









信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度。给定包含关于某个目标概念的正反样例的样例集S,那么S相对于这个布尔型分类的熵为:
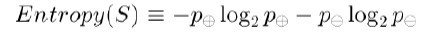
其中,p+代表正样例,比如p+则意味着去打羽毛球,而p-则代表反样例,不去打球。
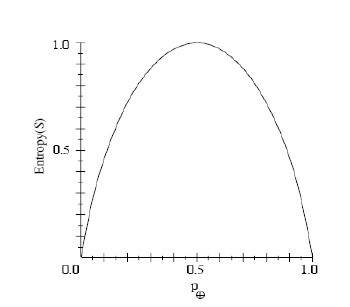
注意:如果S的所有成员属于同一类,那么S的熵为0;如果集合中正反样例的数量相等时,熵为1;如果集合中正反样例的数量不等时,熵介于0和1之间。如下图所示:
相关代码实现:
//根据具体属性和值来计算熵 double ComputeEntropy(vector <vector <string> > remain_state, string attribute, string value,bool ifparent){ vector<int> count (2,0); unsigned int i,j; bool done_flag = false;//哨兵值 for(j = 1; j < MAXLEN; j++){ if(done_flag) break; if(!attribute_row[j].compare(attribute)){ for(i = 1; i < remain_state.size(); i++){ if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent记录是否算父节点 if(!remain_state[i][MAXLEN - 1].compare(yes)){ count[0]++; } else count[1]++; } } done_flag = true; } } if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正实例或者负实例 //具体计算熵 根据[+count[0],-count[1]],log2为底通过换底公式换成自然数底数 double sum = count[0] + count[1]; double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0); return entropy; }
举例来说,假设S是一个关于布尔概念的有14个样例的集合,它包括9个正例和5个反例(我们采用记号[9+,5-]来概括这样的数据样例),那么S相对于这个布尔样例的熵为:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
在信息论中熵的另一种解释是,熵确定了要编码集合S中任意成员的分类所需要的最少二进制位数。例如:如果p+是1,接受者知道抽出的样例比为正,所以不必发任何消息,此时的熵为0。另一方面,如果p+是0.5,必须用一个二进制位来说明抽出的样例是正还是负。如果p+是0.8,那么对所需的消息编码方法时赋予正例集合较短的编码,可能性较小的反例集合较长的编码,平均每条消息的编码少于1个二进制位。
一般地,如果目标属性具有c个不同的值,那么S相对于c个状态的分类熵为:
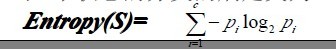
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望,个人结合前面理解,总结为用来衡量给定的属性区分训练样例的能力)。更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:

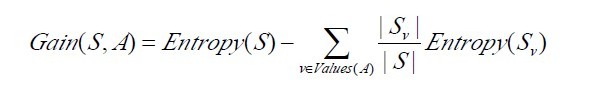


通过以上的计算,相对于目标,Humidity比Wind有更大的信息增益
下图仍摘取自《机器学习》 是ID3第一步后形成的部分决策树 其中经比较OutLook的信息增益最大 选作root

上图中分支Overcast的所有样例都是正例,所以成为目标分类为Yes的叶结点。另两个结点将被进一步展开,方法是按照新的样例子集选取信息增益最高的属性。















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









