









Pandas高级数据分析快速入门之一——Python开发环境篇
Pandas高级数据分析快速入门之二——基础篇
Pandas高级数据分析快速入门之三——数据挖掘与统计分析篇
Pandas高级数据分析快速入门之四——数据可视化篇
Pandas高级数据分析快速入门之五——机器学习特征工程篇
Pandas高级数据分析快速入门之六——机器学习预测分析篇
0. 前言
Pandas高级数据分析的数据挖掘过程与传统的统计分析相似,也就是从数据源提取、扩展特征,形成新的统计表,更高级、科学的方面包括:
- 大数据全样本
- 使用机器学习技术增强特征
- 数据分析方法更丰富,例如相关性、相似性、趋势、聚类等等
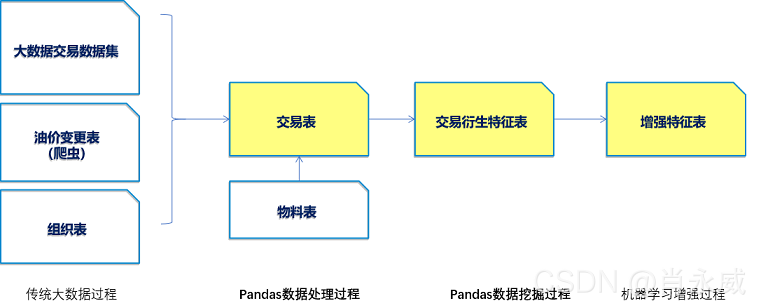
本文重点在Pandas数据处理过程和Pandas数据挖掘过程。通过挖掘、统计分析客户加油交易行为,形成客户画像。
1. 原数据挖掘——交易明细
客户给车辆加油时一种持续、周期性较强的交易行为。如下图所示加油消费时序过程。
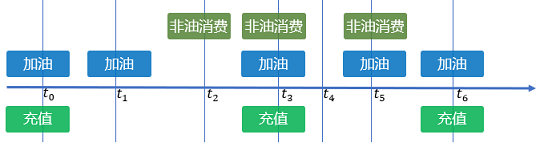
客户在加油站加油,及非油消费,在数据层面的体现为客户)、交易时间、交易地点(略)、交易物品(油、非油)、油价、加油量、消费金额、充值金额等信息。

上表中数据项定义如下所示:

1.1. 读取原数据
import pandas as pd
import datetime
import numpy as np
cols_name = ['carduser_id','occurday','balance','recharge','volumn','all_oils','all_goods',
'discount','goods_id','DIM_DATE','END_DATE','ZDE_92']
df = pd.read_csv('trade.csv',usecols=cols_name,encoding='utf_8_sig')
print(df)
carduser_id occurday balance recharge volumn all_oils all_goods discount goods_id DIM_DATE END_DATE ZDE_92
0 1313943 2019/1/3 42799 0 0 0 -20000 0 100016.0 2018/12/15 2019/2/14 -0.10
1 1313943 2019/1/9 22799 0 3101 -20000 0 0 102546.0 2018/12/15 2019/2/14 -0.10
2 1313943 2019/1/19 0 0 3654 -22799 0 0 102546.0 2018/12/15 2019/2/14 -0.10
3 1313943 2019/4/26 4000 40600 5229 -36600 0 0 102546.0 2019/4/13 2019/4/26 -0.05
4 1313943 2019/6/30 0 22800 3459 -22000 -4800 0 102546.0 2019/6/27 2019/7/9 -0.10
... ... ... ... ... ... ... ... ... ... ... ... ...
