







目标检测分解
- 确定目标位置
- 判断检测目标类别
前置知识
什么是图像卷积
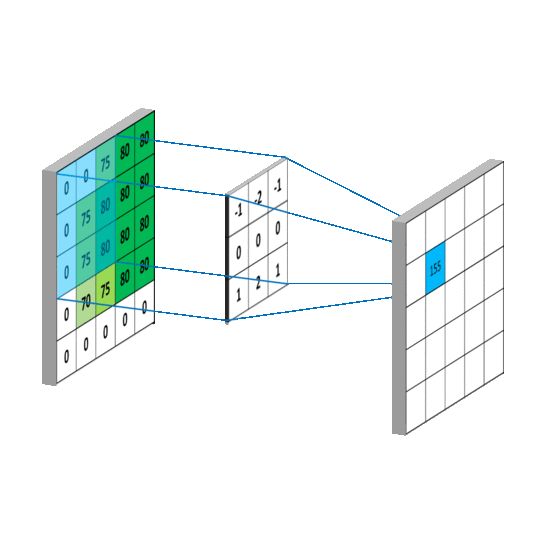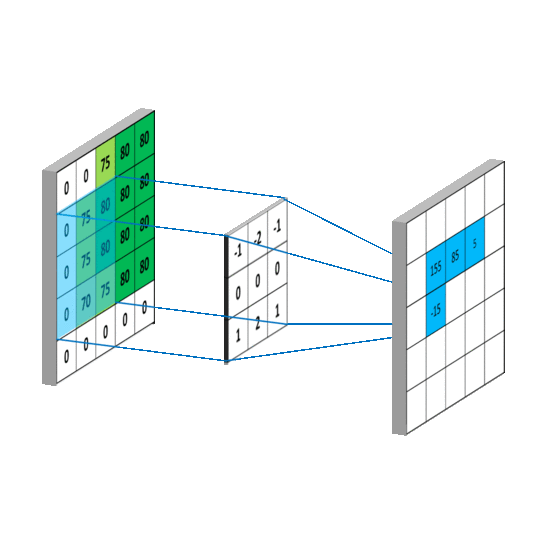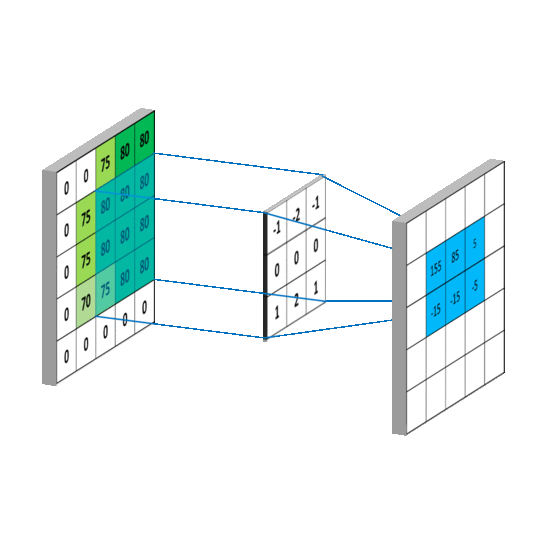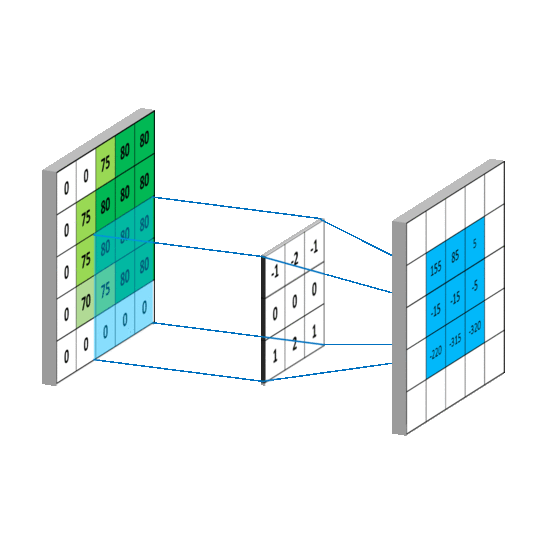
卷积有啥作用捏
就是提取图像纹理(细节)
训练网络原理是什么
训练网络就和教小孩做数学题一样,做对了给糖做错了给巴掌。慢慢这个孩子也就会做题了。所以训练神经网络也会有相应的奖惩措施,也就是损失函数。
什么是过拟合
就相当于你就让孩子做一道题,做了一万遍(同一样本训练次数过多),到后来孩子把答案背下来了。再换个数给他做,他还是会做错!所以深度学习最主要就是大样本。就可以类比为题海战术,这样就可以尽量避免过拟合。
什么是欠拟合
就是题做少了,基础不好,网络准确率也不会很高

