






我们将全国税收调查数据和专利全库两份数据匹配起来,由于两份数据都非常巨大(20GB 和 100GB),所以我就直接帮大家匹配好了。
因为数据较大,所以我特意将税收调查数据与专利数据匹配结果分拆成分年版本,时间范围为 2007~2016 年。数据格式方面,我提供的是供 Stata 读取的 dta 格式。以 2016 年为例,数据概览如下:
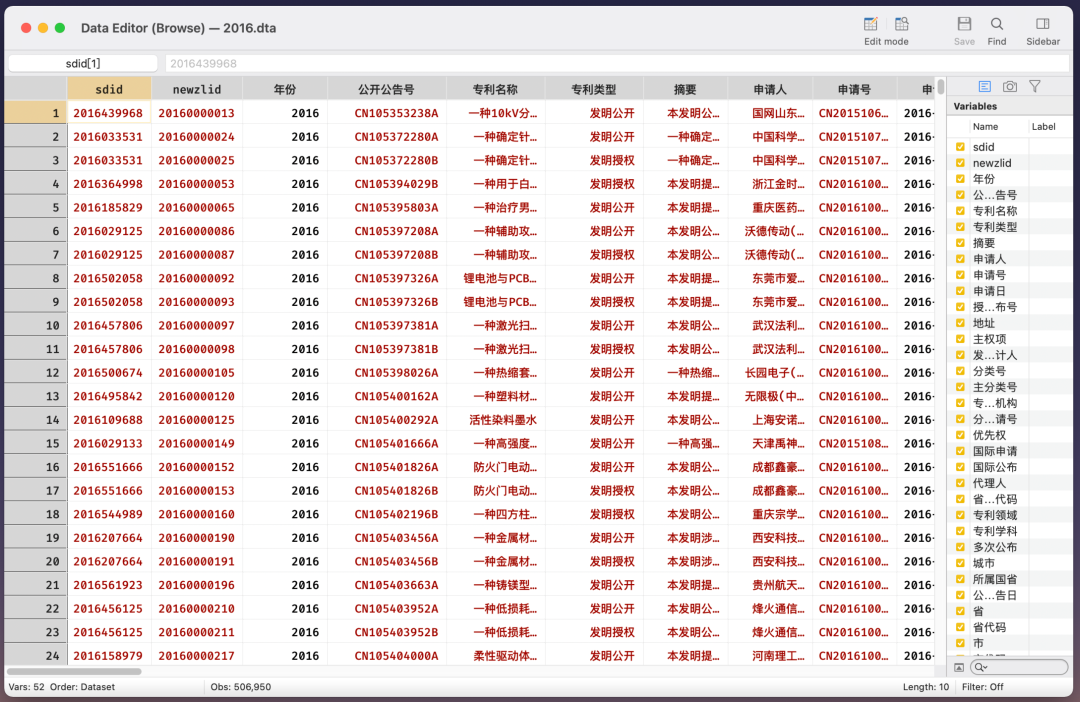
匹配结果
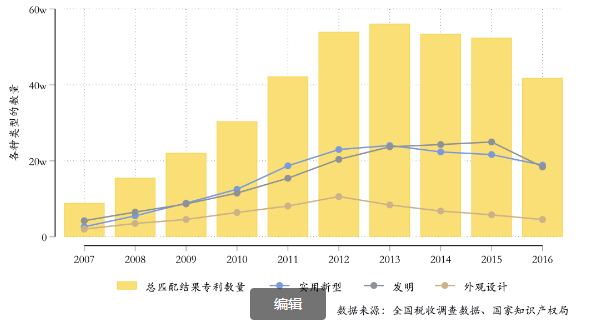
下图展示了税收调查与专利数据匹配结果中各年总匹配专利的数量,以及各年各种类型的专利数量:
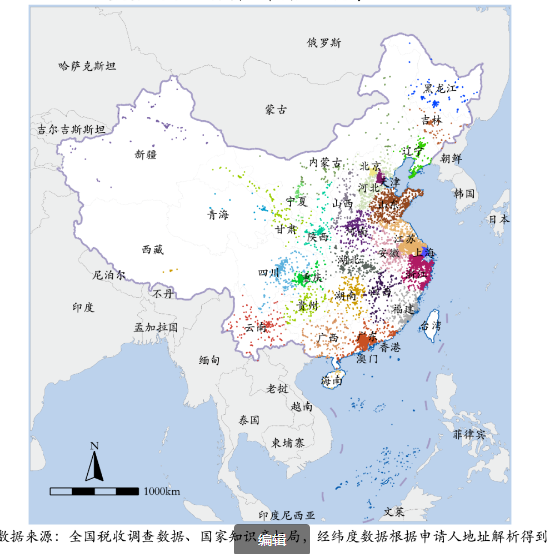
下图展示了 2016 年税调企业中专利申请人地址分布:
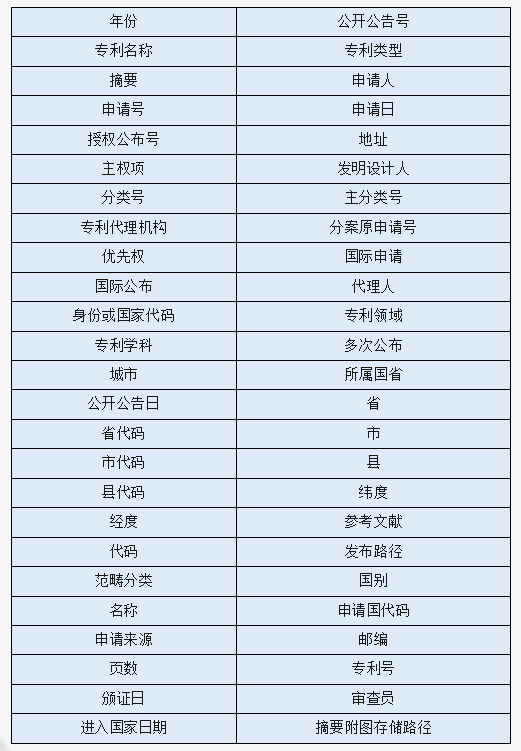
字段说明:
匹配方法:
结合税收调查数据与专利数据的变量,我们使用税调数据中的企业名称(还使用了税调与工商注册信息匹配结果来补充企业名称)与专利数据中的申请人进行匹配。具体匹配方法分为三步:
- 专利数据中有个申请人变量,每个专利可能有多个申请人,申请人之间使用冒号分隔。因此需要首先处理申请人变量,处理思路如下:
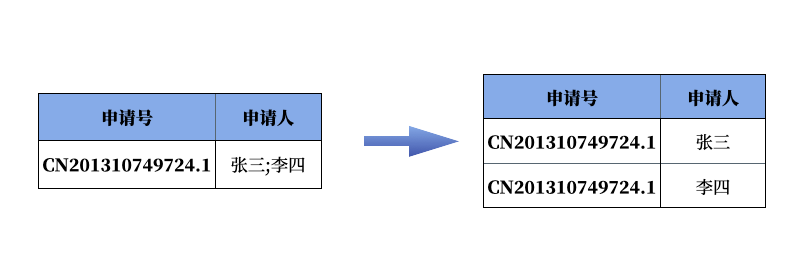
