







一、问题描述
巡检发现,某主机的vsan磁盘组中闪存盘故障,如下:

二、分析处理:
1)登录管理console,检查该主机是否有硬件报错:


2)如上确定是硬件故障,则将该磁盘组移除,数据迁移到其他磁盘:

先进行预检查故障磁盘是否可数据迁移,一般系统会报无法迁移
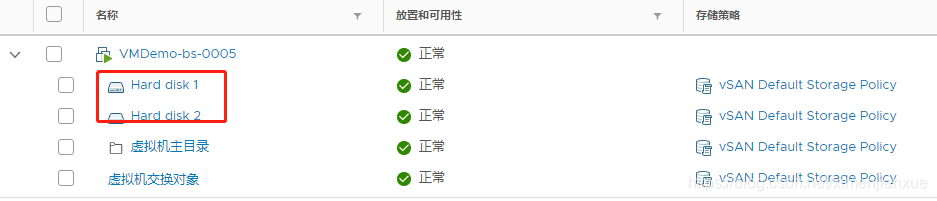
3)检查故障盘上的vm存储对象和见证:


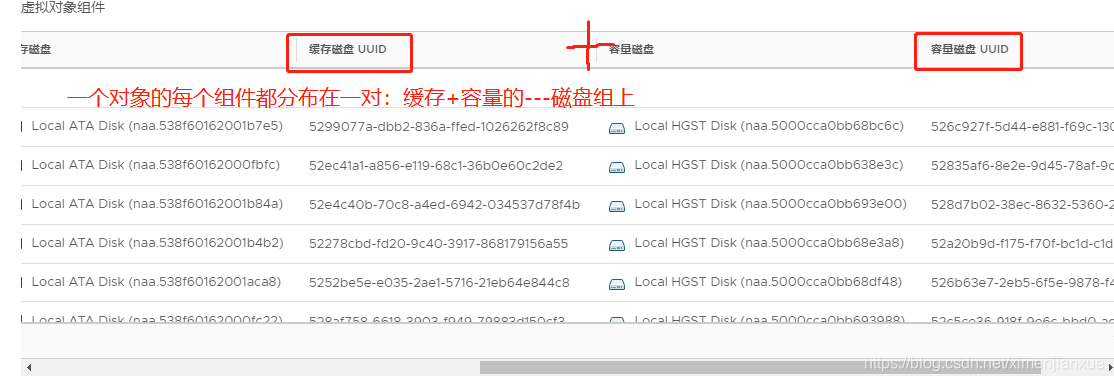
从上图可知,该磁盘组中已经没有vm相关对象;随后检查其他主机的物理磁盘对象,无告警等报错。
VSAN数据存储是一种对象存储系统,虚拟机是由大量不同的存储对象组成的,而不是文件。对象指的是一个独立的存储块设备,大小没限制。在VSAN中最典型的存储块设备就是独立的VMDK、虚拟机主页名字空间、虚拟机交换文件和增量盘。
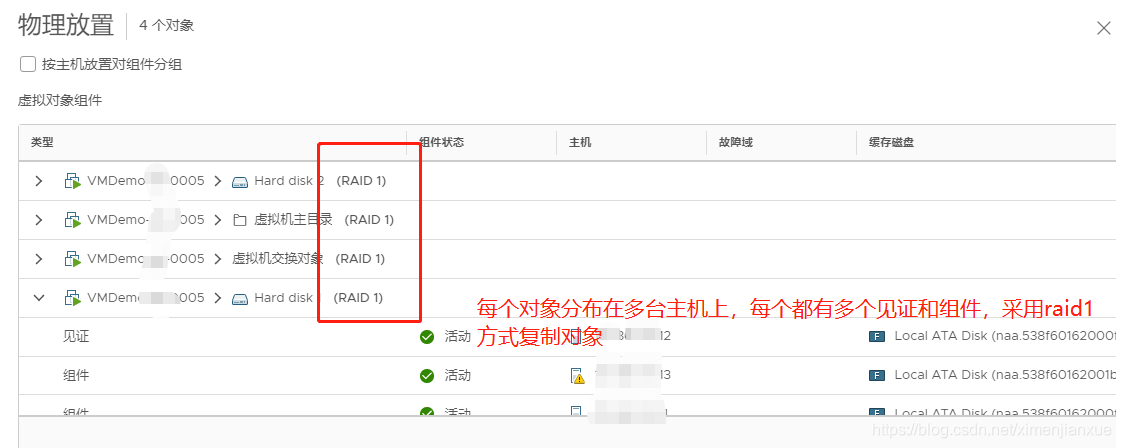
如上图,VSAN中的每个对象都有其自己的RAID树,将策略要求映射成物理设备上实际的布局(按存储策略决定如何在物理设备上存放)。虚拟机具有4种不同类型的对象,每台虚拟机都可以由这些对象中的部分组合而成,这些对象如下:
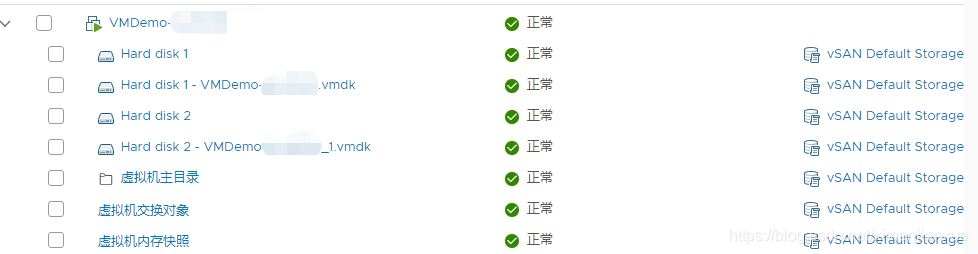
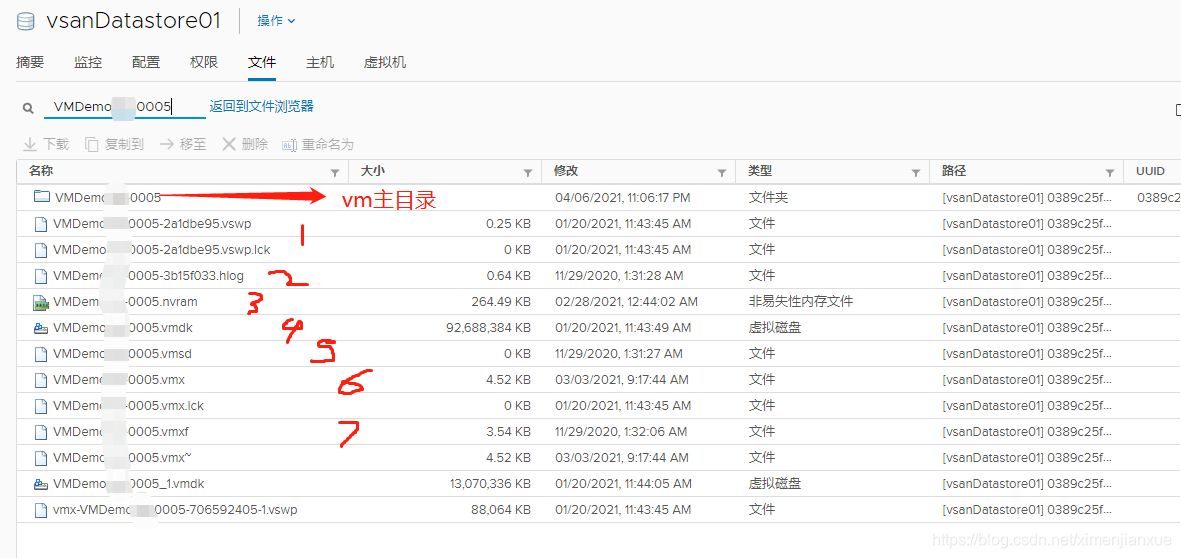