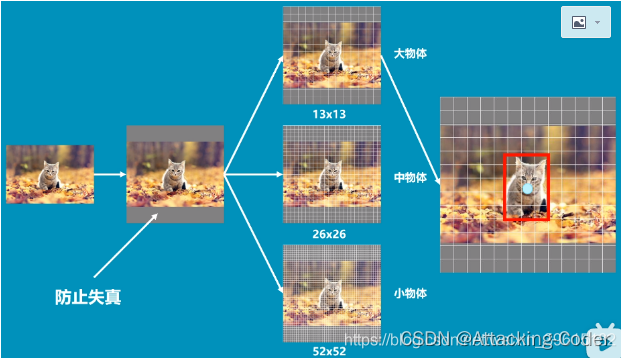
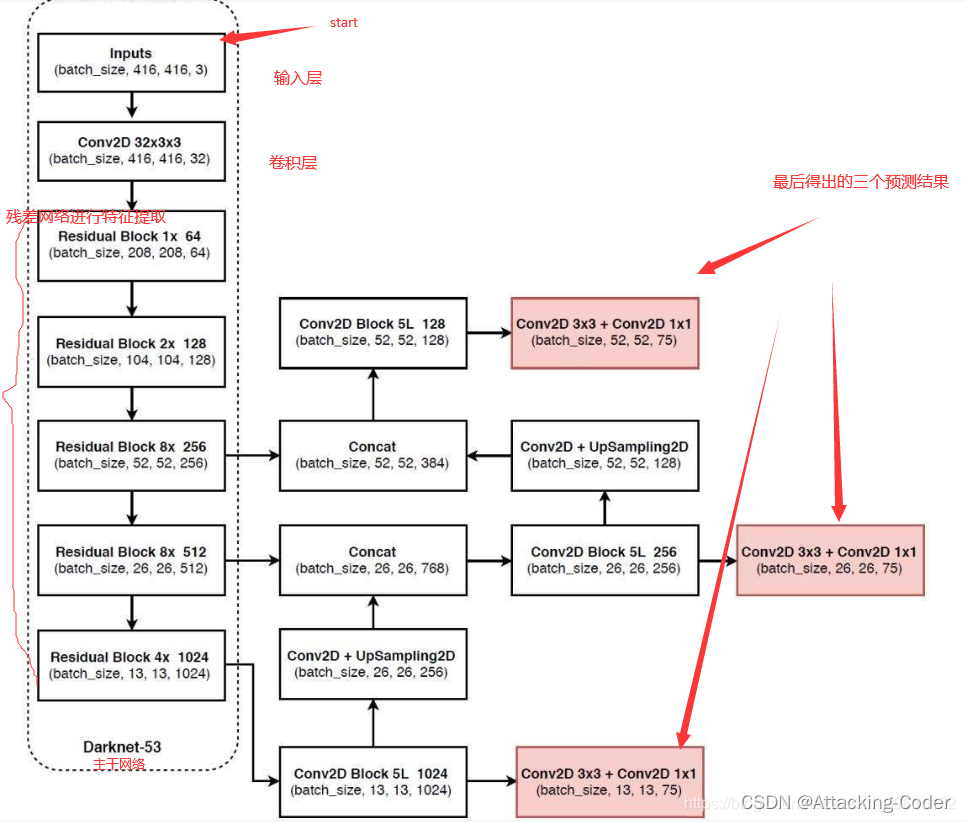
该图是基于voc数据集讲解的,voc数据集有20个类别,最下面红框中(13,13,75)表示预测结果的shape,实际上是13,13,3×25,表示有13*13的网格,每个网格有3个先验框,每个先验框有25个参数(20个类别+5个参数),这5个参数分别是x_offset、y_offset、height、width与置信度confidence,用这3个框去试探,试探是否框中有物体,如果有,就会把这个物体给框起来。如果是基于coco的数据集就会有80种类别,最后的维度应该为3x(80+5)=255,最上面两个预测结果shape同理。
yolov3主干网络为Darknet53,重要的是使用了残差网络Residual,darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU激活函数。
为什么要用残差网络?
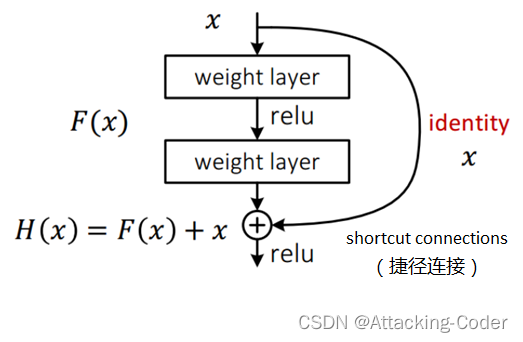
在卷积时候虽然是在提取特征但是同时一些表层特征也会损失掉。所以残差网络他就是卷一层然后和被卷的直射图像在进行堆叠,尽可能去保留原有特征。保留的细节越多越容易被识别出来。















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









