







10.1-决策树原理
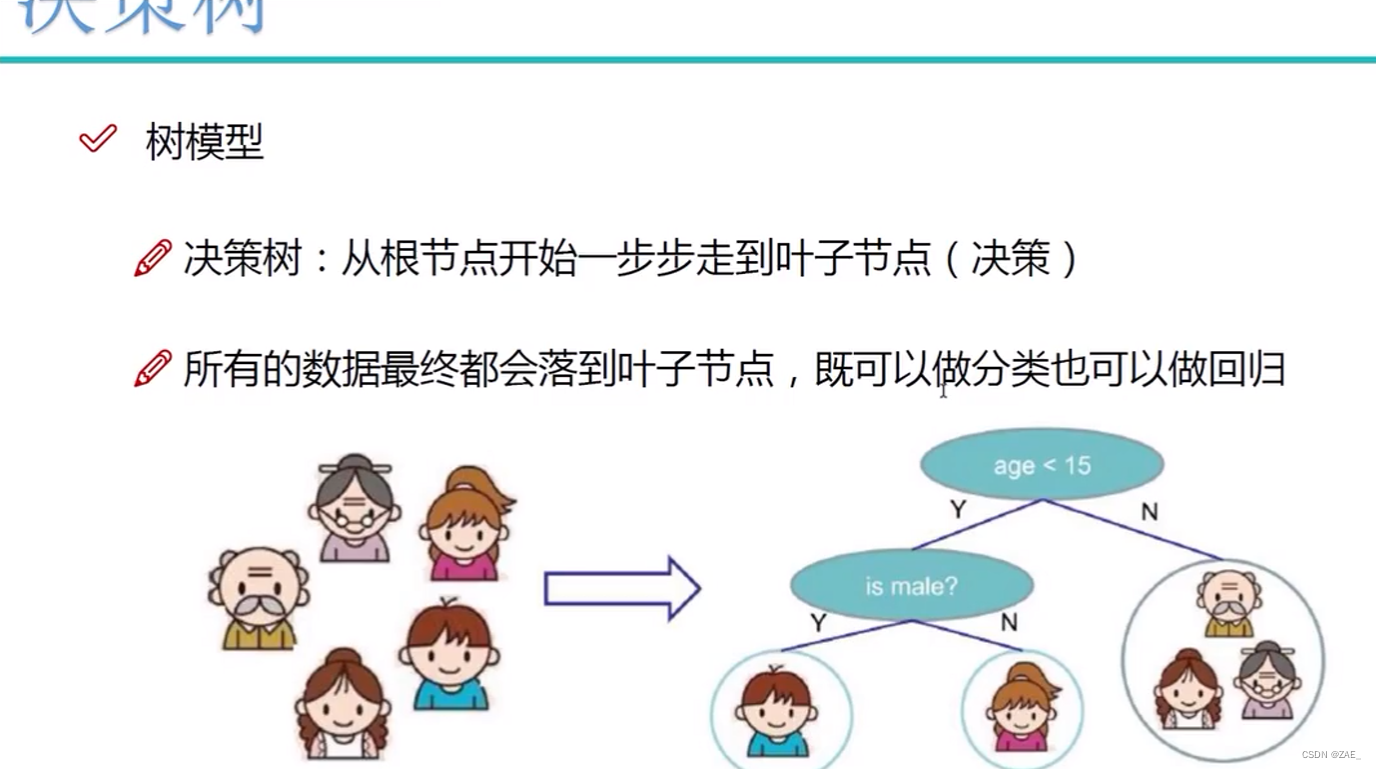
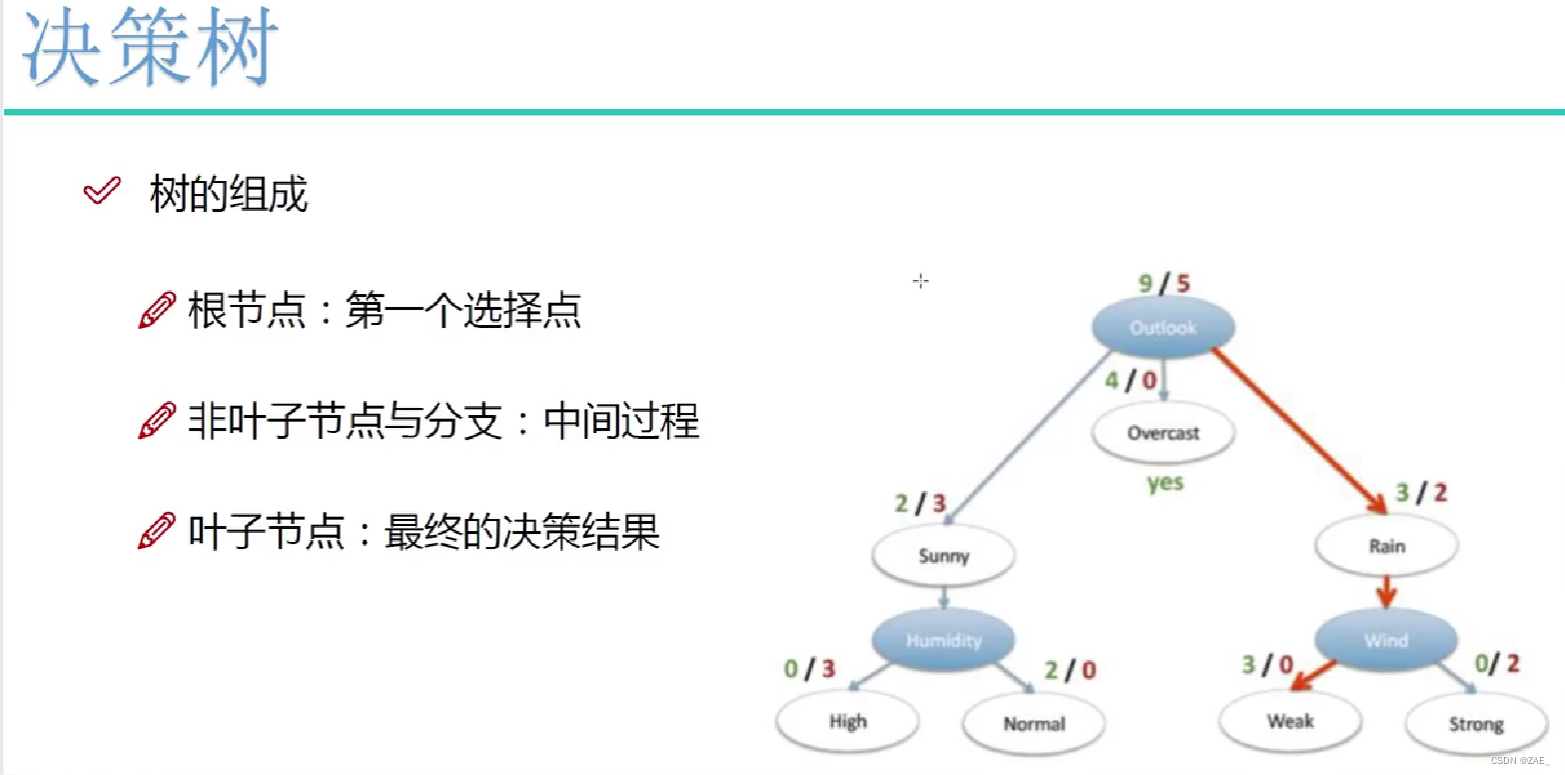

决策树是一种常用的机器学习算法,用于分类和回归问题。它通过构建一棵树状结构来表示决策过程,每个节点代表一个特征或属性,每个分支代表一个决策规则,每个叶节点代表一个类别或数值。以下是决策树的原理以及训练与测试流程:
决策树原理:
-
树的构建: 决策树的构建始于一个根节点,然后递归地选择最佳的特征来分割数据集,使得每个子集中的样本尽量属于同一类别(对于分类问题)或具有相似的数值(对于回归问题)。
-
特征选择: 在每个节点上,算法会评估所有可用特征,并选择最佳的特征来进行分割。通常使用信息增益、基尼不纯度或均方差等指标来评估特征的好坏。
-
树的生长: 决策树会不断生长,直到某个停止条件满足,例如达到最大深度、样本数不足以分割、基尼不纯度低于某个阈值等。
-
剪枝: 为了防止过拟合,可以对已构建的决策树进行剪枝操作,去除一些不必要的节点和分支。
决策树训练与测试流程:
-
数据准备: 首先,你需要准备带有标签的训练数据集。这些标签表示每个样本的目标类别(对于分类问题)或目标数值(对于回归问题)。
-
特征选择: 根据问题和数据集的特点,选择合适的特征用于训练决策树模型。这些特征应该能够很好地区分不同类别或预测目标数值。
-
训练模型: 使用训练数据集来构建决策树模型。这通常涉及到选择一个适当的特征分裂策略,并不断分割数据集直到满足停止条件为止。
-
模型评估: 使用测试数据集(不包含在训练数据中)来评估决策树模型的性能。你可以使用不同的评估指标,如准确率、精确度、召回率、F1 分数等(对于分类问题),或均方误差、R² 分数等(对于回归问题)。
-
调优: 根据模型的评估结果,你可以进行超参数调优、特征选择、剪枝等操作,以改善模型的性能。
-
