






1、Fully Convolutional Network-Based Multifocus Image Fusion
2、论文提及数据集制作方式
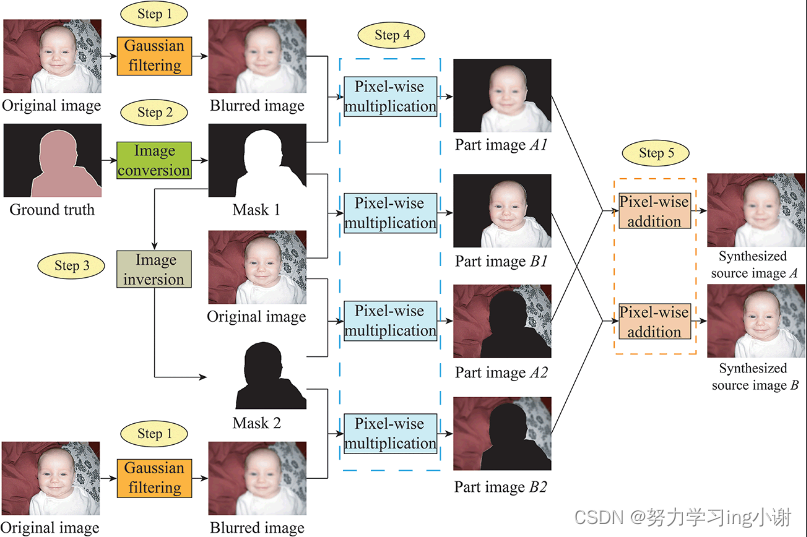
一对多焦点图像的合成程序示意图。该程序有五个步骤:高斯滤波、图像转换、图像反转、像素化乘法和像素化加法。首先,我们使用高斯滤波来产生各种版本的模糊图像。在图像转换和图像反转中,我们利用地面真实图像产生两个三通道的二进制掩码,分别用于聚焦模糊图像中的前景和背景。接下来,根据二进制掩码和原始图像产生部分图像,其中只包含前景或背景的焦点区域或失焦区域。最后,一对合成的多焦点图像可以从一对部分图像中得到。A1和A2或B1和B2。
3、Python PIL复现(VOC2012_240以及子文件夹代码会自己创建,只需要在项目下加入VOC2012以及两个子文件夹)
import os
import cv2
import argparse
import random
import numpy as np
def Ramdom_GaussianBlur(input):
blur_levels = [(5, 5), (7, 7), (9, 9), (11, 11),(13,13),(15,15)] # 不同的模糊级别,每个元素是一个元组,包含了高斯核的大小
selected_level = random.choice(blur_levels) # 随机选择一个模糊级别
out = cv2.GaussianBlur(input, selected_level, 0) # 使用选定的模糊级别进行高斯模糊处理
return out
def make_mask(gt):
mask=np.zeros_like(gt)
mask[gt == 220] = 0
mask[mask!=0]=255
return mask
def trans(input_path1,input_path2,mode='train'):#mode=0 train mode=1 test
Original_img = cv2.imread(input_path1).astype(np.float32) / 255.0
Mask1_img=cv2.imread(input_path2,0)
Mask1_img[Mask1_img==220]=0
Mask1_img[Mask1_img != 0] = 255
Mask1_img=Mask1_img.astype(np.float32) / 255.0
Mask2_img = 1 - Mask1_img
Blurred_img = Ramdom_GaussianBlur(Original_img)
Mask1_img = np.stack((Mask1_img, Mask1_img, Mask1_img), axis=-1)
Mask2_img = np.stack((Mask2_img, Mask2_img, Mask2_img), axis=-1)
Synthesized_imgA = Mask1_img * Original_img + (1 - Mask1_img) * Blurred_img
Synthesized_imgB = Mask2_img * Original_img + (1 - Mask2_img) * Blurred_img
result_root1 = os.path.join(os.getcwd(), args.out_dir_name, mode, 'sourceA')
result_root2 = os.path.join(os.getcwd(), args.out_dir_name, mode, 'sourceB')
result_root3 = os.path.join(os.getcwd(), args.out_dir_name, mode, 'decisionmap')
result_root4 = os.path.join(os.getcwd(), args.out_dir_name, mode, 'groundtruth')
# Synthesized_imgA save path
save_rootA = os.path.join(result_root1, os.path.split(input_path1)[1].split('.')[0])
# Synthesized_imgB save path
save_rootB = os.path.join(result_root2, os.path.split(input_path1)[1].split('.')[0])
# mask save path
save_rootC = os.path.join(result_root3, os.path.split(input_path1)[1].split('.')[0])
# ori save path
save_rootD = os.path.join(result_root4, os.path.split(input_path1)[1].split('.')[0])
cv2.imwrite(save_rootA + '.jpg', (Synthesized_imgA * 255).astype(np.uint8))
cv2.imwrite(save_rootB + '.jpg', (Synthesized_imgB * 255).astype(np.uint8))
cv2.imwrite(save_rootC + '.png', (Mask1_img * 255).astype(np.uint8))
cv2.imwrite(save_rootD + '.jpg', (Original_img * 255).astype(np.uint8))
def main(args):
# 创建文件夹
dirname = args.out_dir_name
if os.path.exists(dirname) is False:
os.makedirs(dirname)
if os.path.exists('{}/train'.format(dirname)) is False:
os.makedirs('{}/train'.format(dirname))
if os.path.exists('{}/test'.format(dirname)) is False:
os.makedirs('{}/test'.format(dirname))
if os.path.exists('{}/train/sourceA'.format(dirname)) is False:
os.makedirs('{}/train/sourceA'.format(dirname))
if os.path.exists('{}/train/sourceB'.format(dirname)) is False:
os.makedirs('{}/train/sourceB'.format(dirname))
