









作者:白松 西工大研究生。转载请注明出处:http://blog.csdn.net/xin_jmail/article/details/32101483。
本文参加了2014年CSDN博文大赛,如果您觉得此文对您有所帮助,就请为我投上您宝贵的一票,不胜感激。投票地址:http://vote.blog.csdn.net/Article/Details?articleid=32101483 。
本文目的:讲解并行Finding a Maximal Independent Set(寻找最大独立集问题)算法,以及在Hama平台上如何实现该算法。该算法可方便移植到所有的Pregel-Like系统中,如Giraph、GPS (Graph Processing System)。
前言:关于Maximal Independent Set(MIS)的基础知识参考我的博客《找最大独立集问题-Finding a Maximal Independent Set》。
1. 本算法参考 Luby's classic parallel algorithm《a simple parallel algorithm for maximal independent set problem》,把顶点分为三类:
1) S:The MIS being constructed. Starts empty and grows in iterations.
2) NotInS: Vertices that have at least one edge to a vertex in S and as a result cannot be in S.
3) Unknown: Vertices that do not have an edge to any vertex in S but are not yet in S.
2. Hama平台下 MIS算法描述。
初始时,所有顶点都在UnKnown集合中。算法如下:
1) UnKnown集合中的每个顶点向邻接顶点发送自己的VertexID。
2) 若顶点u的VertexID比自己所有邻接顶点都小,则该顶点进入 S 集合中,并发送neighbor-in-set 消息给所有 邻接顶点,通知它们退出Unknown集合进入到NotInS集合中,并最后把u置为InActive状态;否则,顶点u继 续保持UnKnown状态。
3) S集合中顶点的邻接顶点收到neighbor-in-set 消息,则该顶点进入NotInS,并且 become Inactive。回到步骤 1继续迭代,直到UnKnown集合为空。
算法分析:上述每个步骤都是一个SuperStep,步骤间需要一次全局同步。步骤3是收到neighbor-in-set 消息的UnKnown顶点进入NotInS集合中,而未进入NotInS集合的UnKnown顶点在下一轮迭代的步骤1向邻接顶点发送自己的VertexID。两者互不影响,因此从可以把步骤3和步骤1合并,以此来减少全局同步次数。
3. 算法实现和源码。程序中按照顶点value取值不同来区分顶点的类别,关系如下:
1) value 等于 vertexID ,表示顶点在 Unknown 集合中;
2) value 等于 -1 ,表示顶点在 S 集合中
3) value 等于 -2 ,表示顶点在 NotInS 集合中。
当所有顶点进入S或者NotInS集合中(即没有 Unknown 顶点),就停止计算,表明已找到一个 MIS。源码如下:
package graph.mis;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hama.HamaConfiguration;
import org.apache.hama.bsp.HashPartitioner;
import org.apache.hama.bsp.TextInputFormat;
import org.apache.hama.bsp.TextOutputFormat;
import org.apache.hama.graph.Edge;
import org.apache.hama.graph.GraphJob;
import org.apache.hama.graph.Vertex;
import org.apache.hama.graph.VertexInputReader;
/**
* 目的:找到一个MIS。
*
* 方法:使用Luby's classic parallel algorithm,该算法把顶点分为三类:
* 1) S:The MIS being constructed. Starts empty and grows in iterations.
* 2) NotInS: Vertices that have at least one edge to a vertex in S and as
* a result cannot be in S.
* 3) Unknown: Vertices that do not have an edge to any vertex in S
* but are not yet in S.
*
* 说明:程序中按照顶点value取值不同来区分顶点的类别,关系如下:
* 1) value 等于 vertexID ,表示顶点在 Unknown 集合中;
* 2) value 等于 -1 ,表示顶点在 S 集合中
* 3) value 等于 -2 ,表示顶点在 NotInS 集合中。
* 当所有顶点进入S或者NotInS集合中(即没有 Unknown 顶点),就停止计算,表明已找到一个 MIS。
*
*
* @author 西工大-白松 (HamaWhite的博客)。2014-6-18
*
*/
public class FindMIS {
/**
* VertexID设置为LongWritable是为处理上百亿的顶点.
