









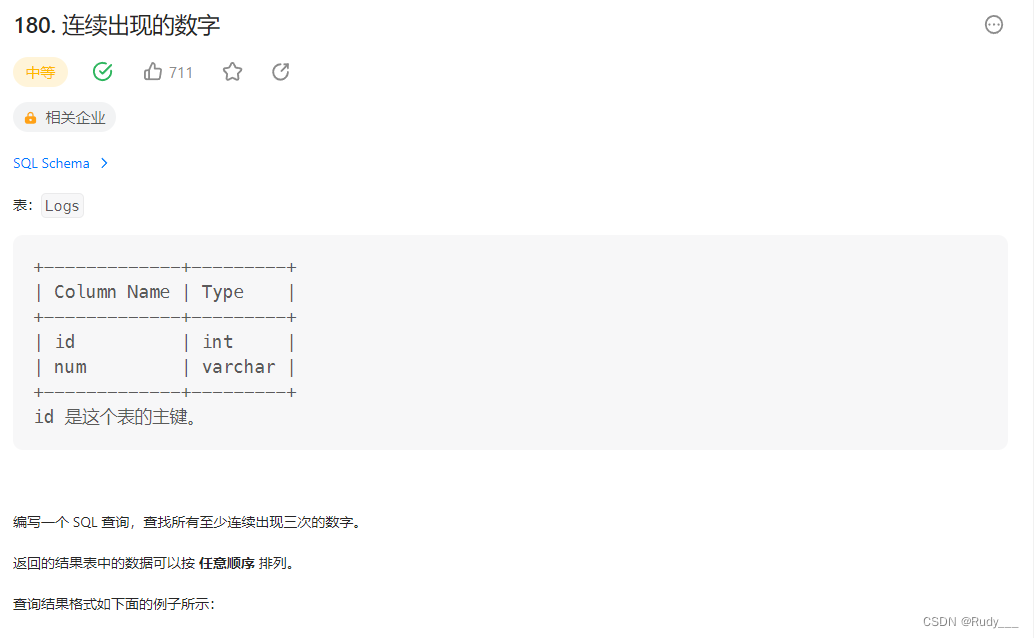
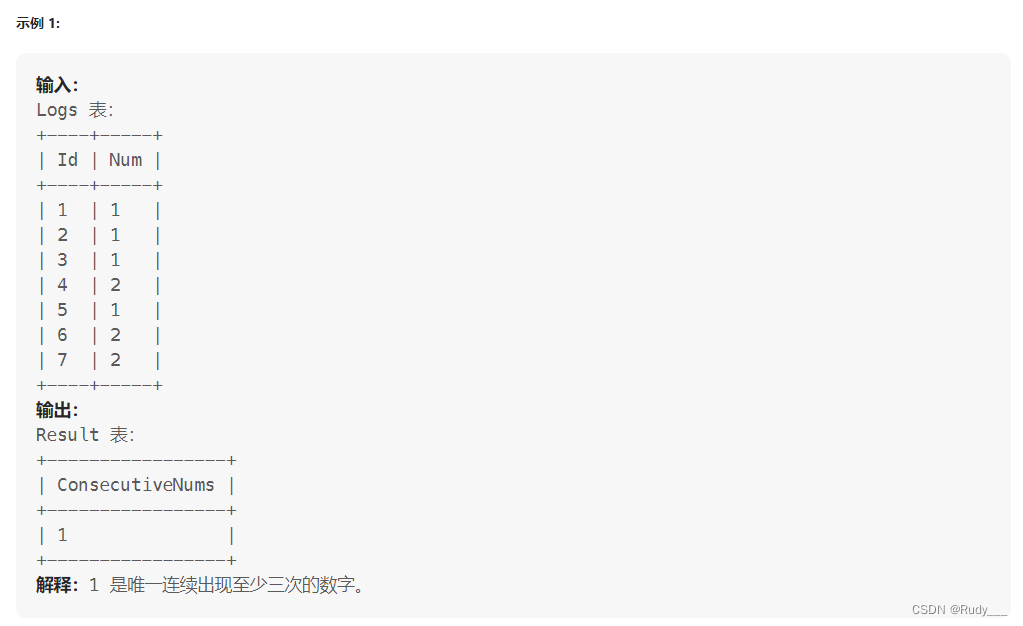
方法一:暴力(三表连接)
select distinct l1.Num as ConsecutiveNums
from
Logs l1,
Logs l2,
Logs l3
where l1.Num = l2.Num
and l2.Num = l3.Num
and l1.Id = l2.Id - 1
and l2.Id = l3.Id - 1;
方法二:窗口函数
请看大佬写的 [SQL SERVER 解法]
select distinct Num as ConsecutiveNums
from(
select Num, COUNT(1) as SerialCount
from(
select Id, Num,
row_number() over(order by id) - row_number() over(partition by Num order by Id) as SerialNumberSubGroup
from Logs
) as Sub
group by Num, SerialNumberSubGroup
having COUNT(1) >= 3
) as Result
常用的用于排序的窗口函数
(我的理解:窗口函数,即,额外加一列字段,用于标记排序的序号)
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
窗口函数1:row_number() over() 分组排序
函数详细例子请看ROW_NUMBER() OVER()函数用法详解 (分组排序 例子多)
语法格式:
row_number() over(partition by 分组列 order by 排序列 desc)
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
窗口函数2:rank() over() 分组排序
窗口函数3:dense_rank() over() 分组排序
区别(row_number函数、rank函数、dense_rank函数)
如果有并列名次的行,例如,两人并列第一,
row_number函数:不考虑并列名次的情况。(随机将并列第一的其中一人标记为1,另一个并列第一的人标记为2)即,标记数字是没重复的,也没缺少的。排名是正常的1,2,3,4,…
rank函数:严格意义上的排序,(并列第一的都标记为1,就没有标记为2的人了,再往后一名就被标记为3)即,标记数字有可能有重复的,也有可能有缺少的。排名为:1,1,3,4,…
dense_rank函数:顾名思义,比rank函数更紧密了些。(并列第一的都标记为1,再后一名就被标记为2)即,标记数字有可能有重复的,但一定没有缺少的。排名为:1,1,2,3,4,…
参考链接:
https://leetcode.cn/problems/consecutive-numbers/solutions/21537/sql-server-jie-fa-by-neilsons/
http://t.csdn.cn/Oqu6u
https://www.zhihu.com/tardis/zm/art/92654574?source_id=1005















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