if os.path.exists('{}/test/sourceA'.format(dirname)) is False:
os.makedirs('{}/test/sourceA'.format(dirname))
if os.path.exists('{}/test/sourceB'.format(dirname)) is False:
os.makedirs('{}/test/sourceB'.format(dirname))
if os.path.exists('{}/test/groundtruth'.format(dirname)) is False:
os.makedirs('{}/test/groundtruth'.format(dirname))
if os.path.exists('{}/train/groundtruth'.format(dirname)) is False:
os.makedirs('{}/train/groundtruth'.format(dirname))
if os.path.exists('{}/test/decisionmap'.format(dirname)) is False:
os.makedirs('{}/test/decisionmap'.format(dirname))
if os.path.exists('{}/train/decisionmap'.format(dirname)) is False:
os.makedirs('{}/train/decisionmap'.format(dirname))
#os.getcwd():E:\pycharmproject\makeupdatasets_voc2012
data_root=args.data_root#数据集位置E:\pycharmproject\makeupdatasets_voc2012\VOC2012
Ground_list_name = [i for i in os.listdir(os.path.join(data_root,'SegmentationObject'))if i.endswith('png')]
Ground_list=[os.path.join(data_root,'SegmentationObject',i)for i in Ground_list_name]
Original_list=[os.path.join(data_root,'JPEGImages',i.split('.')[0]+'.jpg')for i in Ground_list_name]
for i in range(len(Ground_list)):
if i<=int(len(Ground_list)*0.85):#0.7就是 (训练:测试)=(7:3)
trans(Original_list[i],Ground_list[i],'train')
print('finish no.', i + 1, 'for train datasets')
else:
trans(Original_list[i], Ground_list[i],'test')
print('finish no.', i + 1, 'for test datasets')
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Make dataset for training')
parser.add_argument('--rate', type=float, default=0.85,
help='split rate')
parser.add_argument('--data_root', type=str,
default=r'E:\pycharmproject\makeupdatasets_voc2012\VOC2012', help='DUTS path')
parser.add_argument('--out_dir_name', type=str, default='VOC2012_MFF')
args = parser.parse_args()
main(args)
4、从DUTS数据集制作多聚焦数据集已更新,代码的复用性也改了一下,看这个吧
# -*- coding: utf-8 -*-
# @Author : XinZhe Xie
# @University : ZheJiang University
import os
import random
import numpy as np
import cv2
import argparse
def Ramdom_GaussianBlur(input):
blur_levels = [(5, 5), (7, 7), (9, 9), (11, 11),(13,13),(15,15)] # 不同的模糊级别,每个元素是一个元组,包含了高斯核的大小
selected_level = random.choice(blur_levels) # 随机选择一个模糊级别
out = cv2.GaussianBlur(input, selected_level, 0) # 使用选定的模糊级别进行高斯模糊处理
return out
def trans(args,input_path1,input_path2,mode):
Original_img = cv2.imread(input_path1).astype(np.float32) / 255.0
Mask1_img = cv2.imread(input_path2).astype(np.float32)/ 255.0
Mask2_img = 1 - Mask1_img
Blurred_img = Ramdom_GaussianBlur(Original_img)
Synthesized_imgA=Mask1_img*Original_img+(1-Mask1_img)*Blurred_img
Synthesized_imgB=Mask2_img*Original_img+ (1-Mask2_img)*Blurred_img
result_root1 = os.path.join(os.getcwd(), args.out_dir_name,mode,'sourceA')
result_root2 = os.path.join(os.getcwd(), args.out_dir_name,mode,'sourceB')
result_root3 = os.path.join(os.getcwd(), args.out_dir_name,mode,'decisionmap')
result_root4 = os.path.join(os.getcwd(), args.out_dir_name,mode,'groundtruth')
#Synthesized_imgA save path
save_rootA = os.path.join(result_root1,os.path.split(input_path1)[1].split('.')[0])
