







1、文件、目录操作命令(18个)
ls 即list:列出目录的内容及其内容属性信息。
主要参数:
-a:显示隐藏文件 -l:是以更详细的列表形式显示-S:
drwxr-xr-x (也可以用二进制表示 111 101 101 --> 755)
d:标识节点类型(d:文件夹 -:文件 l:链接)
r:可读 w:可写 x:可执行
第一组rwx: ## 表示这个文件的拥有者对它的权限:可读可写可执行
第二组r-x: ## 表示这个文件的所属组用户对它的权限:可读,不可写,可执行
第三组r-x: ## 表示这个文件的其他用户(相对于上面两类用户)对它的权限:可读,不可写,可执行
以下命令参数只截取部分,不全;
eg1:
ls -F 查看目录中的文件
ls \*[0-9]* 显示包含数字的文件名和目录名
ls /tmp | pr -T5 -W$COLUMNS 将终端划分成5栏显示
cd 即change directory:从当前工作目录切换到指定的工作目录
cd - //返回上次所在的目录
cp 全拼为copy,功能为复制文件或目录。
eg1: 复制目录及其下隐藏文件到目标------>2种方法:
1)方法一:
cp -rf `ls -A1 --color=never` 目标目录
其中:–color=never选项是为了关闭ls的彩色显示,一般都是打开的,如果打开了,会包含彩色显示的转义字符,cp命令会提示找不到文件。-1选项,让ls一行只显示一个文件或目录名,仅是为看着舒服,这里加不加都不影响。如果已经将非隐藏的文件或目录复制过去了,仅想复制隐藏的文件和目录,执行以下命令:
cp -urf `ls -A1 --color=never` 目标目录
其中:-u参数,只会复制目标目录下不存在的文件;或者目标目录下存在,但当前目录下更新的文件。
2)方法二:
cp -rf `ls -d .[^.]* --color=never` 目标目录
其中:-d 不展开目录显示,.[^.]*匹配当前目录下以.开头的文件和目录。
tree 显示文件和目录由根目录开始的树形结构
lstree 显示文件和目录由根目录开始的树形结构
tree -d //树状显示目录
find 查找,用于查找目录及目录下文件。
语法:find [path…] [expression_list]
【工作原理】
其中,expression分为三种:options、test、action。对于多个表达式,find是从左向右处理的,所以表达式的前后顺序不同会造成不同的搜索性能差距。find命令默认递归遍历所指定的目录树,针对每个文件依次执行find命令中的表达式,表达式首先根据逻辑运算符进行结合,然后依次从左至右对表达式求值。
find首先对整个命令行进行语法解析,并应用给定的options,然后定位到搜索路径path下开始对路径下的文件或子目录进行表达式评估或测试,评估或测试的过程是按照表达式的顺序从左向右进行的(此处不考虑操作符的影响),如果最终表达式的表达式评估为true,则输出(默认)该文件的全路径名。
对于find来说,一个非常重要的概念:find的搜索机制是根据表达式返回的true/false决定的,每搜索一次都判断一次是否能确定最终评估结果为true,只有评估的最终结果为true才算是找到,并切入到下一个搜索点。
eg1:find /tmp -type f -name “*.log” -exec ls ‘{}’ ; -print,##该find中给定了两个test,两个action,它们之间从前向后按顺序进行评估
表达式优先级如下:

其中,-regex:这个参数和 -name 有类似的作用,都是通过文件的名字进行匹配,但是二者的不同的点是:
1)-name 只是对文件的名称做匹配,而-regex 是对文件的路径做匹配;-regex不是匹配文件名,而是匹配完整的文件名(包括路径)。例如,当前目录下有一个文件"abar9",如果你用"ab.*9"来匹配,将查找不到任何结果,正确的方法是使用".*ab.9"或者"./ab.*9"来匹配。
2) 在需要用正则表达式的时候,-regex 会比 -name方便很多, -name 是不支持正则表达式的,name 选项只支持通配符 * ? [],正则表达式有不同的标准,所以在find命令中可以通过 -regextype 来指定采用的正则表达式规范 , 从而让 -regex 按照指定的正则表达式规范工作,默认是 emacs 规范;另外有posix-awk, posix-basic, posix-egrep and posix-extended四种,可在man中获取得到。
用法:find dir -regextype "type" -regex "pattern"
示例:find . -regextype grep -regex “.*/[0-9]{4}$” | head //查找文件名称是4个数字构成的文件,然后取结果的前10行,其中-regex 采用的是 和 grep 命令相同的正则表达式规范;-regex 表达式忽略了文件的路径“./”,需在启后指定路径。
如果用name: find . -name “[0-9][0-9][0-9][0-9]” | head
-name 选项:按照文件名模式来匹配文件,若匹配则返回true,否则返回false。最好用引号将文件名模式引起来,防止shell自己解析要匹配的字符串。(可以用单引号也可以用双引号,单引号和双引号在shell环境中的区别,后者内不全是普通字符,前者特殊字符会被shell识别)-name对大小写字母敏感,如果想匹配时不考虑大小写可以使用-iname测试项.
find . -name "[A-Za-b]*" -print //当前目录及子目录中查找文件名以一个大写字母开头或者以小写a或b开头的文件
find . -name "[^A-Z][a-z][0-9][0-9].txt" -print //当前目录查找文件名不以大写字母开头,之后跟一个小写字母,再之后是两个数字,最后是.txt的文件;注意,此处的模式匹配并不符合正则表达式。
find . -size +0c -wholename "*e*[0-9]*" -o ! /( -name "." -o -name "*phone" /) -prune -name "*.c" -user xixi -o -name "*phone" //-prune是一个动作项,它表示当文件是一个目录文件时,不进入此目录进行搜索。-prune经常和-path或-wholename一起使用,以避开某个目录,常见的形式是:
find PATH (-path <don't want this path #1> -o -path <don't want this path #2>) -prune -o -path <global expression for what I do want> //注意:如果同时使用-depth设置项,那么-prune将被find命令忽略。
find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; #批量调整当前目录中的文件大小并将它们发送到指定的缩略图目录
find / -user user1 搜索属于用户 ‘user1’ 的文件和目录
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
find / -name \\*.rpm -exec chmod 755 '{}' \; 搜索以 ‘.rpm’ 结尾的文件并定义其权限
find / -xdev -name \*.rpm 搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备
locate \*.ps 寻找以 ‘.ps’ 结尾的文件 - 先运行 ‘updatedb’ 命令
whereis halt 显示一个二进制文件、源码或man的位置
which halt 显示一个二进制文件或可执行文件的完整路径
vim/vi 文本编辑器:
1)常用快捷键:(在一般模式下使用):
a :在光标后一位开始插入
A 在该行的最后插入
I 在该行的最前面插入
gg 直接跳到文件的首行
G 直接跳到文件的末行
dd 删除一行;3dd 删除3行;yy 复制一行;3yy 复制3行;p 粘贴;u:即undo撤销操作;
v :进入字符选择模式,选择完成后,按y复制,按p粘贴
ctrl+v 进入块选择模式,选择完成后,按y复制,按p粘贴
shift+v 进入行选择模式,选择完成后,按y复制,按p粘贴
2)查找并替换
1 显示行号 :set nu
2 隐藏行号::set nonu
3 查找关键字 :/you ## 效果:查找文件中出现的you,并定位到第一个找到的地方,按n可以定位到下一个匹配位置(按N定位到上一个)
4 替换操作 :s/sad/bbb 查找光标所在行的第一个sad,替换为bbb
:%s/sad/bbb 查找文件中所有sad,替换为bbb
其他:
mkdir 全拼为make directories,其功能是创建目录。-p:创建多级目录;
mv 全拼为move,其功能是移动或重命名文件。
pwd 全拼为print working directory,功能是显示当前工作目录的绝对路径。
rename 用于重新命名文件。
rm 全拼为remove,其功能是删除一个或多个文件或目录。
rmdir 全拼为remove empty directories,功能是删除空目录。
touch 创建个空文件,改变已有文件的时间戳属性。
tree 功能是以树形结构显示目录下的内容。
basename 显示文件名或着目录名。
dirname 显示文件或着目录路径。
chattr 改变文件扩展属性。
lsattr 查看文件扩展属性。
file 显示文件类型。
md5sum 计算和校验文件的MD5值。
rmdir dir1 删除一个叫做 ‘dir1’ 的目录’
rm -rf dir1 删除一个叫做 ‘dir1’ 的目录并同时删除其内容
rm -rf dir1 dir2 同时删除两个目录及它们的内容
ln -s file1 lnk1 创建一个指向文件或目录的软链接
ln file1 lnk1 创建一个指向文件或目录的物理链接
touch -t 0712250000 file1 修改一个文件或目录的时间戳 (格式:YYMMDDhhmm)
file file1 文件类型查看
iconv -l 列出已知的编码

2、查看文件、内容处理命令(21个)
at 全拼为concatenate,功能是用于连接多个文件并且打印到屏幕输出或重定向到指定文件中。
tac tac是cat的反向拼写,因此命令的功能为反向显示文件内容。
more 分页显示文件内容。
less 分页显示文件内容,more命令的相反用法。
head 显示文件内容头部。
head -10 install.log 查看文件头部的10行
tail 显示文件内容尾部。
tail **-10** install.log 查看文件尾部的10行
tail **+10** install.log 查看文件 10–>末行
tail -f install.log 小f跟踪文件的唯一inode号,就算文件改名后,还是跟踪原来这个inode表示的文件
tail -F install.log 大F按照文件名来跟踪
cut: 将文件的每一行按指定分隔符分割并输出。
split 分割文件为不同的片段。
paste 按行合并文件内容。
sort 对文件的文本内容排序。
uniq 去除掉重复行。
wc 统计文件行数、单词数或是字节数。
iconv 转换文件编码格式。
dos2unix 将DOS格式文件转换成UNIX格式。
diff 全拼为difference,比较文件差异,用于文本文件。
vimdiff 命令行可视化文件比较工具,用于文本文件。
rev 反向输出文件内容。
grep/egrep 常用于过滤字符串。
join 按两个文件的相同字段合并。
tr 替换、删除字符。
vi/vim 命令行文本编辑器。
3、搜索文件命令(4个)
which 查找二进制文件的命令,按环境变量PATH路径查找。
which ls //查找可执行的命令所在的路径
find 从磁盘遍历查找文件或目录。
find / -name "hadooop*" -ok rm {} \;
find / -name "hadooop*" -exec rm {} \;
find /home -user hadoop -type d -ls ##查找用户为hadoop的文件夹
whereis 查找二进制文件的命令,按环境变量PATH路径查找。
相对于which,whereis 查找可执行的命令和帮助的位置;
locate 从数据库/var/lib/mlocate/mlocate.db中查找命令,使用updatedb更新库。
4、文件压缩及解压缩命令(4个)
tar 打包压缩。
tar -cvzf bak.tar ./aaa
将/etc/password追加文件到bak.tar中(r)
tar -rvf bak.tar /etc/password
tar -xvf bak.tar
解压到/usr/下:tar -zxvf a.tar.gz -C /usr
查看压缩包内容tar -ztvf a.tar.gz
tar -cvf archive.tar file1 创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar 显示一个包中的内容
tar -xvf archive.tar 释放一个包
tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp目录下
tar -cvfj archive.tar.bz2 dir1 创建一个bzip2格式的压缩包
tar -xvfj archive.tar.bz2 解压一个bzip2格式的压缩包
tar -cvfz archive.tar.gz dir1 创建一个gzip格式的压缩包
tar -xvfz archive.tar.gz 解压一个gzip格式的压缩包
unzip 解压和zip压缩文件。
zip file1.zip file1 创建一个zip格式的压缩包
zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
unzip file1.zip 解压一个zip格式压缩包
gzip 压缩工具。
gunzip a.txt.gz或gzip -d a.txt.gz
gunzip file1.gz 解压一个叫做 'file1.gz'的文件
gzip file1 压缩一个叫做 'file1'的文件
gzip -9 file1 最大程度压缩
bzip2和bunzip2解压缩
bunzip2 a.bz2
bzip2 -d a.bz2
打包并压缩成bz2 : tar -jcvf a.tar.bz2------>解压:tar -jxvf a.tar.bz2
bunzip2 file1.bz2 解压一个叫做 'file1.bz2’的文件
bzip2 file1 压缩一个叫做 ‘file1’ 的文件
rar压缩和unrar解压缩
rar a file1.rar test_file 创建一个叫做 'file1.rar' 的包
rar a file1.rar file1 file2 dir1 同时压缩 'file1', 'file2' 以及目录 'dir1'
rar x file1.rar 解压rar包
unrar x file1.rar 解压rar包
5、系统信息查询命令(11个)
uname 显示操作系统相关信息。
hostname 显示或者设置当前系统的主机名。
dmesg 显示开机信息,用于诊断系统故障。
uptime 显示系统运行时间以及负载。
stat 显示文件或文件系统的状态。
arch 显示机器的处理器架构(1)
uname -m 显示机器的处理器架构(2)
dmidecode -q 显示硬件系统部件 (SMBIOS / DMI)
hdparm -i /dev/hda 罗列一个磁盘的架构特性
hdparm -tT /dev/sda 在磁盘上执行测试性读取操作
cat /proc/cpuinfo 显示CPU info的信息
cat /proc/interrupts 显示中断
cat /proc/meminfo 校验内存使用
cat /proc/swaps 显示哪些swap被使用
cat /proc/version 显示内核的版本
cat /proc/net/dev 显示网络适配器及统计
cat /proc/mounts 显示已加载的文件系统
lspci -tv 罗列 PCI 设备
lsusb -tv 显示 USB 设备
top 实时显示系统资源使用情况。
free 查看系统内存
date 显示、设置系统时间
cal 查看日历、时间信息
cal 2021 显示2021年的日历表
date 041217002021.00 设置日期和时间 - 月日时分年.秒
clock -w 将时间修改保存到 BIOS
6、用户管理及权限、用户授权,登陆相关命令(21个)
useradd 添加用户。
添加一个tom用户,设置它属于users组,并添加注释信息:useradd -g users -c "hr tom" tom
useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 “admin” 用户组的用户
usermod 修改系统已经存在用户属性。
修改tom用户的登陆名为tomcat:usermod -l tomcat tom
将tomcat添加到sys和root组(-G,-g)中:usermod -G sys,root tomcat
查看tomcat的组信息:groups tomcat
usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
userdel 删除用户。
userdel -r spark 加一个-r就表示把用户及用户的主目录都删除
groupadd 添加用户群组+groupmod组修改
passwd 修改用户密码。
chage 修改用户密码有效期限。
id 查看用户的uid/gid及归属的用户群组
groupmod -n new_group_name old_group_name 重命名一个用户组
chmod 改变文件、目录权限
chmod -R 770 aaa/ ##如果要将一个文件夹的所有内容权限统一修改,则可以-R参数
chmod ugo+rwx directory1 ##设置目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限
chmod go-rwx directory1 ##删除群组(g)与其他人(o)对目录的读写执行权限
find / -perm -u+s 罗列一个系统中所有使用了SUID控制的文件
chmod u+s /bin/file1 设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限
chmod u-s /bin/file1 禁用一个二进制文件的 SUID位
chmod g+s /home/public 设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的
chmod g-s /home/public 禁用一个目录的 SGID 位
chmod o+t /home/public 设置一个文件的 STIKY 位 - 只允许合法所有人删除文件
chmod o-t /home/public 禁用一个目录的 STIKY 位
chgrp 更改文件用户群组。
chown 改变文件、目录的属主和属组
chown :angela aaa ## 改变所属组
chown angela:angela aaa/ ## 同时修改所属用户和所属组
chown -R user1 directory1 ##改变一个目录的所有人属性并同时改变改目录下所有文件的属性
umask 显示、设置权限掩码。
whoami 显示当前有效用户名称,相当于执行id -un命令。
who 显示目前已登录系统的用户信息。
w 显示已登陆系统的用户列表,并显示用户正在执行的指令。
last 显示已登入系统的用户。
lastlog 显示系统中所有用户最近一次的登录信息。
users 显示当前登录系统的所有用户的用户列表。
finger 查找、显示用户信息。
gpasswd
将tomcat用户从root组和sys组删除:gpasswd -d tomcat root&&gpasswd -d tomcat sys
将america组名修改为am:groupmod -n am america
chattr 配置文件的特殊属性 - 使用 “+” 设置权限,使用 “-” 用于取消
chattr +a file1 只允许以追加方式读写文件
chattr +c file1 允许这个文件能被内核自动压缩/解压
chattr +d file1 在进行文件系统备份时,dump程序将忽略这个文件
chattr +i file1 设置成不可变的文件,不能被删除、修改、重命名或者链接
chattr +s file1 允许一个文件被安全地删除
chattr +S file1 一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘
chattr +u file1 若文件被删除,系统会允许你在以后恢复这个被删除的文件
lsattr 显示特殊的属性
为用户配置sudo权限
su 切换用户身份。
visudo 编辑/etc/sudoers文件的专属命令。
sudo 以另外一用户身份(默认为root用户)执行事先在sudoers文件中允许的命令。
用root编辑 vi /etc/sudoers;不过现在默认都用visudo命令来编辑文件,在文件的如下位置,为hadoop添加一行即可
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
然后,hadoop用户就可以用sudo来执行系统级别的指令
验证:切换到授权的用户下,执行:sudo -l 来查看哪些命令是可以执行或禁止的;

