






Prophet 时间序列预测框架入门实践笔记
接续上文,预测结果:
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(48)
forecast 是Pandas的DataFrame,数据项及含义如下:
- ‘ds’: 是日期时间戳列,表示时间序列中的每个时间点。
- ‘trend’: 是趋势项,表示整体趋势的模型预测值。
- ‘trend_lower’: 是趋势项的下限,表示趋势项的最低可能值。
- ‘trend_upper’: 是趋势项的上限,表示趋势项的最高可能值。
- ‘Lunar_festivals’: 这是根据实际情况自定义的农历节日项,表示农历节日对预测结果的影响。
- ‘Lunar_festivals_lower’: 是农历节日项的下限,表示农历节日项的最低可能值。
- ‘Lunar_festivals_upper’: 是农历节日项的上限,表示农历节日项的最高可能值。
- ‘additive_terms’: 是可加性分量,包括季节性项和假日项的总和。
- ‘additive_terms_lower’: 是可加性分量的下限,表示可加性分量的最低可能值。
- ‘additive_terms_upper’: 是可加性分量的上限,表示可加性分量的最高可能值。
- ‘china’:这是根据实际情况自定义的中国假日项,表示中国假日对预测结果的影响。
- ‘china_lower’: 是中国假日项的下限,表示中国假日项的最低可能值。
- ‘china_upper’: 是中国假日项的上限,表示中国假日项的最高可能值。
- ‘daily’: 是每日季节性项,表示每日季节性对预测结果的影响。
- ‘daily_lower’: 是每日季节性项的下限,表示每日季节性项的最低可能值。
- ‘daily_upper’: 是每日季节性项的上限,表示每日季节性项的最高可能值。
- ‘holidays’: 是所有假日项的总和,包括农历节日和中国假日。
- ‘holidays_lower’: 是所有假日项的下限,表示所有假日项的最低可能值。
- ‘holidays_upper’: 是所有假日项的上限,表示所有假日项的最高可能值。
- ‘weekly’: 是每周季节性项,表示每周季节性对预测结果的影响。
- ‘weekly_lower’: 是每周季节性项的下限,表示每周季节性项的最低可能值。
- ‘weekly_upper’: 是每周季节性项的上限,表示每周
- ‘multiplicative_terms’、‘multiplicative_terms_lower’、‘multiplicative_terms_upper’:这些列表示Prophet模型中的乘法项(Multiplicative Terms)。在时间序列的建模过程中,Prophet模型可以使用加法模型(Additive Model)或乘法模型(Multiplicative Model)来表示趋势和季节性之间的关系。这些列提供了乘法项的估计值,以及对应的下限和上限。
- ‘yhat’:表示模型对未来值的预测结果。它是根据历史数据和模型的参数计算得出的对未来趋势和季节性的估计。'yhat’列提供了每个时间点的预测值。
- ‘yhat_lower’: 是预测值的下限,表示在给定置信水平下的最低预测值。
- ‘yhat_upper’: 是预测值的上限,表示在给定置信水平下的最高预测值。
这些列中的值是模型预测的结果,可以用于评估和分析时间序列数据的趋势和季节性。值得注意的是,这些列的具体形式和影响因素取决于数据集的特征和模型的训练结果。因此,具体的数值和解释可以根据数据和模型的上下文进行分析和解释。
