







机器学习—决策树(ID3,C4.5)算法解析
Label 机器学习 决策树 解析
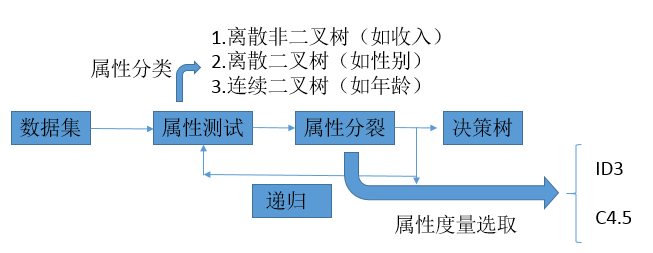
决策树实现思路:假设有已知的数据集X【例如某些人的集合,数据内容包括用于描述他们的特征属性及特征属性值,如性别(男|女),年龄(整数),收入(较低|中等|较高)等】,以及数据集的分类标签Y【是否是某俱乐部的成员(是|否)】,对数据集做特征属性测试【在当前可选的特征属性中选取最佳分裂属性,其评判标准为特征属性的度量值,一般越大越好,根据该度量值的计算不同,将决策树算法分为ID3和C4.5】,对数据集做属性分裂,其子类可再进行属性测试和属性分裂,直至可选属性为空或者子类不能分;不理解的概念参看本节备注
决策树是一种贪心算法,每次选取的分割数据的特征都是当前的最佳选择,并不关心是否达到最优。很容易在训练数据中生成复杂的树结构,造成过拟合(overfitting)。剪枝可以缓解过拟合的负作用,常用方法是限制树的高度、叶子节点中的最少样本数量。
1 ID3
ID3算法的核心思路是,在决策树的整体框架下,利用信息增益来作为属性度量值,取最大信息增益对应的特征属性作为最佳分裂属性对样本集做属性分裂;
以下引自:http://www.cnblogs.com/wxquare/p/5379970.html
【ID3决策树可以有多个分支,但是不能处理特征值为连续的情况。ID3算法十分简单,核心是根据“最大信息熵增益”原则选择划分当前数据集的最好特征,信息熵是信息论里面的概念,是信息的度量方式,不确定度越大或者说越混乱,熵就越大。在建立决策树的过程中,根据特征属性划分数据,使得原本“混乱”的数据的熵(混乱度)减少,按照不同特征划分数据熵减少的程度会不一样。在ID3中选择熵减少程度最大的特征来划分数据(贪心),也就是“最大信息熵增益”原则】
相关的定义:
信息熵: H(X)=−∑i=1Lpilog(pi) ; pi=|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









