







文章目录
0. 摘要
简要介绍
i
t
e
r
t
o
o
l
s
itertools
itertools模块,参考网址:https://pymotw.com/3/itertools/。如有错误,欢迎指正。
i
t
e
r
t
o
o
l
s
itertools
itertools提供的函数受函数式编程语言(如Clojure、Haskell、APL和SML)的类似特性的启发。它们的目的是快速和有效地使用内存,同时也被连接在一起以表达更复杂的基于迭代的算法。
与使用列表的代码相比,基于迭代器的代码提供了更好的内存消耗特性。由于数据在需要之前不会从迭代器生成,所以不需要同时将所有数据存储在内存中。这种“惰性”处理模型可以减少交换和其他大数据集的副作用,从而提高性能。
除了
i
t
e
r
t
o
o
l
s
itertools
itertools中定义的函数外,本节中的示例还依赖于一些内置函数进行迭代。
1. Merging and Splitting Iterators
这一小节主要讲迭代器的合并和拆分。
1.1 chain()
c
h
a
i
n
(
)
chain()
chain()函数可以接受几个(任意个)迭代器作为参数,并返回一个迭代器,该迭代器生成所有输入的内容,就像它们来自一个迭代器一样。


它可以轻松处理多个序列,而无需构造一个大列表。
1.1.1 chain.from_iterable()
如果要被组合的迭代器不是事先都知道的,可以使用
c
h
a
i
n
.
f
r
o
m
_
i
t
e
r
a
b
l
e
(
)
chain.from\_iterable()
chain.from_iterable():

如果这里依然使用
c
h
a
i
n
(
)
chain()
chain(),结果会是什么呢?
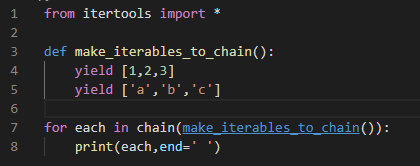

1.2 zip()
z
i
p
(
)
zip()
zip()是内置函数,它接受多个迭代器作为参数,并将每个迭代器的第一个、第二个……元素依次组合起来作为一个元组,返回一个迭代器。


当输入的任意一个迭代器耗尽时,
z
i
p
(
)
zip()
zip()会退出:
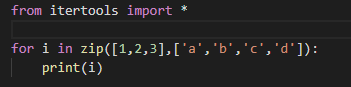

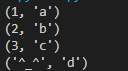
1.2.1 zip_longest()
如果想处理完所有的迭代器,尤其是当它们包含的元素个数不同时,可以使用这个函数:


默认情况下,没有值的地方将使用
N
o
n
e
None
None填充。可以指定
f
i
l
l
v
a
l
u
e
fillvalue
fillvalue参数来修改这个值:

1.3 islice()
i
s
l
i
c
e
(
)
islice()
islice()返回一个迭代器,它包含了输入迭代器中被选择(通过指定区间和步长)的元素:


把迭代器想象成一个列表,其它的几个参数就像列表切片一样: s t a r t 、 s t o p 、 s t e p start、stop、step start、stop、step。忽略输入的迭代器,如果只有 1 1 1个参数,那么它相当于 s t o p stop stop;如果有 2 2 2个参数,那么相当于 [ s t a r t , s t o p ) [start,stop) [start,stop);如果有 3 3 3个参数,那么区间依然是 [ s t a r t , s t o p ) [start,stop) [start,stop),但是元素之间的步长是 s t e p step step。
1.4 tee()
t
e
e
(
)
tee()
tee()基于单个输入参数返回几个独立的迭代器,默认返回两个:


t
e
e
(
)
tee()
tee() 的语义类似于
U
n
i
x
t
e
e
Unix\ tee
Unix tee程序,它重复从输入中读取值并将其写入命名文件和标准输出。
t
e
e
(
)
tee()
tee() 返回的迭代器可用于将同一组数据馈送到多个并行处理的算法中。
由
t
e
e
(
)
tee()
tee() 创建的新迭代器共享其输入,因此在创建新迭代器之后不应使用原始迭代器:


否则你可能会丢失掉某些值。
2. Converting Inputs
2.1 map()
内置的
m
a
p
(
)
map()
map() 函数返回一个迭代器,该迭代器对输入迭代器中的值调用函数,并返回结果。像
z
i
p
(
)
zip()
zip()一样,当任意一个输入迭代器耗尽时,它会退出。


注意,传入的迭代器个数应该等于要调用的函数的参数个数。
2.2 starmap()
s
t
a
r
m
a
p
(
)
starmap()
starmap() 函数与
m
a
p
(
)
map()
map() 类似,但它不是从多个迭代器构造元组,而是使用
∗
*
∗语法将单个迭代器中的项拆分出来作为
m
a
p
p
i
n
g
mapping
mapping函数的参数。


如果说 m a p ( ) map() map()对应的函数调用是 f ( i 1 , i 2 ) f(i_1,i_2) f(i1,i2),那么 s t a r m a p ( ) starmap() starmap()对应的函数调用就是 f ( ∗ i ) f(*i) f(∗i)。
3. Producing New Values
3.1 count()
它返回一个迭代器,该迭代器无限的生成连续的整数。第一个参数可以指定整数的起始值,默认为
0
0
0,第二个参数可以指定步长,默认为
1
1
1:


c
o
u
n
t
(
)
count()
count() 的
s
t
a
r
t
start
start和
s
t
e
p
step
step参数可以是任何可以相加的数值,下面这个例子将使用分数:


