









引入
在了解信息熵和信息增益之前我们先明确以下几个概念:
1.信息:某人(模型)判断一个宏观态属于哪个微观态时对我们判断有所帮助的物理量,以上简单来说就是信息就是分类时有用的东西。它的作用有调整概率、排除干扰、确定某种情况等。
2.概率:某件事(宏观态)属于某个情况(微观态)的确定性。
3.熵:某人(模型)对于某件事(宏观态)属于某个情况(微观态)的不确定性。
决策树
由于信息熵和信息增益在决策树中是个较为重要的应用,所以我们在这里先介绍决策树。
- 决策树希望从给定训练数据集学得一个模型用以对新示例进行分类。一棵决策树的根节点包含的是样本全集,内部结点表示各种判断元素,每个节点的连接路径对应一个判断测试序列,叶子结点即表示分类结果。
- 决策树是基于树结构来进行决策的,看起来比较简单,但在实际操作过程中,我们不仅要考虑要将数据的哪些属性纳入决策树判断来,而且要考虑这些属性在决策树中作用的先后顺序。
如果对上面所说的属性在决策树中的优先度无法理解的话,请尝试理解一下这个例子:对于一堆在商场里售卖的衣服,它们有颜色、长度、品牌、材质等属性,每件衣服的以上属性都不相同,我们想要使用决策树来判断出哪些衣服是当季流行的或不流行的;对于树形结构如下图,每个分叉结点就代表一次属性的决策,每个属性判断的先后顺序就是它们的优先度。
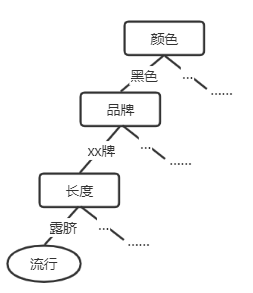
如何选择属性的优先度,我们就需要信息熵及信息增益来得出。
信息熵和信息增益
- 对于信息熵和信息增益的具体计算方法,就不在这里赘述了,推荐一定要去看一下推导过程,否则不太好理解。总之就是信息熵和信息增益可以判断出样本集合中各个属性的优先度,从而建立出决策树。
决策树建立:对于一个属性(如衣服颜色),我们先计算该属性里各个分支(如黑、白、粉)的信息熵,再由信息熵算出该属性的信息增益;算出该数据集所有属性的信息增益后,相比较即可知道哪个应该优先划分,信息增益最大的就应该做当前分支。随后分支建立之后,要再重新计算分别在不同的分支单独的信息熵和信息增益,如此重复。















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