sudo -v //可更新sudo切换后的时间戳,不至于过期
/etc/sudoers中每行就算一个规则,带有#号可以当作是说明的内容,不会执行;如果规则很长,一行列不下时,可以用\号来续行,这样一个规则就可以有多个行;/etc/sudoers 的规则可分为两类;一类是别名定义,另一类是授权规则;别名定义并不是必须的,但授权规则是必须的;
别名规则定义格式如下:
Alias_Type NAME = item1, item2, ...
## 或如下这样
#Alias_Type NAME = item1, item2, item3 : NAME = item4, item5 //别名之间用:号分割;
##别名类型(Alias_Type):别名类型包括如下四种
#Host_Alias 定义主机别名; 用于在下文定义授权规则时通过该定义主机别名来限制特定一组主机,否则就需要用ALL来匹配所有可能出现的主机情况
#User_Alias 用户别名,别名成员可以是用户,用户组(前面要加%号),成员与成员之间,通过半角,号分隔;;且需要在系统中确实在存在的,即;在/etc/paswd中必须存在
#Runas_Alias 用来定义runas别名,这个别名指定的是“目的用户”,即sudo 允许切换至的用户; 定义的是某个系统用户可以sudo 切换身份到Runas_Alias 下的成员
#Cmnd_Alias 定义命令别名;注意:命令别名下的成员必须是文件或目录的绝对路径; 别名长的话,可以通过 \ 号断行;
Cmnd_Alias USERMAG=/usr/sbin/adduser,/usr/sbin/userdel,/usr/bin/passwd [A-Za-z]*,/bin/chown,/bin/chmod
Cmnd_Alias DISKMAG=/sbin/fdisk,/sbin/parted
Cmnd_Alias NETMAG=/sbin/ifconfig,/etc/init.d/network
Cmnd_Alias KILL = /usr/bin/kill
Cmnd_Alias PWMAG = /usr/sbin/reboot,/usr/sbin/halt
Cmnd_Alias SHELLS = /usr/bin/sh, /usr/bin/csh, /usr/bin/ksh, \
/usr/local/bin/tcsh, /usr/bin/rsh, \
/usr/local/bin/zsh
Cmnd_Alias SU = /usr/bin/su,/bin,/sbin,/usr/sbin,/usr/bin
##授权规则语法:授权用户 主机=命令动作,在动作之前也可以指定切换到特定用户下,在这里指定切换的用户要用括号括起来,如果不需要密码直接运行命令的,应该加NOPASSWD:参数
ZQadmin ALL=/bin/chown,/bin/chmod ##表示ZQadmin可以在任何可能出现的主机名的系统中,可以切换到root用户下执行/bin/chown 和/bin/chmod 命令;这里省略了指定切换到哪个用户下执行/bin/shown 和/bin/chmod命令;在省略的情况下默认为是切换到root用户下执行;同时也省略了是不是需要ZQadmin用户输入验证密码,如果省略了,默认为是需要验证密码。
#因此授权规则可以这样写:授权用户 主机=[(切换到哪些用户或用户组)] [是否需要密码验证] 命令1,[(切换到哪些用户或用户组)] [是否需要密码验证] [命令2],[(切换到哪些用户或用户组)] [是否需要密码验证] [命令3]...... //[ ]中的内容,是可以省略;命令与命令之间用,号分隔;
ZQadmin ALL=(root) NOPASSWD:/bin/chown, /bin/chmod ##//执行chown不需输入密码,执行chmod时需要ZQadmin输入自己的密码
%admin ALL=/usr/sbin/*,/sbin/* ##表示admin用户组下的所有成员,在所有可能的出现的主机名下,都能切换到root用户下运行 /usr/sbin和/sbin目录下的所有命令;
wangju ALL=/usr/sbin/*,/sbin/*,!/usr/sbin/fdisk #//表示wangju用户在所有可能存在的主机名的主机上运行/usr/sbin和/sbin下所有的程序,但fdisk 程序除外;
#按别名来建立规则,b写明首位必须为大写字母,其后可跟下划线和数字
User_Alias SYSADER=admin,linuxsir,%admin
User_Alias DISKADER=lanhaitun
Runas_Alias OP=root #/定义要临时su的目标用户的别名为OP,实际成员为root
Cmnd_Alias SYUCMD=/bin/chown,/bin/chmod,/usr/sbin/adduser,/usr/bin/passwd [A-Za-z]*,!/usr/bin/passwd root #/不能通过passwd 来更改root密码;
Cmnd_Alias DSKCMD=/sbin/parted,/sbin/fdisk #注:定义命令别名DSKCMD,下有成员parted和fdisk ;
## 定义别名规则
SYSADMIN ALL= SYUCMD,DSKCMD #/admin、linuxsir和admin用户组下的成员能以root身份运行chown 、chmod 、adduser、passwd,但不能更改root的密码;也可以以root身份运行 parted和fdisk
DISKADER ALL=(OP) DSKCMD
#SYSADMIN ALL= NOPASSWD:SYDCMD,NOPASSWD:DSKCMD//不用输入密码
其他
chage -E 2005-12-31 user1 设置用户口令的失效期限
pwck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的用户
grpck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的群组
newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
7、基础网络操作命令(11个)
telnet 用TELNET协议远程登录。
ssh 用SSH加密协议远程登录。
scp 全拼为secure copy,用于不同主机之间复制文件。
wget 用命令行下载文件。
ping 测试主机之间网络的连通性。
route 显示和设置linux系统的路由表。
ifup 启动网卡。
ifdown 关闭网卡
dhclient eth0 以dhcp模式启用 ‘eth0’
ip link show 显示所有网口链路状态
mii-tool eth0 显示eth0的链路状态
ethtool eth0 显示eth0网卡数据统计
iwlist scan 显示无线网络
iwconfig eth1 显示eth1的无线网卡的配置
whois www.baidu.com 在 Whois 数据库中查找
nbtscan ip_addr netbios解析 (windows)
nmblookup -A ip_addr netbios查看(windows)
smbclient -L ip_addr/hostname 显示 Windows 主机的远程共享
smbget -Rr smb://ip_addr/share 通过 smb 从主机 windows 下载文件
ifconfig 查看、配置、启用或禁用网络接口的命令
ifconfig eth0 promisc 设置 ‘eth0’ 成混杂模式以嗅探数据包 (sniffing)
route 路由管理
route -n show routing table
route add -net 0/0 gw IP_Gateway configura default gateway
route add -net 192.168.0.0 netmask 255.255.0.0 gw 192.168.1.1 configure static route to reach network '192.168.0.0/16'
route del 0/0 gw IP_gateway remove static route
echo "1" > /proc/sys/net/ipv4/ip_forward activate ip routing
netstat 查看网络状态
1)查看某个服务的TCP连接数
#netstat -an | grep ESTABLISHED | grep ':80' | wc -l