1.2. 时序数据挖掘
对于数据表中的时间数据(例如:2019/1/3),Pandas能取到年、月、年月、日、时、分、秒、季节、周、节假日、两日间隔时长等等,Pandas举例如下所示。
其中:
- pandas排序sort_values():tradedf.sort_values(by=[carduser_id,dt_col], ascending=True),按carduser_id,dt_col两个字段联合排序
- pandas差分diff():tradedf[‘date’].diff(),计算字段‘date’的时间差,再通过tradedf[‘date’].diff().dt.days中的dt.days获取日期差
- pandas分组groupby():tradedf[[‘carduser_id’,‘date’,‘days’]].groupby([‘carduser_id’], as_index=False)
# 交时序易特征挖掘、提取
def trade_feature(tradedf):
# 恢复为原有的字段名称(利旧源代码)
tradedf = tradedf.rename(columns={'all_oils':'amount','all_goods':'goods','goods_id':'goodscategory_id'})
carduser_id = 'carduser_id'
dt_col = 'occurtime'
tradedf['occurtime']=tradedf['occurday']
tradedf['tradecount']=1 #默认一条记录为一次交易,便于统计
tradedf['occurtime'] = tradedf['occurtime'].astype('datetime64')
tradedf = tradedf.sort_values(by=[carduser_id,dt_col], ascending=True)
tradedf['date'] = tradedf[dt_col].dt.strftime('%Y%m%d')
tradedf['date'] = tradedf['date'].astype('datetime64')
#时间差分,提取本次加油距上次加油间隔天数
tradedf['days'] = tradedf['date'].diff().dt.days
#每客户首条记录,间隔时间为0,每个客户首行间隔时间,实际是不知道的,计算没有意义。
tradedf.loc[tradedf[['carduser_id','date','days']].groupby(['carduser_id'], as_index=False).head(1).index,'days'] = 0
# data:提取日期型和时间型的特征变量
tradedf['year']= tradedf[dt_col].dt.year
tradedf['month'] = tradedf[dt_col].dt.month
tradedf['day'] = tradedf[dt_col].dt.day
tradedf['yearmonth'] = tradedf[dt_col].dt.strftime('%Y%m')
tradedf['initdate']=tradedf['date'] #取交易起始时间
return tradedf
注:pandas时间datetime有丰富的接口“.dt”,dt.year、dt.month、dt.day、dt.hour、dt.minute、dt.second、dt.week 分别返回日期的年、月、日、小时、分、秒及一年中的第几周。
trade_df = trade_feature(df)
print(trade_df)
carduser_id occurday balance recharge volumn amount goods discount goodscategory_id DIM_DATE ... ZDE_92 occurtime tradecount date days year month day yearmonth initdate
0 1313943 2019/1/3 42799 0 0 0 -20000 0 100016.0 2018/12/15 ... -0.10 2019-01-03 1 2019-01-03 0.0 2019 1 3 201901 2019-01-03
1 1313943 2019/1/9 22799 0 3101 -20000 0 0 102546.0 2018/12/15 ... -0.10 2019-01-09 1 2019-01-09 6.0 2019 1 9 201901 2019-01-09
2 1313943 2019/1/19 0 0 3654 -22799 0 0 102546.0 2018/12/15 ... -0.10 2019-01-19 1 2019-01-19 10.0 2019 1 19 201901 2019-01-19
3 1313943 2019/4/26 4000 40600 5229 -36600 0 0 102546.0 2019/4/13 ... -0.05 2019-04-26 1 2019-04-26 97.0 2019 4 26 201904 2019-04-26
4 1313943 2019/6/30 0 22800 3459 -22000 -4800 0 102546.0 2019/6/27 ... -0.10 2019-06-30 1 2019-06-30 65.0 2019 6 30 201906 2019-06-30
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1.3. 数据计算
本文案例中的消费支出以负数表示,不方式统计、观看,把这部分数据转换为正数,以及计算交易合计金额。
def trade_amount(df):
#交易金额合计
df['sumamount'] = -(df['amount'] + df['goods']) #负值转换为正
df['amount'] = -df['amount'] #负值转换为正
df['goods'] = -df['goods'] #负值转换为正
return df
1.4. 挖掘数据周期维度
时序数据隐含有时间窗口特性、周期性。例如客户常见交易汇总统计包括:按天统计、按月统计、按年统计等。本文增加按月统计客户加油交易数据。
对于周期性,比较明显的是季节性、月份,总体特征比较明显,例如2月份过年前,就是典型的消费高峰期。
# 月统计数据
def monthStatistics(df):
ms_df = df[['carduser_id','yearmonth','sumamount','recharge','amount','goods','volumn','tradecount'
]].groupby(['carduser_id','yearmonth'], as_index=False).sum()
# 余额月均值
MonthBalance = df[['carduser_id','yearmonth','balance']].groupby(['carduser_id','yearmonth'], as_index=False).mean()
ms_df = pd.merge(left=ms_df,right=MonthBalance,how="left",on=['carduser_id','yearmonth'])
del MonthBalance
ms_df['month'] = ms_df['yearmonth'].str[4:6]
ms_df['year'] = ms_df['yearmonth'].str[0:4]
ms_df['yearmonth'] = ms_df['yearmonth'].astype('int64')
ms_df['month'] = ms_df['month'].astype('int64')
ms_df['year'] = ms_df['year'].astype('int64')
ms_df = ms_df.sort_values(by=['carduser_id','yearmonth'], ascending=True)
print(ms_df)
return ms_df
ms_df = monthStatistics(trade_df)
carduser_id yearmonth sumamount recharge amount goods volumn tradecount balance month year
0 1313943 201901 62799 0 42799 20000 6755 3 21866.000000 1 2019
1 1313943 201904 36600 40600 36600 0 5229 1 4000.000000 4 2019
2 1313943 201906 26800 22800 22000 4800 3459 1 0.000000 6 2019
3 1313943 201907 22000 22000 22000 0 3390 1 0.000000 7 2019
4 1313943 201909 72600 72600 62000 10600 9477 3 3533.333333 9 2019
... ... ... ... ... ... ... ... ... ... ... ...