1>虚拟机主页或名字空间目录(vm主目录): 所有虚拟机文件,包括VMDK、增量(快照)和交换文件都存放在VSAN上一块叫做虚拟机名字空间的地方。在虚拟机主页名字空间中最典型的文件有.vmx虚拟机描述文件、.log日志文件、.vmdk磁盘描述文件、快照增量盘描述文件以及所有其他可能在虚拟机主页目录中找到的文件。如下图所示:
2>交换文件对象(vm交换对象):
3>虚拟磁盘VMDK:
4>增量盘:
而组件就是对象的RAID树上上的叶子,这意味着:一个对象的组件是存放在一个特定的闪存设备+磁盘 (即磁盘组)的组合上。其中,见证(witness)组件,它非常重要,也很特殊,当群集中的虚拟机存储对象出现故障的时候,它将作为必要的仲裁对象,决定新的镜像副本存放位置
VSAN上的每个存储对象都可以被看成是一棵RAID树,每片树叶就是一个组件。例如,如果一个VMDK的条带宽度是2(2块磁盘),那么这个VMDK上就会配置一个RAID-0条带并横跨2块磁盘。这个VMKD是一个对象,组成它的每一片条带就是这个对象的一个组件 。如果定义了这块VMDK在群集中应该至少容忍一个故障(主机、磁盘或网络 ),就要对这个VMDK对象创建一个RAID-1镜像—在群集内的一台主机上就会产生一个副本,而对应的组件同时也就在另一台主机上有另一个副本组件了。最后,如果同时需要配置条带和可用性,那么条带组件将会在主机之间被镜像,最终形成RAID0+1配置。VSAN中所有的IO会先通过闪存,即所有的写都会先进入写缓存,而所有的读也将尽可能地从读缓冲区中提供,如果数据不在读缓冲区中(读缓冲未命中),则读取将不得不由磁盘提供服务。