2) netstat -nu //查看udp的连接数
3)查看网卡列表: netstat -i
- 显示组播组的关系:netstat -g
ss 查看网络状态
1)ss -ta //检测套接字
2)显示所有活动的TCP连接以及计时器:ss -to
nmap 网络扫描命令
#弱口令检测
nmap –sU –p161 –script=snmp-brute ip //查找snmp弱口令,U:udp;
#弱口令利用
nmap -sU -p161 --script=snmp-netstat ip //获取网络端口状态文章来源站点
nmap –sU –p161 –script=snmp-sysdescr ip //获取系统信息
nmap -sU -p161 --script=snmp-win32-user ip //获取用户信息
#批量ping扫描
nmap -sP 192.168.10.0/24
nmap -sL 192.168.10.0/24 //仅列出指定网络上的每台主机,不发送任何报文到目标主机(隐蔽探测)
nmap -PS -p 22,23,2,80 39.156.66.18 //探测目标主机开放的端口,默认情况下nmap只扫描TCP端口
nmap -sS 39.156.66.0/24 //S:使用SYN半开放扫描,T:tcp
nmap -sO 39.156.66.0/24 //探测目标主机支持哪些IP协议
nmap -vv nmap 192.168.10.1 192.168.10.2 192.168.10.3 //扫描多台主机
nmap 192.168.10.1,2,3
nmap 192.168.10.* --exclude 192.168.10.10 //执行全网扫描或用通配符扫描时你可以使用“-exclude”选项来排除某些你不想要扫描的主机
nmap -A 192.168.10.11 //-A启用操作系统和版本检测,脚本扫描和路由跟踪功能,“-O”和“-osscan-guess”也帮助探测操作系统信息
nmap -sA 192.168.10.11 //探测该主机是否使用了包过滤器或防火墙
nmap -PN 192.168.10.11 //扫描主机检测其是否受到数据包过滤软件或防火墙的保护,“-F”选项执行一次快速扫描,仅扫描列在nmap-services文件中的端口而避开所有其它的端口,“-r”选项表示不会随机的选择端口扫描
nmap --iflist //“–iflist”选项检测主机接口和路由信息
nmap -p T:8888,80 192.168.10.11 //指定具体的端口类型和端口号来让nmap扫描,扫描tcp端口
nmap -p 80-160 192.168.10.11 //扫描某个范围内的端口
nmap -PS 192.168.10.11 //包过滤防火墙会阻断标准的ICMP ping请求,在这种情况下,我们可以使用TCP ACK (PA)和TCP Syn(PS)方法来扫描远程主机
nmap -sS 192.168.10.11 //隐蔽扫描
nmap -sN 1192.168.10.11 //TCP空扫描规避防火墙
lsof 全名为list open files,也就是列举系统中已经被打开的文件。
mail 发送、接收邮件。
mutt 邮件管理命令。
nslookup 查询互联网DNS服务器的命令
dig 查找DNS的解析过程
host 查询DNS的命令。
traceroute 追踪数据传输路由状况
tcpdump 命令行的抓包工具
用法: tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ] [ -i 网络接口 ] [ -r 文件名] [ -s snaplen ] [ -T 类型 ] [ -w 文件名 ] [表达式 ]
tcpdump的选项:
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息,包括源mac和目的mac,以及网络层的协议;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 指定将每个监听到数据包中的域名转换成IP地址后显示,不把网络地址转换成名字;
-nn: 指定将每个监听到的数据包中的域名转换成IP、端口从应用名称转换成端口号后显示
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-p: 将网卡设置为非混杂模式,不能与host或broadcast一起使用
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-s snaplen snaplen表示从一个包中截取的字节数。0表示包不截断,抓完整的数据包。默认的话 tcpdump 只显示部分数据包,默认68字节。
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;)
-X 告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示),这在进行协议分析时是绝对的利器。
1)抓取包含10.10.10.122的数据包
tcpdump -i eth0 -vnn host 10.10.10.122
2)抓取包含10.10.10.0/24网段的数据包
tcpdump -i eth0 -vnn net 10.10.10.0/24
3)抓取包含端口22的数据包
tcpdump -i eth0 -vnn port 22
4)抓取udp协议的数据包
tcpdump -i eth0 -vnn udp
5)抓取icmp协议的数据包
#tcpdump -i eth0 -vnn icmp
6)抓取arp协议的数据包
tcpdump -i eth0 -vnn arp
7)抓取ip协议的数据包
tcpdump -i eth0 -vnn ip
8)抓取源ip是10.10.10.122数据包。
tcpdump -i eth0 -vnn src host 10.10.10.122
9、抓取目的ip是10.10.10.122数据包
tcpdump -i eth0 -vnn dst host 10.10.10.122
10)抓取源端口是22的数据包
tcpdump -i eth0 -vnn src port 22
11)抓取源ip是10.10.10.253且目的ip是22的数据包
tcpdump -i eth0 -vnn src host 10.10.10.253 and dst port 22
12)抓取源ip是10.10.10.122或者包含端口是22的数据包
tcpdump -i eth0 -vnn src host 10.10.10.122 or port 22
13)抓取源ip是10.10.10.122且端口不是22的数据包
tcpdump -i eth0 -vnn src host 10.10.10.122 and not port 22
14)抓取源ip是10.10.10.2且目的端口是22,或源ip是10.10.10.65且目的端口是80的数据包。
tcpdump -i eth0 -vnn ( src host 10.10.10.2 and dst port 22 ) or ( src host 10.10.10.65 and dst port 80 )
15)抓取源ip是10.10.10.59且目的端口是22,或源ip是10.10.10.68且目的端口是80的数据包。
tcpdump -i eth0 -vnn ‘src host 10.10.10.59 and dst port 22’ or ’ src host 10.10.10.68 and dst port 80 ’
16)把抓取的数据包记录存到/tmp/fill文件中,当抓取100个数据包后就退出程序。
tcpdump –i eth0 -vnn -w /tmp/fil1 -c 100
17)从/tmp/fill记录中读取tcp协议的数据包
tcpdump –i eth0 -vnn -r /tmp/fil1 tcp
18)从/tmp/fill记录中读取包含10.10.10.58的数据包
tcpdump –i eth0 -vnn -r /tmp/fil1 host 10.10.10.58
mtr((My traceroute是ping+traceroute)
Linux版本的mtr命令默认发送ICMP数据包进行链路探测。可以通过“-u”参数来指定使用UDP数据包用于探测。相对于traceroute命令只会做一次链路跟踪测试,mtr命令会对链路上的相关节点做持续探测并给出相应的统计信息。所以,mtr命令能避免节点波动对测试结果的影响,所以其测试结果更正确,建议优先使用。此工具也有对应的Windows版本,名称为WinMTR。
用法:
mtr [-hvrctglspni46] [-help] [-version] [-report] [-report-cycles=COUNT] [-curses] [-gtk] [-raw] [-split] [-no-dns] [-address interface] [-psize=bytes/-s bytes] [-interval=SECONDS] HOSTNAME [PACKETSIZE]
常见可选参数说明:
-r 或 -report:以报告模式显示输出。
-p 或 -split:将每次追踪的结果分别列出来。
-s 或 -psize:指定ping数据包的大小。
-n 或 -no-dns:不对IP地址做域名反解析。
-a 或 -address:设置发送数据包的IP地址。用于主机有多个IP时。
-4:只使用IPv4协议。
-6:只使用IPv6协议。
另外,也可以在mtr命令运行过程中,输入相应字母来快速切换模式。
?或 h:显示帮助菜单。
d:切换显示模式。
n:切换启用或禁用DNS域名解析。
u:切换使用ICMP或UDP数据包进行探测。
默认配置下,返回结果中各数据列的说明:
第一列(Host):节点IP地址和域名。如前面所示,按n键可以切换显示。
第二列(Loss%):节点丢包率。
第三列(Snt):每秒发送数据包数。默认值是10,可以通过参数“-c”指定。
第四列(Last):最近一次的探测延迟值。
第五、六、七列(Avg、Best、Wrst):分别是探测延迟的平均值、最小值和最大值。
第八列(StDev):标准偏差。越大说明相应节点越不稳定。
ncat(nc)
ncat/nc既是一个端口扫描工具,也是一款安全工具,还是一款监测工具,甚至可以做为一个简单的TCP代理。
yum install nmap-ncat -y
ncat -l 80 //监听某个端口的入站连接
ncat -v 49.235.179.157 22 //测试主机端口的连通性,另一端监听,还可实现nc进行主机间通信
ftop(查看流量)
yum install iftop -y
iftop -i eth0 //
参数:
-i: 指定监听接口
-B: 以字节而非比特显示,默认是小b,即比特
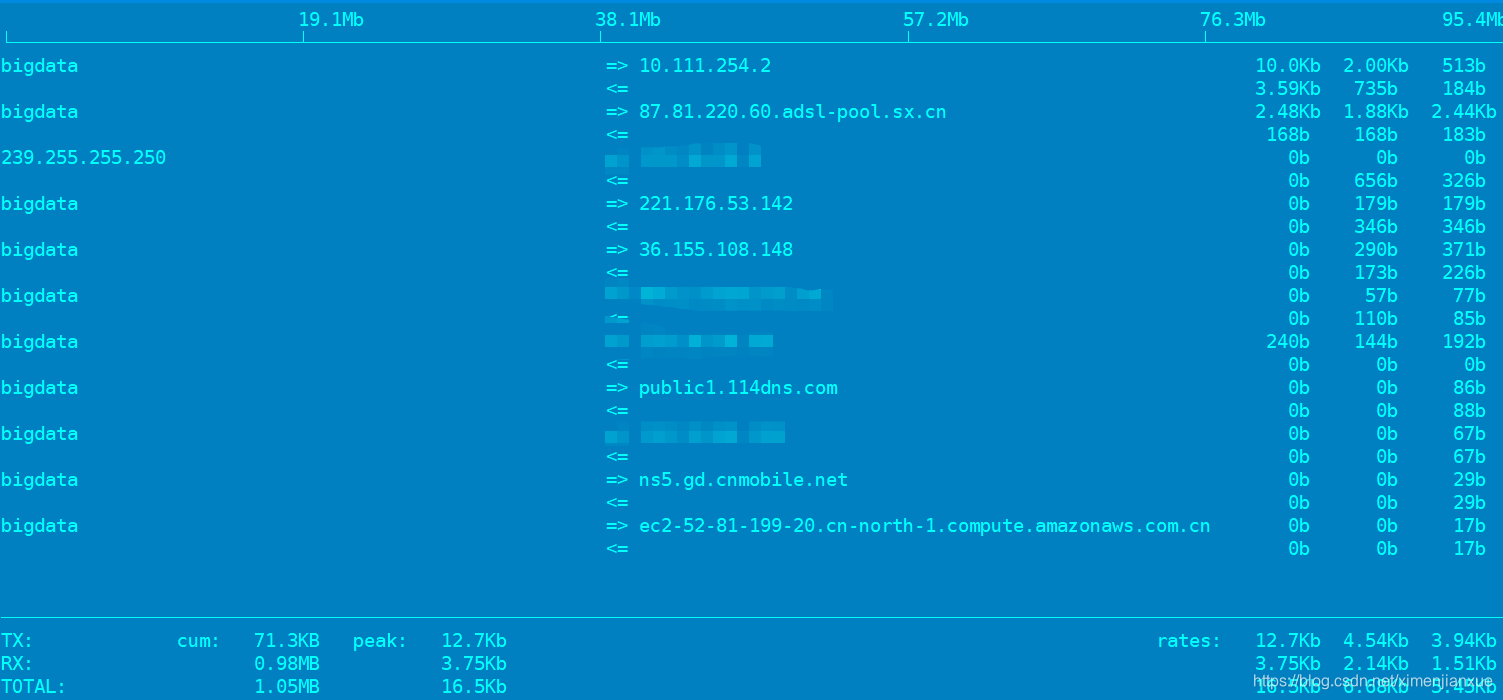
其中,结果各字段表示如下:
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s 10s 40s 的平均流量
trickle(限制带宽):应用用于限制网络带宽
yum install trickle -y //安装
1)限制wget的上传和下载速度限制上传为10KB/S,下载为20KB/s
trickle -u 10 -d 20 wget http://mirrors.163.com/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1503-01.iso
2)单独限制某个进程的下载和上传速度
trickle -s -d 50 -u 25 ftp
3)限制终端下的所有命令带宽为,下载500KB/S,上传250KB/s;
trickle -s -d 500 -u 250 bash //单独命令使用时,必须加-s参数
网络带宽测试:iperf
iperf 是一个网络性能测试工具,它可以测试 TCP 和 UDP 带宽质量,可以测量最大 TCP 带宽,具有多种参数和 UDP 特性,可以报告带宽,延迟抖动和数据包丢失。利用 iperf 这一特性,可以用来测试一些网络设备如路由器,防火墙,交换机等的性能。
yum -y install iperf gcc gcc-c++ gcc-g77
或源码安装:
wget -C https://downloads.es.net/pub/iperf/iperf-3-current.tar.gz
tar xvf iperf-3-current.tar.gz
cd iperf
./configure
make
make install
测试示例:
1 )测试最大的TCP 带宽(参数-r是做双向测试,-M指定传输帧的大小)
server端:iperf -s -p 5800 -M 1460 -i 1
client端: iperf -c server_ip -p 5800 -M 1460 -m -i 1 -r
- 测试丢包率
server端:iperf -s -i 1 -u
client端: iperf -c server_ip -i 1 -u -t 10 -b 500m -d
带宽测试工具:speedtest
speedtest 是一个用 Python 写成的工具,speedtest 命令将直接提供上传/下载速率;
$ sudo apt install speedtest-cli
或者
$ sudo pip3 install speedtest-cli
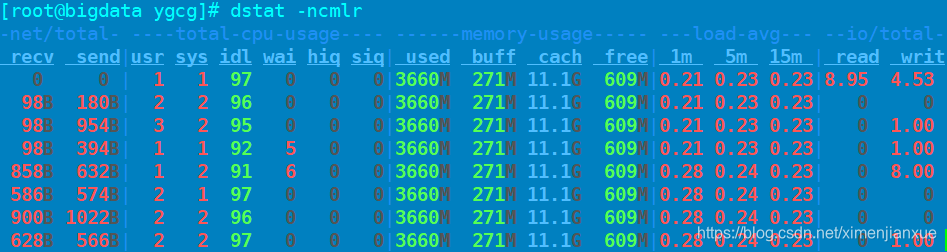
dstat(监控cpu内存)
yum install dstat -y //安装
参数:
-c: 显示cpu综合占有率
-m: 显示内存使用情况
-n: 显示网络状况
-l:显示系统负载情况
-r:显示I/O请求(读/写)情况
eg1:dstat -ncmlr
curl(发送请求)
1)url -O 文件名 url //保存到文件
2)用-i,显示网页头部信息 当然也会把网页信息显示出来,参数 -v可以显示通信的过程
3)更详细的通信信息可以用 参数 --trance 文件名 url,具体信息保存到单独的文件中
curl --trace info.txt www.baidu.com
4)使用参数 -X指定htpp的动词,例如GET POST,PUT,DELETE等,curl默认的是get请求,如果发送POSt请求
curl -X POST www.baidu.com
5)发送表单的时,只需要把数据拼接到url后面就行
curl www.baidu.com?data=xxx&data1=xxx
6)POST发送表单
curl -X POST --data “data=xxx” example.com/form.cgi
POST发送请求的数据体可以用-d
$ curl -d’login=emma&password=123’-X POST https://google.com/login
或者
$ curl -d ‘login=emma’ -d ‘password=123’ -X POST https://google.com/login
使用-d参数以后,HTTP 请求会自动加上标头Content-Type : application/x-www-form-urlencoded。并且会自动将请求转为 POST 方法,因此可以省略-X POST。-d参数可以读取本地文本文件的数据,向服务器发送。
curl -d ‘@data.txt’ https://google.com/login //读取data.txt文件的内容,作为数据体向服务器发送。
7)文件上传
curl --form upload=@localfilename --form press=OK [URL]
curl --referer www.baidu.com www.baidu.com //–referer参数表示的是你从哪个页面来的
8)其他参数:
–user-agent 可以用-A或者-H来替代,这个字段表示的是客户端设备的信息,服务器可能会根据这个User Agent字段来判断是手机还是电脑
curl --user-agent " 内容" url
–cookie参数,使用–cookie可以携带cookie信息
curl --cookie “name=xxx” URL
-c cookie-file可以保存服务器返回的cookie到文件,
-b cookie-file可以使用这个文件作为cookie信息,进行后续的请求。
–header增加头部信息
curl --header “Content-Type:application/json” http://example.com
8、磁盘与文件系统的命令(16个)
mount 挂载文件系统。
mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom/ ##将设备/dev/cdrom挂载到 挂载点 : /mnt/cdrom中
mount -t iso9660 -o loop /home/hadoop/Centos-6.7.DVD.iso /mnt/centos ##挂载光盘镜像文件(.iso文件)
mount /dev/fd0 /mnt/floppy 挂载一个软盘
mount -o loop file.iso /mnt/cdrom 挂载一个文件或ISO镜像文件
mount -t vfat /dev/hda5 /mnt/hda5 挂载一个Windows FAT32文件系统
mount /dev/sda1 /mnt/usbdisk 挂载一个usb 捷盘或闪存设备
mount -t smbfs -o username=user,password=pass //WinClient/share /mnt/share 挂载一个windows网络共享
注:挂载的资源在重启后即失效,需要重新挂载。要想自动挂载,可以将挂载信息设置到/etc/fstab配置文件中,vi /etc/fstab,增加:/dev/cdrom /mnt/cdrom iso9660 defaults 0 0
umount 卸载文件系统。
umount /mnt/cdrom(挂载点)
fuser -km /mnt/hda2 当设备繁忙时强制卸载
umount -n /mnt/hda2 运行卸载操作而不写入 /etc/mtab 文件- 当文件为只读或当磁盘写满时非常有用
fsck 检查并修复Linux文件系统。
dd 转换、复制文件。
dumpe2fs 导出ext2/ext3/ext4等文件系统信息。
dump ext2/3/4等文件系统备份工具。
fdisk 磁盘分区命令,适用于2TB以下磁盘分区。
parted 磁盘分区命令,没有磁盘大小限制,常用于2TB以下磁盘分区。
mkfs 格式化创建Linux文件系统。
partprobe 更新内核的硬盘分区表信息。
e2fsck 检查ext2/ext3/ext4等类型文件系统。
mkswap 创建Linux的交换分区。
swapon 启用交换分区。
swapoff 关闭交换分区。
sync 将内存缓冲区内的数据写入磁盘。
resize2fs 调整ext2/ext3/ext4等文件系统大小。
du 计算磁盘空间使用情况。
du -sh /mnt/cdrom/packages统计文件或文件夹的大小
du -cks * | sort -rn | head -n 10 ##找出占用空间最多的文件或目录:
du -sh dir1 估算目录 'dir1' 已经使用的磁盘空间'
du -sk * | sort -rn 以容量大小为依据依次显示文件和目录的大小
ls -lSr |more 以尺寸大小排列文件和目录
rpm -q -a --qf ‘%10{SIZE}t%{NAME}n’ | sort -k1,1n 以大小为依据依次显示已安装的rpm包所使用的空间 (fedora, redhat类系统)
dpkg-query -W -f=‘
I
n
s
t
a
l
l
e
d
−
S
i
z
e
;
10
t
{Installed-Size;10}t
Installed−Size;10t{Package}n’ | sort -k1,1n 以大小为依据显示已安装的deb包所使用的空间 (ubuntu, debian类系统)
df 报告文件系统磁盘空间使用情况。
df -h 查看磁盘的空间
磁盘I/O负载
#iostat -x 1 2 //检查I/O使用率(%util)是否超过100%
光盘操作
光盘
cdrecord -v gracetime=2 dev=/dev/cdrom -eject blank=fast -force 清空一个可复写的光盘内容
mkisofs /dev/cdrom > cd.iso 在磁盘上创建一个光盘的iso镜像文件
mkisofs /dev/cdrom | gzip > cd_iso.gz 在磁盘上创建一个压缩了的光盘iso镜像文件
mkisofs -J -allow-leading-dots -R -V “Label CD” -iso-level 4 -o ./cd.iso data_cd 创建一个目录的iso镜像文件
cdrecord -v dev=/dev/cdrom cd.iso 刻录一个ISO镜像文件
gzip -dc cd_iso.gz | cdrecord dev=/dev/cdrom - 刻录一个压缩了的ISO镜像文件
mount -o loop cd.iso /mnt/iso 挂载一个ISO镜像文件
cd-paranoia -B 从一个CD光盘转录音轨到 wav 文件中
cd-paranoia – “-3” 从一个CD光盘转录音轨到 wav 文件中(参数-3)
cdrecord --scanbus 扫描总线以识别scsi通道
dd if=/dev/hdc | md5sum 校验一个设备的md5sum编码,例如一张 CD
文件系统其他
badblocks -v /dev/hda1 检查磁盘hda1上的坏磁块
fsck /dev/hda1 修复/检查hda1磁盘上linux文件系统的完整性
fsck.ext2 /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck -j /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.ext3 /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.vfat /dev/hda1 修复/检查hda1磁盘上fat文件系统的完整性
fsck.msdos /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
dosfsck /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
初始化一个文件系统
mkfs /dev/hda1 在hda1分区创建一个文件系统
mke2fs /dev/hda1 在hda1分区创建一个linux ext2的文件系统
mke2fs -j /dev/hda1 在hda1分区创建一个linux ext3(日志型)的文件系统
mkfs -t vfat 32 -F /dev/hda1 创建一个 FAT32 文件系统
fdformat -n /dev/fd0 格式化一个软盘
mkswap /dev/hda3 创建一个swap文件系统
SWAP文件系统
mkswap /dev/hda3 创建一个swap文件系统
swapon /dev/hda3 启用一个新的swap文件系统
swapon /dev/hda2 /dev/hdb3 启用两个swap分区
9、系统其它(25个)
echo 打印变量,直接输出指定的字符串
printf 将结果格式化输出到标准输出中。
rpm 管理rpm包命令。
yum 自动化简单化地管理rpm包的命令。
watch 周期的执行给定的命令,并将命令的输出以全屏方式显示。
alias 设置系统别名。
unalias 取消系统别名。
date 查看、设置系统时间。
clear 清除屏幕,简称清屏。
history 查看命令执行的历史纪录。
eject 弹出光驱。
time 计算命令执行时间。
nc 功能强大网络工具。
xargs 将标准输入转换成命令行的参数。
exec 调用并执行指令的命令。
export 设置或者显示环境变量。
unset 删除变量、函数。
type 用于判断另外一个命令是否为内置的命令。
bc 命令行科学计算器
系统管理、性能监视命令(9个)
chkconfig 管理Linux系统开机启动项。
vmstat 虚拟内存统计。
mpstat 显示各个可用CPU的状态统计。
iostat 统计系统的IO。
sar 全面地获取系统CPU、运行队列、磁盘读写、分页、内存、 CPU中断和网络性能数据。
ipcs 用于报告Linux中进程间通信设施的状态,显示信息包括消息列表、共享内存和信号量信息。
ipcrm 用来删除一个或更多的消息队列、信号量集或者共享内存标识。
strace 用于诊断、调试Linux用户空间跟踪器。我们用它来监控用户空间进程和内核交互,比如系统调用、信号传递、进程状态变更。
ltrace 命令会跟踪进程库函数调用,它会显现哪个库函数被调用。
shutdown 关机。
shutdown -h now 关闭系统
init 0 关闭系统
telinit 0 关闭系统
shutdown -h hours:minutes & 按预定时间关闭系统
shutdown -c 取消按预定时间关闭系统
shutdown -r now 重启
reboot 重启(2)
logout 注销
halt 关机。
poweroff 关闭电源。
logout 退出当前登录的Shell。
exit 退出当前登录的Shell。
Ctrl+d 退出当前登录的Shell的快捷键。
进程管理相关命令(15个)
bg 将一个后台暂停的命令,变成继续执行。
fg 将后台的命令调至前台继续运行。
jobs 查看当前有多少后台运行的命令。
kill 终止进程。
killall 通过进程名来终止进程。
pkill 通过进程名来终止进程。
crontab 定时任务命令。
ps 显示进程快照。
pstree 树形显示进程。
nice/renice 调整程序运行的优先级。
nohup 忽略挂起信号运行指定。
pgrep 查找匹配条件进程。
runlevel 查看系统当前运行级别。
init 切换运行级别。
service 启动、停止、重新启动、关闭系统服务,还可以显示所有系统服务的当前状态。
软件安装命令
1)RPM 包 - (Fedora, Redhat及类似系统)
rpm -ivh package.rpm 安装一个rpm包
rpm -ivh --nodeeps package.rpm 安装一个rpm包而忽略依赖关系警告
rpm -U package.rpm 更新一个rpm包但不改变其配置文件
rpm -F package.rpm 更新一个确定已经安装的rpm包
rpm -e package_name.rpm 删除一个rpm包
rpm -qa 显示系统中所有已经安装的rpm包
rpm -qa | grep httpd 显示所有名称中包含 “httpd” 字样的rpm包
rpm -qi package_name 获取一个已安装包的特殊信息
rpm -qg “System Environment/Daemons” 显示一个组件的rpm包
rpm -ql package_name 显示一个已经安装的rpm包提供的文件列表
rpm -qc package_name 显示一个已经安装的rpm包提供的配置文件列表
rpm -q package_name --whatrequires 显示与一个rpm包存在依赖关系的列表
rpm -q package_name --whatprovides 显示一个rpm包所占的体积
rpm -q package_name --scripts 显示在安装/删除期间所执行的脚本l
rpm -q package_name --changelog 显示一个rpm包的修改历史
rpm -qf /etc/httpd/conf/httpd.conf 确认所给的文件由哪个rpm包所提供
rpm -qp package.rpm -l 显示由一个尚未安装的rpm包提供的文件列表
rpm --import /media/cdrom/RPM-GPG-KEY 导入公钥数字证书
rpm --checksig package.rpm 确认一个rpm包的完整性
rpm -qa gpg-pubkey 确认已安装的所有rpm包的完整性
rpm -V package_name 检查文件尺寸、 许可、类型、所有者、群组、MD5检查以及最后修改时间
rpm -Va 检查系统中所有已安装的rpm包- 小心使用
rpm -Vp package.rpm 确认一个rpm包还未安装
rpm2cpio package.rpm | cpio --extract --make-directories bin 从一个rpm包运行可执行文件
rpm -ivh /usr/src/redhat/RPMS/arch/package.rpm 从一个rpm源码安装一个构建好的包
rpmbuild --rebuild package_name.src.rpm 从一个rpm源码构建一个 rpm 包
2)YUM 软件包升级器 - (Fedora, RedHat及类似系统)
yum install package_name 下载并安装一个rpm包
yum localinstall package_name.rpm 将安装一个rpm包,使用你自己的软件仓库为你解决所有依赖关系
yum update package_name.rpm 更新当前系统中所有安装的rpm包
yum update package_name 更新一个rpm包
yum remove package_name 删除一个rpm包
yum list 列出当前系统中安装的所有包
yum search package_name 在rpm仓库中搜寻软件包
yum clean packages 清理rpm缓存删除下载的包
yum clean headers 删除所有头文件
yum clean all 删除所有缓存的包和头文件
3)DEB 包 (Debian, Ubuntu 以及类似系统)
dpkg -i package.deb 安装/更新一个 deb 包
dpkg -r package_name 从系统删除一个 deb 包
dpkg -l 显示系统中所有已经安装的 deb 包
dpkg -l | grep httpd 显示所有名称中包含 “httpd” 字样的deb包
dpkg -s package_name 获得已经安装在系统中一个特殊包的信息
dpkg -L package_name 显示系统中已经安装的一个deb包所提供的文件列表
dpkg --contents package.deb 显示尚未安装的一个包所提供的文件列表
dpkg -S /bin/ping 确认所给的文件由哪个deb包提供
4)APT 软件工具 (Debian, Ubuntu 以及类似系统)
apt-get install package_name 安装/更新一个 deb 包
apt-cdrom install package_name 从光盘安装/更新一个 deb 包
apt-get update 升级列表中的软件包
apt-get upgrade 升级所有已安装的软件
apt-get remove package_name 从系统删除一个deb包
apt-get check 确认依赖的软件仓库正确
apt-get clean 从下载的软件包中清理缓存
apt-cache search searched-package 返回包含所要搜索字符串的软件包名称
10、四剑客及高级(grep,sed,awk,cut,管道,xargs)
10.1 cut:以分隔符截取列(分段)
说明:cut命令用于读取文件的每一行按分隔符获取指定字节、字符和字段数并将这些字节、字符和字段写至标准输出。我们把cutm命令,可简单认为是对行数据的处理。官方释义:remove sections from each line of files(截取每行分段);如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
语法:
cut OPTION... [FILE]...
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
参数:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符(TAB)。
-f :与-d一起使用,指定显示哪个区域,即指定哪一个字段进行提取。。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除
eg1:cut截取以:分割保留第七段:grep hadoop /etc/passwd | cut -d: -f7 //分隔符也可以单引号引起
eg2:使用分隔符:打印/etc/passwd文件中每一行的第一个字段
cut -d ‘:’ -f 1 /etc/passwd
eg3:grep ‘/bin/bash’ /etc/passwd| cut -d ‘:’ -f 1,6 //从/etc/passwd文件提取第一和第六个字段
eg4:grep ‘/bin/bash’ /etc/passwd|cut -d ‘:’ -f 1-4,6,7 //取1-4连续字段的范围,指定以-分隔的开始字段和结束字段即可;
eg5:grep ‘/bin/bash’ /etc/passwd|cut -d ‘:’ --complement -f 2 //–complement用于排除/etc/passwd文件中的第二个字段
eg6:cut -d ‘:’ -f1,7 --output-delimiter=’ ’ /etc/passwd|sort //–output-delimiter=’ '用于指定输出的分隔符,默认输出的为cut处理时的指定分隔符
注:cut命令一个限制是它不支持指定多个字符作为分隔符。多个空格被视为多个字段分隔符,必须使用tr命令才能得到所需的输出。
10.2 grep查询表达式匹配到的字符或字符串
grep -v hadoop /etc/passwd ##查询不包含hadoop的行
grep ‘hadoop’ /etc/passwd ##一般用单引号,如果内部有转移字符的话且想保留转移字符的意义,这时用双引号;单引号屏蔽特殊字符的意义。
grep 'h.*p' /etc/passwd 正则表达(点代表任意一个字符)
grep '^hadoop' /etc/passwd 正则表达以hadoop开头
grep 'hadoop$' /etc/passwd 以hadoop结尾
grep -v '^#' a.txt | grep -v '^$' 查找不是以#开头的行
grep '^[hr]'/etc/passwd 以h或r开头的
grep '^[^hr]' /etc/passwd 不是以h和r开头的
grep '^[^h-r]' /etc/passwd 不是以h到r开头的
grep [0-9] /var/log/messages 选择 '/var/log/messages' 文件中所有包含数字的行
grep Aug -R /var/log/* 在目录 '/var/log' 及随后的目录中搜索字符串"Aug"
规则:
. : 任意一个字符
a* : 任意多个a(零个或多个a)
a? : 零个或一个a
a+ : 一个或多个a
.* : 任意多个任意字符
. : 转义.
o{2} : o重复两次
10.3 awk 文本分析工具
awk对文件进行逐行读入,默认以空格为分隔符将每行切片,切开的部分再进行各种分析处理,即awk会对文本依次对每一行进行处理,然后输出。 awk是行处理器,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息。
awk的用法:
awk 参数 ’ BEGIN{} // {action1;action2} ’ END{} 文件名 //-F 指定分隔符;-f 调用脚本,-v 定义变量,awk的格式中,-F后紧跟单引号,然后里面可自定义输出分隔符,print的动作要用 { } 括起来,否则会报错。print还可以打印自定义的内容,但是自定义的内容要用“”双引号括起来。
Begin{}: //初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
/匹配内容/: // 匹配代码块,可以是字符串或正则表达式;'$1~/me/'中,~表示匹配的意思,获取第一个字段并匹配其后/ /内的关键字me;
{} : // 命令代码块,包含一条或多条命令,多条命令用 ; 隔开
END{} : //结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
eg1: //统计 /etc/passwd 文件中包含root行的总数
#awk ‘BEGIN{X=0}/root/{X+=1}END{print “I find”,X,“root lines”}’ /etc/passwd

