







转载自 数据库系统概念笔记-关系模型介绍 作者 CyninMa
数据库系统概念笔记-关系模型介绍
2.1 关系数据库的结构
关系数据库由表(table)的集合构成,每个表有唯一的名字。例如,instructor表记录了有关教师的信息,它有四个列首:ID、name、dept_name和salary。该表中每一行记录了一位教师的信息,包括该教师的ID、name、dept_name以及salary。类似的,course表存放了关于课程的信息,包括每门课程的course_id、title、dept_name和credits。注意,每位教师通过ID列的取值进行标识,而每门课程则通过course_id列的取值来标识。
第三个表是prereq,它存放了每门课程的先修课程信息。该表具有course_id和prereq_id两列,每一行由一个课程对组成,这个课程对表示了第二门课程是第一门课程的先修课。
由此,prereq表中的每行标识了两门课程之间的联系:其中一门课程是另一门课程的先修课。作为另一个例子,我们考察instructor表,表中的行可被认为是代表了从一个特定的ID到相应的name、dept_name和salary值之间的联系。
一般来说,表中一行代表了一组值之间的一种联系。由于一个表就是这种联系的一个集合,表这个概念和教学上的关系这个概念是密切相关的,这也正是关系数据模型名称的由来。在数学术语中,元组(tuple)只是一组值的序列(或列表)。在n个值之间的一种联系可以在数学上用关于这些值的一个n元组(n-tuple)来表示,换言之,n元组就是一个有n个值的元组,它对应于表中的一行。
| ID | name | dept_name | salary |
| 10101 | Srinivasan | Comp. Sci. | 65000 |
| 12121 | Wu | Finance | 90000 |
| 15151 | Mozart | Music | 40000 |
| 22222 | Einstein | Physics | 95000 |
| 32343 | El Said | History | 60000 |
| 33456 | Gold | Physics | 87000 |
| 45565 | Katz | Comp. Sci. | 75000 |
| 58583 | Califieri | History | 62000 |
| 76543 | Singh | Finance | 80000 |
| 76766 | Crick | Biology | 72000 |
| 83821 | Brandt | Comp. Sci. | 92000 |
| 98345 | Kim | Elec. Eng. | 80000 |
| course_id | title | dept_name | credits |
| BIO-101 | Intro. to Biology | Biology | 4 |
| BIO-301 | Genetics | Biology | 4 |
| BIO-399 | Compultational Biology | Biology | 3 |
| CS-101 | Intro. to Computer Science | Comp. Sci. | 4 |
| CS-190 | Game Design | Comp. Sci. | 4 |
| CS-315 | Robotics | Comp. Sci. | 3 |
| CS-319 | Image Processing | Comp. Sci. | 3 |
| CS-347 | Database System Concepts | Comp. Sci. | 3 |
| EE-181 | Intro. to Digital Systems | Elec. Eng. | 3 |
| FIN-201 | Investment Banking | Finance | 3 |
| HIS-351 | World History | History | 3 |
| MU-199 | Music Video Production | Music | 3 |
| PHY-101 | Physical Principles | Physics | 4 |
| course_id | prereq_id |
| BIO-301 | BIO-101 |
| BIO-399 | BIO-101 |
| CS-190 | CS-101 |
| CS-315 | CS-101 |
| CS-319 | CS-101 |
| CS-347 | CS-101 |
| EE-181 | PHY-101 |
这样,在关系模型的术语中,关系相当于表,而元组相当于行,类似的,属性相当于列。可见instructor关系有四个属性:ID、name、dept_name和salary。
我们用关系实例这个术语来表示一个关系的特定实例,也就是所包含的一组特定的行。可见instructor的实例有12个元组,对应于12个教师。
由于关系是元组集合,所以元组在关系中出现的顺序是无关紧要的,也就是说,无论怎么排序,它们都是同样的元组集合。
对于关系的每个属性,都存在一个允许取值的集合,称为该属性的域。这样instructor关系的salary属性的域就是所有可能的工资值的集合,而name属性的域是所有可能的教师名字的集合。
我们要求对所有关系 r 而言,r 的所有属性的域都是原子的。如果域中元素被看作是不可再分的单元,则域是原子的。例如,假设instructor表有一个属性phone_number,它存放教师的一组电话号码,那么phone_number就不是原子的,因为一组电话号码还可以细分出单个电话号码。
空(null)值是一个特殊的值,标识值未知或不存在。如果某个教师没有电话号码,或者不提供,那么我们只能使用空值来强调该值未知或不存在。
2.2 数据库模式
谈论数据库时,我们必须区分数据库模式和数据库实例,前者是数据库的逻辑设计,后者是给定时刻数据库中数据的一个快照。
关系的概念对应于程序设计语言中变量的概念,而关系模式的概念对应于程序设计语言中类型定义的概念。关系实例的概念对应于程序设计语言中变量的值的概念。给定变量的值可能随事件发生变化;类似的,当关系被更新时,关系实例的内容也随事件发生了变化。相反,关系的模式是不常变化的。