当VSAN集群中某主机上磁盘发生了故障。VSAN会根据类型对这一故障做出响应,将所有受影响组件( VMDK)标记为“已降级”,然后立即创建一个新的镜像副本。且会在创建此镜像 VSAN 之前,验证是否有足够的资源来存储这一新副本。而该过程中,虚拟机不会注意到这一点。但如果需从磁盘读取方面考虑,虚拟机性能会受到影响。如果没有足够的资源可以创建该镜像副本,VSAN 会一直等待,直至新的资源添加到位为止。添加新磁盘或主机后,恢复过程就会立即开始。此时,虚拟机允许不受影响,仍然可以执行 IO操作。
vsan6.0起,vsphere web提供了在vsan故障发生时,可监控数据同步状况的功能,它会显示正在重新同步的组件数量、重新同步的剩余字节数以及完成重新同步所需要的时间等。
VSAN中,当缓存设备不可访问时,同一个磁盘组中那个缓存设备支持的所有容量设备都将会无法被访问。缓存设备故障等同于缓存设备背后的所有容量设备故障。从本质上说,当一个缓存设备故障时,整个磁盘组被认为是“已降级的”。如果VSAN群集中有多余的容量,它就会试图在另一台主机或磁盘上重新配置存储对象。因此,从架构决策角度看,根据使用的主机类型不同,创建多个小的磁盘组可能会比单个大磁盘组好,因为一个磁盘组可以被视为一个故障域。
注:当磁盘容量全满时,vSAN会暂停写数据并为写请求申请新的磁盘空间,如果未及时添加新的磁盘,则vsan写操作会出现错误,引发虚拟机I/O错误。
4)检查虚拟机对象,状态正常,如下所示:

