




瑞吉外卖项目总结
文章目录
前言
这周跟着黑马程序员做了一个外卖项目,本文主要对该项目用到的一些技术进行总结概况,该项目主要用到的技术有SpringBoot、Mysql、Mybatis、MybatisPlus、Redis、SpringCache、Sharding-JDBC等。
项目官方视频地址:https://www.bilibili.com/video/BV13a411q753?p=4&vd_source=21559f9b93a639dc9b0307c824e79817
我的项目代码地址:https://gitee.com/xin-77/ruiji-takeout-project.git
Mysql数据库设计
该项目总共有十一个表,分别为地址表、菜品表、订单表、口味表、套餐表、员工表、套餐菜品表、购物车表、订单详情表、分类表、用户表。各个表之间不设置外键,一切外键概念都在应用层解决。外键会影响数据库 的插入速度。

MybatisPlus
该项目主要使用了MybatisPlus来进行对持久层操作,MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
项目中使用MybatisPlus完成对简单的增删改查代码简化,我们只需要继承BaseMapper类即可使用MybatisPlus为我们封装好的增删改查方法。
public interface BaseMapper<T> extends Mapper<T> {
// 插入数据
int insert(T entity);
// 根据id删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param("cm") Map<String, Object> columnMap);
// 根据 entity 条件,删除记录
int delete(@Param("ew") Wrapper<T> queryWrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
// 根据 ID 修改
int updateById(@Param("et") T entity);
// 根据 whereWrapper 条件,更新记录
int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
<E extends IPage<T>> E selectPage(E page, @Param("ew") Wrapper<T> queryWrapper);
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param("ew") Wrapper<T> queryWrapper);
}
再配合mybatisplus为我们提供的条件构造器可以实现大部分对数据库的操作,涉及多个表的操作我们可以在Service层解决,例如如下代码
@Override
@Transactional
public void saveWithDish(SetmealDto setmealDto) {
// 保存套餐的基本信息,操作setmeal,执行insert操作
this.save(setmealDto);
List<SetmealDish> setmealDishes = setmealDto.getSetmealDishes();
List<SetmealDish> dishes = setmealDishes.stream().map((item) -> {
item.setSetmealId(setmealDto.getId());
return item;
}).collect(Collectors.toList());
// 保存套餐和菜品的关联信息,操作setmeal_dish, 执行insert操作
setmealDishService.saveBatch(dishes);
}
上述方法主要是用于添加套餐信息,需要同时操作setmeal表和操作setmeal_dish表时需要在Service层解决,并且涉及多表操作需要加上@Transactional来开启事务。
Redis
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
该项目使用了redis来进行缓存,对用户经常查询的菜品信息等进行缓存,减小了频繁的查询对mysql数据库的压力。
在使用Redis时需要自己重新定义一个 RedisTemplete来配置相关的数据序列化方法。
通过Springboot的redis自动配置类RedisAutoConfiguration我们可以看到如果我们不定义的RedisTemplete会自动帮我们注入下面这个默认的RedisTemplate,默认的Key序列化器为:JdkSerializationRedisSerializer,JdkSerializationRedisSerializer: 使用JDK提供的序列化功能。
优点是反序列化时不需要提供类型信息(class),但缺点是需要实现Serializable接口,还有序列化后的结果非常庞大,是JSON格式的5倍左右,这样就会消耗redis服务器的大量内存,可视化工具查看乱码。
@Bean
@ConditionalOnMissingBean(
name = {"redisTemplate"}
)
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
我们自己定义其它的序列号器
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class));