尽管知道关系模式和关系实例的区别非常重要,我们常常使用同一个名字,比如instructor,既指代模式,也指代实例。在需要的时候,我们会显式地指明模式或实例。例如“instructor模式”或“instructor关系的一个实例”。然而,在模式或实例的含义清楚的情况下,我们就简单的使用关系的名字。
考察department关系,该关系的模式是:
department(dept_name, building, budget)
| dept_name | building | budget |
| Biology | Watson | 90000 |
| Comp. Sci. | Taylor | 100000 |
| Elec. Eng. | Taylor | 85000 |
| Finance | Painter | 120000 |
| History | Painter | 50000 |
| Music | Packard | 80000 |
| Physics | Watson | 70000 |
请注意属性dept_name既出现在instructor模式中,又出现在department模式中。这样的重复并非一种巧合。实际上,在关系模式中使用相同属性正是将不同关系的元组联系起来的一种方法。例如,假设我们希望找出Watson大楼工作的所有教师的相关信息。我们首先在department关系中找出所有位于Watson的系的dept_name。接着,对每一个这样的系,我们在instructor关系中找出与dept_name对应的教师信息。
2.3 码(主码-外码)
我们必须有一种能区分给定关系中不同元组的方法。这用它们的属性来表明。也就是说,一个元组的属性值必须是能够唯一区分元组的。
超码(superkey)是一个或多个属性的集合,它可以唯一地标识一个元组。例如,ID是instructor的一个超码,它可以唯一地标识instructor的一个元组。
超码中可能包含无关紧要的属性。例如,ID和name的组合是instructor的一个超码,但是name是无关紧要的,倒是它的真子集ID也是一个超码,而且ID集合的任意真子集都不再是instructor的超码了。我们通常值对这样的一些超码感兴趣,他们的任何真子集都不能称为超码,这样的最小超码就被称为候选码。
我们用主码这个术语来代表被数据库设计者选中的、主要用来在一个关系中区分不同元组的候选码。码是整个关系的一种性质,而不是单个元组的性质。关系中的任意两个不同的元组都不允许同时在码属性上具有相同的值。
一个关系模式(如r1)可能在它的属性中包括另一个关系模式(如r2)的主码。这个属性在r1上称作参照r2的外码。关系r1也称为外码依赖的参照关系,r2叫做外码的被参照关系。例如,instructor中的dept_name属性在instructor上是外码,它参照department,因为dept_name是department的主码。
现在考察section和teaches关系。如下需求是合理的:如果一门课程是分段授课的,那么它必须至少由一位教师来讲授;当然它可能由不止一位教师来讲授。为了施加这种约束,我们需要保证如果一个特定的(course_id, sec_id, semester, year)组合出现在section中,那么该组合也必须出现在teaches中。可是,这组值并不构成teaches的主码,因为不止一位教师可能讲授同一个这样的课程段。其结果是,我们不能声明从section到teaches的外码约束。从section到teaches的约束是参照完整性约束。
2.4 模式图
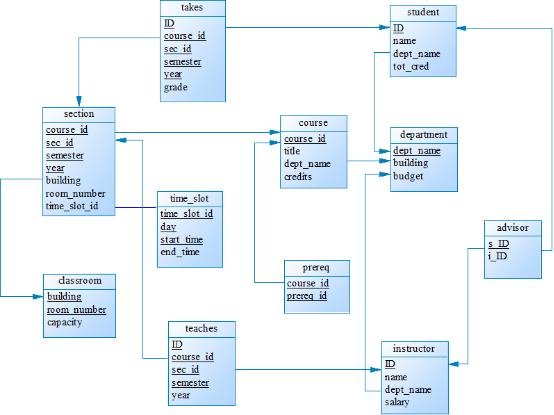
一个含有主码和外码依赖的数据库模式可以用模式图来标识。下图展示了我们大学组织的模式图。每一个关系用一个矩形来标识,关系的名字显示在矩形上方,矩形内列出各属性。主码属性用下划线标注。外码依赖用从参照关系的外码属性到被参照关系的主码属性之间的箭头来标识。
2.5 关系查询语言
查询语言是用户从数据库中请求获取信息的语言。这些语言通常比标准的程序设计语言层次更高。查询语言可以分为过程化的和非过程化的。在过程化语言中,用户知道系统对数据库执行一些列操作以计算出所需的结果。在非过程化语言中,用户只需描述所需信息,而不用给出获取信息的具体过程。
2.6 关系运算
所有的过程化关系查询语言都提供了一组运算,这些运算要么施加于单个关系上,要么施加于一对关系上。这些运算具有一个很好的,并且也是所需的性质:运算结果总是单个关系。这个性质使得人们可以用模块化的方式来组合几种这样的运算。特别是,由于关系查询的结果本身也是关系,所以关系运算可施加到查询结果上,正如施加到给定关系集上一样。
过滤元组:最常用的关系运算是从单个关系(如instructor)中选出满足一些特定谓词(如salary>85 000美元)的特殊元组,其结果是一个新的关系,它是原始关系(instructor)的一个子集,而不满足谓词的元组就被过滤掉了。
选择属性:另一个常用的运算是从一个关系中选出特定的属性(列)。其结果是一个只包含哪些被选中属性的新的关系。例如,假设我们只要查出instructor关系的ID和工资,那么教师的名字和系的名字都不会被查出来。
连接运算可以通过下述方式来结合两个关系:把分别来自两个关系的元组对合并成单个元组。有好几种不同的方式来对关系进行连接。例如,在查出教师信息的同时,也查询出教师所在系的信息,这样就把instructor和department连接在一起了。笛卡尔积运算倒是不同了,它的运算结果是包含来自两个关系元组的所有对,无论它们的属性值是否匹配,比如一个关系总共有3个元组,另一个关系总共有5个元组,笛卡尔积运算后共有15个元组。
并运算适合在两个“相似结构”的表上执行,比如一个订单表和历史订单表,我们要查询出过去和现在所有的订单,那么我们就可以将这两张表并起来。
关系运算的对象不仅仅是已建立的表,还可以是元算的结果。例如,如果我们向找出工资超过85 000美元的教师的ID和salary,我们可以先从instructor关系中选出salary值大于85 000美元的元组,然后从结果中选出ID和salary两个属性。
去重:有时候查询结果包含了重复的元组,我们要去掉重复的,例如我们只想找出instructor关系所有的教师的名字,因为教师中可能会有相同的姓名,那么我们可以在查询的同时把重复的名字去掉。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









