







异步编程,是目前解决性能问题的一个大方向。其中怎么样实现异步有多种不同的实现方式。通过异步的方式,能够实现更高的资源利用和响应性。在网络和图形界面编程里面,一种非常普遍的做法是基于事件来实现用户响应性。也就是程序利用一个主事件循环,不断的处理触发的事件。而对应事件的处理是通过回调(callback)的形式注册到事件循环中,当对应的事件触发的时候,主循环就是调用对应的回调。
虽然这种基于事件和回调的编程模式存在了很多年了,但是用回调来写业务逻辑有一种很不爽的感觉,那就是经常的发事件,然后写对应的回调函数,会将一个很简单的处理逻辑分散在不同的地方,并且很有可能会引入额外的复杂性。自己在写界面的时候就经常出现一段紧密相关的逻辑分布在两个不同的类中,使得在找对应的上下文的时候出现极大的阻碍。
对于这种情况,在Python里面的twisted.defer提供了一种很优雅的解决方案。利用defer里面的inlineCallbacks这个decorator,可以使我们写异步的代码可以像写同步的代码一样,从而降低了异步编程的难度。(在C# 5和Javascript的Jscex里面已经有类似的实现)
twisted是一个Python的基于事件循环的网络库,里面实现了基本的事件循环和各种相关的网络工具。其中的defer抽象就是这篇文章主要介绍的对象。关于twisted的介绍可以看官网的教程,或者是著名的poetry twisted tutor。
例子
本文会用一个比较典型的例子来进行讲解。想象我们需要写这么一个服务器:
一个视频下载服务器,在接受到客户端的请求之后,会去下载相关的视频,并保存在服务器本地。具体来说,客户段会发送给服务器一个段地址。服务器在接受到短地址之后,会首先向段地址服务提供商请求转换段地址。在服务器接受到转换后的原地址之后,会向真正的下载地址发出真正的下载请求,然后在下载完成之后,将它保存起来。
首先,服务器程序肯定不会是同步的去处理这种请求,因为这样就大大的降低服务器的处理能力。所以我们会用异步调用的方式来处理这个请求,而在twisted里面就是通过注册事件回调的方式来完成。
同步实现
假设我们利用同步的方式来完成上述的功能,对应的代码应该是像下面这样:
|
def stringReceived(self, shortUrl):
self.transport.loseConnection()
self.downloadVideoFromShortUrl(shortUrl)
def downloadVideoFromShortUrl(self, shortUrl):
try:
url = transformShortUrl(shortUrl)
video = downloadVideoFromUrl(url)
storeVideo(video)
except BaseException, e:
print "exception:", e
|
其中,stringReceived函数会在接收到客户端发送过来的短地址之后调用,参数就是对应的shortUrl。在downloadVideoFromShortUrl里面的是程序的主要逻辑,它按顺序的调用了shortUrl转换、从url下载地址视频和本地储存视频文件。假设每个函数都是同步调用的话,逻辑非常清晰,看代码的时候直接从上往下读就可以了。其中也包含了错误的处理,也就是一个大的try…catch,其中transformShortUrl和downloadVideoFromUrl会在出现错误的时候抛BaseException。
但是同步代码的问题就在于,当你进程阻塞在任何一个同步调用上的时候,你的进程什么都干不了了。所以这个时候我们就会利用异步调用来解决这个问题。假设transformShortUrl、downloadVideoFromUrl都变成了异步调用。一般来说异步调用的结果我们都会通过回调的方式来处理。现在看看代码是怎么样。
基于回调的异步实现
基本的代码如下:
|
def downloadVideoFromShortUrlAsync(self, shortUrl):
d = transformShortUrlAsync(shortUrl)
def downloadVideoFromUrl(url):
print "long url:", url
d = downloadVideoFromUrlAsync(url)
def errDownloadVideoFromUrl(err):
print "exception:", err
d.addCallbacks(storeVideo, errDownloadVideoFromUrl)
def errTransformShortUrl(err):
print "exception:", err
d.addCallbacks(downloadVideoFromUrl, errTransformShortUrl)
|
为了容易区别,我把所有异步调用的函数都在函数名后面加上Async,来表示它是一个异步调用。每个异步调用会返回一个defer,暂且你可以认为这个defer表示的是这个调用是异步的。当你要处理这个异步调用的结果的时候,就往这个defer上面添加一个函数。当这个异步调用完成之后,就会调用添加到这个defer上面的函数。
由于现在我们要用回调来处理调用结果,所以我们就要将处理结果的逻辑放在另一个函数里面。就比如我们在转换完段地址之后,会从这个地址下载视频。而下载视频的逻辑就另外定义一个函数来完成,也就是代码中的downloadVideoFromUrl。可以看到,处理逻辑已经变得复杂,而且增加了嵌套。况且处理的逻辑有点不符合从上往下的阅读习惯。在利用回调的实现里面,必须将结果的处理和调用逻辑分开写,否则你无法完成操作。在写一些带有循环和复杂逻辑的代码的时候,这个弊端就会显现出来。
而且你可以看到处理错误的逻辑和正确的处理逻辑被分割开,你很难看出里面的具体逻辑。如果你不是写习惯了这种基于回调的代码,相信一般人很难在一开始的时候就看出上面的逻辑。
既然基于回调的写程序方式那么的反人类,那么我们有什么解决方案呢?twisted的inlineCallbacks就出场了。
基于inlineCallbacks的异步实现
首先我们的几个基本调用还是异步,那么用了inlineCallbacks之后的代码如下:
|
@inlineCallbacks
def downloadVideoFromShortUrlAsync(self, shortUrl):
try:
url = yield transformShortUrlAsync(shortUrl)
video = yield downloadVideoFromUrlAsync(url)
storeVideo(video)
except BaseException, e:
print "exception:", e
|
省略掉多出来的yield,这个代码就和同步的一模一样!!唯一不同的就是在异步调用的前面加上了yield!!