1.5. 表关联(merge)
pandas的merge方法提供了一种类似于SQL的表关联操作,官网文档提到它的性能会比其他开源语言的数据操作要高效。
merge的参数
- left:左侧的DataFrame
- right:右侧的DataFrame 或 named Series
- on:关联列名,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。
- left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
- right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
- left_index/ right_index: 如果是True的haunted以index作为对齐的key
- how:数据融合的方法,‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’, 默认是 ‘inner’。
- sort:根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。
def mergergoods(trade_df):
# 提取物料编码特征
goodsCode = pd.read_csv('goodscode.csv',encoding='utf_8_sig')
goodsCode = goodsCode.rename(columns={'id':'goodscategory_id'})
trade_df = pd.merge(left=trade_df, right=goodsCode,how="left",on='goodscategory_id')
print(trade_df)
return trade_df
trade_df = mergergoods(trade_df)
carduser_id occurday balance recharge volumn amount goods discount goodscategory_id DIM_DATE ... days year month day yearmonth initdate sumamount catname h1 h2
0 1313943 2019/1/3 42799 0 0 0 20000 0 100016.0 2018/12/15 ... 0.0 2019 1 3 201901 2019-01-03 20000 香烟 100015.0 100016.0
1 1313943 2019/1/9 22799 0 3101 20000 0 0 102546.0 2018/12/15 ... 6.0 2019 1 9 201901 2019-01-09 20000 92号 车用汽油(ⅥA) 100000.0 100002.0
2 1313943 2019/1/19 0 0 3654 22799 0 0 102546.0 2018/12/15 ... 10.0 2019 1 19 201901 2019-01-19 22799 92号 车用汽油(ⅥA) 100000.0 100002.0
3 1313943 2019/4/26 4000 40600 5229 36600 0 0 102546.0 2019/4/13 ... 97.0 2019 4 26 201904 2019-04-26 36600 92号 车用汽油(ⅥA) 100000.0 100002.0
4 1313943 2019/6/30 0 22800 3459 22000 4800 0 102546.0 2019/6/27 ... 65.0 2019 6 30 201906 2019-06-30 26800 92号 车用汽油(ⅥA) 100000.0 100002.0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
1.6. 小结
至此,本文基于数据源,输出了两个交易数据集:一是扩展时间特征的日交易数据集,二是按月统计归集的月交易数据集。
2. 常用特征提取——极限值与统计值
数据挖掘与分析的目标是为关注对象(客户)打上特征数据,例如当前余额、最后一次交易信息、客户时长、累计交易金额、平均间隔时长等等。
2.1. 最后一次交易关键特征
新建客户特征数据集,首先从交易数据集中获取每个客户的最后一次交易关键信息,为每个客户建立唯一特征数据记录。
按每客户升序排序,取最后一条记录’tail(1)'提取数据。接着合并统计数据,例如累计交易次数、平均间隔天数。
def customer_last(trade_df):
# 取最后一次交易间隔时间
cf_df = trade_df[['carduser_id','occurday','balance','days']].groupby(['carduser_id']).tail(1)
cf_df['occurtime'] = cf_df['occurday'].astype('datetime64')
cf_df = cf_df.rename(columns={'occurday':'latestday','days':'latestdays'})
return cf_df
cf_df = customer_last(trade_df)
carduser_id latestday balance latestdays occurtime
0 1313943 2020-12-07 60 1.0 2020-12-07
1 1505320 2020-12-30 105072 17.0 2020-12-30
2 1726223 2021-01-31 41910 7.0 2021-01-31
3 1726514 2021-01-14 10 19.0 2021-01-14
4 1728962 2021-01-10 85999 19.0 2021-01-10
.. ... ... ... ... ...