3.2 cycle()
它返回一个迭代器,该迭代器无限地重复给定参数的内容。因为它必须记住输入迭代器的全部内容,如果迭代器很长,它可能会消耗很多内存。


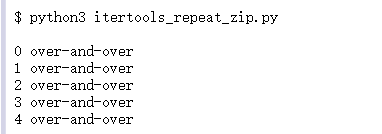
3.3 repeat()
它返回一个迭代器,每次访问它时都会产生相同的值。
t
i
m
e
s
times
times参数可以指定重复的次数:


当其他迭代器中的值需要包含不变值时,可以将
r
e
p
e
a
t
(
)
repeat()
repeat()与
z
i
p
(
)
zip()
zip()或
m
a
p
(
)
map()
map()结合使用。



4.Filtering
4.1 dropwhile()
它返回一个迭代器,从输入迭代器中依次过滤掉了条件为真的值,当第一次条件为假时返回(注意并不是对每一个元素都做一次验证)。从函数名字也可以看出来 d r o p w h i l e t r u e drop\ while\ true drop while true。


可以看到,从前往后过滤掉了 − 1 、 0 -1、0 −1、0。
4.2 takewhile()
它与
d
r
o
p
w
h
i
l
e
(
)
dropwhile()
dropwhile()相反,它接受输入迭代器中条件为真的值,当条件第一次为假时返回。
t
a
k
e
w
h
i
l
e
t
r
u
e
take\ while\ true
take while true。


可以看到,从前往后接受了 − 1 、 0 、 1 -1、0、1 −1、0、1。
4.3 filter()
内置函数
f
i
l
t
e
r
(
)
filter()
filter()返回一个迭代器,该迭代器只包含测试函数返回
t
r
u
e
true
true的项。


它与之前的两个函数不同,它会对输入迭代器的每个元素做一次判断。
4.4 filterfalse()
它与
f
i
l
t
e
r
(
)
filter()
filter()相反,只包含测试函数返回
f
a
l
s
e
false
false的项。


4.5 compress()
c
o
m
p
r
e
s
s
(
)
compress()
compress()提供了另一种过滤的方法。它不调用函数,而是使用另一个迭代器中的值来指示何时接受值和何时忽略它。

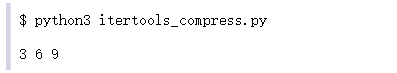
5. Grouping Data
5.1 groupby()
稍微有一点复杂,简单来说就是对输入迭代器按照给定的
k
e
y
key
key分组,把
k
e
y
key
key相同的元素放在同一组内。这个函数正常工作的前提是输入已经按照
k
e
y
key
key排序过了,下面来看一个例子:

我们的数据集
d
a
t
a
data
data为:

如果不进行排序,直接分组:

可以看到
k
e
y
key
key值相同的元素也没有被分到一起。现在看看排序的情况:

6. Combining Inputs
6.1 accumulate()
a
c
c
u
m
u
l
a
t
e
(
)
accumulate()
accumulate()返回一个迭代器,第一个元素等于输入迭代器的第一个元素,此后的第
i
i
i个元素等于生成的第
i
−
1
i-1
i−1个元素和输入迭代器的第
i
i
i个元素的和(默认使用加法)。看例子就懂了:


第一个例子是整数加法,第二个是字符串加法。
可以将
a
c
c
u
m
u
l
a
t
e
(
)
accumulate()
accumulate()与接受两个输入值的任何其他函数结合使用,以获得不同的结果。


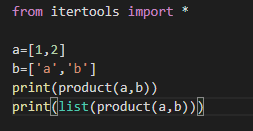
6.2 product()
p
r
o
d
u
c
t
(
)
product()
product()相当于嵌套的
f
o
r
for
for循环,它返回一个迭代器,是输入序列的笛卡尔积。先举一个简单的例子:

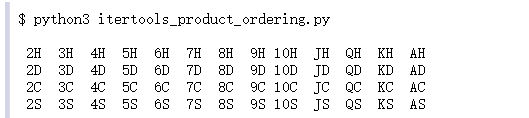
再看一个稍微复杂点的:


更改参数的顺序看一看?

要计算序列与自身的乘积,请指定重复的次数:


6.3 permutations()
它返回一个迭代器,包含输入序列的全排列。假设只有一个输入迭代器,且元素个数为
n
n
n,那么结果就相当于
n
n
n个人排队的全排列。通过指定参数
r
r
r的值,结果相当于
n
n
n人中任意取
r
r
r个人的排队结果。默认情况下
r
=
n
r=n
r=n。


6.4 combinations()
它返回一个迭代器,结果是输入序列的组合(必须指定参数
r
r
r的值)。相当于从
n
n
n个人中任意取
r
r
r个人的结果。只要输入序列没有重复元素,那么返回结果一定没有重复元素:
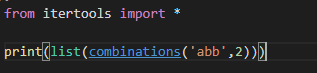



从上面结果可以发现,
c
o
m
b
i
n
a
t
i
o
n
s
(
)
combinations()
combinations()不重复单个输入元素,就是没有
a
a
、
b
b
、
c
c
、
d
d
aa、bb、cc、dd
aa、bb、cc、dd这些情况。如果需要的话可以使用
c
o
m
b
i
n
a
t
i
o
n
s
_
w
i
t
h
_
r
e
p
l
a
c
e
m
e
n
t
(
)
combinations\_with\_replacement()
combinations_with_replacement()。
















 5233
5233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









