







篇二 踩坑指南:https://blog.csdn.net/xiedelong/article/details/124019277
介绍
YouTube的推荐系统的主要挑战有三:
- 规模:有一些算法在小规模的问题上表现很好,但是难以应用于较大规模的问题,高度专业化的分布式学习算法和高效的服务系统是处理的关键。
- 新鲜性(冷启动):Youtube 网站上随时都有新鲜内容产生,怎么把这些新鲜内容推荐出去是需要考虑的。
- 噪声:用户不会对观看的内容有显性的满意度评价,我们只能模拟有噪声的隐式反馈信号(用户观看时长、是否完成观看等),同时视频不是结构性的内容,需要提取到对应的特征,以让模型具有鲁棒性
系统结构
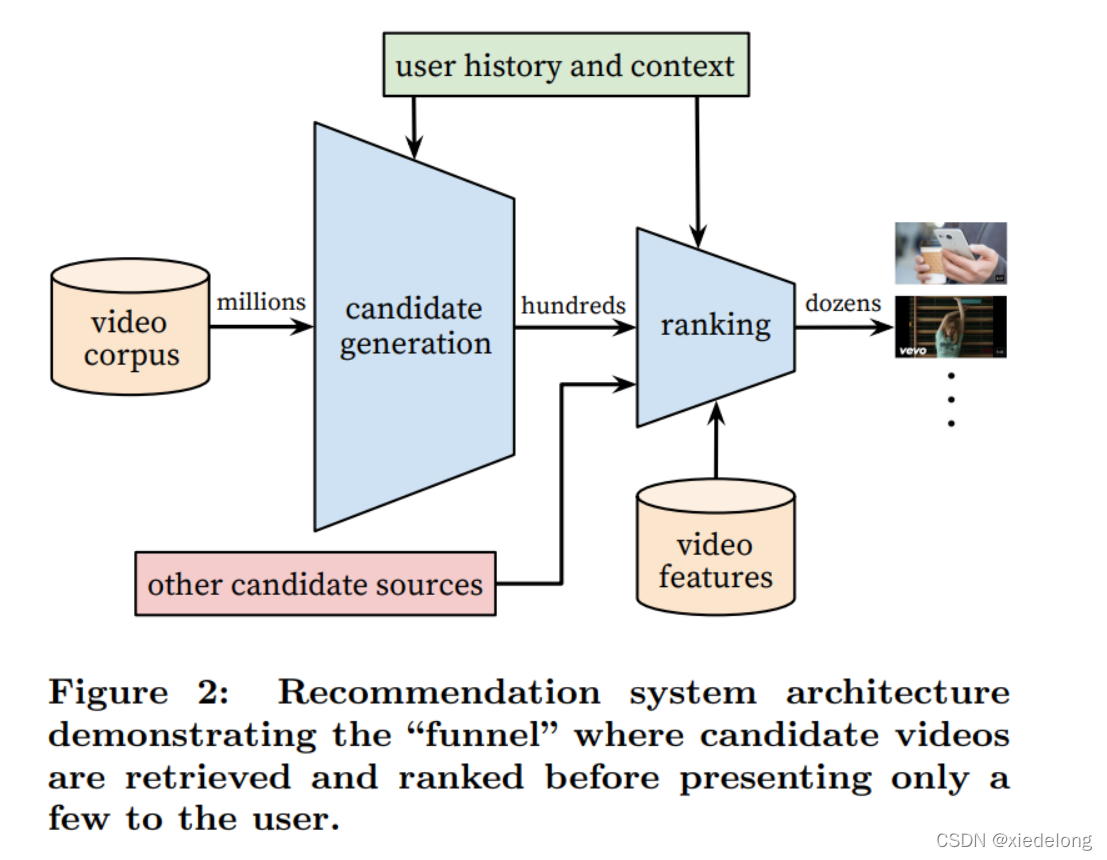
- 包括召回阶段 & 排序阶段
- 召回网络:以用户的历史行为作为输入,召回一个小候选集(百量级),这些候选对象通常与用户有较高的相关性,用户特征用:用户看过的视频id、query、人口统计特征 来表达
- 排序网络:区分候选集中的 “best recommendations” ,也就是使用丰富的特征集描述 user 和 video ,并对不同的视频进行打分
- 同时,这个结构可以混合其他源生成的候选,也就是图里的 other candidate sources
生成候选集
极端多类分类的方法:基于用户 U 和上下文 C,在时间 t 时,在语料库 V 中数百万个视频 (classes) 中准确地将特定的视频观看 wt 进行分类
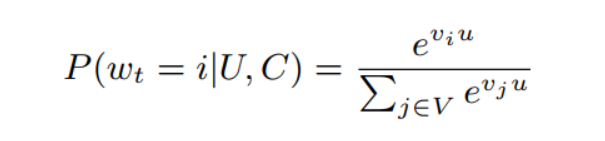
- 其中 U 表示用户的高维 embedding 表示
- C 表示上下文的 embedding 表示(也就是用户看过的视频)
- vj 表示候选视频的 embedding 表示
- 这三个的维度都是 N,神经网络的目标是学习 user 的embedding 表示 u
高效的极端多分类
- 候选抽样 + 重要性加权,对于每个例子,交叉熵损失是最小的真实标签和采样的负类
- 作者使用了分层 softmax 采样,但是没有达到预期的精度,而且性能不好