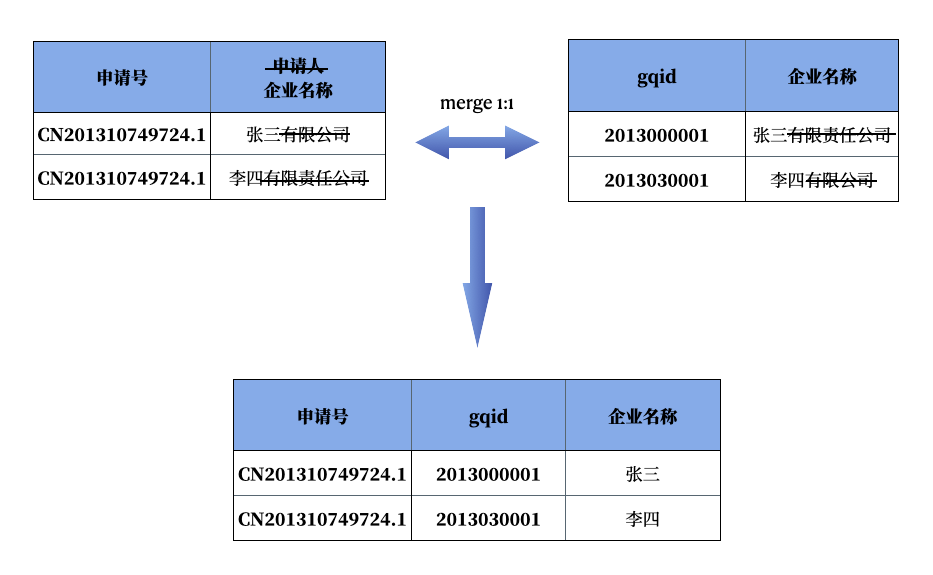
- 其次,对税调数据库里的企业名称和专利数据里的申请人变量进行处理,主要是改正错字和去除对匹配没有帮助的词汇(例如“有限公司”、“有限责任公司”)。为便于两个数据集的连接,我在税调数据中生成了sdid 变量作为企业名称的标识码。在之前的课程「Stata 中的中文模糊匹配——以 2014 年工企数据和境外投资名录数据匹配为例」中,我分享过使用 Stata 进行模糊匹配的方法,不过模糊匹配耗时耗力,并且错误率很高。不同于英文,中文企业名称只要有一个字不同都可能不是同一家企业(英文企业名称有一两个字母不同可能是因为笔误)。所以中文企业名称的模糊匹配没有意义。因此这里我还是使用了精确匹配,考虑到企业名称中经常会把“有限公司”和“有限责任公司”混用,以及有限公司改股份有限公司之类的。所以这里在匹配前删除了下面词汇:股份有限、集团有限、有限责任、有限、责任、股份、公司、厂、 、(集团)、(集团)、(、)、(、)、省、市、区、县、回族自治区、壮族自治区、维吾尔自治区、自治区。这样可以大大提高匹配成功率。
【下载→
方式一(推荐):主页 个人 简介
方式二:数据下载方式汇总-CSDN博客

















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









