






python提供处理(解析和创建)XML格式文件的接口:xml.etree.ElementTree(以下简称ET) 模块。
> 注:自version3.3后,xml.etree.cElementTree模块废弃。
一、XML格式
XML是一种层级数据格式,通常可以用“树”表示。ET中有两个类(class)可对XML进行表示:
- ElementTree:将整个XML文件表示成“树”;(class ET.ElementTree)
- Element:表示这棵树中的单个节点。(class ET.Element)
二、解析XML
下文以解析 country_data.xml 文件为例:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>2.1 读取XML格式文件
2.1.1 读取方法
(1)方法一:来自文件
import xml.etree.ElementTree as ET
#方法1:来自文件
tree = ET.parse('XXXX.xml') #文件存储路径,获取整个xml
root = tree.getroot() #获取xml的根节点
(2) 方法二:来自文件内容(字符串)
#方法2:来自字符串
root = ET.fromstring('XXXX.xml文件的全部字符串')说明:ET.fromstring() 函数将XML文件内容(字符串格式)直接解析为一个Element对象(节点),这个Element是这个被解析的XML树的根节点。
2.1.2 代码
import xml.etree.ElementTree as ET
filePath = 'C:\codes\data\country_data.xml'
##method1: reading from a file
tree = ET.parse(filePath)
root = tree.getroot()
print(root.tag)
##method2: importing from a string
root2 = ET.fromstring('''<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>''')
print (root2.tag)输出:
![]()
2.2 获取Element对象属性
| 序号 | 属性 | 表示 | 数据类型 | 举例 |
| 1 | Element.tag | element name,指该element对象的类型 | 字符串 | 输入:root.tag 输出:data |
| 2 | Element.attrib | element atrribute's name and value | 字典 | 输入:root[0].attrib 输出:{‘name’:'Liechtenstein'} |
| 3 | Element.text | the text between the element's start tag and its first child or end tag, or None.(当前element起始tag与下一个邻近tag之间的文本) | 通常为字符串 | 输入:root[0][0].text 输出:1 |
| 4 | Element.tail | the text between the element's end tag and the next tag, or None.(当前element结束tag与下一个tag之间的文本) | 通常为字符串 | 输入:root[0][0].tail 输出:None |
| 5 | Element.keys() | 获取当前对象/节点属性的键,返回列表 | list | 输入:root[0].keys() 输出:['name'] |
| 6 | Element.items() | 获取当前对象/节点属性键值对,返回列表 | list[(,)] | 输入:root[0][3].items() 输出:[('name', 'Austria'), ('direction', 'E')] |
2.3 查询subElement对象的函数
2.3.1查找范围为当前Element对象及以下所有层级
迭代器查找:Element.iter('tagname')
- 查询当前element对象及以下所有层级tag为tagname的对象(深度优先查找);
- 若tagname为 None 或 ' * ',则查找当前element对象及以下所有层级的所有对象。
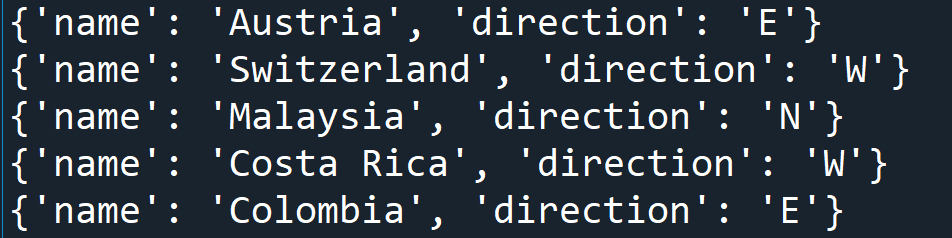
#获取当前element对象下所有层级tag为Neighbor的对象
for neighbor in root.iter('neighbor'):
print(neighbor.attrib) 输出:
2.3.2 查找范围为当前Element对象下一层级
- Element.findall(match):获取当前Element对象下一层级(仅这一层)匹配的对象列表。
- Element.iterfind(match):获取当前Element对象下一层级(仅这一层)匹配的对象迭代器。
- Element.find(match):获取当前Element对象下一层级中第一个匹配的对象。
- Element.findtext(match, default=None):获取当前Element对象下一层级中第一个匹配的对象的text(不好用,会出现很多'\n(空格)')。
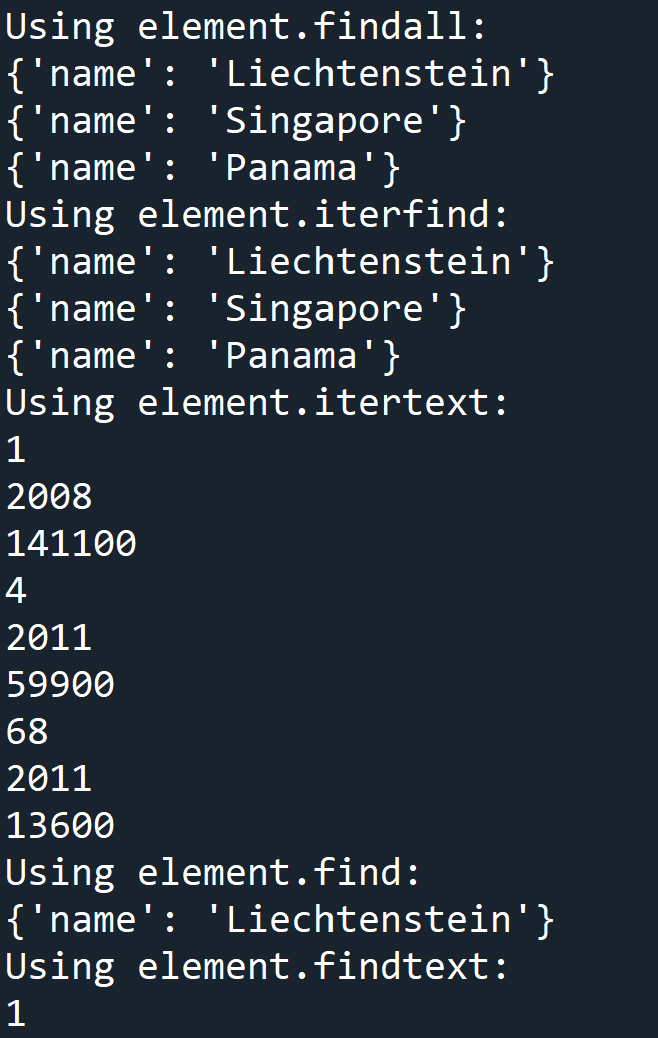
#查找当前element对象下一层级
print('Using element.findall:')
ele1 = root.findall('country')
for every in ele1:
print(every.attrib)
print("Using element.iterfind:")
for every in root.iterfind('country'):
print(every.attrib)
print('Using element.itertext:')
for every in root.itertext():
if every.startswith('\n')==False:
print(every)
#查找当前element对象下一层级第一个匹配对象
print('Using element.find:')
ele = root.find('country')
print(ele.attrib)
print('Using element.findtext:')
ranktext = ele.findtext('rank')
print(ranktext)输出:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