eg2:显示 /etc/passwd 中含有 root 的行
awk ‘/root/’ /etc/passwd
eg3:以 : 为分隔,显示/etc/passwd中每行的第1和第7个字段(可以理解为1和第7列)
awk -F “:” ‘{print $1,$7}’ /etc/passwd
awk ‘BEGIN{FS=“:”}{print $1,$7}’ /etc/passwd
eg4:以 : 为分隔,显示/etc/passwd中含有 root 的行的第1和第7个字段
awk -F “:” ‘/root/ {print $1,$7}’ /etc/passwd
eg5:以 : 为分隔,显示/etc/passwd中以 root 开头行的第1和第7个字段
awk -F “:” ‘/^root/ {print $1,$7}’ /etc/passwd
eg6:以 : 为分隔,显示/etc/passwd中第3个字段大于999的行的第1和第7个字段
awk -F ":" '$3>999{print $1,$7}' /etc/passwd
类似的还有:awk -F: '$3=="600"' passwd
这是awk匹配条件操作符的用法,用逻辑符号判断的,比如 ‘==' 就是等于,也可以理解为 ‘精确匹配' 另外也有 >, ‘>=, ‘<, ‘<=, ‘!= 等等,值得注意的是,在和数字比较时,若把比较的数字用双引号引起来后,那么awk不会认为是数字,而认为是字符,加单引号和不加则认为是数字。还可以使用 && “并且”和 || “或者” 的意思。
awk -F: '$3>$4 && $7=="/bin/bash"' passwd
eg7:以 : 为分隔,显示/etc/passwd中第7个字段包含bash的行的第1和第7个字段
awk -F “:” ‘$7 ~ “bash” {print $1,$7}’ /etc/passwd
eg8:以 : 为分隔,显示/etc/passwd中第7个字段不包含bash的行的第1和第7个字段
awk -F “:” ‘$7!~“nologin”{print $1,$7}’ /etc/passwd
eg9:以 : 为分隔,显示$3>999并且第7个字段包含bash的行的第1和第7个字段,非系统用户的异常登录权限
awk -F “:” ‘$3>999&&$7~“bash”{print $1,$7}’ /etc/passwd
eg10:以 : 为分隔,显示$3>999或第7个字段包含bash的行的第1和第7个字段
awk -F “:” ‘$3>999||$7~“bash”{print $1,$7}’ /etc/passwd
eg11:获取eth0网卡的ip和掩码
ifconfig eth0|awk -F “[ :]+” ‘NR==2{print $4 “/” $NF}’ //[ :]+这个是正则表达式,+表示一个或多个,这里就表示一个或多个空格或冒号;

eg12:awk -F: ‘/root/ {print $1,$3} /user/ {print $1,$3}’ passwd //多次匹配,本例中全文匹配包含root关键词的行,再匹配包含user的行,打印所匹配的第1、3段。
【字符含义】:
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量,用分隔符分隔后一共有多少段
NR 行数,每行的记录号,多文件记录递增,{print NR":"NF}列出行号,以冒号分隔,列出共有多少段;
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符,内建变量FS保存输入域分隔符的值,默认是空格或tab。我们可以通过-F命令行选项修改FS的值。如$ awk -F: '{print $1,$5}' test将打印以冒号为分隔符的第一,第五列的内容。可以同时使用多个域分隔符,这时应该把分隔符写成放到方括号中,如$awk -F'[ :\t]' '{print $1,$3}' test,表示以空格、冒号和tab作为分隔符。
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 包含
!~ 不包含
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
\+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
OFS 自定义输出字段分隔符, 默认也是空格,可以改为其他的,'OFS="#"{print $3,$4}',分隔符需要用双引号括起来
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F [:#/] 定义了三个分隔符
【print 打印】:print 是 awk打印指定内容的主要命令,也可以用 printf
awk ‘{print}’ /etc/passwd 等效于 awk ‘{print $0}’ /etc/passwd
awk ‘{print " "}’ /etc/passwd 不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
awk ‘{print “a”}’ /etc/passwd //输出相同个数的a行,一行只有一个a字母
awk -F: ‘{print $1}’ /etc/passwd 等效于 awk -F “:” ‘{print $1}’ /etc/passwd
awk -F: ‘{print $1 $2}’ //输入字段1,2,中间不分隔
awk -F: ‘{print $1,$3,$6}’ OFS=“\t” /etc/passwd 输出字段1,3,6, 以制表符作为输出分隔符
awk -F: ‘{print $1; print $2}’ /etc/passwd 输入字段1,2,分行输出
awk -F: ‘{print $1 “**” $2}’ /etc/passwd 输入字段1,2,中间以**分隔
awk -F: ‘{print “name:”$1"\tid:"$3}’ /etc/passwd 自定义格式输出字段1,2