2.2. 关键极值特征
-
最后充值时间:
筛选充值记录,按时间升序排序,取最大值‘tail(1)’,再与最后的交易记录做差,计算与最后交易的间隔时间。 -
最大间隔时间:
按间隔时间升序排序,取最大值‘tail(1)’。
def customer_extreme(cf_df ,trade_df):
# 取最后一次充值时间,由于date已经变成int64,需要使用initdate列
recharge = trade_df[trade_df['recharge']>0][['carduser_id','initdate','recharge']].groupby(['carduser_id']).tail(1)
lasttrade = trade_df[['carduser_id','initdate']].groupby(['carduser_id']).tail(1).copy()
recharge = recharge.rename(columns={'initdate':'redate','recharge':'lastrecharge'})
lasttrade = pd.merge(left=lasttrade,right=recharge,how='inner',on=['carduser_id'])
lasttrade['recharge_days'] = (lasttrade['initdate'].astype('datetime64')-lasttrade['redate'].astype('datetime64')).dt.days
cf_df = pd.merge(left=cf_df,right=lasttrade[['carduser_id','recharge_days','lastrecharge']],how='left',on=['carduser_id'])
#取最大间隔时间
maxtrade = trade_df.sort_values(by=['carduser_id','days'], ascending=True)
maxtrade = maxtrade[['carduser_id','days']].groupby(['carduser_id']).tail(1)
cf_df = pd.merge(left=cf_df, right=maxtrade,how="left",on='carduser_id')
cf_df['daysnum'] = (cf_df['occurtime'] -cf_df['initdate'].astype('datetime64')).dt.days #客户会员时长,天数
cf_df = cf_df.fillna(0) # 空值填充为0
return cf_df
cf_df = customer_extreme(cf_df ,trade_df)
print(cf_df)
carduser_id latestday balance latestdays occurtime recharge_days lastrecharge initdate days daysnum
0 1313943 2021/6/27 1065 18.0 2021-06-27 0.0 22000.0 2019-01-03 237.0 906
1 1456894 2019/7/26 0 145.0 2019-07-26 0.0 0.0 2019-03-03 145.0 145
2 1459877 2020/8/18 0 21.0 2020-08-18 0.0 0.0 2020-07-28 21.0 21
3 1480968 2019/4/25 24870 0.0 2019-04-25 0.0 50000.0 2019-04-25 0.0 0
4 1481117 2020/11/20 0 0.0 2020-11-20 0.0 0.0 2020-11-20 0.0 0
.. ... ... ... ... ... ... ... ... ... ...
2.3. 累计/均值/计数等通常特征
使用DataFrame的聚合方法sum、count、mean等,统计累计交易次数、间隔时间均值、充值次数、累计消费情况等。
#输入特征集、日交易集
def customer_aggregation(cf_df,trade_df):
# 取累计交易次数
tradecount_df = trade_df[['carduser_id','tradecount']].groupby(['carduser_id'],as_index=False).sum()
cf_df = pd.merge(left=cf_df,right=tradecount_df,how='left',on='carduser_id')
# 取间隔均值
meandaystrade_df =trade_df[trade_df['days']>0].reset_index(drop=True)
meandays_df = meandaystrade_df[['carduser_id','days','balance']].groupby(['carduser_id'],as_index=False).mean().round(2)
meandays_df = meandays_df.rename(columns={'days':'meandays','balance':'balancemean'})
cf_df = pd.merge(left=cf_df,right=meandays_df,how='left',on='carduser_id')
rechrage_count_df = trade_df.loc[trade_df['recharge']>0].reset_index(drop=True).copy()
rechrage_count_df = rechrage_count_df[['carduser_id','recharge']].groupby(['carduser_id'],as_index=False).count()
rechrage_count_df = rechrage_count_df.rename(columns={'recharge':'count'})
cf_df = pd.merge(left=cf_df, right=rechrage_count_df,how="left",on='carduser_id')
acc_trade = trade_df[['carduser_id','sumamount','amount','goods','volumn']].groupby(['carduser_id'], as_index=False).sum()