5)检查“重新同步对象,无相关对象执行同步,即所有vm对象已完成同步,否则可等vsan自动重建,或者手动执行“立即重新同步”;如下所示:

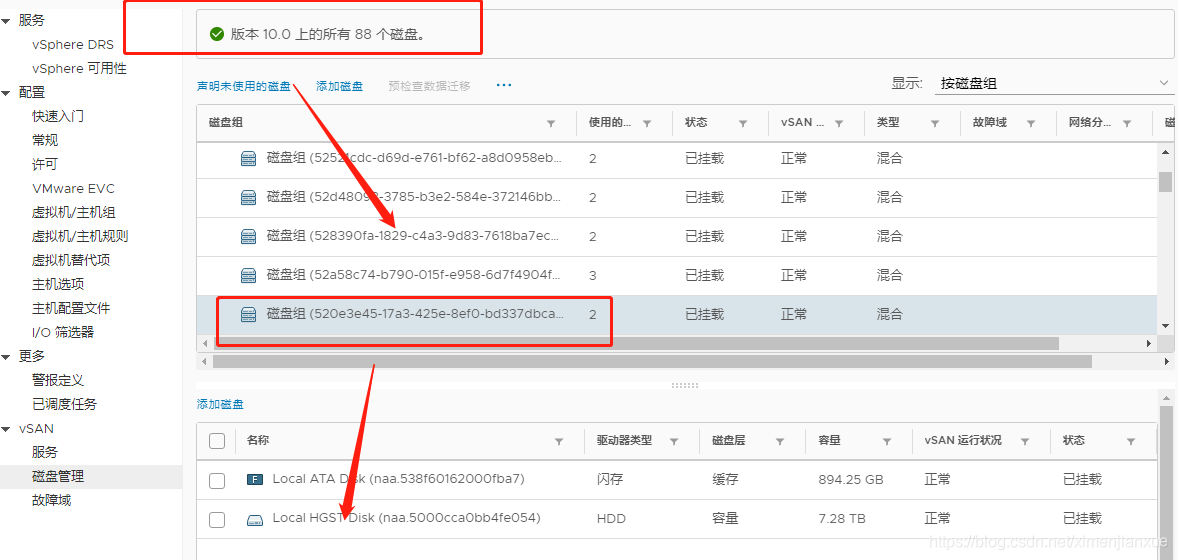
6)将主机进入“维护模式”,然后对故障的缓存磁盘进行“移除磁盘”操作;“移除磁盘操作”在主机正常状态下移除报错。将主机置于维护模式,等待其上vm迁移完成:

7)联系主机运维人员,报故障处理。如磁盘热插播后,状态恢复,验证其上对象即可,否则,移除故障的缓存磁盘,重新建立磁盘组。


删除后重新建:

恢复正常,主机退出维护模式:
命令删除,可登录对应的ESXI主机shell里,执行:
1)esxcli vsan storage list;
2)esxcli vsan storage remove -n storage的id;

