






今年搭子火了,从中我们发掘现代人的社交新模式。其实,在小红书上,还藏着另一种社交模式——“互换生活”。不管是大热的旅游赛道,还是美妆、穿搭、美食等,都频出爆文。
一、小红书用户的社交新模式:互换生活
火热的旅游市场掀起一股“互换生活”的风潮,互换特产、交换式旅游;无独有偶,还出现了互换饮食、互换妆容、互换穿搭。以及角色互换(母女、父子、学霸&学渣…)等,通过互换,体验不同的人生与生活。此间,隐藏着一种新的社交模式——“互换生活”,
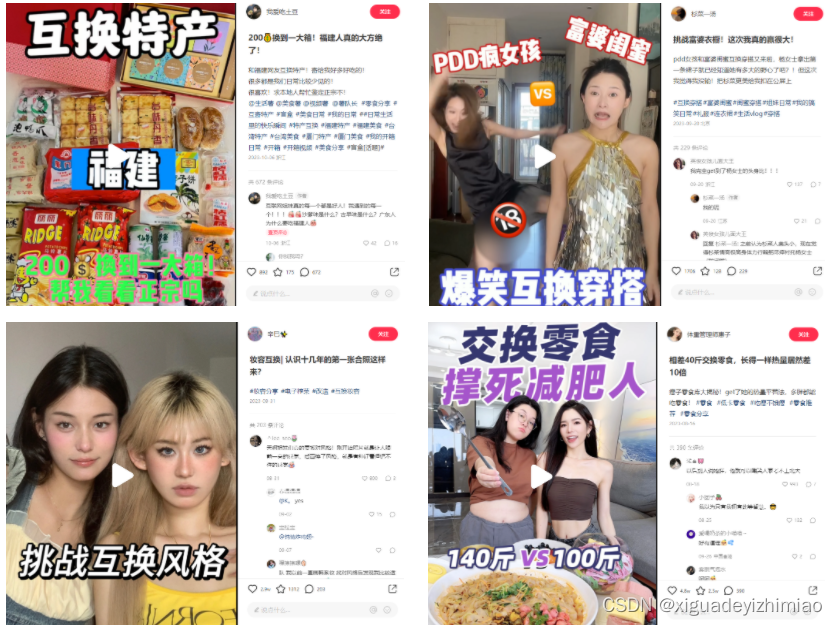
图 | 小红书截图
今年9月,小红书还上线了新话题#评论区交换铺#,浏览量已超2400万,近30天流量数据增长246%,笔记互动总量超百万。话题下的内容就包括:减脂餐交换、人生照片交换、景点交换、早餐交换等,这类笔记用户评论热情高涨。
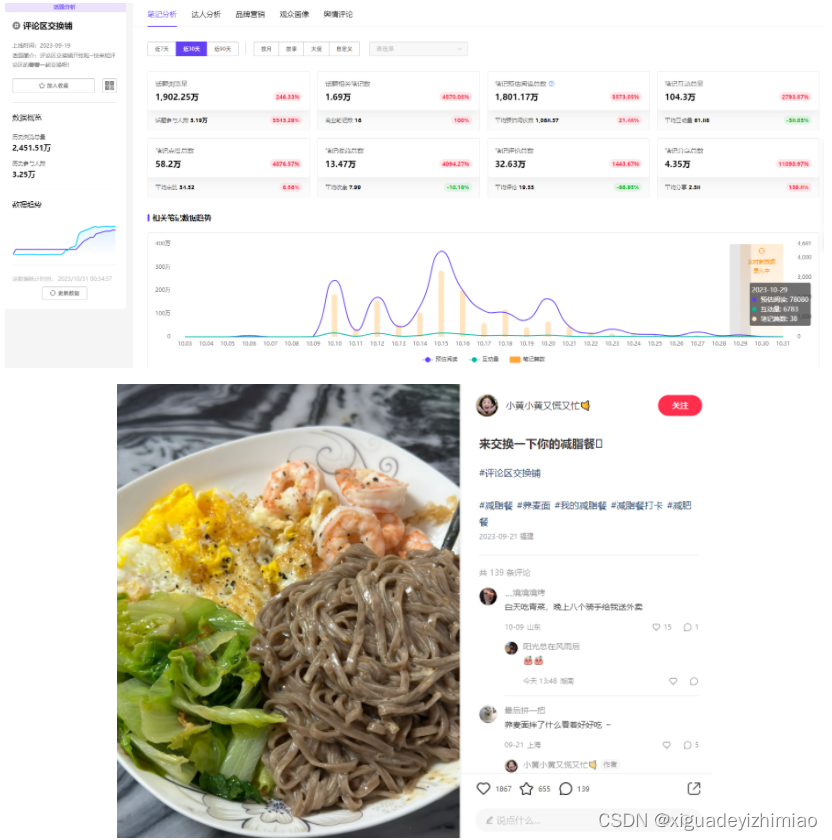
图 | 千瓜数据&小红书截图
二、行为洞察,互换式种草怎么玩?
