






同步阻塞IO、同步非阻塞IO、IO多路复用、异步阻塞IO、异步非阻塞IO,这五种IO模型有没有朋友记过多次了,但是总是记不住?那是因为没有理解本质。5年前我记住了,到现在发现记忆和区分仍然很清晰,今天把理解方法介绍给大家。
首先,大家先思考一个问题:
IO操作其实主要为了读和写。本文以读数据做说明。
当程序调用read方法时,会切换到系统内核来完成真正的读取。而读取又分为等待数据和复制数据两个阶段。如下图所示:
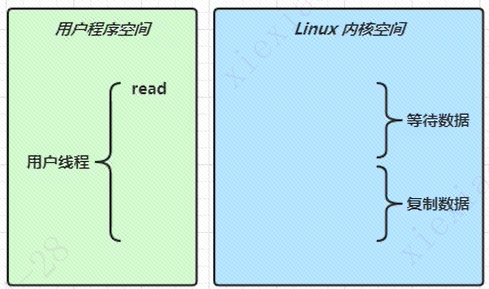
同步阻塞IO
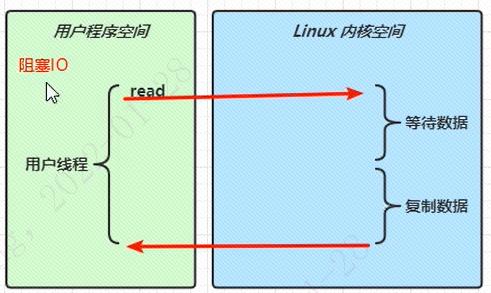
如上图所示,用户线程发起一个read请求,会切换到内核空间。这时候如果没有数据过来,则用户线程和对应的内核线程什么都做不了,一直等到有数据进来,并且完成了内核态的数据复制才继续返回用户空间继续执行。这整个过程是阻塞的。
同步非阻塞IO
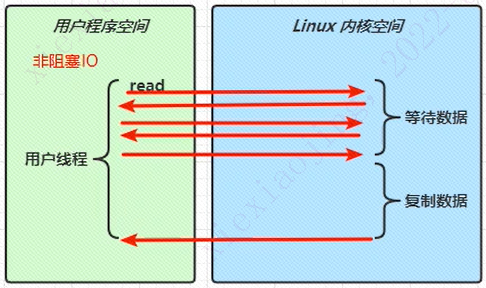
如上图所示,用户线程发起一个read请求,会切换到内核空间。这时候如果没有数据过来,则直接返回。它可以再次轮循发起read,如果某一次发现有数据过来,则等待完成了内核态的数据复制才继续返回用户空间继续执行。
这个过程中,没有数据时是非阻塞的。有数据时是阻塞的,被称为非阻塞IO。这种方式涉及多次内核切换,某些情况下反而会影响性能。之前业界发生过一个由阻塞切换成非阻塞,流量高峰时性能不足引起的重大故障。
IO多路复用
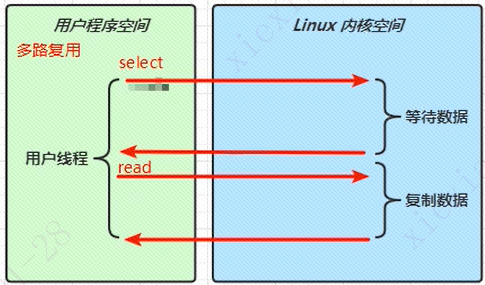
如上图所示,用户线程发起一个select请求,会切换到内核空间。这时候如果没有数据过来,则阻塞直到有数据时返回给用户线程。用户线程收到有数据的消息,发起read操作同步等待直到完成内核态的数据复制才继续返回用户空间继续执行。
这时候,是不是有朋友冒出来一个问题:似乎看不到多路复用的优势啊。似乎阻塞才是最佳选择啊。
上面都是以最简单的例子来介绍的,下面来看一个复杂一些的阻塞IO。
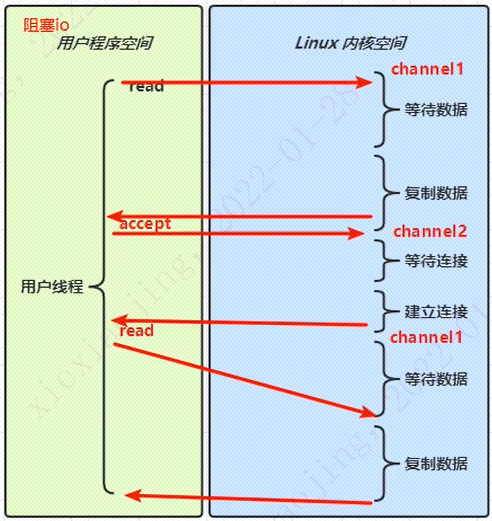