预测: 一旦你满意于模型的性能,你可以使用训练好的决策树模型来进行新样本的预测。根据输入特征,模型会沿着树的节点进行决策,最终给出一个预测结果。
决策树是一个直观且易于理解的机器学习模型,但也容易过拟合训练数据。因此,在应用决策树模型时,需要注意调整模型的复杂度以避免过拟合,并使用适当的评估方法来评估模型的性能。
10.2-熵的作用

1. 如何切分特征(选择节点):
在决策树的构建过程中,选择哪个特征作为节点来分割数据是一个关键决策。这个过程通常基于以下几种策略之一:
-
信息增益(Information Gain): 信息增益是一种常用的特征选择标准,它基于信息论的概念。在每个节点上,计算每个可用特征的信息增益,选择具有最大信息增益的特征作为节点。信息增益衡量了通过特征分割数据后,不确定性减少的程度。
-
基尼不纯度(Gini Impurity): 基尼不纯度是另一种用于特征选择的标准。在每个节点上,计算每个可用特征的基尼不纯度,选择具有最小基尼不纯度的特征作为节点。基尼不纯度度量了从数据集中随机选择两个样本,它们不属于同一类别的概率。
-
均方差(Mean Squared Error): 均方差通常用于回归问题中。在每个节点上,计算每个可用特征的均方差,选择使得子集中样本的均方差最小的特征作为节点。
选择哪种特征选择标准取决于具体的问题和数据特征。信息增益和基尼不纯度通常用于分类问题,而均方差通常用于回归问题。

2. 熵的作用:
熵是信息论中的一个概念,用于衡量系统的混乱程度或不确定性。在决策树中,熵常常用来衡量数据集的不确定性,特别是在分类问题中。熵越高,表示数据集越混乱,样本属于不同类别的概率更均等;熵越低,表示数据集越有序,样本更倾向于属于同一类别。
在决策树的上下文中,熵的作用是帮助选择最佳的特征来分割数据。具体来说,熵的变化量被用作信息增益的度量。在每个节点上,计算当前数据集的熵,然后计算使用每个可用特征分割数据后的加权平均熵。信息增益就是原始熵减去分割后的平均熵,它衡量了通过选择某个特征进行分割后,数据集的不确定性减少了多少。通常情况下,选择信息增益最大的特征作为节点,因为这将使得决策树更快地将数据分类到不同类别中。