- 由于从 softmax 输出层时不需要标准的相似度(不需要打分排序),因此问题可以简化为,在点积空间中进行最近邻搜索,并且作者的 AB 实验结果表明,最近邻搜索算法的选择,对最终的结果影响极小
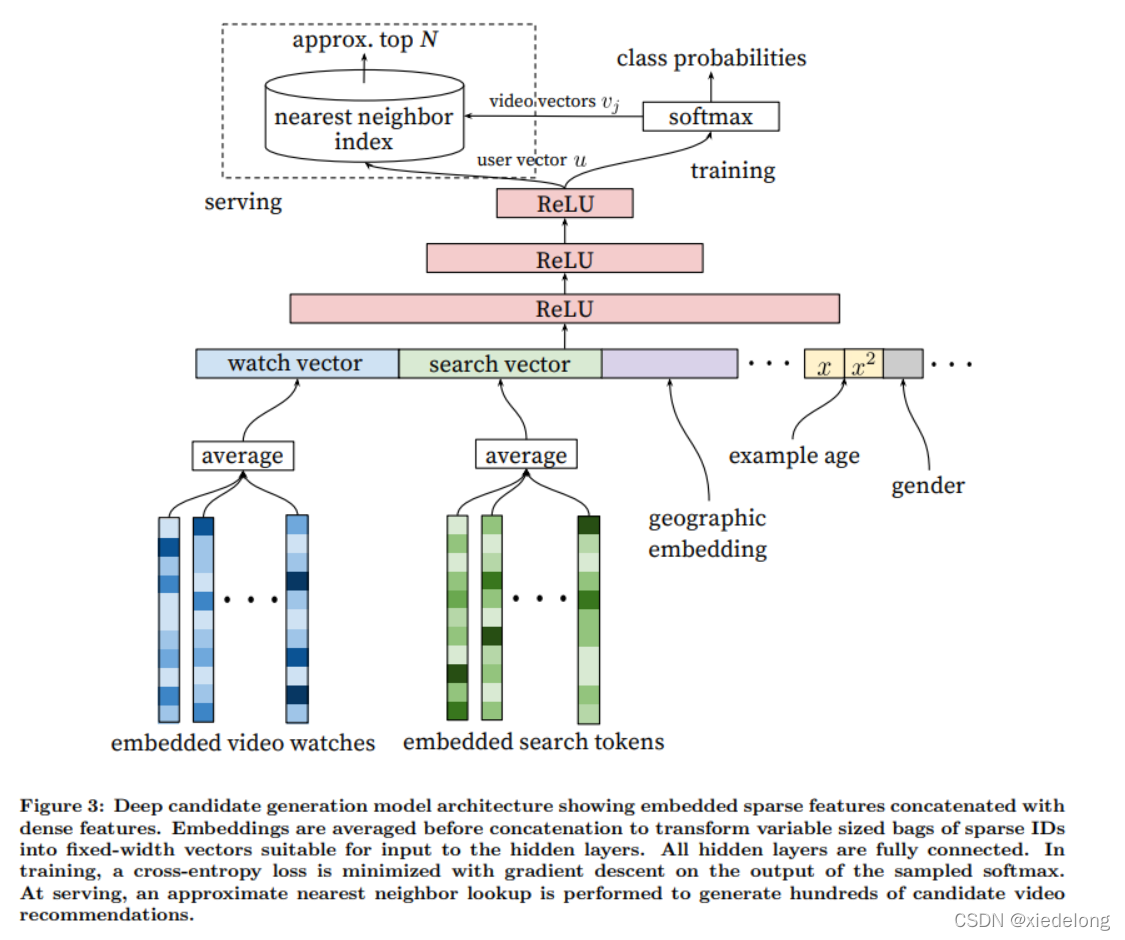
模型架构
- 用户的观看历史由一个可变长度的稀疏视频 id 序列表示,该序列通过嵌入映射到稠密向量表示,之后进行 avg pooling(在求和、最大值、平均等中表现最好)。输入的是 video id,通过 embedding 层进行嵌入,嵌入是通过正常梯度下降反向传播更新与所有其他模型参数一起学习的,实际使用时,输入的 watched video 是被预先 embedding 成 n 维向量(可以是256,也可以是128)作为 dense vector 输入到 input layer;
- 历史 search query 特征同样的 tokenized 后进行 embedding
- 人口统计特征对于提供先验信息很重要,这样推荐才能对新用户做出合理的反应
- 用户的地理区域(城市、常驻地)和设备,这些枚举值特征也进行 embedding 并连接起来。
- 简单的二进制和连续特征,如用户的性别、登录状态和年龄,归一化为[0, 1] 后直接输入到网络中
- 特征被连接到一个宽的第一层,接着是几层全连接的整流线性单元(ReLU)
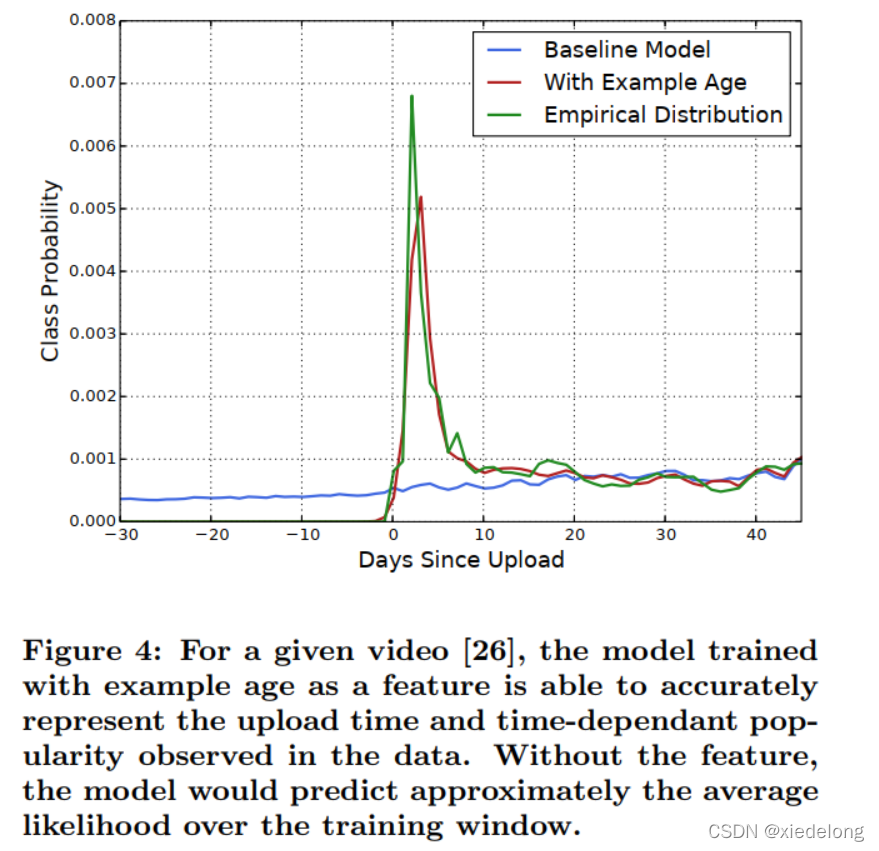
“Example Age” Feature
每秒钟都有很多视频被上传,用户更喜欢(与之相关的)新鲜的内容。同时可以引导内容的传播
- 按照文章的说法,会直接把 sample log 距离当前(训练时)的时间作为 example age。比如24小时前的日志,这个example age就是 24。
- 为什么这么做:通过example age 这一维特征,模型可以学到 example age 越小的样本(也就是离训练这一时刻越近的样本),更符合用户当前的兴趣(应该需要和 userid 进行交叉使用,类似于 DIN 对用户兴趣序列进行建模,得到用户长中短期兴趣),从而在模型中权重更大。所以在serving的时候,example age设为 0,或者是很小的负值,来说明我需要预测用户现在这一刻的兴趣。
