







文章主要有两个创新点
- 将量化后的weigths进行split, 然后优化每一位bit, 使得目标函数最小, 得到每一位的bit后再将所有位的bit进行stitching
- 在保证计算效率的前提下, 可以对Activation使用per-channel的量化, 论文中叫Error Compensated Activation Quantization(ECAQ)
下面针对这两条分别说明,
Bit-Split and Stitching
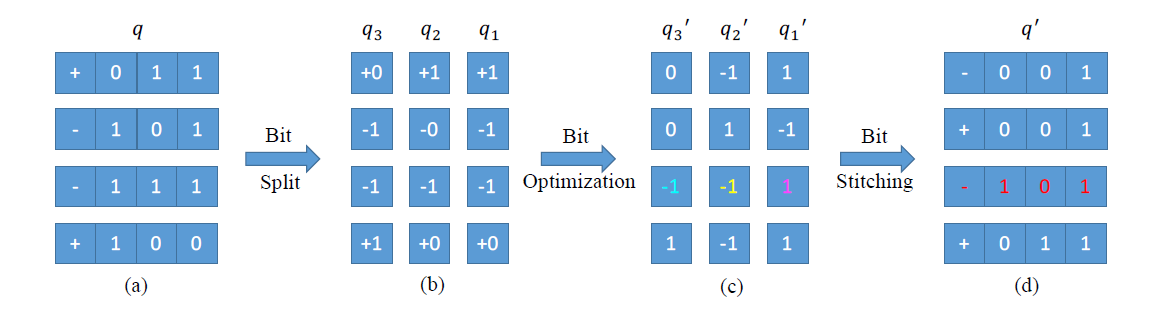
- 常规的二进制, 第一位是符号位, 后面的是绝对值, 每一位只能取0或1. split的作用就是把符号位分配给每个bit, 经过split处理, 总位数会少1, 每一位可取值变为-1, 0, 1. 可表示的范围其实没变都是最小位-111, 最大111.
经过这样处理后, 就可以利用论文中的公式进行优化, 优化这块不太懂. 大致思想还是迭代, 每次迭代时, 固定其他值, 然后求解其中某一位的值.
其实我不太懂, 为什么这里split后求解得出的量化值和scale精度就会更好
- conv/fc的计算过程可以表示位 $ Y = W^{T}X ( 假 设 (假设 (假设W$shape为[M, N] X X Xshape为[N, C], 则 Y Y Y的shape为[M, C]), 经过per_tensor量化后变为 Y = α W ^ X ^ β Y = \alpha \hat{W}\hat{X}\beta Y=αW^X^β其中 α \alpha α和 β \beta
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