如上图所示,用户线程发起一个read请求,会切换到内核空间。这时候又有另外一个连接请求过来。这个线程不会立即影响这个连接请求,而是一直等到有数据进来,并且完成了内核态的数据复制才继续返回用户空间继续执行。处理完第一个连接的所有read操作之后,才会响应新的连接。新连接从accept(netty中建立连接的函数)到read都是同步阻塞的,每次只能处理一个连接的事件。
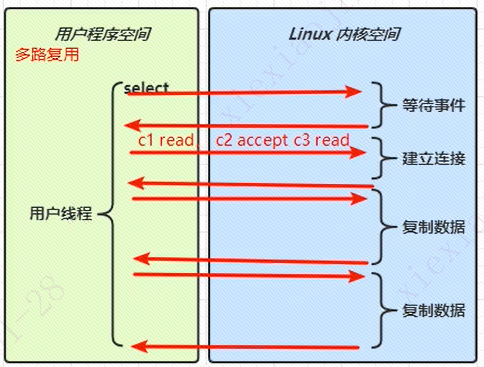
如上图所示,多路复用时,用户程序发起一个select操作,会返回一批事件,有read、write、accept(netty中建立连接的事件)。这时候,该等的时间select操作都已经做了。这时候,用户线程可以用新的线程(worker线程)直接去建立连接、复制数据。
异步非阻塞IO
这里就要明确IO模型中,同步和异步的概念了。
同步:线程自己去获取结果。(一个线程)
异步:线程自己不去获取结果,而由其他线程送结果。(至少两个线程)
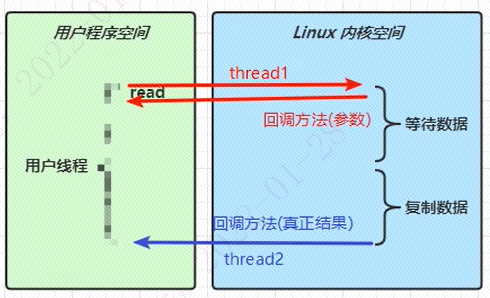
如上图所示,异步是通过回调来完成的。用户程序发起read操作只是去通知操作系统我在等待数据。另外一个线程等待数据复制完成回调read方法返回结果。异步IO从实现上是基于操作系统信号驱动的,也叫信号驱动IO。
异步阻塞IO和异步非阻塞IO又有什么区别呢?看上面的过程,异步read操作去通知完操作系统肯定是直接返回的,也就是肯定是非阻塞的。其实根本没有异步阻塞这种说法,纯属误传。
总结
最近发现,为了把一件事情讲清楚,要写的字越来越多。因为写的过程中会引出一些额外层面的问题需要解释。两者没有分离好反而不好理解。
我就想出来现在的办法,先在一篇文章中阐述一件事,同时抛出来一个问题让大家思考。然后另起一篇把问题讲透。就像本周的《HTTP状态码1XX深入理解》和《【答案公布】客户端与服务端通信时,所有的http状态码是否都是服务端返回的?》。自己觉得这种方式更加清晰,大家觉得如何呢?















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