笔者观察,这种互换式种草往往是通过对比反差感、同类项发散等,给人留下深刻印象,形象塑造更加立体,叙事张力更强,因而笔记曝光、互动效果较好。具体而言,品牌可从以下四个方向切入与达人共创。
1、社交影响与关联性:
其一,互换行为受社交影响,是由他人的想法、行动、语言,驱动的社交活动,涵盖如竞争行为、羡慕行为、伙伴关系等。
以玫珂菲与达人合作的妆容互换笔记为例,辣妹风、温柔风,两个不同风格的闺蜜互换妆容,二者即为伙伴关系,以彼此的想法行动来改变对方的妆容风格。该篇笔记预估曝光360万+,点赞超10万,高出达人日常水平223.77%。
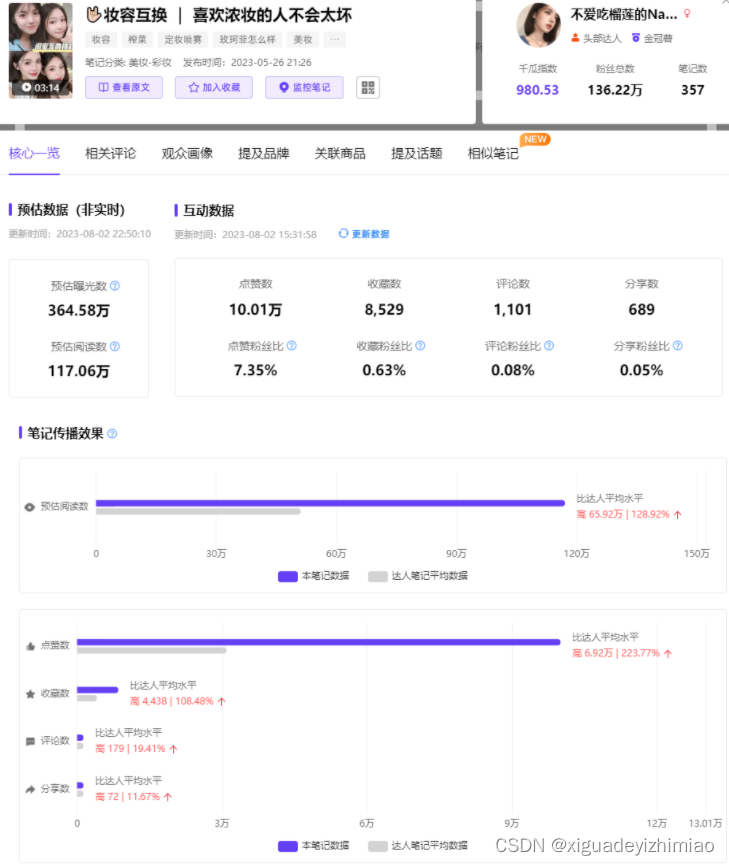
图 | 千瓜数据
2、未知性与好奇心:
其二,互换行为也是对未知性的探索与好奇心的满足,这种对原始大脑的内在刺激,有时甚至比外在激励还有效。
譬如,徐福记与达人合作的兴趣好爱笔记,展示与陌生人交换礼物的体验,笔记预估曝光15万,点赞1400+。
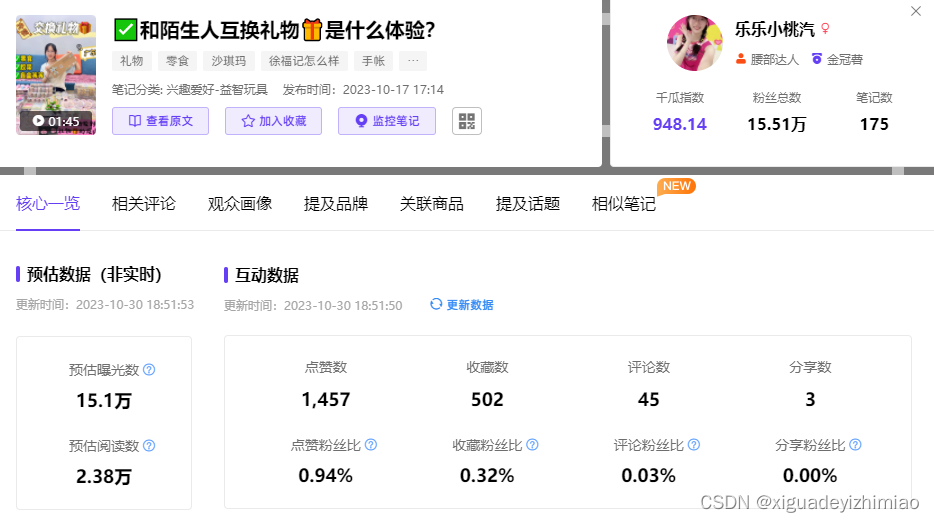
图 | 千瓜数据
3、稀缺性与渴望:
其三,事物的稀缺性引发的渴望,即不能马上拥有某样东西,或获取难度较大,不能轻易得到的独特性带来巨大吸引力力。