总之,熵在决策树中是一个关键概念,它帮助我们衡量数据集的不确定性,从而选择最佳的特征进行节点切分,以构建一个有效的决策树模型。
10.3-信息增益原理

当讨论决策树中熵的作用时,我们可以使用数学公式来更清晰地描述。熵是一个信息论概念,用来衡量系统的混乱程度或不确定性。在分类问题中,熵可以表示为以下数学公式:
熵(Entropy)的定义:
其中:
是数据集
的熵。
是数据集
是数据集
个类别的样本占总样本数的比例。
熵的计算基于每个类别在数据集中的分布,它衡量了数据集的不确定性。当所有样本都属于同一类别时,熵达到最小值为0,表示数据集是完全有序的。当不同类别的样本均匀分布时,熵达到最大值,表示数据集是最不确定的或混乱的。
在决策树中,熵的作用是帮助选择最佳的特征来分割数据。具体来说,我们可以使用信息增益来衡量特征选择的好坏。信息增益(Information Gain)可以表示为以下数学公式:
信息增益的定义:
其中:
是特征
对数据集
是特征
是特征
的子数据集。
表示数据集
信息增益的计算涉及以下步骤:
- 计算数据集
- 对于每个特征
- 计算每个子数据集
。
- 计算信息增益,即初始熵
选择信息增益最大的特征作为节点切分的特征,可以最大程度地降低数据集的不确定性,帮助构建一个更有效的决策树模型。这是因为信息增益衡量了通过选择某个特征进行分割后,数据集的不确定性减少了多少。
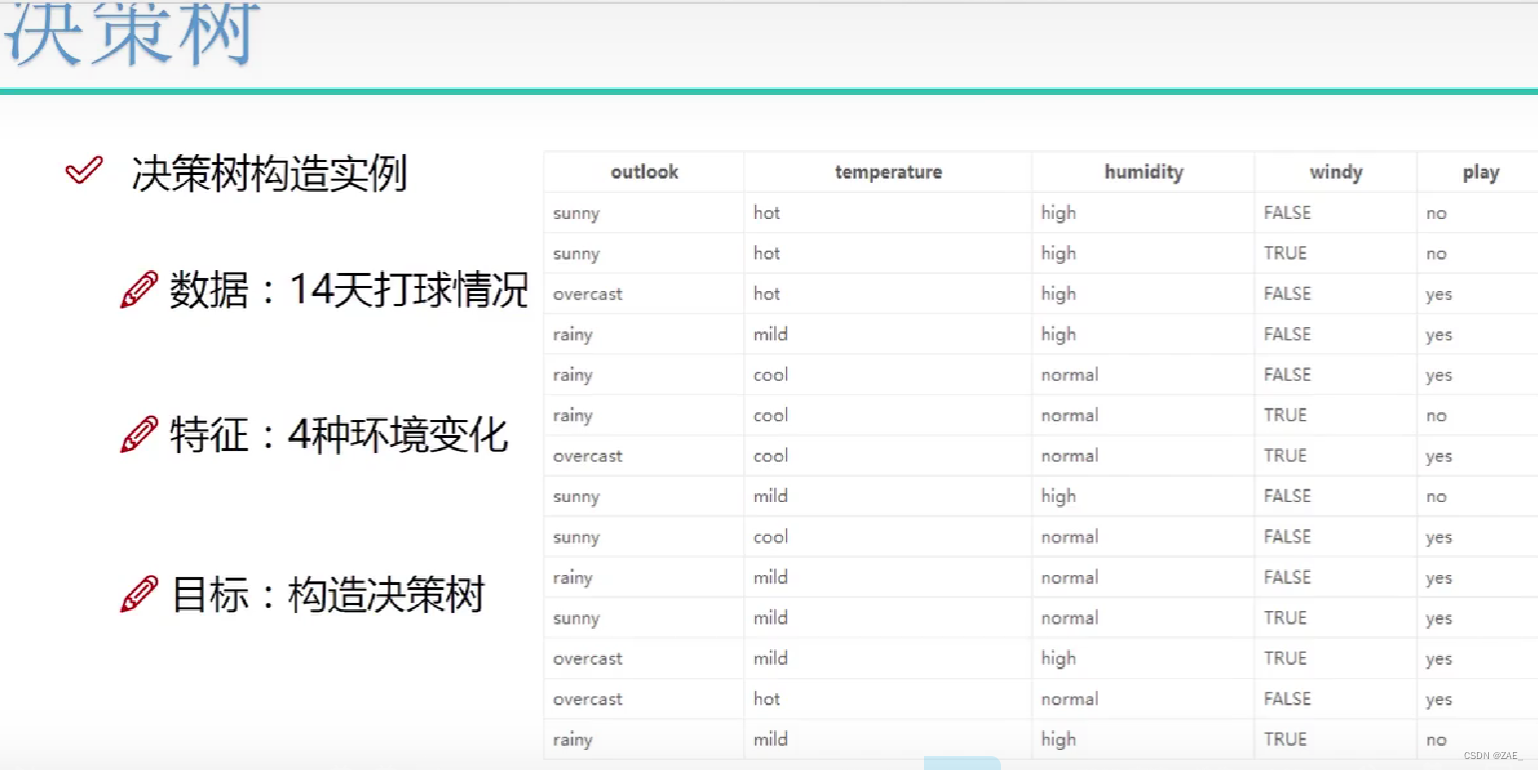
10.4-决策树构造实例



10.5-信息增益率与gini系数

信息增益率(Information Gain Ratio)和 Gini 系数是用于决策树算法中的特征选择标准,分别用于解决 ID3 算法中信息增益的问题和 CART 算法的不纯度度量问题。以下是它们的原理、用法和优势:
信息增益率(Information Gain Ratio):
信息增益率是用于改进 ID3 算法的特征选择标准。ID3算法存在一个问题,它偏向于选择具有更多可能取值的特征,因为这些特征通常会有更高的信息增益。信息增益率引入了一个归一化因子,解决了这个问题。
信息增益率的计算公式如下:
其中:
是特征
衡量了特征
信息增益率通过将信息增益除以特征的取值多样性来消除偏向于多值特征的问题。它更倾向于选择既有高信息增益又不会引入过多取值的特征。
Gini 系数:
Gini 系数是 CART(Classification and Regression Trees)算法中用于衡量不纯度的标准。在 CART 中,决策树的目标是最小化每个节点的 Gini 系数。
Gini 系数的计算公式如下:
其中:
是数据集
Gini 系数度量了从数据集中随机选择两个样本,它们不属于同一类别的概率。Gini 系数越低,表示数据集的不纯度越低,即数据更倾向于属于同一类别。
与信息增益率相比,Gini 系数在每个节点的计算更加简单,通常更快。此外,Gini 系数在处理二元分类问题时效果较好,但它不会像信息增益率那样受到特征取值数量的影响,因此不会过分偏向于多值特征。
总之,信息增益率和 Gini 系数都是用于特征选择和节点分割的重要标准,它们分别解决了不同决策树算法中的问题,从而提高了决策树模型的性能和稳定性。选择哪种标准通常取决于问题的性质和数据集的特点。
10.6-预剪枝方法
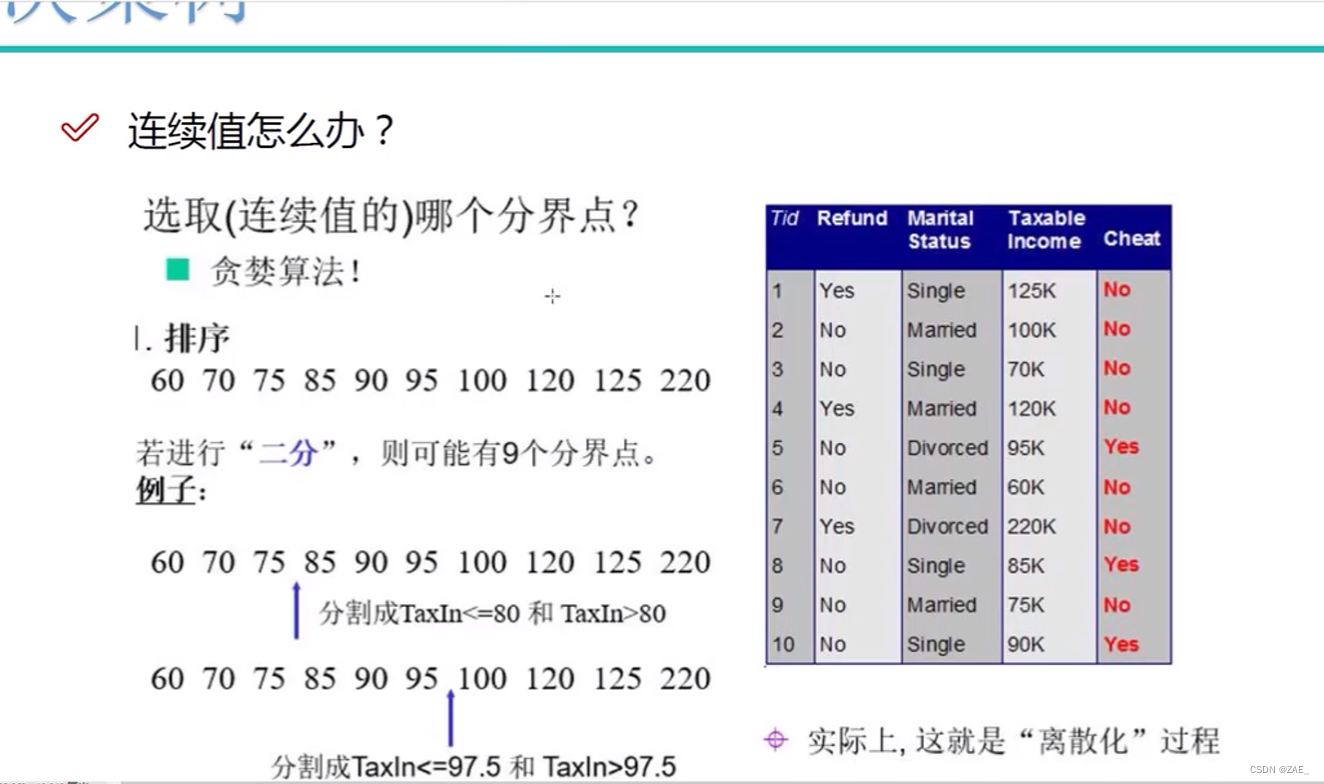
在决策树中遇到连续值的情况时,通常需要将连续特征(continuous feature)离散化(discretize),以便决策树算法能够处理它们。这个过程涉及使用贪婪算法,通常采用二分法进行切分,以将连续特征分成多个离散的取值区间。以下是关于如何处理连续特征的要点:
贪婪算法: 处理连续特征时通常使用贪婪算法,该算法会选择一个特征的最佳分割点,以最大程度地提高节点的纯度或信息增益。这个过程是自顶向下的,从根节点开始,对每个特征寻找最佳的分割点,然后将数据分割成两个子集,分别进一步处理。
二分切分: 在贪婪算法中,通常采用二分法进行切分。这意味着选择一个特征后,算法会对该特征的取值进行排序,并在取值之间的中点进行切分。这个切分点将数据分成两个子集,其中一个子集包含小于等于切分点的取值,另一个子集包含大于切分点的取值。
离散化过程: 连续特征的离散化过程可以简要描述如下:
- 对连续特征的取值进行排序。
- 针对每对相邻的取值,计算它们的中点作为一个候选切分点。
- 使用贪婪算法选择最佳的候选切分点,通常是通过衡量信息增益或基尼不纯度来选择。
- 将数据集划分为两个子集,一个包含小于等于切分点的取值,另一个包含大于切分点的取值。
- 在每个子集上递归应用相同的过程,直到满足预定义的停止条件,如树的深度达到最大值或节点的样本数小于某个阈值。
通过离散化连续特征,决策树算法可以处理这些特征,并根据切分点的选择将其纳入树的构建过程。这样,连续特征将被转化为离散特征,可以与其他离散特征一起用于树的节点分割和决策。这种方式使决策树更适合处理不同类型的特征,提高了模型的灵活性和性能。

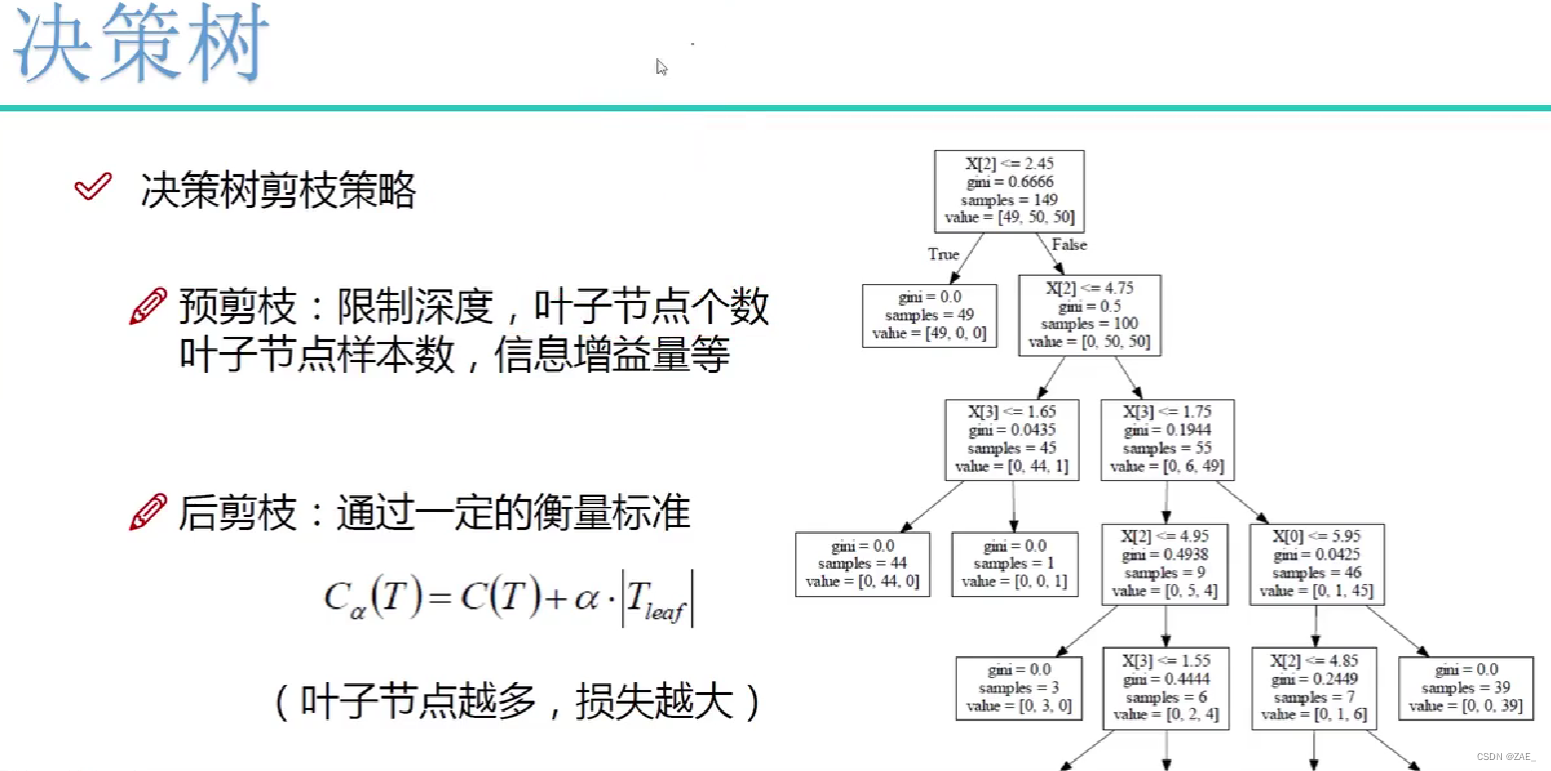
决策树预剪枝(Pre-pruning)是一种在构建决策树模型之前限制其生长的技术。预剪枝的主要目的是防止决策树过度拟合(Overfitting)训练数据,提高模型的泛化性能。以下是有关决策树预剪枝的背景、方法以及意义:
背景:
决策树是一种高度灵活的模型,它可以在训练数据上生成非常复杂的树状结构,以尽量准确地拟合训练数据。然而,如果树太深或太复杂,可能会导致过拟合问题,模型在新数据上表现不佳。为了解决这个问题,引入了预剪枝技术,它在构建树的过程中限制了树的深度、叶子节点个数、叶子节点样本数等。
方法:
以下是一些常见的决策树预剪枝方法:
-