- 参考:这个特征的用处按我理解可以这样描述:比如某个视频点击集中在7天前(比如7天前点击率10%),训练前这个时间点点击率比较低(训练前10分钟点击率3%),模型学出来之后预测的时候把Example Age置为0去预测,预测出这个视频点击率就会更接近3%。同理如果某视频以前不火,训练前突然火了,预测的时候Example Age置为0就可以预测到更高的点击率。如果不带Example Age,模型学出来的该视频点击率更接近于这个训练区间下这个视频平均点击率。
- 在做模型 serving 的时候,不管使用哪个 video,会直接把这个 feature 设成 0,因为:显然在召回阶段用户还没收到推荐的结果, 因此log时间(Youtube假设它推荐的每个视频用户都会点击,log时间就是用户(将要)点击视频的时间, 这个想法很合理)应该比召回时间稍微晚一会儿,所以age <= 0
Label and Context Selection
- 训练样本使用的是所有 Youtube 观看生成的,而不仅仅是模型推荐的(应该是有其他的访问方式)
- 采样时,为每个用户生成固定数量的训练样本,可以有效的在损失函数中平衡所有用户,避免高活用户的影响
- 必须非常小心地向分类器隐瞒信息,以防止过拟合,case:如加入用户刚刚搜索了 ‘taylor swift’ 这个特征。由于我们的问题是预测下一个观看的视频,分类器将预测:最有可能被观看的视频是那些出现在 taylor swift 相应搜索结果页面上的视频。不出所料,将用户的最后一个搜索页面复制为主页推荐效果非常差。
- 因此,通过丢弃序列信息并使用无序的 bag of tokens 表示搜索 query ,分类器将不再直接知道标签的来源
特征和深度的实验
- 最大的 watched video 个数,和最大的历史 search query 个数都是 50
- 网络结构遵循一个常见的 “塔” 模式,即网络底部最宽,每个连续的隐藏层将单元数量减半
排序