臭宝螺蛳粉与达人合作的笔记,90斤与130斤交换干饭,不同的身材不同的饮食习惯,对彼此来说都是短时间内难以达到或改变的。这样的反差会让用户产生期待。通过千瓜数据查看笔记数据,预估曝光171.79万,点赞8000+。评论区热词“螺蛳粉”位列TOP1,产品成功引起消费者注意。
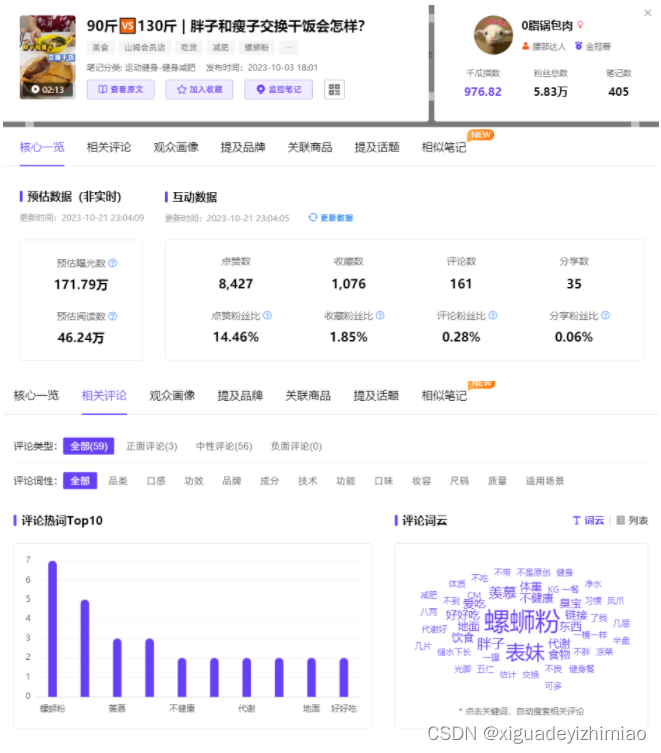
图 | 千瓜数据
4、共情体验:
最后是,互换身份触发的共情体验。正如有句话说:“当我成了你,我才读懂了你。”站在不同的角度,设身处地感受不同角色或身份的处境,让人真实体会其中的情感。
欧莱雅与达人合作的笔记中,母亲与儿子互换身份,儿子成为妈妈,做饭、打扫,甚至改作业,还原妈妈的一天。该篇笔记曝光预估476.73万,预估阅读数高出达人平均水平443.22%,可见传播效果甚佳。
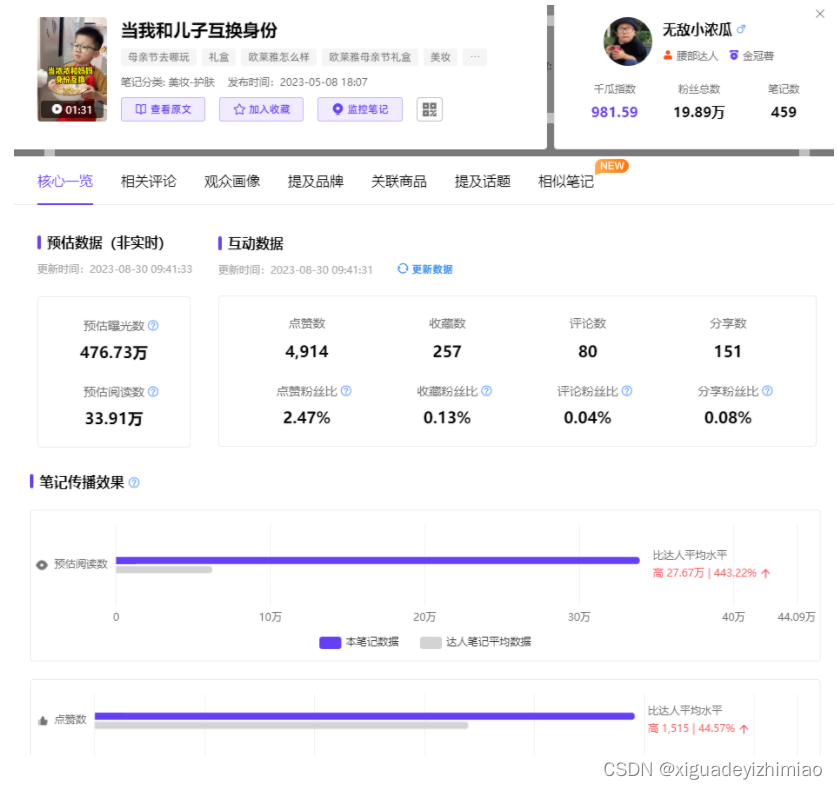
图 | 千瓜数据
品牌不妨将“互换式种草”作为爆款笔记打造的一个方向,借助社交影响、好奇心、稀缺性与共情体验,提升产品的曝光与转化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