其中:
yhat = trend + daily + holidays + weekly
additive_terms = daily + holidays + weekly
如下图所示,截取部分数据示例。
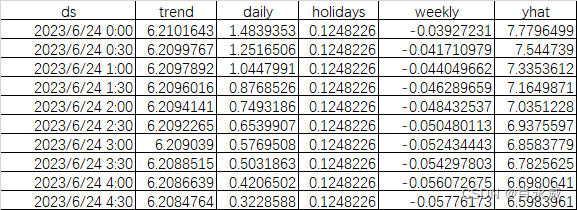
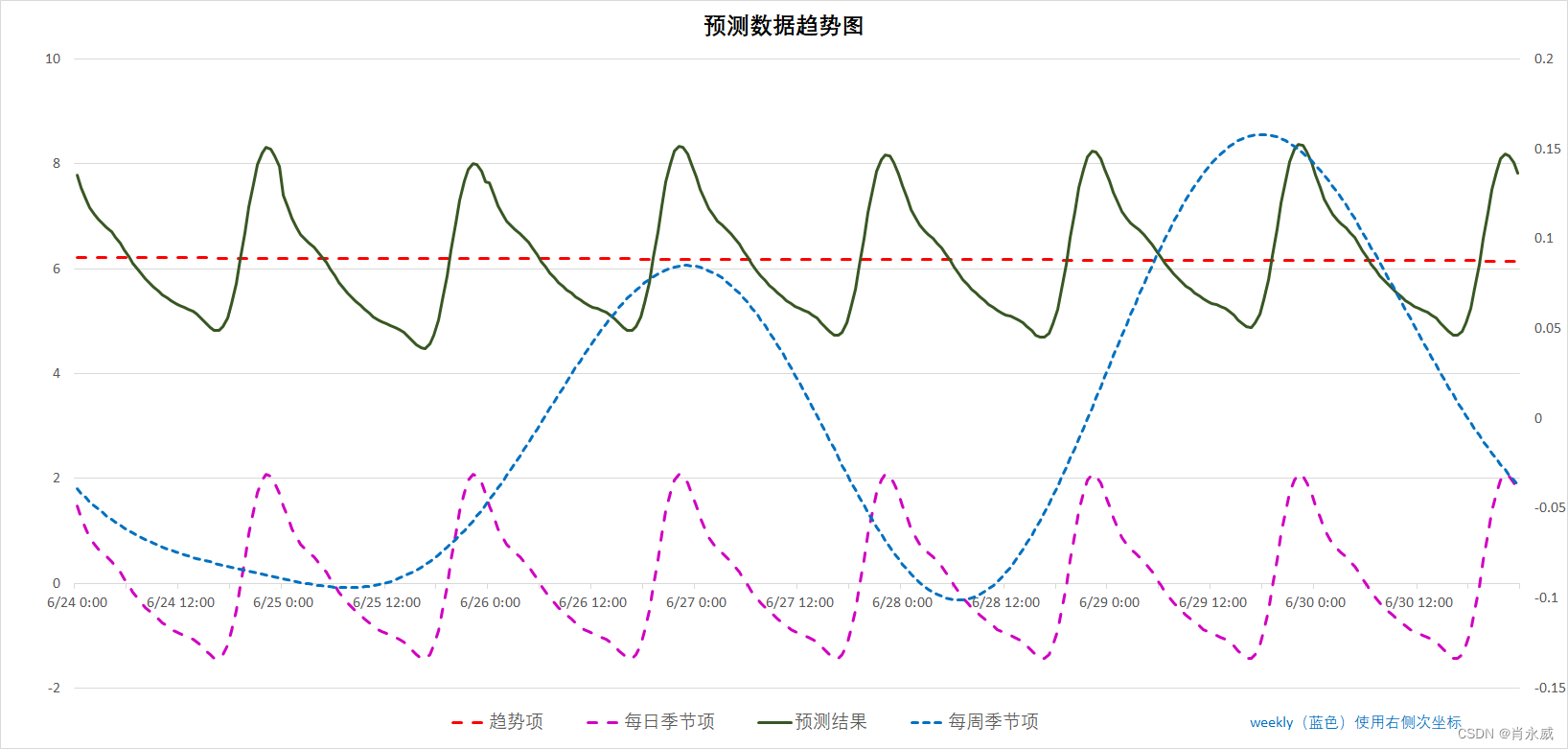
输出一周的图形如下图所示:
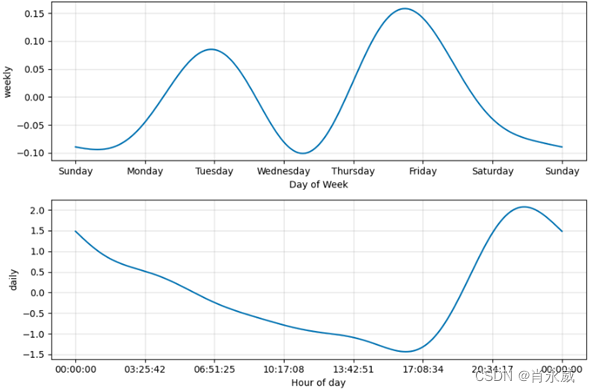
其,季节项如下图:
根据加法模型,Prophet模型的预测输出可以表示为:
yhat = trend + seasonal + holidays + additional_components + error
其中,
- trend 表示趋势项,代表时间序列的整体变化趋势;
- seasonal 表示季节性项,表示时间序列在周期性变化方面的模式;
- holidays 表示节假日项,表示特定节假日对时间序列的影响;
- additional_components 表示其他额外的因素,如自定义的重要事件等;
- error 表示模型的误差项。
附加解释概念:
- 能通俗的解释模型中的加法项、乘法项?
当使用Prophet模型建模时间序列数据时,可以选择使用加法项或乘法项来表示趋势和季节性之间的关系。
加法模型(Additive Model)假设趋势和季节性之间是相互独立的,即趋势和季节性的效果是可以简单地相加的。在加法模型中,时间序列的值可以表示为:原始值 = 趋势 + 季节性 + 其他因素(例如节假日、特殊事件等)。
乘法模型(Multiplicative Model)假设趋势和季节性之间是相互影响的,即趋势和季节性的效果是相互放大或相互减弱的。在乘法模型中,时间序列的值可以表示为:原始值 = 趋势 * 季节性 * 其他因素。
具体选择加法模型还是乘法模型,取决于时间序列数据的特征和具体的应用场景。通常情况下,加法模型适用于季节性效果与趋势相对独立的情况,而乘法模型适用于季节性效果与趋势相关强烈的情况。
在Prophet模型中,可以通过调整参数来选择使用加法模型或乘法模型来建模时间序列数据。根据选择的模型类型,模型会计算出对应的趋势、季节性和其他因素的估计值,以提供对未来值的预测。
- 当涉及到实际案例时,以下是一些加法项和乘法项的例子:
-
加法项的实际案例:
假设我们正在分析某电子商务平台每天的订单量。加法项可以用于表示每天的订单量由趋势、每周季节性和节假日等因素组成。- 趋势项:表示订单量随着时间的推移呈现逐渐增长或递减的趋势。
- 每周季节性项:表示每周不同天的订单量的周期性变化,例如周末订单量较高,工作日订单量较低。
- 节假日项:表示节假日对订单量的影响,例如圣诞节、感恩节等节假日可能会带来订单量的增加。
-
乘法项的实际案例:
假设我们正在分析某农产品的年度产量。乘法项可以用于表示产量受到趋势、季节性和气候因素等的相互影响。- 趋势项:表示产量随着时间的推移呈现逐渐增长或递减的趋势。
- 季节性项:表示每年不同季节的产量的周期性变化,例如春季产量较高,冬季产量较低。
- 气候因素项:表示气候因素对产量的影响,例如降雨量、温度等气候因素可能会对产量产生影响。
这些是加法项和乘法项在实际案例中的一些示例,它们可以根据具体的应用领域和时间序列数据的特征来进行调整和扩展。重要的是要根据具体的情况选择适当的建模方式,并考虑到趋势、季节性和其他相关因素对时间序列数据的影响。


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