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
StringRedisSerializer只能存储类型为String的value,当存储其他类型的数据,如double,则无法将value保存到redis,必须转为String。
Jackson2JsonRedisSerializer: 使用Jackson库将对象序列化为JSON字符串。
优点是速度快,序列化后的字符串短小精悍,不需要实现Serializable接口。
但缺点也非常致命,那就是此类的构造函数中有一个类型参数,必须提供要序列化对象的类型信息(.class对象)。
直接使用redis进行缓存时需要改造代码相对繁琐,可以使用Spring Cache通过注解来实现缓存。
Spring Cache
Spring Cache介绍
Spring cache是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
Spring Cache提供了一层抽象,底层可以切换不同的cache实现。具体就是通过CacheManager接口来统一不同的缓存技术。
Cache Manager是Spring提供的各种缓存技术抽象接口。
针对不同的缓存技术需要实现不同的Cache Manager:
| Cache Manager | 描述 |
|---|---|
| EhCacheCacheManager | 使用EhCache作为缓存技术 |
| GuavaCacheManager | 使用Google的GuavaCache作为缓存技术 |
| RedisCacheManager | 使用Redis作为缓存技术 |
Spring Cache常用注解
| 注解 | 说明 |
|---|---|
| @EnableCaching | 开启缓存注解功能 |
| @Cacheable | 在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中 |
| @CachePut | 将方法的返回值放到缓存中 |
| @CacheEvict | 将一条或多条数据从缓存中删除 |
Spring Cache参数说明
| 参数 | 说明 |
|---|---|
| value | 缓存的名称,每个缓存名称下面可以有多个key |
| key | 缓存的key |
| condition | 条件,满足条件时才缓存 |
| unless | 满足条件时不缓存 |
| allEntries | 表示是否删除所有缓存数据,默认为false |
在spring boot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。
例如,使用Redis作为缓存技术,只需要导入Spring data Redis的maven坐标即可。
Spring Cache使用方式
在Spring Boot项目中使用Spring Cache的操作步骤(使用redis缓存技术);
1、导入maven坐标
- spring-boot-starter-data-redis、spring-boot-starter-cache
2、配置application.yml
spring:
cache:
redis:
time-to-live: 1800000#设置缓存有效期
3、在启动类上加入@EnableCaching注解,开启缓存注解功能
4、在Controller的方法上加入@Cacheable、@CacheEvict等注解,进行缓存操作
项目中相关代码实现如下:
/**
* 查询套餐列表,如果有缓存直接从redis获取,没有缓存则查询数据库并添加缓存
* @param setmeal
* @return
*/
@GetMapping("/list")
@Cacheable(value = "setmealCache", key = "#setmeal.categoryId + '_' + #setmeal.status")
public R<List<Setmeal>> list(Setmeal setmeal){
LambdaQueryWrapper<Setmeal> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(setmeal.getCategoryId() != null, Setmeal::getCategoryId, setmeal.getCategoryId());
wrapper.eq(setmeal.getStatus() != null, Setmeal::getStatus, setmeal.getStatus());
wrapper.orderByDesc(Setmeal::getUpdateTime);
List<Setmeal> list = setmealService.list(wrapper);
return R.success(list);
}
/**
* 新增套餐信息,在新增套餐时删除套餐相关缓存。
* @param setmealDto
* @return
*/
@PostMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> save(@RequestBody SetmealDto setmealDto){
log.info("套餐信息{}", setmealDto);
setmealService.saveWithDish(setmealDto);
return R.success("新增套餐成功!");
}
Mysql主从复制
介绍