限制深度(Max Depth): 设置决策树的最大深度,当达到这个深度时停止树的生长。这有助于防止树在训练数据上无限制地生长,限制了模型的复杂性。
-
限制叶子节点个数(Max Leaf Nodes): 设置叶子节点的最大数量。当达到这个数量时,停止树的生长。这可以有效地限制了树的复杂性。
-
限制叶子节点样本数(Min Samples per Leaf): 设置每个叶子节点所需的最小样本数。如果叶子节点的样本数量低于这个阈值,停止分裂。这有助于防止生成具有很少样本的叶子节点,从而减少了过拟合的风险。
-
信息增益量(Min Information Gain): 设置每次分裂至少需要达到的信息增益阈值。如果信息增益低于这个阈值,停止分裂。这确保了只有当分裂能够显著提高模型的性能时才会发生。
意义:
决策树预剪枝的主要意义在于:
-
防止过拟合: 预剪枝限制了决策树的复杂性,防止模型在训练数据上过度拟合,从而提高了在新数据上的泛化性能。
-
提高模型解释性: 较简单的决策树更容易解释和理解,因此预剪枝可以产生更可解释的模型。
-
减少计算成本: 较浅或较小的决策树需要更少的计算资源进行预测,因此可以减少模型的计算成本。
-
提高模型稳定性: 预剪枝可以减少模型对训练数据中噪声的敏感性,从而提高模型的稳定性。
总之,决策树预剪枝是一个重要的技术,用于调整决策树模型的复杂性,防止过拟合,并提高模型的性能和可解释性。选择合适的预剪枝方法通常需要根据具体问题和数据集的特点来决定。
10.7-后剪枝方法
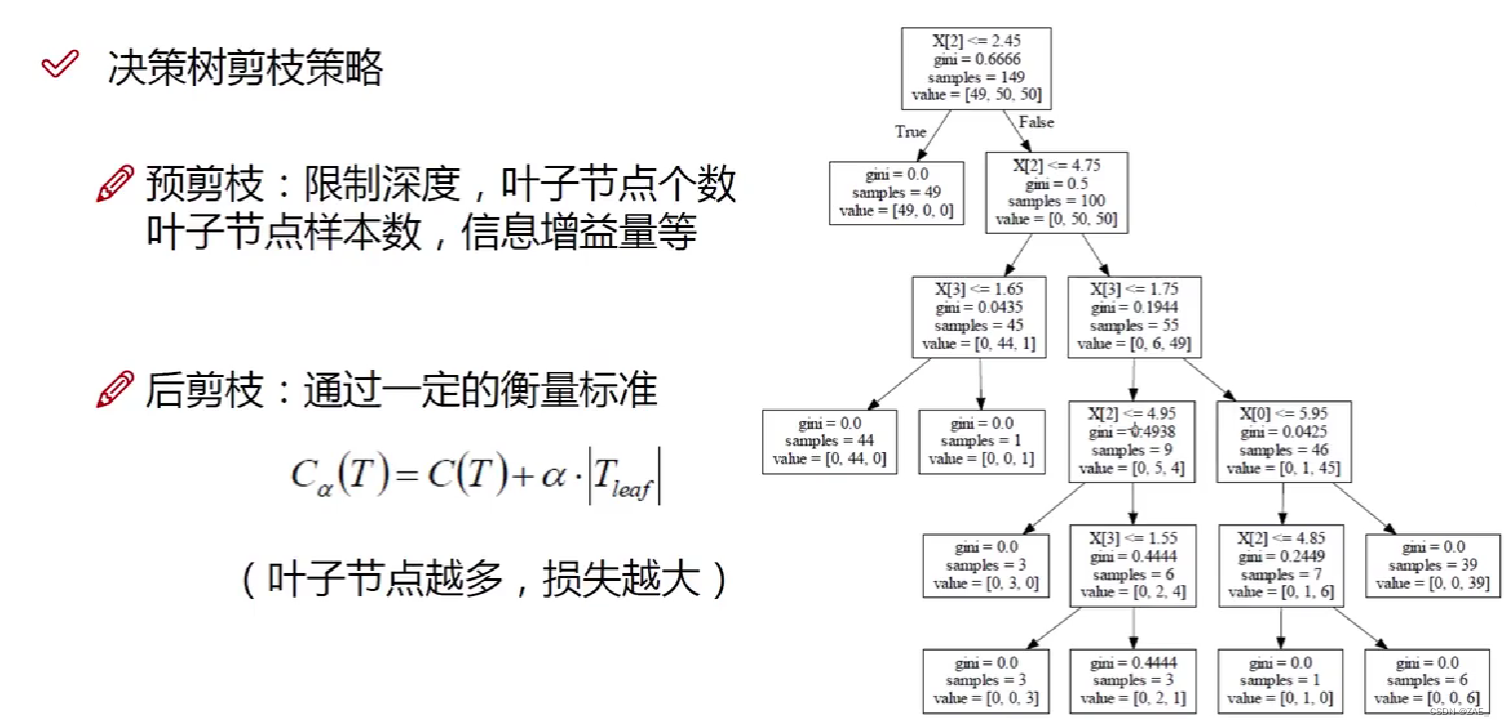
决策树后剪枝(Post-pruning)是一种用于减小决策树模型复杂度的技术,以防止过拟合。它是在构建完整个决策树后,通过剪枝操作来减少树的分支节点或叶子节点的技术。以下是关于决策树后剪枝的背景、意义、方法以及与预剪枝的对比:
背景与意义:
在构建决策树时,贪婪算法通常会努力生成一个复杂的树,以最大程度地拟合训练数据。这很容易导致过拟合,使得模型在新数据上表现不佳。因此,后剪枝的主要目的是将过拟合的风险降到最低,提高模型的泛化性能。
方法:
决策树后剪枝的方法通常包括以下步骤:
1. 构建完整的决策树,包括生长到叶子节点的所有分支。
2. 从底向上遍历树的每个节点,包括分支节点和叶子节点。
3. 对每个节点进行考虑剪枝的操作。这通常涉及计算一个代价函数,该函数考虑了剪枝前后模型的性能以及剪枝的代价。
4. 如果剪枝后代价函数值更小(模型性能更好),则执行剪枝操作;否则,保持节点不变。
5. 重复步骤3和4,直到树的结构不再发生改变或直到达到某个停止条件。
代价函数通常采用如下形式:
其中:
是考虑剪枝代价的树
的总代价。
是树
是一个用于权衡模型复杂度和性能的参数。
是树
通过调整参数 ,可以控制剪枝的程度。较大的
值倾向于剪枝更多的节点,从而降低模型复杂度,而较小的
值倾向于保留更多的节点,以更好地拟合训练数据。
与预剪枝的对比:
- 预剪枝在树的构建过程中就限制了树的生长,而后剪枝则在构建完整个树之后再进行修剪。因此,后剪枝可以更灵活地调整树的结构。
- 预剪枝通常使用信息增益、基尼不纯度等度量来做出判断,而后剪枝使用代价函数来决定是否剪枝。后剪枝可以考虑到整体树结构的性能,而不仅仅是局部节点的信息增益。
- 后剪枝可以避免过于激进的剪枝决策,因为它可以在整个树上综合考虑性能,而不仅仅是根据局部节点的局部信息。这可以导致更好的泛化性能。
综上所述,决策树后剪枝是一种用于减小模型复杂度、防止过拟合的重要技术。通过仔细选择代价函数和参数,可以在保持模型性能的同时,减少决策树的复杂性,提高模型的泛化性能。与预剪枝相比,后剪枝通常更加灵活且具有更好的性能表现。
10.8-回归问题解决
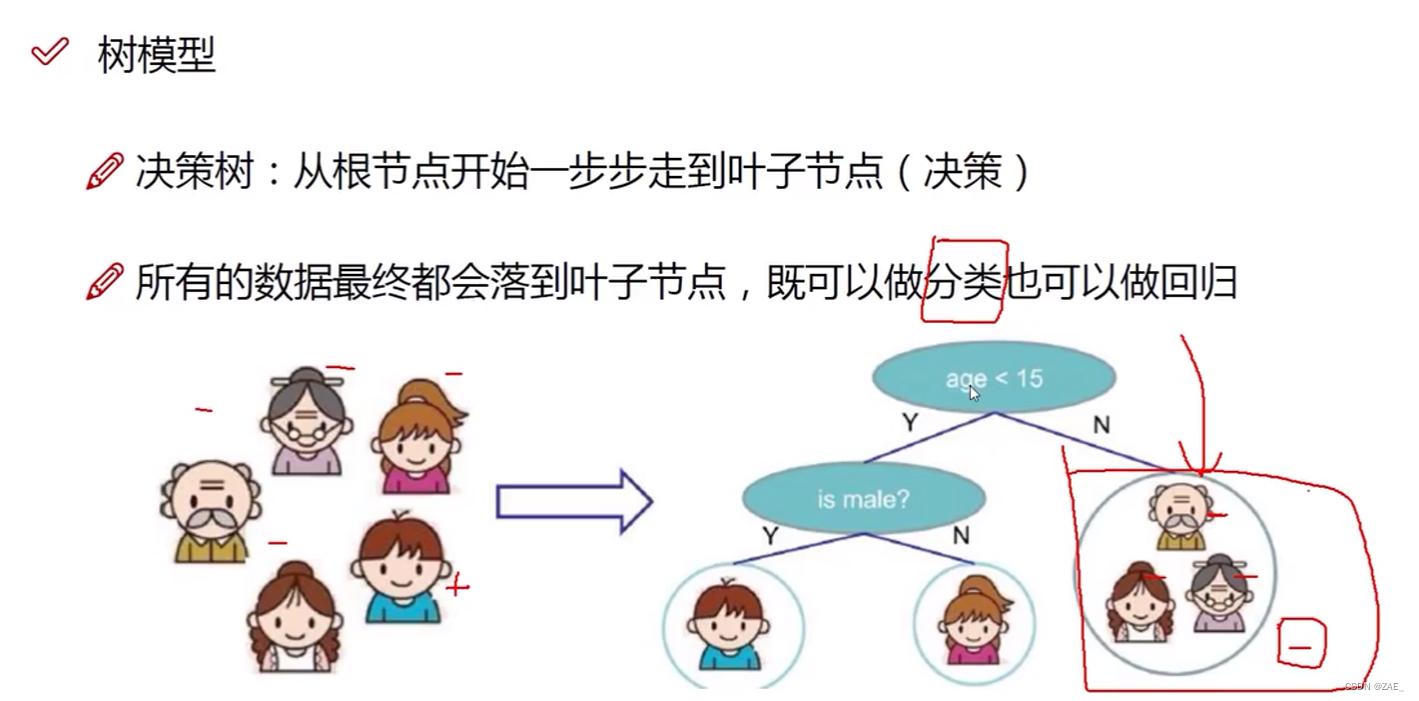
