






随着短视频平台的火爆,越来越多的创作者希望制作出吸引人的视频内容。
然而,撰写一个既有趣又具有吸引力的脚本并非易事,它需要创意、时间和专业知识。为了帮助创作者们提高效率,目前AI技术已经被引入到脚本创作过程中。
在这篇文章中,我将为大家介绍如何用AI写脚本,从而简化创作流程,让视频制作变得更加轻松和高效。

✚借助【AI写作宝】
这是一款专为内容创作者设计的免费AI写作助手,它可以帮助我们快速生成文章、视频脚本、广告文案等内容。
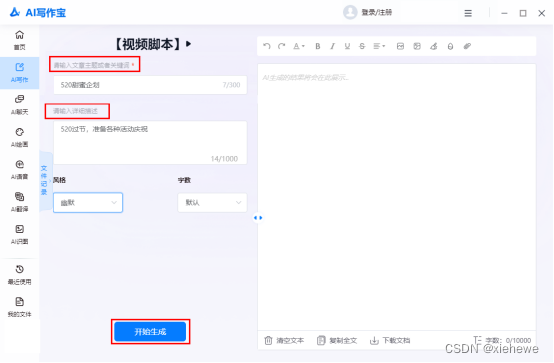
▷AI生成视频脚本操作步骤:
①打开软件,找到“视频脚本”功能;
②输入视频主题或关键点,并对其进行详细介绍;
③接着调整风格和字数后,软件就会提供的信息生成一个视频脚本草稿;
④最后,我们可以根据需要调整和完善脚本。
✚借助【Chat GPT】
这是由Open AI开发的一个大型语言模型,它擅长理解和生成自然语言文本。借助这个功能,我们可以生成视频脚本。
▷AI生成视频脚本操作步骤:
①打开该软件的界面;
②在“输入框”中输入视频主题和想要传达的信息;
③接着软件就会根据描述提供视频脚本的大纲和建议;
④最后我们可以根据建议来编写或调整视频脚本。

✚借助【Notion AI】
这是一个多功能的笔记和任务管理工具,它可以帮助我们整理思路、生成内容和自动化工作流程。
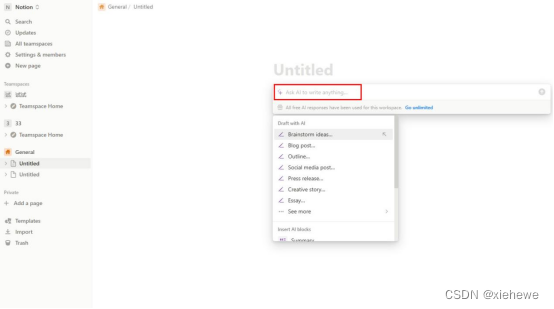
▷AI生成视频脚本操作步骤:
①打开软件并进入AI文章生成的工作区;
②输入需要生成的视频主题和关键词;
③接着软件就会根据主题和关键词,自动生成视频脚本;
④如果有不满意的地方,也可以直接让AI进行修改。
Tips:在选择视频脚本内容时,我们需要注意哪些东西?
1.主题相关性:确保AI生成的内容与视频的主题紧密相关,避免偏离主题。
2.内容准确性:检查AI生成的脚本中的事实和数据是否准确无误。
3.语言风格:根据目标观众和视频类型选择合适的语言风格,如正式、幽默、口语化等。
4.情感表达:视频脚本应能够传达适当的情感,与观众建立情感联系。
5.结构清晰:脚本应该有清晰的结构,包括引言、主体和结尾,且逻辑连贯。

今天的介绍到这里就要结束了,大家现在知道如何用AI写脚本了吧。这五个软件在视频脚本生成方面都有其独特的优势,大家可以根据自己的需求和喜好来选择使用哪一个。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