三、附录:容量大小设置准则
1)至少留有 30% 的未使用空间,以防止 vSAN 重新平衡存储负载。只要单个容量设备上的消耗达到 80% 或以上,vSAN 就会重新平衡群集中的组件。重新平衡操作可能会影响应用程序的性能。要避免这些问题,存储消耗应低于 70%。
2)规划额外容量,用于处理潜在故障或替换容量设备、磁盘组和主机。当某个容量设备无法访问时,vSAN 会在群集中的其他设备中恢复组件。当闪存缓存设备出现故障或移除时,vSAN 会从整个磁盘组中恢复组件。
3)预留额外容量以确保 vSAN 在出现主机故障或主机进入维护模式时恢复组件。例如,置备具有足够容量的主机,以便留有足够的可用容量供可在主机出现故障或维护期间成功进行重新构建组件。存在三个以上的主机时这非常重要,这样您才有足够的可用容量来重新构建故障的组件。如果主机出现故障,将在其他主机的可用存储上进行重新构建,这样可以允许再次出现故障。但是,在三主机群集中,如果将允许的故障数主要级别设置为 1,则 vSAN 不会执行重新构建操作,因为在一个主机出现故障后,群集中只剩下两个主机。要允许故障后重新构建,至少必须有三个主机。
4)提供足够的临时存储空间,以便在 vSAN 虚拟机存储策略中进行更改。动态更改虚拟机存储策略时,vSAN 可能会为组成对象的副本创建一个布局。当 vSAN 实例化这些副本并将其与原始副本进行同步时,群集必须临时提供额外空间。
5)如果规划使用软件校验和或去重和压缩等高级功能,请保留额外的空间以处理操作开销。
注意:
SSD 拥堵问题会引发VSAN夯住。这时特定磁盘组的写入 IO 的活动工作集显著大于该磁盘组缓存层的大小时,通常会引发 SSD 拥堵,继而引发VSAN群集夯住。在混合和全闪存 vSAN 群集中,数据首先写入到写入缓存(也称为写入缓冲区)。一个称为降级转储的进程会将数据从写入缓冲区移至容量磁盘。写入缓存承受较高的写入速率,从而确保写入性能不受容量磁盘的限制。不过,如果以非常快的速率填充写入缓存,降级转储进程可能跟不上到达 IO 的速率。在这种情况下,会引发 SSD 拥堵,需要指示 vSAN DOM 客户端层将 IO 减速到 vSAN 磁盘组可以处理的速率。
补救措施:要避免 SSD 拥堵,请调整所用的虚拟机磁盘的大小。为达到最佳效果,我们建议虚拟机磁盘(活动工作集)的大小不超过所有磁盘组写入缓存累计大小的 40%。请注意,对于混合 vSAN 群集,写入缓存的大小为缓存层磁盘大小的 30%。在全闪存群集中,写入缓存的大小是缓存层磁盘的大小,但不应超过 600 GB。如果超限大量写入,容易引起VSAN群集夯住,容量层磁盘也将会无法被访问。
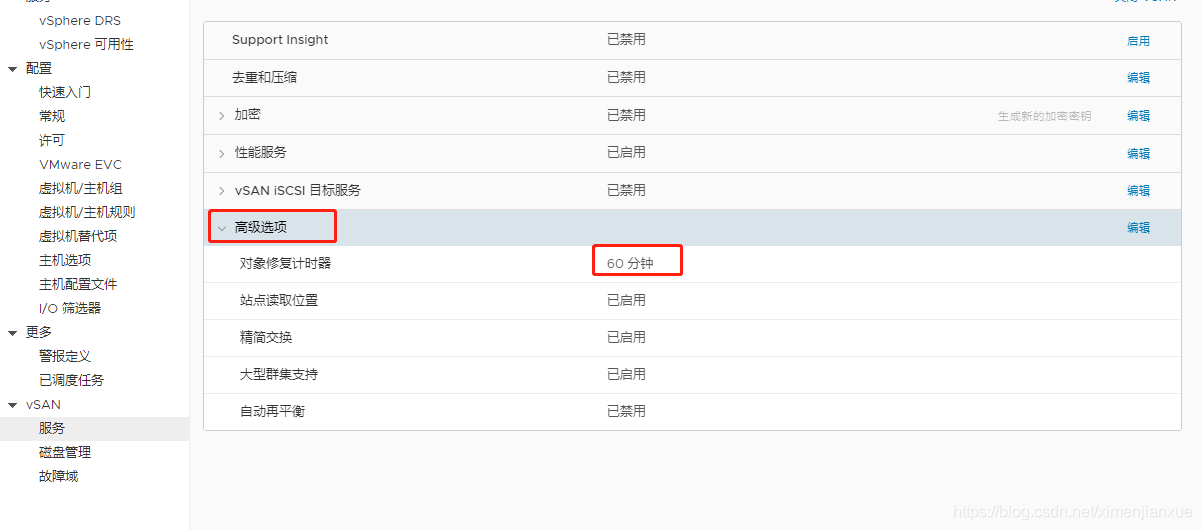
补充:VSAN主机故障时响应过程
与“磁盘故障”稍有不同。发生磁盘故障时,VSAN 会注意到所发生的情况,它会注意到磁盘无法恢复。但发生主机故障时,VSAN 不会注意到所发生的情况。这种故障状态称为 “不存在”。一旦 VSAN 注意到组件(在上述示例中为 VMDK)不存在,计时器就会开始 60 分钟计时,如果组件在 60 分钟内恢复,VSAN就会同步镜像副本。如果组件无法恢复,则 VSAN 就会创建新的镜像副本。请注意,我们可以通过更改高级设置“对象修复计时值”来减少此超时值。




















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