在排序过程中,可以构造更多视频的特征,以及用户和视频的相关性特征,且可以对不同源的候选集进行排序(使用 logistic regression)。优化目标是:曝光视频的观看时间,如果用点击率优化,会导致经常推广欺骗性的视频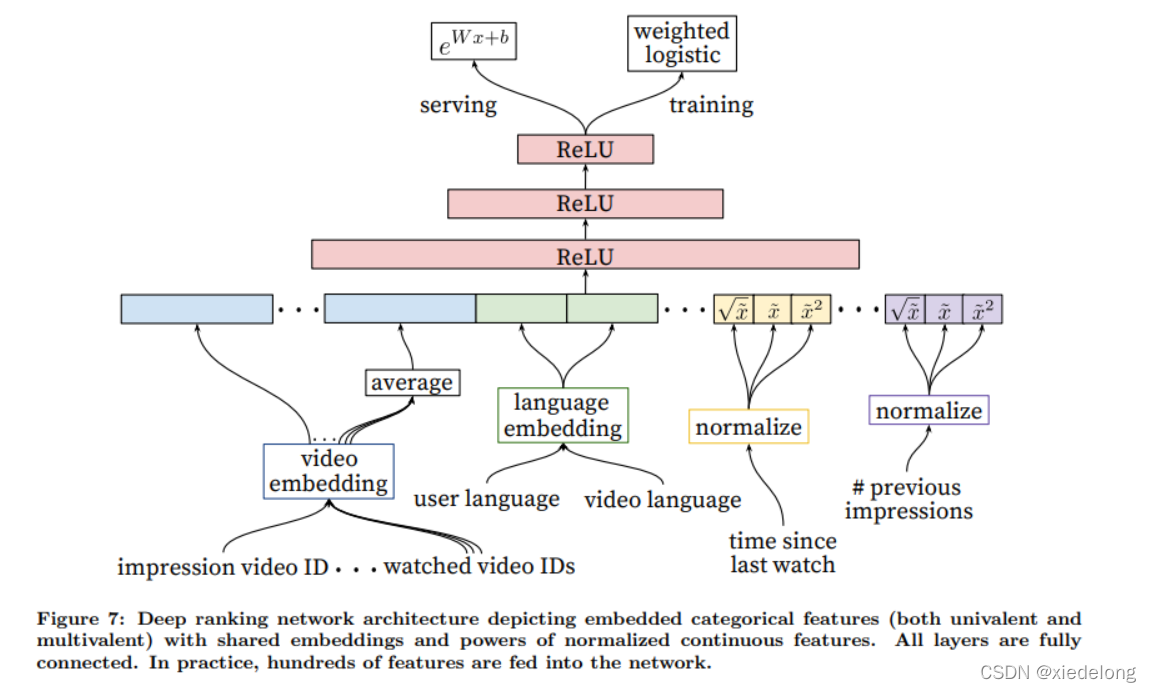
- impression video ID:待排序的 video
- watched video IDs:用户最近观看的 n 个 video,并进行 average
- language:枚举值特征 embedding
- normalize:连续值特征的归一化
特征表达
- 特征有:连续特征、分类特征(单个,case 当前待排序 video id),分类特征(多个,case 用户最后观看的 n 个 video id),search query 每个请求计算一次,video 特征对每个待排序的 item 计算一次
- 重点是构造用户历史观看的视频特征,与当前待排序特征的交叉(relate)特征,如:用户在当前类别/频道看了多少视频,用户上一次在该频道看视频是什么时候等
- 另外:该 video 是从哪个召回源推荐的,召回的 score 是多少,这些特征也很重要
- 描述 video 历史曝光量也很重要,可以评估它的流失率,原文中应该是说交叉特征:用户上一次曝光了某个类别的视频,但是没有观看,这个特征对于当前用户的下一次请求很重要(模型会降低曝光)
- embedding 特征:dim 维数一般是 ID 个数(or 枚举值个数)的 log ,同时 vocabulary 会按照频次排序,进行点击截断,末尾的特征映射到 zero embedding
- 所有的 ID 共享一个 embedding(图中的 video embedding,不管输入是哪个 id 特征,都会经过这个共享的 embedding 层),可以提高泛化能力,加快训练速度,模型的主要参数量都在 embedding 中,要比全连接层的参数大很多倍
- 对于连续型特征,使用累积分位数归一映射到0-1的值,并且将 x2 和 √x 一并作为输入,增加非线性
建模期望观看时长