acc_trade = acc_trade.rename(columns={'sumamount':'accsumamount','amount':'accamount','goods':'accgoods','volumn':'accvolumn'})
cf_df = pd.merge(left=cf_df, right=acc_trade,how="left",on='carduser_id')
return cf_df
cf_df = customer_aggregation(cf_df,trade_df)
print(cf_df)
carduser_id latestday balance latestdays occurtime recharge_days lastrecharge initdate days daysnum tradecount meandays balancemean count accsumamount accamount accgoods accvolumn
0 1313943 2021/6/27 1065 18.0 2021-06-27 0.0 22000.0 2019-01-03 237.0 906 46 20.13 5852.51 29.0 672034 616514 55520 101337
1 1456894 2019/7/26 0 145.0 2019-07-26 0.0 0.0 2019-03-03 145.0 145 2 145.00 0.00 NaN 45000 45000 0 6625
2 1459877 2020/8/18 0 21.0 2020-08-18 0.0 0.0 2020-07-28 21.0 21 2 21.00 0.00 NaN 50000 50000 0 8788
3 1480968 2019/4/25 24870 0.0 2019-04-25 0.0 50000.0 2019-04-25 0.0 0 1 NaN NaN 1.0 33000 33000 0 4714
4 1481117 2020/11/20 0 0.0 2020-11-20 0.0 0.0 2020-11-20 0.0 0 1 NaN NaN NaN 9400 9400 0 1691
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2.4. 方差/标准差等波动特征
方差、标准差、峰度、偏度做为客户交易特征,可以用于客户细分的特征。
# 波动分析,方差、偏度、峰度
def fluctuation_analysis(cf_df ,df):
#计算加油消费金额、加油量、加油间隔的标准差
df_feature = df[['carduser_id','volumn','amount','goods','sumamount','days']].groupby(['carduser_id']).std()
df_feature = df_feature.rename(columns={'amount':'amount_std','volumn':'volumn_std','goods':'goods_std','sumamount':'sumamount_std','days':'days_std'})
cf_df = pd.merge(left=cf_df, right=df_feature,how="left",on=['carduser_id']) #左连接
# 偏度(三阶)
df_feature4 = df[['carduser_id','volumn','amount','goods','sumamount','days']].groupby(['carduser_id']).skew()
df_feature4 = df_feature4.rename(columns={'amount':'amount_skew','volumn':'volumn_skew','goods':'goods_skew','sumamount':'sumamount_skew','days':'days_skew'})
cf_df = pd.merge(left=cf_df, right=df_feature4,how="left",on=['carduser_id']) #左连接
return cf_df
cf_df = fluctuation_analysis(cf_df ,trade_df)
print(cf_df)
carduser_id latestday balance latestdays ... volumn_std amount_std goods_std sumamount_std days_std volumn_skew amount_skew goods_skew sumamount_skew days_skew
0 1313943 2021/6/27 1065 18.0 ... 1656.557441 10216.623760 3381.192340 10001.420605 38.313252 -0.367407 -0.229370 4.507406 -0.236091 4.512808
1 1456894 2019/7/26 0 145.0 ... 980.757106 7778.174593 0.000000 7778.174593 102.530483 NaN NaN NaN NaN NaN
2 1459877 2020/8/18 0 21.0 ... 2740.745884 15597.361379 0.000000 15597.361379 14.849242 NaN NaN NaN NaN NaN
3 1480968 2019/4/25 24870 0.0 ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
4 1481117 2020/11/20 0 0.0 ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
注,其中方差、标准差、峰度、偏度公式为:
(1)均值:
μ = 1 n ∑ i = 1 n x i \mu = \frac{1}{n}\sum_{i=1}^{n} x_{i} μ=n1i=1∑nxi
(2)方差:
σ 2 = 1 2 ∑ i = 1 n ( x i − μ ) 2 \sigma^{2}=\frac{1}{2}\sum_{i=1}^{n}(x_{i}-\mu)^2 σ2=21i=1∑n(xi−μ)2
(3)标准差:
σ = 1 n − 1 ∑ i = 1 n ( x i − μ ) 2 \sigma = \sqrt {\frac{1}{n-1}\sum_{i=1}^{n}(x_{i}-\mu)^{2}} σ=n−11i=1∑n(xi−μ)2
标准差是方差的开方,描述的是样本集合的各个样本点到均值的距离之平均;同时,也可以反映一个数据集的离散程度