*/
public static class MISVertex extends
Vertex<LongWritable, NullWritable, LongWritable> {
@Override
public void compute(Iterator<LongWritable> messages) throws IOException {
if (getSuperstepCount() == 0) {
//初始第0个超步,把所有顶点的value值赋值为自己的vertexID,
//表明初始所有顶点均在 UnKnown 集合中。
setValue(getVertexID());
//把自己的VertexID发送给邻接顶点
sendMessageToNeighbors(getValue());
} else {
/**
* 若 NotInS 集合中,则voteToHalt。
* 解释:若NotInS集合中的某个顶点u的邻接顶点v在 Unknown集合中,则v会向u发送消息.
* 这样u就会接到消息,被系统自动激活进入Active状态。若此处不做处理将会导致一直
* 有活跃顶点,迭代就不会停止。
*/
if(getValue().get()==-2) {
voteToHalt();
} else {
/**
* recMsg用来表示顶点是否收到消息。该算法中存在两种消息:
* (1) UnKnown集合中的顶点向邻接顶点发送,寻找顶点进入 S 中。
* (2) S集合中的顶点向邻接顶点发送,通知邻接顶点进入 NotInS 集合中。
*
* 若某个顶点没收到消息,说明该顶点是在 UnKnown集合中,需要向外发送消息寻找。
*/
boolean revMsg = false; //标记是否收到消息
while (messages.hasNext()) {
revMsg = true;
long msg = messages.next().get();
if (msg == -2) {
//收到消息-2,表示该顶点的某个邻接顶点已进入 S 集合,
//该顶点需要进入 NotInS集合中,并且voteToHalt
setValue(new LongWritable(-2));
voteToHalt();
return;
} else if (msg < getValue().get()) {
//若收到的vertexID比自己大,说明该顶点不能进入 S
//继续保持 UnKnown状态,参与下次迭代。
return;
}
}
if (revMsg) {
//说明自身vertexID比所有邻接顶点都小,则进入 S 集合中。
setValue(new LongWritable(-1)); //进入 S 集合中
//用消息-2 通知自己的邻接顶点进入 NotInS 集合中
sendMessageToNeighbors(new LongWritable(-2));
voteToHalt(); //置为 InActive,不参与后续计算
} else {
// UnKnown集合中的顶点,向外发送消息寻找顶点进入S中。
sendMessageToNeighbors(getValue());
}
}
}
}
}
/**
* 解析输入格式,以\t间隔的邻接表形式,每行表示一个顶点.如:
* 1\t2\t3
* 2\t1
* 3\t2
* @author root
*
*/
public static class MISTextReader extends
VertexInputReader<LongWritable, Text, LongWritable, NullWritable, LongWritable> {
@Override
public boolean parseVertex(LongWritable key, Text value,
Vertex<LongWritable, NullWritable, LongWritable> vertex)
throws Exception {
String[] split = value.toString().split("\t");
for (int i = 0; i < split.length; i++) {
if (i == 0) {
vertex.setVertexID(new LongWritable(Long.parseLong(split[i])));
} else {
vertex.addEdge(new Edge<LongWritable, NullWritable>(
new LongWritable(Long.parseLong(split[i])), null));
}
}
return true;
}
}
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
if (args.length < 2) {
System.err.println("Usage: <input> <output>");
System.exit(-1);
}
HamaConfiguration conf = new HamaConfiguration(new Configuration());
