







1. 名义变量:nominal variable定类,只是用来分类
有序变量:ordinalvariable一种在类别上有些顺序的变量
2. 确定性算法表明在不同运行中,算法输出并不会改变。PC A可以得到一样的输出,但K-means不可以。
4. 梯度下降算法GD,每一次迭代需要使用整个训练数据集。
随机梯度下降算法SGD,每次迭代使用的批量是数据集中的随机样本组成的。
5. 增加随机森林中树的深度有可能会造成模型过拟合;
增加随机森林中树的数量可能会造成模型欠拟合
学习速率不能影响随机森林的拟合程度,不是超参数。
6. 如果是连续型的目标变量,该问题可以被划分到回归问题,采用均方误差作为损失函数的度量标准。
7. 激活函数sigmoid函数取值范围【0,1】,tanh函数取值范围【-1.1】,ReLU激活函数范围【0,inf】
8. 信息熵的公式:
9. 正在处理类属特征,并且没有查看分类变量再测试集中的分布。现在将one hot encoding(ONE)应用于类属特征中,那么应用ONE会面临的困难:分类变量中所有的类别没有全部出现在测试集中,不能进行ONE编码类别;类别的频率分布在训练集和测试集是不同的,使用ONE是需要注意。
10. word2vec算法:其中为词嵌入而设计的最优模型Skipgram模型(总-分),输入当前word,预测该word周围的多个词。CBOW模型(分-总)两者相反
12.对数损失度量函数不能取负值。损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。 机器学习中常见的损失函数:
a) log对数损失函数(逻辑回归),标准形式:L(Y,P(Y|X))=−logP(Y|X)
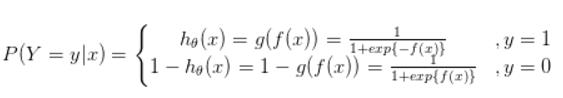
b) 平方损失函数(最小二乘法, Ordinary Least Squares )
标准形式如下:L(Y,f(X))=(Y−f(X))^2
c) 指数损失函数(Adaboost)

在给定n个样本的情况下,Adaboost的损失函数为:
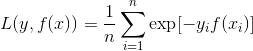
d) Hinge损失函数(SVM)
Hinge 损失函数的标准形式
L(y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