awk -F: ‘{print NF}’ /etc/passwd 显示每行有多少字段(多少个分段/多少列)
awk -F: ‘NF>2{print }’ /etc/passwd 将每行字段数大于2的打印出来
awk -F: ‘NR==5{print}’ /etc/passwd 打印出/etc/passwd文件中的第5行
awk -F: ‘NR==5|NR==6{print}’ /etc/passwd 打印出/etc/passwd文件中的第5行和第6行
awk -F: ‘NR!=1{print}’ /etc/passwd 不显示第一行
awk -F: ‘{print > “1.txt”}’ /etc/passwd 输出到文件中
awk -F: ‘{print}’ /etc/passwd > 2.txt 使用重定向输出到文件中
【字符匹配】:
awk -F: '/root/{print }' /etc/passwd 打印出文件中含有root的行
awk -F: '/'$A'/{print }' /etc/passwd 打印出文件中含有变量 $A的行
awk -F: '!/root/{print}' /etc/passwd 打印出文件中不含有root的行
awk -F: '/root|tom/{print}' /etc/passwd 打印出文件中含有root或者tom的行
awk -F: '/mail/,mysql/{print}' test 打印出文件中含有 mail*mysql 的行,*代表有0个或任意多个字符
awk -F: '/\^[2][7][7]*/{print}' test 打印出文件中以27开头的行,如27,277,27gff 等等
awk -F: '$1~/root/{print}' /etc/passwd 打印出文件中第一个字段是root的行
awk -F: '($1=="root"){print}' /etc/passwd 打印出文件中第一个字段是root的行,与上面的等效
awk -F: '$1!~/root/{print}' /etc/passwd 打印出文件中第一个字段不是root的行
awk -F: '($1!="root"){print}' /etc/passwd 打印出文件中第一个字段不是root的行,与上面的等效
awk -F: '$1~/root|ftp/{print}' /etc/passwd 打印出文件中第一个字段是root或ftp的行
awk -F: '($1=="root"||$1=="ftp"){print}' /etc/passwd 打印出文件中第一个字段是root或ftp的行,与上面的等效
awk -F: '$1!~/root|ftp/{print}' /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行
awk -F: '($1!="root"||$1!="ftp"){print}' /etc/passwd 打印出文件中第一个字段不是root或不是ftp的行,与上面等效
awk -F: '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd 如果第一个字段是mail,则打印第一个字段,否则打印第2个字段
awk '/\$1|\$6/{print $1}' /etc/shadow
awk '/\$6/{print $1}' /etc/shadow
上述两条命令等效,其中正则表达式'/\$1|\$6/{print $1}'表示使用匹配模式'/匹配模式/',|表可以匹配多个规则,抓取$1或$6字符的行,$0它表示整行,$n表第n个字段,因打印分段默认分隔符为空格,所以$1就相当于整行了,关于口令特性如下:
星号代表帐号被锁定,将无法登录;双叹号表示这个密码已经过期了, 如果是$x$xxxxxxxx$的形式,则代表密码正常。
$6$开头的,表明是用SHA-512加密的,密文长度86,示例中‘5NAhdLZN’为salt值,是一个随机字符串,供加密使用
$1$ 表明是用MD5加密的,密文长度22个字符
$2$ 是用Blowfish加密的,
$5$ 是用 SHA-256加密的,密文长度43
格式化输出
awk ‘{printf “%-5s %.2d”,$1,$2}’ test
printf 表示格式输出
%格式化输出分隔符
-8表示长度为8个字符
s表示字符串类型,d表示小数
10.4 sed:流编辑器
sed把当前处理的行存储在一个称为“模式空间”(pattern space)的临时缓冲区中。 sed 处理数据之前,需要预先提供一组规则,sed 会按照此规则来编辑数据。此命令的关键在于掌握各式各样的脚本命令及模式匹配;sed模式是匹配行,而非对应的字符串,操作时对匹配航的匹配字符串,模式中y可进行字符替换,它会对单个字符一一映射匹配替换。
【语法】:
1)sed的命令格式:sed [options] ‘command’ file(s); //默认直接在命令行模式上进行sed动作编辑
2)sed的脚本格式:sed [options] -f scriptfile file(s); //-f选项,将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
注意:对于/pattern/command,必须用正斜线将要指定的 pattern 封起来,sed 会将该命令作用到包含指定文本模式的行上。
命令执行数据的顺序如下:
1>每次仅读取一行内容;
2>根据提供的规则命令匹配并修改数据。注意, sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
3>将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
【选项】:
-i :直接修改文件内容;
-n :只打印模式匹配的行;默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。
-r :支持扩展表达式;
-e 脚本命令: 该选项会将其后跟的脚本命令添加到已有的命令中
-f 脚本命令文件: 该选项会将其后文件中的脚本命令添加到已有的命令中
【模式参数】:
a(或 i)+\新文本内容: 在当前行下面插入文本;
i\ +要插入的新文本 : 在当前行上面插入文本;
c+用于替换的新文本: 把选定的行改为新的文本;
y/inchars/outchars/:转换命令会对 inchars 和 outchars 值进行一对一的映射,即 inchars 中的第一个字符会被转换为 outchars 中的第一个字符,第二个字符会被转换成 outchars 中的第二个字符…这个映射过程会一直持续到处理完指定字符。如果 inchars 和 outchars 的长度不同,则 sed 会产生一条错误消息。
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行,即搜索符号条件的行,并输出该行的内容。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
【文本替换参数】:
g 表示行内全面替换;
p 表示打印行;
w 表示把行写入一个文件;
x 表示互换模板块中的文本和缓冲区中的文本;
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式);
\1 子串匹配标记;
& 已匹配字符串标记;
【文本匹配】:
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行;
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行;
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d;
- 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行;
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed;
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行;
(…) 匹配子串,保存匹配的字符,如s/(love)able/\1rs,loveable被替换成lovers;
& 保存搜索字符用来替换其他字符,如s/love/&/,love这成love;
< 匹配单词的开始,如:/\
> 匹配单词的结束,如/love>/匹配包含以love结尾的单词的行;
x{m} 重复字符x,m次,如:/0{5}/匹配包含5个0的行;
x{m,} 重复字符x,至少m次,如:/0{5,}/匹配至少有5个0的行;
x{m,n} 重复字符x,至少m次,不多于n次,如:/0{5,10}/匹配5~10个0的行;
命令示例:
测试文件:#cat sed.txt
date schooL teaCher
tea Car red Hell0
Centos liNux
1)sed ‘s/date/Date/’ sed.txt

2)sed -n ‘s/date/Date/p’ sed.txt //-n 选项会禁止 sed 输出,但 p 标记会输出修改过的行,-n选项和p命令一起使用表示只打印那些发生替换的行:

3)sed ‘s/date/Date/2’ sed.txt //使用数字 2 作为标记的结果就是,sed 编辑器只替换每行中第 2 次出现的匹配模式
-
sed ‘s/date/Date/w test.txt’ sed.txt //w 标记会将匹配后的结果保存到指定文件中
-
sed ‘3d’ sed.txt //删除 sed.txt 文件内容中的第 3 行,如果不指定删除行,sed文件内容将全部删除,请慎重
6)sed ‘2,3d’ sed.txt //删除 sed.txt 文件内容中的第 2、3行
7)sed ‘/1/,/3/d’ sed.txt //删除第 1~3 行的文本数据,用两个文本模式来删除某个区间内的行,要小心指定的第一个模式会“打开”行删除功能,第二个模式会“关闭”行删除功能,因此,sed 会删除两个指定行之间的所有行(包括指定的行)
8)sed ‘3,$d’ sed.txt //删除 sed.txt 文件内容中第 3 行开始的所有的内容,默认情况下 sed 并不会修改原始文件,这里被删除的行只是从 sed 的输出中消失了,原始文件没做任何改变。
9)sed ‘3i\This is an inserted line.’ sed.txt //将一个新行插入到数据流第三行前,将i改为a,就表示将一个新行附加到数据流中第三行后
10)将一个多行数据添加到数据流中,只需对要插入或附加的文本中的每一行末尾(除最后一行)添加反斜线即可:
sed '1i\
This is one line of new text.
This is another line of new text.’ sed.txt ##//第1行前插入2行
11)sed ‘3c\This is a changed line of text.’ sed.txt //sed 编辑器会修改第三行中的文本,将第2行修改/替换为新内容
12)echo “This 1 is a test of 1 try.” | sed ‘y/123/456/’ //输出如下,因y字符替换是全局命令,它会文本行中找到的所有指定字符自动进行转换,而不会考虑它们出现的位置,无法限定只转换在特定地方出现的字符
This 4 is a test of 4 try.
13) sed -n ‘/number 3/p’ sed.txt //用 -n 选项和 p 命令配合使用,我们可以禁止输出其他行,只打印包含匹配文本模式的行,用于只查看特定行的内容
14)如需要在修改之前查确认该行,可以使用打印命令,与替换或修改命令一起使用,sed 命令会查找包含数字 3 的行,然后执行两条命令。首先,脚本用 p 命令来打印出原始行;然后它用 s 命令替换文本,并用 p 标记打印出替换结果。输出同时显示了原来的行文本和新的行文本。
sed -n '/3/{
> p
> s/line/test/p
> }' data6.txt
This is line number 3.
This is test number 3.
15)r 命令用于将一个独立文件的数据插入到当前数据流的指定位置
[root@localhost ~]# cat data12.txt
This is an added line.
This is the second added line.
[root@localhost ~]# sed '3r data12.txt' data6.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is an added line.
This is the second added line.
This is line number 4.
将指定文件中的数据插入到数据流的末尾,可以使用 $ 地址符:
sed '$r data12.txt' data6.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
This is an added line.
This is the second added line.
16)sed ‘/number 1/{ s/number 1/number 0/;q; }’ test.txt //sed 命令会在匹配到 number 1 时,将其替换成 number 0,然后直接退出
17)默认情况下,sed 命令会作用于文本数据的所有行。如果只想将命令作用于特定行或某些行,则必须写明 address 部分,表示的方法有以下 2 种:
a、以数字形式指定行区间;
eg1:sed ‘2s/dog/cat/’ data1.txt //sed 只修改地址指定的第二行的文本
eg2:sed ‘2,3s/dog/cat/’ data1.txt //修改指定的第二行到第三行包括2者的文本
eg3:sed ‘2,$s/dog/cat/’ data1.txt //修改文本中从某行开始的所有行
b、用文本模式指定具体行区间。
[address]脚本命令
或者
address {
多个脚本命令
} //上例中的/number 1/就是指定了匹配的address
18)用文本模式指定行区间:/pattern/command;必须用正斜线将要指定的 pattern 封起来,sed 会将该命令作用到包含指定文本模式的行上
eg1:sed ‘/demo/s/bash/csh/’ /etc/passwd //只修改用户 demo 的默认 shell
在文本模式使用正则表达式指明作用的具体行。正则表达式允许创建高级文本模式匹配表达式来匹配各种数据。这些表达式结合了一系列通配符、特殊字符以及固定文本字符来生成能够匹配几乎任何形式文本的简练模式。
19)其他用法:
sed ‘/^KaTeX parse error: Expected 'EOF', got '#' at position 48: …除所有空白行 sed '/ *#̲/d; /^/d’ example.txt 从example.txt文件中删除所有注释和空白行
echo ‘esempio’ | tr ‘[:lower:]’ ‘[:upper:]’ 合并上下单元格内容
sed -e ‘1d’ result.txt 从文件example.txt 中排除第一行
sed -n ‘/stringa1/p’ 查看只包含词汇 “string1"的行
sed -e ‘s/ $//’ example.txt 删除每一行最后的空白字符
sed -e ‘s/stringa1//g’ example.txt 从文档中只删除词汇 “string1” 并保留剩余全部
sed -n ‘1,5p;5q’ example.txt 查看从第一行到第5行内容
sed -n ‘5p;5q’ example.txt 查看第5行
sed -e 's/00/0/g’ example.txt 用单个零替换多个零
cat -n file1 标示文件的行数
cat example.txt | awk ‘NR%2==1’ 删除example.txt文件中的所有偶数行
echo a b c | awk ‘{print $1}’ 查看一行第一栏
echo a b c | awk ‘{print $1,$3}’ 查看一行的第一和第三栏
paste file1 file2 合并两个文件或两栏的内容
paste -d ‘+’ file1 file2 合并两个文件或两栏的内容,中间用”+"区分
sort file1 file2 排序两个文件的内容
sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq -u 删除交集,留下其他的行
sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm -1 file1 file2 比较两个文件的内容只删除 ‘file1’ 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 ‘file2’ 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
20)特殊用法:
10.5 、tr(Translate替换/转译)命令
用于替换/转化(大小写转化)、压缩重复和/或删除标准输入中的字符,写入标准输出。在没有任何参数选项时,默认是替换,与加上-s参数选项结果是一致的。
语法:tr [OPTION]…SET1[SET2]
参数:
-c, --complement:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
-d, --delete:删除指令字符
-s, --squeeze-repeats:缩减连续重复的字符成指定的单个字符
-t, --truncate-set1:削减 SET1 指定范围,使之与 SET2 设定长度相等
–help:显示程序用法信息
–version:显示程序本身的版本信息
11、正则表达式(regular expression):
正则表达式(regular expression)是一种文本模式,描述了一种字符串匹配的模式(pattern),包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。使用该模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。或这种模式,描述了在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。模式中由5类字符组成:
1)普通字符
[A-Za-z0-9_] //所有大写和小写字母、所有数字、所有标点符号和一些其他符号
2)非打印字符
\cx 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
3)特殊字符
所谓特殊字符,就是一些有特殊含义的字符。‘*’,'+‘和’?'这三个符号,表示一个或一序列字符重复出现的次数。它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面;
4)限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。

示例:
[0-9]* 表示任意多个数字;
在方括号里用 '^'表示不希望出现的字符,'^'应在方括号里的第一位;
"(b¦cd)ef":表示"bef"或"cdef";
请注意表示范围:必须指定范围的下限;如:"{0,2}"而不是"{,2}"。
2)'*','+'和'?'相当于"{0,}","{1,}"和"{0,1}"。
3)'¦',表示“或”操作。在方括号里用'^'表示不希望出现的字符,'^'应在方括号里的第一位,在方括号中,不需要转义字符。
4)* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个? 就可以实现非贪婪或最小匹配。通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配。
5)其他字符匹配(Java正则表达式):
\d :匹配一个数字字符。[0-9]
\D :匹配一个非数字字符。[^0-9]
\w :匹配包括下划线的任何单词字符。[0-9a-zA-Z_]
\W :匹配任何非单词字符。[^\w]
\s :匹配任何空白字符 空格、制表符、换行符
\S :匹配任何非空白字符。
5)定位符
定位符使您能够将正则表达式固定到行首或行尾。定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。 \B 非单词边界运算符,位置并不重要,因为匹配不关心究竟是单词的开头还是结尾。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
12、高级命令组合
SHELL显示多个信息,用EOF
cat << EOF
+--------------------------------------------------------------+
| === Welcome to Nginx Home === |
+--------------------------------------------------------------+
EOF
获取IP地址
ifconfig eth0 |grep “inet addr:” |awk ‘{print $2}’|cut -c 6- //6-表从左第6个字符开始获取
ifconfig eth0 |grep "inet " |awk ‘{print $2}’|cut -c 6-
或者
ifconfig | grep ‘inet addr:’| grep -v ‘127.0.0.1’ | cut -d: -f2 | awk ‘{ print $1}’
ifconfig | grep 'inet '| grep -v ‘127.0.0.1’ | cut -d: -f2 | awk ‘{ print $2}’
获取内存
free -m |grep “Mem” | awk ‘{print $2}’
查看连接某服务端口最多的的IP地址
netstat -an -t | grep “:80” | grep ESTABLISHED | awk ‘{printf “%s %s\n”,$5,$6}’ | sort

查看Apache的并发请求数及其TCP连接状态:
netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’

统计某一类文件大小
eg1:find / -name *.jpg -exec wc -c {} ;|awk ‘{print $1}’|awk ‘{a+=$1}END{print a}’
清除僵死进程
ps -eal | awk ‘{ if ($2 == “Z”) {print $4}}’ | kill -9
13、30个常用快捷键