GraphJob pageJob = new GraphJob(conf, FindMIS.class);
pageJob.setJobName("Find a MIS");
pageJob.setMaxIteration(30);
pageJob.setVertexClass(MISVertex.class);
pageJob.setInputPath(new Path(args[0]));
pageJob.setOutputPath(new Path(args[1]));
pageJob.setVertexIDClass(LongWritable.class);
pageJob.setVertexValueClass(LongWritable.class);
pageJob.setEdgeValueClass(NullWritable.class);
pageJob.setInputKeyClass(LongWritable.class);
pageJob.setInputValueClass(Text.class);
pageJob.setInputFormat(TextInputFormat.class);
pageJob.setVertexInputReaderClass(MISTextReader.class);
pageJob.setPartitioner(HashPartitioner.class);
pageJob.setOutputFormat(TextOutputFormat.class);
pageJob.setOutputKeyClass(Text.class);
pageJob.setOutputValueClass(LongWritable.class);
pageJob.waitForCompletion(true);
}
}
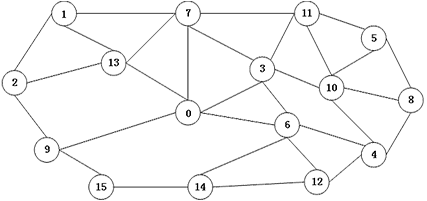
下面分析S集合中的顶点用红色标注,NotInS集合用灰色,UnKnown集合用白色标注。S集合和NotInS集合中的顶点均是InActive状态,UnKnown集合中的顶点是Active状态。
(1) 步骤1:在SuperStep 0,每个顶点把自己的VertexID发送给邻接顶点,,如顶点1发送消息1到顶点2、13、7;顶点2发送消息2到顶点1、9、13;顶点15发送消息15到顶点9和14。其他顶点类似。
(2)步骤2:在SuperStep 1,每个顶点收到邻接顶点发送的消息,如顶点1收到消息2、13、7,;顶点2收到消息1、13、9;顶点0收到消息3、6、7、9、13。只有顶点0、1、4、5比邻接顶点都小,故该四个顶点进入S 集合,用红色标注。其他顶点继续在UnKnown集合中。
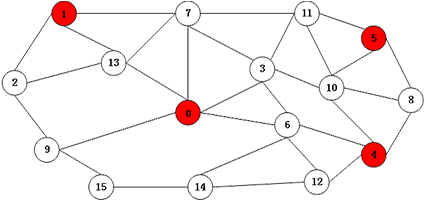
(3).步骤3和步骤1(步骤1属于第二轮), 在SuperStep2中,顶点0、1、4、5的邻接顶点收到neighbor-in-set 消息(源码中用-2表示)进入NotInS集合中,即顶点2、13、7、3、10、6、8、11、12、9共10个顶点进入NotInS集合中,变为InActive状态。同时顶点14和15依然是UnKnown状态,14和15分别向邻接顶点发送消息,顶点14向6、12、15发送消息(15);顶点15向9、14发送消息。
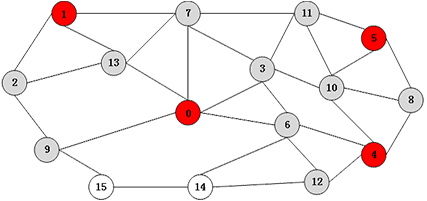
(4) .步骤2(第二轮):在SuperStep 3中,NotInS集合中的顶点6、9和12收到消息后被系统自动激活变为Active状态,所以程序中对此情况有所处理,把顶点6、9、12直接置为Inactive状态,不做后续处理。顶点14收到消息15比自身大,则14进入S集合中,而顶点15则相反继续在UnKnown集合中。顶点14向邻接顶点6、12、15发送neighbor-in-set消息。
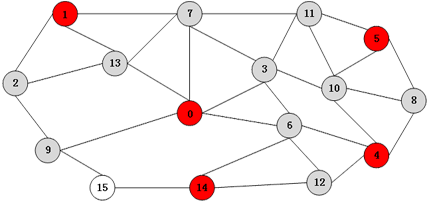
(5) 步骤3(第二轮):在SuperStep 4中,顶点6和顶点12同(4)步处理相同。顶点15收到neighbor-in-set 消息后进入 NotInS集合中。由于UnKnown集合中已没有顶点,不会再向外发送消息。

(6) SuperStep 5中,发现已没有活跃顶点且没有消息在传递,故结束计算。
5. 实验结果。运行结果如下:
HDFS的输出结果如下(-2表示NotInS,-1表示在S集合中):
8 -2
10 -2
12 -2
14 -1
0 -1
2 -2
4 -1
6 -2
9 -2
11 -2
13 -2
15 -2
1 -1
3 -2
5 -1
7 -2
本文参加了2014年CSDN博文大赛,如果您觉得此文对您有所帮助,就请为我投上您宝贵的一票,不胜感激。投票地址:http://vote.blog.csdn.net/Article/Details?articleid=32101483 。
完!















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