(4)离散度百分比
σ ′ = σ μ \sigma'=\frac{\sigma}{\mu} σ′=μσ
(5)峭度
k 4 = 1 n − 1 ∑ i = 1 n ( x i − μ σ ) 4 k_{4} = \frac{1}{n-1}\sum_{i=1}^{n}(\frac{x_{i}-\mu}{\sigma})^{4} k4=n−11i=1∑n(σxi−μ)4
峭度因子是表示波形平缓程度的,用于描述变量的分布。正态分布的峭度等于3,峭度小于3时分布的曲线会较“平”,大于3时分布的曲线较“陡”。
(6)偏度
k 3 = 1 n − 1 ∑ i = 1 n ( x i − μ σ ) 3 k_{3} = \frac{1}{n-1}\sum_{i=1}^{n}(\frac{x_{i}-\mu}{\sigma})^{3} k3=n−11i=1∑n(σxi−μ)3
偏度因子:偏度也叫偏斜度、偏态。偏度和峭度是有一定的相关性的,峭度因子是四阶中心矩和标准差的四次方的比值;偏度因子是三阶中心矩和标准差的三次方的比值。偏度与峭度相同,描述的是分布。
2.5. 其他
DataFrame.apply() 函数则会遍历每一个元素,对元素运行指定的 function。
# 计算距最近交易时间
def set_latesttime(df):
print('计算距最近交易时间')
latestday = '2021-06-30 12:00:00'
print(df)
print(df.dtypes)
df['occurtime'] = df['occurtime'].astype('datetime64')
df['latestday'] = (datetime.datetime.strptime(latestday,'%Y-%m-%d %H:%M:%S') - df['occurtime']).dt.days
# 把距离交易时间标准化,方便聚类
def f(latestday):
days = latestday
if (days >= 180 ):
y = 3
elif (days >= 90 and days < 180 ):
y =2
elif (days >= 30 and days < 90):
y =1
else:
y = 0
return pd.Series([y])
# apply嵌入函数
df[['lateststatus']] = df['latestday'].apply(lambda x:f(x))
# apply直接使用表达式,计算余额率
df['balancerate'] = df.apply(lambda y:(y.balance/y.balancemean) if (y.balancemean!=0) else 0,axis=1).round(2)
return df
注,pandas使用自定义函数,函数返回值为pd.Series()。
cf_df = set_latesttime(cf_df)
print(cf_df)
3. 按周期统计分析数据
通过月周期、季度周期、年度周期方式,增加交易数据分析维度。例如取最后月份的交易量、月均交易量、月标准差等。
3.1. 月周期
# 月统计数据
def monthStatistics(df):
ms_df = df[['carduser_id','yearmonth','sumamount','recharge','amount','goods','volumn','tradecount'
]].groupby(['carduser_id','yearmonth'], as_index=False).sum()
# 余额月均值
MonthBalance = df[['carduser_id','yearmonth','balance']].groupby(['carduser_id','yearmonth'], as_index=False).mean()
ms_df = pd.merge(left=ms_df,right=MonthBalance,how="left",on=['carduser_id','yearmonth'])
del MonthBalance
ms_df['month'] = ms_df['yearmonth'].str[4:6]
ms_df['year'] = ms_df['yearmonth'].str[0:4]
ms_df['yearmonth'] = ms_df['yearmonth'].astype('int64')
ms_df['month'] = ms_df['month'].astype('int64')
ms_df['year'] = ms_df['year'].astype('int64')
ms_df = ms_df.sort_values(by=['carduser_id','yearmonth'], ascending=True)
print(ms_df)
return ms_df
ms_df = monthStatistics(trade_df)
carduser_id yearmonth sumamount recharge amount goods volumn tradecount balance month year
0 1313943 201901 62799 0 42799 20000 6755 3 21866.000000 1 2019
1 1313943 201904 36600 40600 36600 0 5229 1 4000.000000 4 2019
2 1313943 201906 26800 22800 22000 4800 3459 1 0.000000 6 2019
3 1313943 201907 22000 22000 22000 0 3390 1 0.000000 7 2019
4 1313943 201909 72600 72600 62000 10600 9477 3 3533.333333 9 2019
... ... ... ... ... ... ... ... ... ... ... ...
3.2. 月特征提前——极限值与统计值
此部分数据操作与第2章节内容一致,输入数据是月交易数据‘ms_df’,返回结果关联并入到客户特征表中‘cf_df’。
注:文中涉及到数据源,见CSDN资源链接(Pandas高级数据分析快速入门)数据源——加油日交易数据片段。
参考:
肖永威 . 大数据人工智能常用特征工程与数据预处理Python实践(2) ,CSDN博客 ,2020-12
肖永威 . Pandas高级数据分析快速入门之二——基础篇 ,CSDN博客,2021-08















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