#Synthesized_imgB save path
save_rootB = os.path.join(result_root2,os.path.split(input_path1)[1].split('.')[0])
#mask save path
save_rootC = os.path.join(result_root3,os.path.split(input_path1)[1].split('.')[0])
#ori save path
save_rootD = os.path.join(result_root4,os.path.split(input_path1)[1].split('.')[0])
cv2.imwrite(save_rootA + '.jpg', (Synthesized_imgA * 255).astype(np.uint8))
cv2.imwrite(save_rootB + '.jpg', (Synthesized_imgB * 255).astype(np.uint8))
cv2.imwrite(save_rootC + '.png', (Mask1_img * 255).astype(np.uint8))
cv2.imwrite(save_rootD + '.jpg', (Original_img * 255).astype(np.uint8))
def main(args):
dirname=args.out_dir_name
if os.path.exists(dirname) is False:
os.makedirs(dirname)
if os.path.exists('{}/train'.format(dirname)) is False:
os.makedirs('{}/train'.format(dirname))
if os.path.exists('{}/test'.format(dirname)) is False:
os.makedirs('{}/test'.format(dirname))
if os.path.exists('{}/train/sourceA'.format(dirname)) is False:
os.makedirs('{}/train/sourceA'.format(dirname))
if os.path.exists('{}/train/sourceB'.format(dirname)) is False:
os.makedirs('{}/train/sourceB'.format(dirname))
if os.path.exists('{}/test/sourceA'.format(dirname)) is False:
os.makedirs('{}/test/sourceA'.format(dirname))
if os.path.exists('{}/test/sourceB'.format(dirname)) is False:
os.makedirs('{}/test/sourceB'.format(dirname))
if os.path.exists('{}/test/groundtruth'.format(dirname)) is False:
os.makedirs('{}/test/groundtruth'.format(dirname))
if os.path.exists('{}/train/groundtruth'.format(dirname)) is False:
os.makedirs('{}/train/groundtruth'.format(dirname))
if os.path.exists('{}/test/decisionmap'.format(dirname)) is False:
os.makedirs('{}/test/decisionmap'.format(dirname))
if os.path.exists('{}/train/decisionmap'.format(dirname)) is False:
os.makedirs('{}/train/decisionmap'.format(dirname))
Ground_list_name = [i for i in os.listdir(os.path.join(args.data_root,'DUTS-{}'.format(args.mode),'DUTS-{}-Mask'.format(args.mode)))if i.endswith('png')]#MASK
Ground_list=[os.path.join(args.data_root,'DUTS-{}'.format(args.mode),'DUTS-{}-Mask'.format(args.mode),i)for i in Ground_list_name]
Original_list=[os.path.join(args.data_root,'DUTS-{}'.format(args.mode),'DUTS-{}-Image'.format(args.mode),i.split('.')[0]+'.jpg')for i in Ground_list_name]#原图
for i in range(len(Ground_list)):
if args.mode=='TR':
trans(args,Original_list[i],Ground_list[i],'train')
print('finish no.', i + 1, 'for train datasets')
else:
trans(args,Original_list[i], Ground_list[i],'test')
print('finish no.', i + 1, 'for test datasets')
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Make dataset for training')
parser.add_argument('--mode', type=str,default='TR', help='TE/TR,Correspond to making training set or verification set respectively.')
parser.add_argument('--data_root', type=str, default=r'C:\Users\dell\Desktop\Working\GAN_MFF\code_gan_mff\DUTS',help='DUTS path')
parser.add_argument('--out_dir_name', type=str, default='DUTS_MFF')
args = parser.parse_args()
main(args)















 3362
3362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