14、运维实战
a、系统负载查询确认
1>CPU负载情况
1)查看逻辑CPU个数:cat /proc/cpuinfo |grep “processor”|sort -u|wc -l
2)查看物理CPU个数:grep “physical id” /proc/cpuinfo|sort -u|wc -l
3)查看每颗物理CPU核数:cat /proc/cpuinfo |grep “cores”|uniq
每个物理CPU上逻辑CPU个数:grep “siblings” /proc/cpuinfo|uniq
查看是否开启了抄超线程:如多个逻辑CPU的"physical id"和"core id"均相同,说明开启了超线程;
逻辑如下:
a.逻辑CPU个数 > 物理CPU个数 * CPU内核数 开启了超线程
b.逻辑CPU个数 = 物理CPU个数 * CPU内核数 没有开启超线程
4)查看CPU的主频:cat /proc/cpuinfo |grep MHz|uniq
#!/bin/bash
## 定义初始变量
physicalNumber=0
coreNumber=0
logicalNumber=0
HTNumber=0
##获取系统参数值
logicalNumber=$(grep "processor" /proc/cpuinfo|sort -u|wc -l)
physicalNumber=$(grep "physical id" /proc/cpuinfo|sort -u|wc -l)
coreNumber=$(grep "cpu cores" /proc/cpuinfo|uniq|awk -F':' '{print $2}'|xargs)
HTNumber=$((logicalNumber / (physicalNumber * coreNumber)))
cpuHZ=$(cat /proc/cpuinfo |grep MHz|uniq)
echo "****** CPU Information ******"
echo "Logical CPU Number : ${logicalNumber}"
echo "Physical CPU Number : ${physicalNumber}"
echo "CPU Core Number : ${coreNumber}"
echo "HT Number : ${HTNumber}"
echo "Systen cpu MHZ : ${cpuHZ}"
echo "*****************************"

5)top命令:

其中:load average这三个值,隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值;默认不超过cpu合数的2倍为好,超过2倍说明负载偏高;如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了;经验表明:每单核负载在3-5之间尚可,超过6甚至8,就要立刻排查cpu负载高的问题,否则极易宕机。检查%idle是否过低(比如小于5%); us 用户空间占用CPU百分比; sy 内核空间占用CPU百分比;ni 用户进程空间内改变过优先级的进程占用CPU百分比;id 空闲CPU百分比;wa 等待输入输出的CPU时间百分比;hi 硬中断(Hardware IRQ)占用CPU的百分比;si 软中断(Software Interrupts)占用CPU的百分比;st 用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
输出结果说明:
PID:进程编号
USER:进程所属用户
PR/NI:Priority/Nice value进程执行的优先顺序
VIRT:Virtual Image (kb) 虚拟内存使用总额;进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等,即使进程实际使用的远少于改值,但进程运行满载时会达到改值;VIRT=SWAP+RES
RES:Resident size (kb) 常驻内存,表进程当前使用的内存大小,包含其他进程的共享但不包括swap out;RES=CODE+DATA
SHR:Shared Mem size (kb) 共享内存;除了自身进程的共享内存,也包括其他进程的共享内存,即使进程只使用了几个共享库的函数,但它用了整个共享库的大小来占用**;因此,** 某个进程所占的物理内存大小公式:RES – SHR
S:Process Status 进程状态:D不可中断的睡眠状态 R运行态 S睡眠态 T跟踪/停止态 Z僵尸态
%CPU:cpu使用率
%MEM:内存使用率
TIME+:进程开始运行时使用cpu的总时间
COMMAND:进程运行的命令
第三行表示cpu的运行情况,按下1可以显示每个核的运行情况。 top默认排序是%CPU;shift+> 或者shift+< 向右或者向左切换排序基准,共12列,cpu为9列,mem为10列。按x高亮显示,可知道当前是哪一行为排序行。

默认进入top时,各进程是按照CPU的占用量来排序的。在top基本视图中,按键数字“1”可以监控每个逻辑CPU的状况;按键‘b’(打开关闭加亮效果);‘y’来打开或者关闭运行态进程的加亮效果;‘x’(打开/关闭排序列的加亮效果);按”shift+>”或者”shift+<”左右改变排序序列;”f”可进入编辑基本视图中的显示字段;
top -u root //-u:user显示指定用户的进程
top -p 1 //-p:pid显示指定进程
进入top后,按n:设置top屏幕显示的任务数

top -n 5 //top -n num:设置top刷新的次数,指定刷新次数后将退出top,默认一直刷
top -d 5 //delay进入top后,top会定时刷新状态,默认值是5 s,-d参数指定top几秒刷新一次,即刷新频率
top -b -n 60 -d 60 > /tmp/cpu.txt //-b:Batch mode批处理模式,top刷新状态默认是在原数据上刷新,使用-b参数后,会一屏一屏的显示数据。结合重定向功能和计划任务,-b参数在记录服务器运行状态时非常有用。
#更多参数
-d seconds:设置top命令更新屏幕显示的时间间隔(以秒为单位)。默认是3秒或5秒,取决于系统配置。
-b:以批处理模式运行top,这意味着top将输出到标准输出而不等待用户输入。这通常用于脚本中。
-n count:与-b一起使用,指定top命令应该输出多少次更新结果后退出。
-p pid:监视特定的进程ID(PID)。可以指定多个PID,例如-p 1234,5678。
-S:启用累计模式,显示进程在其生命周期内使用的总CPU时间。
-s:使top命令在安全模式下运行,禁用所有交互式命令,防止意外操作。
-i:忽略任何闲置和僵尸进程,不显示它们。
-c:显示完整的命令行,而不仅仅是命令名称。

-M:Memory按照内存使用量排序
-P:CPU按照cpu使用量排序
进入top后按k键:(kill杀死PID的进程)
top -H //以线程方式查看top视图,等同于top内的H键

大写的 R 键可以将当前的排序倒转;
6)自动记录cpu一段时间状态:
top -b -n 60 -d 60 > /tmp/cpu.txt
7)top -H -p 进程号 //查看异常线程
8)查看占用cpu高的线程
ps -H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpu #说明:'H',显示线程相关;-o指定显示的列; -T 显示线程数
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head #linux下获取占用CPU资源最多的10个进程
9)查看占用内存高的线程:
ps aux | head -1;ps aux|sort -k4nr|head -5
linux下获取占用内存资源最多的10个进程:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
cat /proc/pid/status //查看该进程的内存占用情况
10)查看进程按内存、cpu从大到小排序:
ps -e -o “%C : %p : %z : %a”|sort -k5 -nr
ps -e -o “%C : %p : %z : %a”|sort -nr
11)cat /proc/loadavg # 查看系统负载
2>内存负载情况
1)查看进程内存的状况:pmap PID; //查看进程的内存映像信息

说明:
-d:how the deviceformat. 显示设备格式
-q quiet 不显示头尾行
-x extended 显示扩展格式
2)循环显示上述进程的输出的最后1行,间隔2秒:
while true; do pmap -d 11957 | tail -1; sleep 2; done;

最后一行的值说明:
mapped 表示该进程映射的虚拟地址空间大小,也就是该进程预先分配的虚拟内存大小,即ps出的vsz
writeable/private 表示进程所占用的私有地址空间大小,也就是该进程实际使用的内存大小
shared 表示进程和其他进程共享的内存大小
3)查看某进程的设备状态下的内存使用
Address: 内存开始地址、Kbytes: 占用内存的字节数(KB)
Mode: 内存的权限:read、write、execute、shared、private (写时复制)
Offset: 文件偏移
Mapping: 占用内存的文件、或[anon](分配的内存)、或[stack](堆栈)
Device: 设备名 (major:minor)
3>进程和线程异常情况
1)查看当前站cpu最高的进程的线程使用情况:
top -H -p ps aux|sort -k4nr|head -1|awk '{print $2}'

lsof -p pid(察看该进程所打开端口和文件)
2)如上述输出有异常线程,可利用printf “%x\n” 线程号,将异常线程号转化为16进制,用于后续的java线程跟踪用。
printf “%x\n” 12791 //tid需要使用16进制值

3)查看java进程堆栈信息
jstack 进程号|grep 16进制异常线程号 -A90 //-A90是日志行数;查看运行的 Java 进程下,多线程的运行情况
注意:jstack命令在jdk的bin目录下
jstack -F 12791|grep 31f7 -A90 //-F option can be used when the target process is not responding

线程状态有以下几种:
RUNNABLE 线程运行中或 I/O 等待
BLOCKED 线程在等待 monitor 锁( synchronized 关键字)
TIMED_WAITING 线程在等待唤醒,但设置了时限
WAITING 线程在无限等待唤醒
如输出结果有GC,说明内存已经用尽;
jstat -gcmetacapacity pid //命令查看内存分布情况及GC情况

jstat -gcutil pid //查看GC情况
jstat -gccapacity pid
4)查看某进程的线程信息:
ps -mp pid -o THREAD,tid,time|sort -rn //tid为代码线程ID,time代表这个线程的已运行时间;
jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题,
注:其中,LWP为轻量级进程,即线程PID;NLWP为线程数量;WCHAN表当前进程是否正在运行,若为-表示正在运行,若该进程在睡眠,则显示睡眠中的系统函数名;
jps -v //找到java进程相关的pid
jstack -l 12791 >> 123.txt //导出堆栈信息;
5)其他进程管理命令:htop、vmstat、dstat、iostat、glances,pstree、ps、pidof、pgrep、pkill、pmap、kill、killall、job、bg、fg等;
6)当进程打开了某个文件时,只要该进程保持打开该文件,即使将其删除,它依然存在于磁盘中。这意味着,进程并不知道文件已经被删除,它仍然可以向打开该文件时提供给它的文件描述符进行读取和写入。除了该进程之外,这个文件是不可见的,因为已经删除了其相应的目录索引节点。只要这个时候系统中还有进程正在访问该文件,那么我们就可以通过lsof从/proc目录下恢复该文件的内容。
7)可运行进程数目 # vmwtat 1 5
列给出的是可运行进程的数目,检查其是否超过系统逻辑CPU的4倍
- top -id 1 //观察是否有异常进程出现
9)vmstat命令:
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。是对系统的整体情况进行统计,但不适于对某个具体进程进行深入分析。
#vmstat 5 5 //5秒时间内进行5次采样
输出结果字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(Linux默认块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。【interrupt】
cs: 每秒上下文切换数。 【count/second】
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
指标参考:
如果r经常大于4,id经常少于40,表示cpu的负荷很重。
如果bi,bo长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
示例:
eg1:vmstat -a 2 5 //-a 显示活跃和非活跃内存,所显示的内容将增加inact和active列,对应非活跃和活跃;
eg2:vmstat -f //查看linux下创建进程的系统调用。即fork次数,实际是从/proc/stat中的processes字段里取得的值
eg3:vmstat -s //显示内存相关统计信息,包括已使用内存,活跃内存,实际取值于/proc/meminfo,/proc/stat和/proc/vmstat
eg4:vmstat -d //查看磁盘的读写,实际取之于/proc/diskstats
vmstat -p /dev/sda1 //显示指定磁盘分区统计信息
其中,输出结果:
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
eg5:vmstat -m //查看系统的slab信息,用于存储i节点,目录项等小对象,避免为他们消耗一个内存页(4kb),减少内存分配次数。际取值于/proc/slabinfo
eg6:
10)ps命令:
常用参数:
-A 显示所有进程(等价于-e)(utility)
-a 显示一个终端的所有进程,除了会话引线
-N 忽略选择。
-C 通过命令名称搜索进程,后面跟你要找的进程的名字即可
-d 显示所有进程,但省略所有的会话引线(utility)
-x 显示没有控制终端的进程,同时显示各个命令的具体路径。dx不可合用。(utility)
-p pid 进程使用cpu的时间
-u uid or username 选择有效的用户id或者是用户名, 如果长度大于8个字符,然后ps将只显示UID,而不是用户名;多个用户名可以提供以逗号分隔。
-g gid or groupname 显示组的所有进程。
U username 显示该用户下的所有进程,且显示各个命令的详细路径。如:ps U zhang;(utility)
-f -forest全部列出,通常和其他选项联用。如:ps -fa or ps -fx and so on.
-l 长格式(有F,wchan,C 等字段)
-L 查看特定进程的线程
-j 作业格式
-o 用户自定义格式。
v 以虚拟存储器格式显示
s 以信号格式显示
-m 显示所有的线程
-H 显示进程的层次(和其它的命令合用,如:ps -Ha)(utility)
e 命令之后显示环境(如:ps -d e; ps -a e)(utility)
h 不显示第一行
–sort 选项由逗号分隔的多个字段可以用指定,–sort=-pcpu,+pmem(或–sort +pmem,-pcpu),cpu降序排列,内存升序排列。
ps命令参数使用支持以下3种风格:
1)BSD风格: 在 BSD 风格的语法选项前不带连字符。例如: ps aux
2)UNIX/LINUX的风格:在 linux 风格的语法选项前面有一个 “-”。例如: ps -ef
3)混合使用两种 Linux 系统上的语法风格是好事儿。例如:ps ax -f
eg1:# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
其中:VSZ 进程所使用的虚存的大小(Virtual Size);RSS表进程使用的驻留集大小或者是实际内存的大小,Kbytes字节。STAT即进程的状态:使用不通字符表示(STAT的状态码),主要15种状态码如下:
R 运行 Runnable (on run queue) //正在运行或在运行队列中等待。
S 睡眠 Sleeping //休眠中, 受阻, 在等待某个条件的形成或接受到信号。
I 空闲 Idle
Z 僵死 Zombie(a defunct process) //进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放。
D 不可中断 Uninterruptible sleep (ususally IO) //收到信号不唤醒和不可运行, 进程必须等待直到有中断发生。
T 终止 Terminate //进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行。
P //等待交换页
W 无驻留页 has no resident pages // 没有足够的记忆体分页可分配。
X //死掉的进程
< 高优先级进程 //高优先序的进程
N 低优先级进程 //低优先序的进程
L 内存锁页 Lock // 有记忆体分页分配并缩在记忆体内
s //进程的领导者(在它之下有子进程)
l //多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads)
+ //位于后台的进程组
WCHAN 表进程正在睡眠的内核函数名称;该函数的名称是从/root/system.map文件中获得的。
eg2:自定义输出结果并按需排序
ps -eo pid,stat,pri,uid –sort uid //查看当前系统进程的uid,pid,stat,pri, 以uid号排序.
ps -eo user,pid,stat,rss,args –sort rss //查看当前系统进程的user,pid,stat,rss,args, 以rss排序.
eg3:结合 watch命令实时显示进程运行情况
#watch -n 1 ‘ps -aux --sort -pmem,-pcpu’ //1s刷新一次,按cpu和内存排序
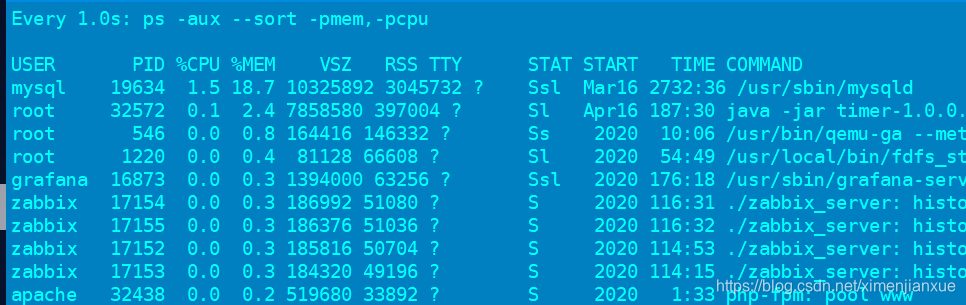
watch -n 1 ‘ps -aux --sort -pmem,-pcpu|head -10’ //动态显示前10行
11)优先级命令nice:
用法: nice <优先值> <进程名> //通过给定的优先值启动一个程序
通过以上命令用户就可以设置和改变进程的优先级。提高一个进程的优先级,内核会分配更多CPU时间片给这个进程。默认情况下,进程以 0 的优先级启动。进程优先级可以通过 top 命令显示的 NI(nice value)列查看。进程优先级值的范围从-20到19。值越低,优先级越高。
类似命令renice:
renice 命令类似 nice 命令,但它可以改变正在运行的进程优先值且用户只能改变属于他们自己的进程的优先值。
renice -n -p //改变指定进程的优先值
renice -u -g //通过指定用户和组来改变进程优先值
12)ipcs命令 :
ipcs 命令报告进程间通信设施状态。(包括共享内存,信号量和消息队列)
eg1:# ipcs -p -m //查看当前共享内存情况,-s查看信号量集合,-a等同于-msq

eg2:# ipcs -p -q //查看当前活动消息队列

b、系统安全检查
1)检查系统中是否有其他特权用户:
awk -F: ‘$3==0 {print $1}’ /etc/passwd //检查是否存在其他特权账户,默认只有root
cat /etc/passwd;stat /etc/passwd //检查是否异常用户,及用户和密码文件状态及修改的日期
awk -F: ‘length($2)==0 {print $1}’ /etc/shadow检查是否存在空口令账户.
awk -F: ‘length($2)==0 {print $1}’ /etc/shadow检查是否存在空口令账户.
last|head;lastb;w
less /var/log/secure //查看ssh的登录日志
2)ps -p PID -o lstart 检查上一次syslog启动时间是否正常
3)检查是否有以rhosts或者以forward结尾的后门文件,判断是否遭到入侵
find / -name “.rhosts” -print
find / -name “.forward” -print
ls /var/spool/cron/
less /etc/rc.d/rc.local
ls /etc/rc.d
ls /etc/rc.d
find / -type f -perm 4000
lsmod
4)检查/var/log日志是否被清理
ls -al /var/log/* //尤其wtmp和utmp
检查 sshd 服务配置文件 /etc/ssh/sshd_config 和系统认证日志 auth、message,判断是否为口令破解攻击。
/etc/ssh/sshd_config 文件确认认证方式。
确认日志是否被删除或者清理过的可能(大小判断)。
5) 查看/var/log/secure日志文件,查看是否有入侵者的信息
cat /var/log/secure | grep -i “accepted password”
检查日志报错:grep -i error或fail /var/log/messages
6) 检查守护进程
ps -ajx //所有的守护进程都是以超级用户启动的(UID为0);没有控制终端(TTY为?);终端进程组ID为-1(TPGID表示终端进程组ID,该值表示与控制终端相关的前台进程组,如果未和任何终端相关,其值为-1;

