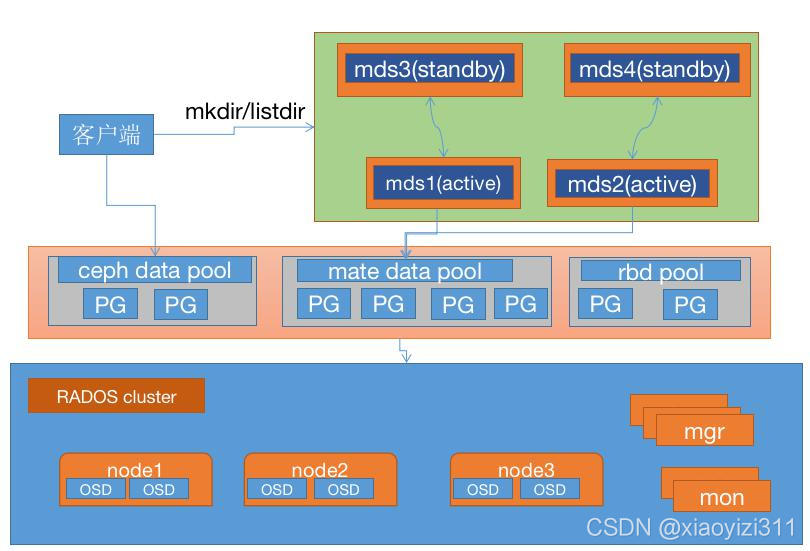
Ceph mds(etadata service)作为 ceph 的访问入口,需要实现高性能及数据备份,假设启动 4 个 MDS 进程,设置 2 个 Rank。这时候有 2 个 MDS 进程会分配给两个 Rank,还剩下 2 个 MDS 进程分别作为另外个的备份。
设置每个 Rank 的备份 MDS,也就是如果此 Rank 当前的 MDS 出现问题马上切换到另个 MDS。 设置备份的方法有很多,常用选项如下:
- mds_standby_replay:值为 true 或 false,true 表示开启 replay 模式,这种模式下主 MDS 内 的数量将实时与从 MDS 同步,如果主宕机,从可以快速的切换。如果为 false 只有宕机的时 候才去同步数据,这样会有一段时间的中断。
- mds_standby_for_name:设置当前 MDS 进程只用于备份于指定名称的 MDS。 mds_standby_for_rank:设置当前 MDS 进程只用于备份于哪个 Rank,通常为 Rank 编号。另 外在存在之个 CephFS 文件系统中,还可以使用 mds_standby_for_fscid 参数来为指定不同的 文件系统。
- mds_standby_for_fscid:指定 CephFS 文件系统 ID,需要联合 mds_standby_for_rank 生效,如 果设置 mds_standby_for_rank,那么就是用于指定文件系统的指定 Rank,如果没有设置,就是指定文件系统的所有 Rank。
3.1 多MDS Active 设置
#当前mds服务器状态
ceph@ceph_deploy:~/ceph_deploy$ ceph mds stat
mycephfs:1 {0=ceph_mgr1=up:active}
#mds服务器安装ceph-mds
root@ceph_mgr2:~# apt install -y ceph-mds
root@ceph_mon2:~# apt install -y ceph-mds
root@ceph_mon3:~# apt install -y ceph-mds
#添加mds服务器
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mds create ceph_mgr2
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mds create ceph_mon2
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy mds create ceph_mon3
#验证mds服务器状态
ceph@ceph_deploy:~/ceph_deploy$ ceph mds stat
mycephfs:1 {0=ceph_mgr1=up:active} 3 up:standby
ceph@ceph_deploy:~/ceph_deploy$ ceph fs status
mycephfs - 1 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph_mgr1 Reqs: 0 /s 10 13 12 1
POOL TYPE USED AVAIL
cephfs-metadata metadata 96.0k 502G
cephfs-data data 0 502G
STANDBY MDS
ceph_mgr2
ceph_mon2
ceph_mon3
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
#当前文件系统状态
ceph@ceph_deploy:~/ceph_deploy$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 4
flags 12
created 2021-08-26T10:42:34.023541+0800
modified 2021-08-26T10:42:35.029398+0800
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 0
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=124222}
failed
damaged
stopped
data_pools [6]
metadata_pool 5
inline_data disabled
balancer
standby_count_wanted 1
[mds.ceph_mgr1{0:124222} state up:active seq 28 addr [v2:192.168.204.19:6802/425543626,v1:192.168.204.19:6803/425543626]]
#设置处于激活状态mds数量
目前有四个 mds 服务器,但是有一个主三个备,可以优化一下部署架构,设置为为两主两备。
ceph@ceph_deploy:~/ceph_deploy$ ceph fs set mycephfs max_mds 2 #设置同时活跃的主mds最大值为2
ceph@ceph_deploy:~/ceph_deploy$ ceph fs status
mycephfs - 1 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph_mgr1 Reqs: 0 /s 10 13 12 1
1 active ceph_mon3 Reqs: 0 /s 10 12 11 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 96.0k 502G
cephfs-data data 0 502G
STANDBY MDS
ceph_mgr2
ceph_mon2
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
3.2 多MDS Active 对应Standby设置
根据目前状态,设置standby节点为指定active节点的备份
#修改配置文件
ceph@ceph_deploy:~/ceph_deploy$ vim ceph.conf
[global]
fsid = 8fa8e277-a409-42ef-96b3-9b5047d86303
public_network = 192.168.204.0/24
cluster_network = 192.168.6.0/24
mon_initial_members = ceph_mon1
mon_host = 192.168.204.14
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon_max_pg_per_osd = 300
mon clock drift allowed = 2
mon clock drift warn backoff = 30
[mds.ceph_mon3]
#mds_standby_for_fscid = mycephfs
mds_standby_for_name = ceph_mon2
mds_standby_replay = true
[mds.ceph_mgr2]
mds_standby_for_name = ceph_mgr1
mds_standby_replay = true
#分发配置文件并重启ceph-mds服务
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy --overwrite-conf config push ceph_mgr1
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy --overwrite-conf config push ceph_mgr2
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy --overwrite-conf config push ceph_mon2
ceph@ceph_deploy:~/ceph_deploy$ ceph-deploy --overwrite-conf config push ceph_mon3
systemctl restart ceph-mds@ceph_mgr1
systemctl restart ceph-mds@ceph_mgr2
systemctl restart ceph-mds@ceph_mon2
systemctl restart ceph-mds@ceph_mon3
#检查集群高可用状态
ceph@ceph_deploy:~/ceph_deploy$ ceph fs status
mycephfs - 1 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph_mgr2 Reqs: 0 /s 11 14 12 1
1 active ceph_mon3 Reqs: 0 /s 10 13 11 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 283k 502G
cephfs-data data 0 502G
STANDBY MDS
ceph_mgr1
ceph_mon2
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)

















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