从根节点开始一步步走到叶子节点(决策): 在决策树的回归问题中,与分类问题类似,我们仍然从根节点开始,逐步沿着树的分支向下移动,直到到达叶子节点。每个节点都代表一个特征测试,根据测试结果选择一个分支,最终到达叶子节点。不同之处在于,叶子节点不再代表一个类别,而是代表一个数值,这个数值通常是与叶子节点中所有样本的目标值相关的一种平均或加权平均。
均方误差: 在回归问题中,我们需要用某种方式来衡量预测值与真实目标值之间的差异。通常使用均方误差(Mean Squared Error,MSE)作为评估指标。MSE是预测值与真实值之差的平方的期望值,用于衡量预测值的精确度。在决策树回归中,我们的目标是构建一棵树,使得所有叶子节点的均方误差最小化。
所有的数据最终都会落到叶子节点,既可以做分类也可以做回归: 决策树的一个重要性质是,无论是在分类问题还是回归问题中,所有的数据最终都会落到叶子节点。在分类问题中,叶子节点代表类别;而在回归问题中,叶子节点代表一个数值。这种一致性使得决策树模型在既可以应对分类任务,又可以用于回归任务。不同的是,在回归问题中,叶子节点的数值通常是与该节点中的样本的目标值相关的统计值,如平均值或加权平均值。
具体来说,决策树回归问题的工作原理如下:
- 选择一个特征和分割点,将数据集划分为左右两个子集。
- 对左右子集分别递归应用相同的划分过程,直到满足停止条件。
- 在叶子节点上存储一个数值,通常是该叶子节点中所有样本标签的平均值(对于均方误差最小化的情况)或其他回归问题的指标。
- 当新样本通过决策树时,从根节点开始,根据特征的取值依次向下走到达叶子节点,最终返回该叶子节点的数值作为回归预测结果。
决策树回归在解决回归问题时具有一定的优势,特别是在处理非线性关系和复杂数据时。它不仅能够提供回归预测结果,还具有可解释性,可以帮助理解哪些特征对预测具有重要影响。通过控制树的深度和其他超参数,可以调整模型的复杂度,以平衡拟合和泛化能力。















 9991
9991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