- 我们的目标是预测期望观看时长。有点击的为正样本,有曝光无点击的为负样本,正样本需要根据观看时长进行加权(权重为观看时长),负样本是单位权重(1)。因此训练阶段网络最后一层用的是 weighted logistic regression。
- odds 表示机会比的意思:假设一件事情发生的概率是 p,那么 Odds 就是一件事情发生和不发生的比值
odds = p / (1-p)
因此对于论文中的odds = sum( Ti ) / ( N - k ),,即:正样本出现的概率和/负样本出现的概率和
- 其中 Ti 表示第 i 个视频的观看时长
- N 表示所有样本
- k 表示正样本
- 所以分子表示正样本发生概率,分母表示负样本发生概率
所以观看的期望 E(T) = ∑(Ti) / N = odds * (N - k) / N,所以 odds = ∑(Ti) * N / (N - k) ~= ∑(Ti),所以我们最终可以用 odds 来估计expected watch minutes,因此在 serving 的时候,即为 watch_minutes_per_impression 的估计值。
参考:
https://juejin.cn/post/6844903703573446670
https://zhuanlan.zhihu.com/p/61827629
线上使用
- 输入的 watched video 被 embedding 成 n 维向量(可以是256,也可以是128)作为 dense vector 输入到 input layer;
- softmax 这里输出的维度取决于你的隐含层最后一层的 units 数目(可以是256,可以是别的);
- 输入训练 input layer 的 video embedding 可以预训练,也可以在网络中学习,而最后用作线上预测的视频 vector 是 softmax 矩阵的权重,是通过 DNN 学习出来的,注意:这个视频 vector 不是输入到 input layer 的 embedding。

















 2378
2378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