参数说明:
-a: 显示所有
-x:显示没有控制终端的进程
-j:显示与作业有关的信息(显示的列):会话期ID(SID),进程组ID(PGID),控制终端(TTY),终端进程组ID(TRGID)
7)查找隐藏进程:
ps -ef|awk ‘{print }’|sort -n|uniq>1
ls /proc/|sort -n|uniq >2
8)检查权限过开文件
find / -uid 0 -perm -4000 -print
find / -size +10000k -print //注意SUID文件,可疑大于10M和空格文件
find / -name “…” -print
find / -name " " -print
find / -name “.” -print
9)检查系统中的core文件
find / -name core -exec ls -l {} ;
10)检查系统文件完整性
rpm -qf /bin/ls
rpm -qf /bin/login
md5sum -b 关键文件名
md5sum -t 关键文件名
日常运维时,可将一些重要的文件的md5值保存,作为之后变化的参照
#!/bin/bash
export path=$PATH:/root
md5sum /etc/passwd >>/etc/md5db
md5sum /etc/shadow >>/etc/md5db
md5sum /etc/group >>/etc/md5db
md5sum /usr/bin/passwd >>/etc/md5db
md5sum /sbin/portmap>>/etc/md5db
md5sum /bin/login >>/etc/md5db
md5sum /bin/ls >>/etc/md5db
md5sum /bin/ps >>/etc/md5db
md5sum /usr/bin/top >>/etc/md5db
11)检查RPM:rpm -Va //列出当前系统中安装后,所有变化过的包文件,可以以此来检查文件包的完整性,安全性等
其中:
S – File size
M – Mode不同权限
5 – MD5 sum
D – Device number

c表示文件为配置文件。其他标志有: d %doc 说明文档;g %ghost 不应包含的文档,有可能有问题;l %license 授权文件;r %readme readme说明文件。
注意相关的 /sbin, /bin, /usr/sbin, and /usr/bin
12)检查文件的变化:
ls -Xal --time-style=+%D | grep ‘date +%D’ //只列出当前目录当天修改的文件,-X 标志来按字母顺序对结果排序,-S 标志来基于大小(由大到小)来排序
find . -maxdepth 1 -newermt “2020-09-13”
find . -maxdepth 1 -newermt “09/13/2020”
或者# find . -maxdepth 1 -newermt “2020/09/13”
13)查看网络连接
netstat -atlpv //看正在网络通讯的进程和socket连接状态

iftop //看活跃的网络通讯以及流量

抓包分析:tcpdump -w tcpdump.log //将tcpdump.log保存成 pcap 格式导入到 wireshark
tcpdump -c 10000 -i eth0 -n dst port 80 > /root/pkts
查看http的并发请求数及其TCP连接状态:
netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
查看cache里的URL
grep -r -a jpg /var/cache/* | strings | grep “http:” | awk -F’http:’ ‘{print “http:”$2;}’
查看网络负载: # sar -n DEV //检查网络流量(rxbyt/s, txbyt/s)是否过高
网络错误 # netstat -i //检查是否有网络错误(drop fifo colls carrier) 也可以用命令:# cat /proc/net/dev


14)文件被黑的常见形式:
/bin (替换基本工具为恶意木马等,比如netstat,ps等)
/sbin (替换基本工具为恶意木马等,比如sshd,lsof,ss等)
/usr/bin(替换基本工具为恶意木马等,比如sshd,lsof,ss等)
/usr/sbin (替换基本工具为恶意木马等,比如sshd,lsof,ss等)
/etc/init.d (修改开机启动任务,添加恶意脚本开机启动)
/etc/
/etc/cront.d (修改计划任务,添加恶意脚本定时执行)
/etc/crontab (修改计划任务,添加恶意脚本定时执行)
~/.ssh/目录 (注入公钥)
/etc/sysconfig (修改iptables配置等,开放网络限制)
/etc/ssh/ (修改ssh配置)
web目录 (修改网站)
需定时检查上述目录下文件被替换或者添加非法文件。
#find /usr/bin -m -1 //查看一天内/usr/bin目录下变化过的文件
#find /var -type f -mtime -1 -exec ls -al {} ;
15)杀掉进程
示例如下:
ps aux |grep p_name |grep -v grep |awk ‘{print $2}’ |xargs kill -9 (从中了解到awk的用途)
killall -TERM 服务名
kill -9 cat /usr/local/apache2/logs/httpd.pid 试试查杀进程PID
16)显示运行3级别开启的服务
ls /etc/rc3.d/S* |cut -c 15- //注意cut截取字符
17).打开文件数目 # lsof | wc -l //检查打开文件总数是否过多
c、系统启动异常处理及备份
1>Linux系统启动引到过程(BRGKi)

●开机自检:检测出第一个能够引导系统的设备,比如硬盘或者光驱。
服务器主机开机以后,将根据主板BIOS中的设置对CPU、内存、显卡、键盘等硬件设备进行初步检测,检测成功后根据预设的启动顺序移交系统控制权,大多时候会移交给本机硬盘,因为操作系统一般都是装在硬盘内。
●MBR 引导:运行放在MBR扇区里的启动GRUB引导程序。
当从本机硬盘中启动系统时,首先根据硬盘第一个扇区中MBR(主引导记录)的设置,将系统控制权传递给包含操作系统引导文件的分区;或者直接根据MBR记录中的引导信息调用启动菜单。例如:GRUB等
●GRUB 菜单:GRUB引导程序通过读取GRUB配置文件**/boot/grub2/grub.cfg**,来获取内核和镜像文件系统的设置以及路径位置。对于Linux操作系统来说,GRUB(统一启动加载器)是使用最为广泛的多系统引导器程序,系统控制权传递给GRUB以后,将会显示启动菜单给用户选择,并根据所选项(或采用默认值)加载Linux内核文件,然后将系统控制权转交给内核。(CentOS 7采用的是GRUB2启动引导器)
●加载Linux内核:把内核和镜像文件系统加载到内存中。
Linux内核是一个预先编译好的特殊二进制文件,介于各自硬件资源与系统程序之间,复制资源分配与调度,内核接过系统控制权以后,将完全掌控整个Linux操作系统的运行过程。(CentOS 7系统中,默认的内核文件位于“/boot/vmlinuz-3.10.0-514.e17.x86_64”)
●init 进程初始化:加载硬件驱动程序,内核把init进程加载到内存中运行。
为了完成进一步的系统引导过程,Linux内核首先将系统中的“/sbin/init”程序加载到内存中运行(运行中的程序称为进程),init进程(systemd)负责完成整个系统的初始化,最后等待用户进行登录。
2> 为避免因引导扇区的损坏或丢失导致系统无法启动,需提前备份MBR扇区信息
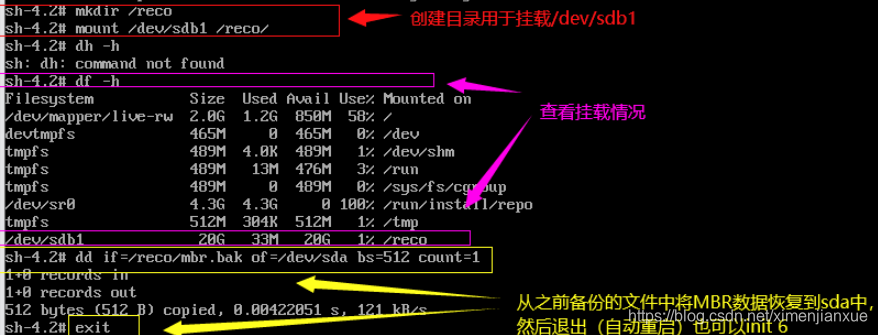
MBR位于第一块硬盘的第一个物理扇区处,总共512字节;故我们可使用dd命令将MBR所在硬盘的第一个512字节的块保存即可,假设MBR在sda(第一块硬盘上),创建的备份目录为sdb上的/mbrbak/,执行命令:

可执行以下命令模式损坏MBR块区:

恢复时,重启系统,使用救援模式,用dd命令将MBR备份写回系统MBR第一个扇区即可:
3>Grub引到程序异常导致的系统启动失败
比如:MBR中的GRUB引导程序(1-446字节)遭到破坏;或grub.cfg文件丢失,引导配置有误,文件位置/boot/grub2/grup.cfg。
故障现象:系统引导卡死到grub >提示符,无法继续进入
解决思路:
1.尝试手动输入引导命令修复(不推荐)
grub> insmod xfs
grub> linux16 /vmlinuz-0-rescue-73d7ede256a74b0e975e69f22d862090 root=UUID=d069b243-6623-4983-8d61-3ec6956a4f2b ro rhgb quiet
grub> initrd16 /initramfs-0-rescue-73d7ede256a74b0e975e69f22d862090.img
grub> boot
2.进入急救模式,重写或者从备份中恢复grub.cfg
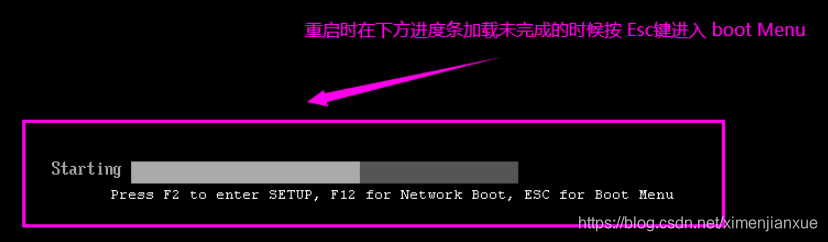
然后挂载系统CD盘,从CD盘恢复GRUB数据。