MySQL主从复制是一个异步的复制过程,底层是基于Nysql数据库自带的二进制日志功能。就是一台或多台MysQL数据库(slave,即从库)从另一台MysQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。


MySQL复制过程分成三步:
- master将改变记录到二进制日志(binary log)
- slave将master的binary log拷贝到它的中继日志( relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中
在这里我使用的是docker来运行多个mysql实现主从复制
# 查询mysql镜像
docker search mysql
# 拉取mysql:5.7镜像
docker pull mysql:5.7
# 新建+启动mysql容器,挂载mysql的日志、数据、配置文件
# 主库端口映射为3306
docker run -d -p 3306:3306 --privileged=true -v /xinuse/mysql/log:/var/log/mysql -v /xinuse/mysql/data:/var/lib/mysql -v /xinuse/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:5.7
# 从库端口映射为3307
docker run -d -p 3307:3306 --privileged=true -v /xinuse/mysql2/log:/var/log/mysql -v /xinuse/mysql2/data:/var/lib/mysql -v /xinuse/mysql2/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql2 mysql:5.7
从库配置
# 从库配置文件在镜像挂载的/xinuse/mysql2/conf里面新建
vim my.cnf
# 输入以下内容
# 设置编码和id
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
server-id=101
主库配置
# 从库配置文件在镜像挂载的/xinuse/mysql/conf里面新建
vim my.cnf
# 输入以下内容
# 设置编码和id
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
log-bin=mysql-bin #启用二进制日志
server-id=100 #服务器唯一ID
# 在主库新建用户
GRANT REPLICATION SLAVE ON *.*TO'xiaoming'@'%' IDENTIFIED BY 'ROOT@123456';
# 在从库配置
CHANGE master to
master_host='192.168.189.100',master_user='xiaoming', master_password='ROOT@123456',master_log_file='mysql-bin.000001',master_log_pos=439;
start slave;
# 查看从库状态
show slave status;
读写分离
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
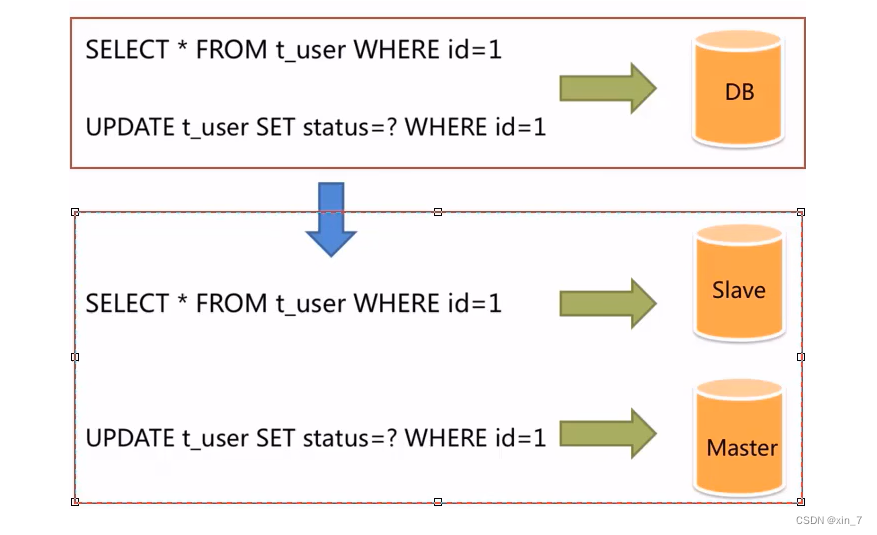
Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate,Mybatis, Spring JDBC Template或直接使用
- JDBC。支持任何第三方的数据库连接池,如:DBCP,C3P0, BoneCP, Druid,HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,sQLServer,PostgresQL以及任何遵循SQL92标准的数据库。
使用Sharding-JDBC实现读写分离步骤:
1、导入maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2、在配置文件中配置读写分离规则
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.189.100:3306/reggie?characterEncoding=utf-8
username: root
password: 123456
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.189.100:3307/reggie?characterEncoding=utf-8
username: root
password: 123456
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
3、在配置文件中配置允许bean定义覆盖配置项
main:
# 声明spring框架是否允许定义重名的bean对象覆盖原有的bean (spring boot默认是false)
allow-bean-definition-overriding: true
总结
以上就是今天要讲的内容,本文总结了瑞吉外卖项目用到的一些技术,瑞吉外卖项目以当前热门的外卖点餐为业务基础,业务真实、实用、广泛。基于流行的Spring Boot、mybatis plus等技术框架进行开发,通过该项目可以锻炼需求分析能力、编码能力、bug调试能力,增长开发经验。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