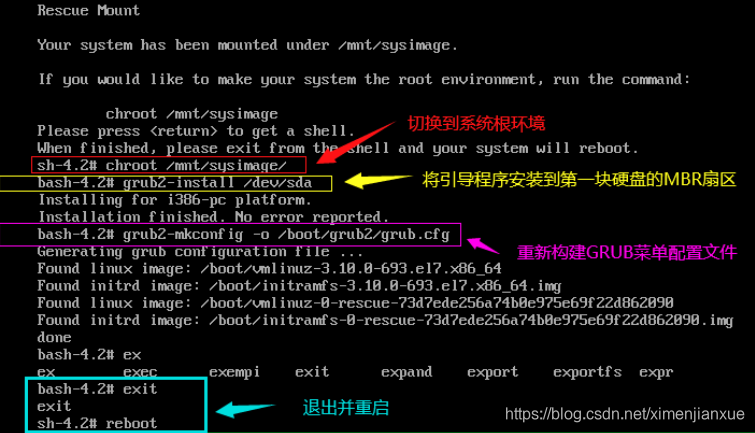
3.急救模式向MBR扇区中重建grub程序
MBR位于第一块硬盘( /dev/sda)的第一个物理扇区处,总共512字节, 前446字节是主引导记录,分区表保存在MBR扇区中的第447-510字节中。修复方法跟MBR基本一致,只是备份的数据只需要446字节就可以,将bs=512修改为bs=446即可。过程如下:
a、创建新目录用以挂载备份磁盘,备份GRUB引导程序
#mkdir /bak
#mount /dev/sdb1 /bak/
#dd if=/dev/sda of=/bak/grup.bak bs=446 count=1
b、模拟对MBR中的GRUB引导程序的破坏,但不破坏分区表
#dd if=/dev/zero of=/dev/sda bs=446 count=1
c、引导界面进入急救模式,从备份文件中恢复GRUB引导程序
sh-4.2# mkdir /backupdir
sh-4.2# mount /dev/sdb1 /backupdir
sh-4.2# dd if=backupdir/grup.bak of=/dev/sda bs=446 count=1
sh-4.2# exit
附录:系统启动时服务自启动管理工具ntsysv
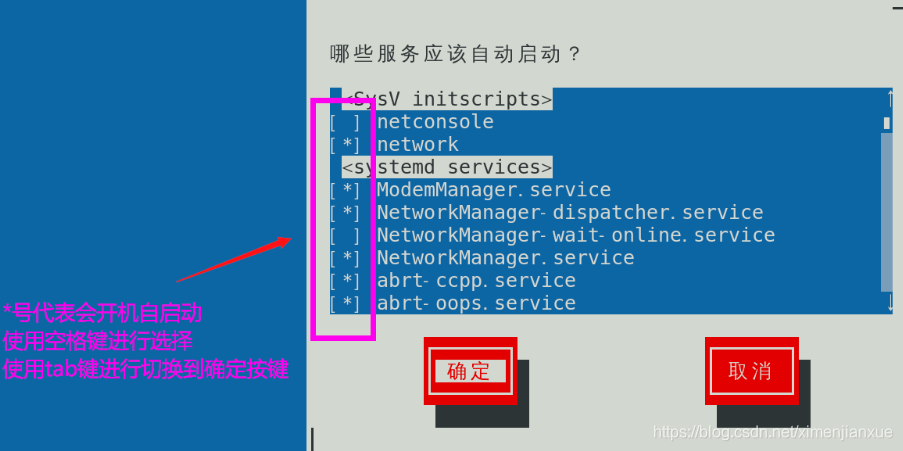
ntsysv命令提供了一个基于文本界面的菜单操作方式,集中管理系统不同的运行等级下的系统服务启动状态。在RedHat各个发行版,CentOS各个版本,都自带这个工具。它具有互动式操作界面,您可以轻易地利用方向键和空格键等,开启,关闭操作系统在每个执行等级中,所要执行的系统服务。
输入ntsysv命令后,出现一个交互式的管理菜单,如下:
备份
dump -0aj -f /tmp/home0.bak /home 制作一个 ‘/home’ 目录的完整备份
dump -1aj -f /tmp/home0.bak /home 制作一个 ‘/home’ 目录的交互式备份
restore -if /tmp/home0.bak 还原一个交互式备份
rsync -rogpav --delete /home /tmp 同步两边的目录
rsync -rogpav -e ssh --delete /home ip_address:/tmp 通过SSH通道rsync
rsync -az -e ssh --delete ip_addr:/home/public /home/local 通过ssh和压缩将一个远程目录同步到本地目录
rsync -az -e ssh --delete /home/local ip_addr:/home/public 通过ssh和压缩将本地目录同步到远程目录
dd bs=1M if=/dev/hda | gzip | ssh user@ip_addr ‘dd of=hda.gz’ 通过ssh在远程主机上执行一次备份本地磁盘的操作
dd if=/dev/sda of=/tmp/file1 备份磁盘内容到一个文件
tar -Puf backup.tar /home/user 执行一次对 ‘/home/user’ 目录的交互式备份操作
( cd /tmp/local/ && tar c . ) | ssh -C user@ip_addr ‘cd /home/share/ && tar x -p’ 通过ssh在远程目录中复制一个目录内容
( tar c /home ) | ssh -C user@ip_addr ‘cd /home/backup-home && tar x -p’ 通过ssh在远程目录中复制一个本地目录
tar cf - . | (cd /tmp/backup ; tar xf - ) 本地将一个目录复制到另一个地方,保留原有权限及链接
find /home/user1 -name ‘.txt’ | xargs cp -av --target-directory=/home/backup/ --parents 从一个目录查找并复制所有以 ‘.txt’ 结尾的文件到另一个目录
find /var/log -name '.log’ | tar cv --files-from=- | bzip2 > log.tar.bz2 查找所有以 ‘.log’ 结尾的文件并做成一个bzip包
dd if=/dev/hda of=/dev/fd0 bs=512 count=1 做一个将 MBR (Master Boot Record)内容复制到软盘的动作
dd if=/dev/fd0 of=/dev/hda bs=512 count=1 从已经保存到软盘的备份中恢复MBR内容
15、Linux运维工具及技巧
1)15 个超赞的 Linux 工具
A、比grep、ack更快的递归搜索文件内容工具ag :
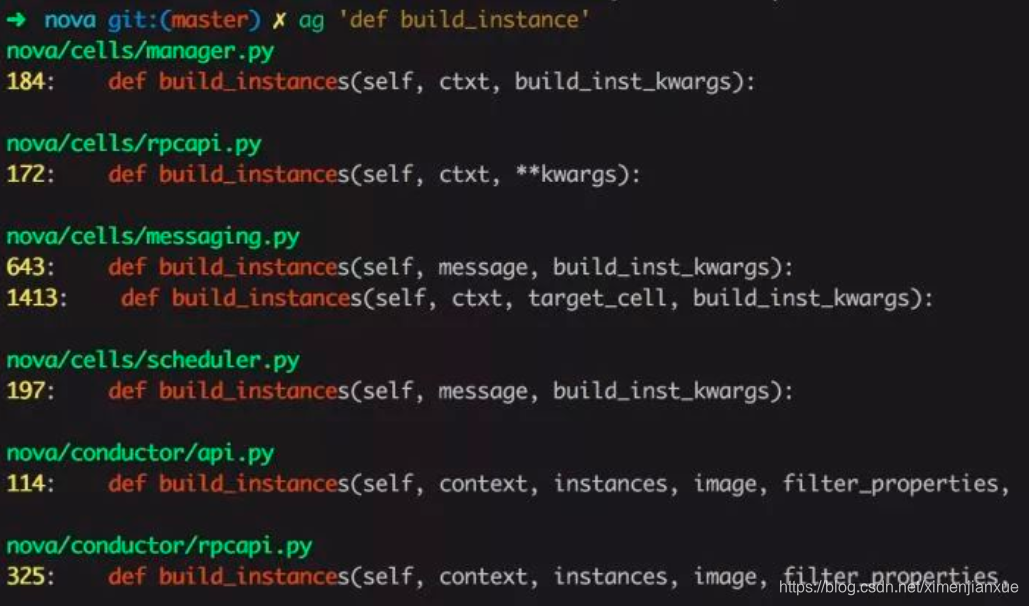
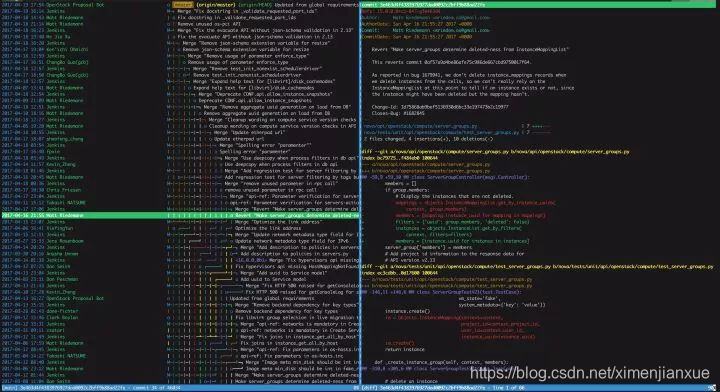
B、tig 命令:字符模式下交互查看git项目,可以替代git命令。
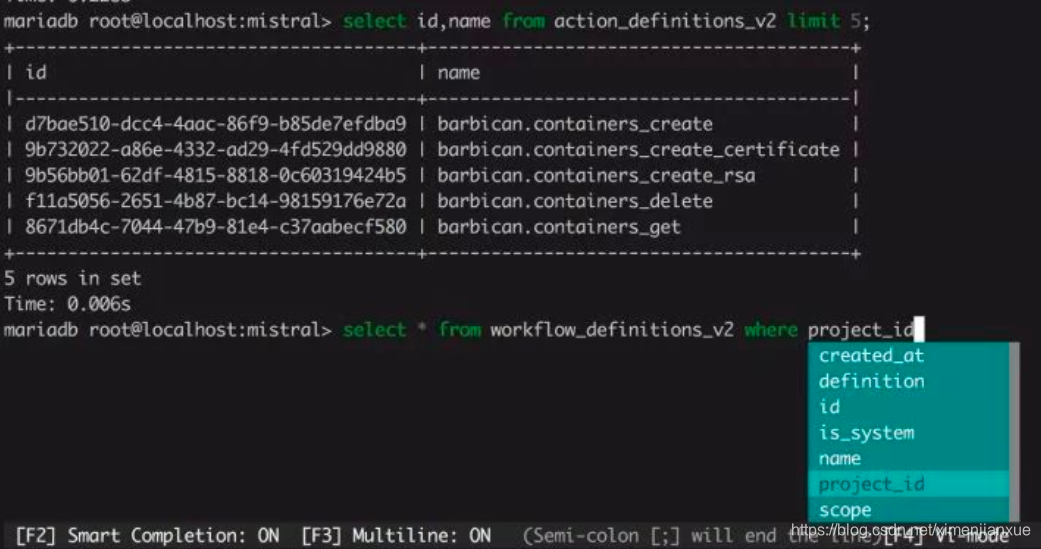
C、mycli :mysql客户端,支持语法高亮和命令补全,效果类似ipython,可以替代mysql命令。
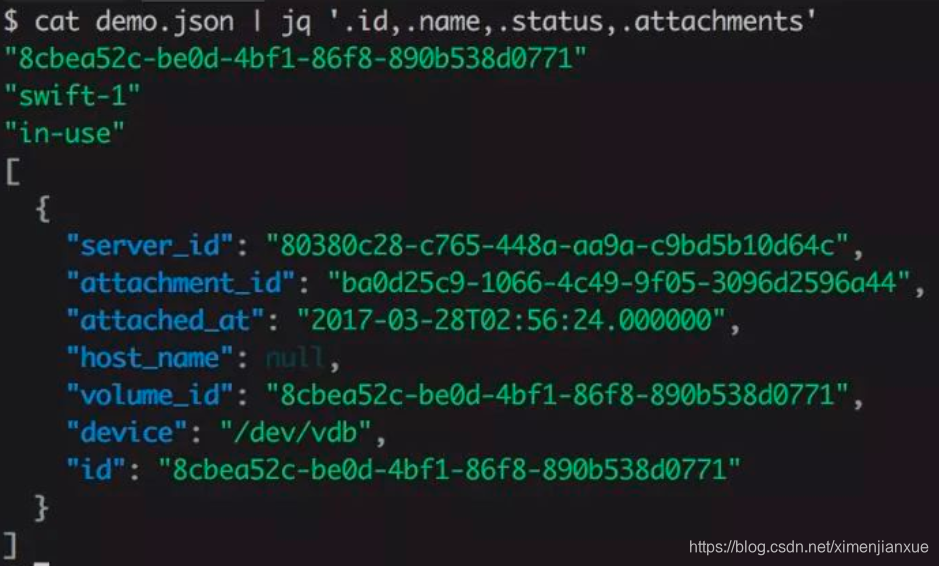
D、jq : json文件处理以及格式化显示,支持高亮,可以替换python -m json.tool。
E、shellcheck : shell脚本静态检查工具,能够识别语法错误以及不规范的写法。
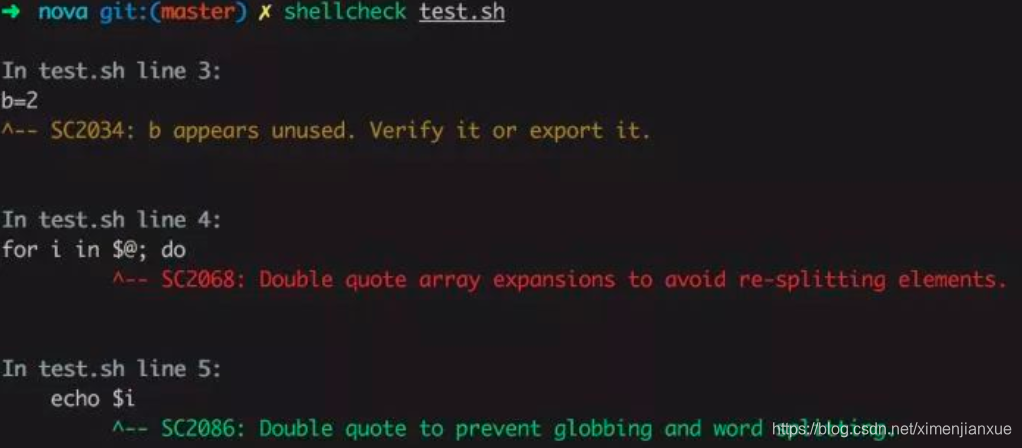
F、、fzf :命令行下模糊搜索工具,能够交互式智能搜索并选取文件或者内容,配合终端ctrl-r历史命令搜索简直完美。

G、PathPicker(fpp) : 在命令行输出中自动识别目录和文件,支持交互式,配合git非常有用。
eg1:git diff HEAD~8 --stat | fpp
H、htop : 提供更美观、更方便的进程监控工具,替代top命令。而glances :更强大的 htop / top 代替者。
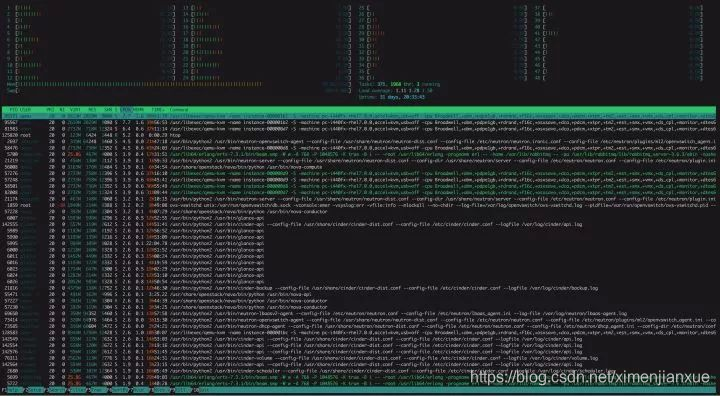
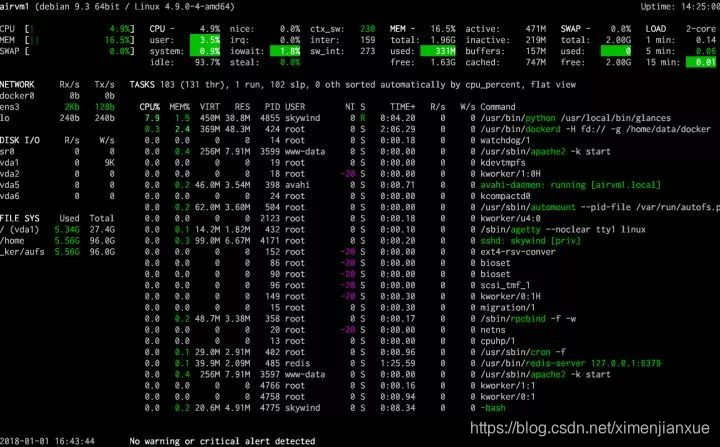
下图为glances的:
I、axel : 多线程下载工具,下载文件时可以替代curl、wget。
eg:axel -n 20 http://centos.ustc.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1511.iso
J、sz/rz : 交互式文件传输,在多重跳板机下传输文件非常好用,不用一级一级传输。
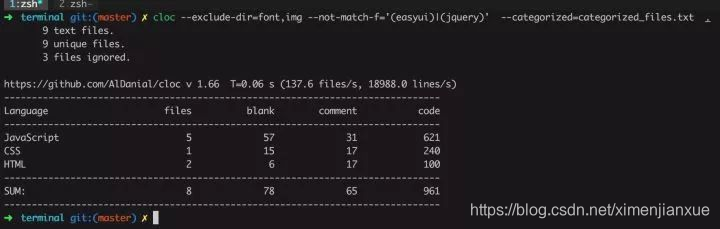
K、cloc :代码统计工具,能够统计代码的空行数、注释行、编程语言。
L、tmux :终端复用工具,替代screen、nohup。
M、script/scriptreplay : 终端会话录制。
eg1:录制
script -t 2>time.txt session.typescript 执行后开始录制,下面你执行的所有操作都可被记录
#your commands
#录制结束
exit
#回放:scriptreplay -t time.txt session.typescript
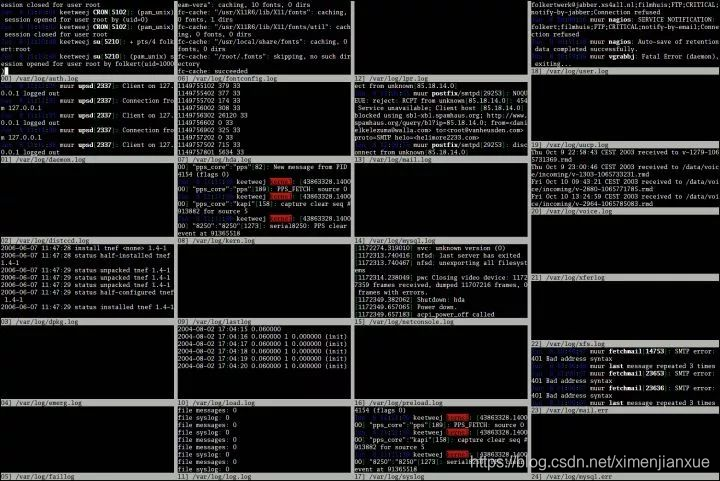
N、multitail :多重 tail。
通常你不止一个日志文件要监控,怎么办? 终端软件里开多个 tab 太占地方,可以试试这个工具:



















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