怎么样,这样写代码是不是很爽?
但是细想一下,我们的transformShortUrlAsync明明是异步调用啊,明明不能马上的获得结果啊,那url = transformShortUrlAsync那不就是错误的么?
秘密就在于我们多加上去的inlineCallbacks这个decorator和yield上面。首先解释一下,downloadVideoFromShortUrlAsync本身也是一个异步调用。当他执行到第一个异步调用的地方,它会在yield的地方“等待”异步调用的执行结束和返回结果。在第二个异步调用的地方也是同样的,他也是“等待”异步调用的执行结束和返回结果。
也就是从downloadVideoFromShortUrlAsync的角度来说,他的执行顺序是和同步没有差别的,他也是首先执行transformShortUrl,然后downloadVideo,最后store。而且从代码的结构上来说,也是很清晰的反应出了这一点。
但是,你会不会觉得这里有点怪怪的?既然downloadVideoFromShortUrlAsync函数会在yield的地方等待异步调用的执行,那么整个调用本身不就又变回同步的了么?那我用异步调用来干什么……
神奇就神奇在,如果yield后面的函数调用是异步的,那么downloadVideoFromShortUrlAsync也还是异步的!但是他要等待结果,怎么异步啊?其实,整个函数的执行是这样的:
- 进入
downloadVideoFromShortUrlAsync函数,调用transformShortUrlAsync。 - 由于
transformShortUrlAsync是一个异步调用,所以在函数返回的时候,结果还没有产生。这个时候,downloadVideoFromShortUrlAsync就返回了。 - 当
transformShortUrlAsync的结果产生之后,就会继续从downloadVideoFromShortUrlAsync函数没有执行的部分开始执行,这个时候url就获得了异步调用的结果。 - 接着调用
downloadVideoFromUrlAsync,和step 2一样,当这个异步调用返回的时候,downloadVideoFromShortUrlAsync就又返回了。 - 当
transformShortUrlAsync的结果获得之后,执行就又从downloadVideoFromShortUrlAsync没有执行的部分开始执行,这个时候就video就赋值为已经下载的视频文件了。 - 接着执行余下的部分。
整个执行时序就如下面这幅图显示:
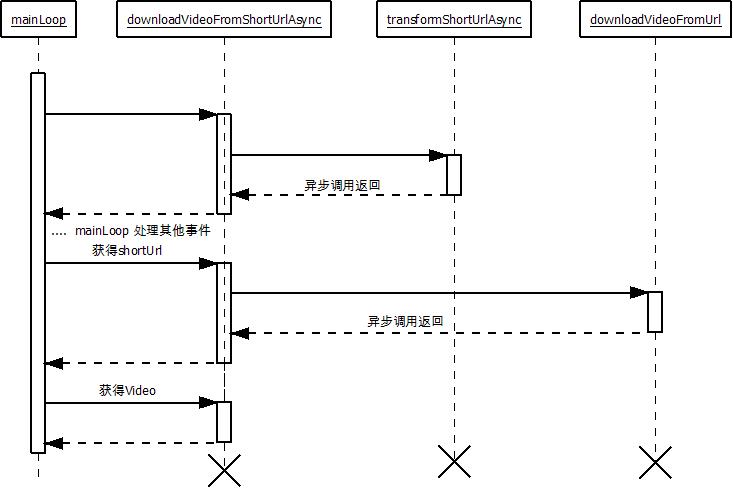
就如上面的图显示的这样,downloadVideoFromShortUrlAsync会在异步调用的结果返回之后继续调用接下来的部分。
需要注意的是,inlineCallbacks并不会将一个本来同步的函数变成异步,他只是使得一个函数在调用异步函数的时候可以很方便的书写,并且将自己也变成一个异步函数。但是如果你调用的函数不是异步的,那么用inlineCallbacks修饰的这个函数也不会是异步的。
inlineCallbacks的实现
所以我们最关心的是,How does the magic happen? 那我们直接来看看代码实现。注意这里我假设你知道Python的decorator, 也知道Python的generator。
|
def inlineCallbacks(f):
def unwindGenerator(*args, **kwargs):
try:
gen = f(*args, **kwargs)
except _DefGen_Return:
raise TypeError(
"inlineCallbacks requires %r to produce a generator; instead"
"caught returnValue being used in a non-generator" % (f,))
if not isinstance(gen, types.GeneratorType):
raise TypeError(
"inlineCallbacks requires %r to produce a generator; "
"instead got %r" % (f, gen))
return _inlineCallbacks(None, gen, Deferred())
return mergeFunctionMetadata(f, unwindGenerator)
|
其中的mergeFunctionMetaData其实就是将f的__name__和__doc__赋给unwindGenerator。而我们从unwindGenerator可以看到,函数首先调用了f,也就是被修饰的函数,而因为要用inlineCallbacks的函数一般都是generator,这个函数返回的是一个generator object。所以最重要的函数是_inlineCallbacks这个函数。我们再来看看它的实现。
|
def _inlineCallbacks(result, g, deferred):
waiting = [True, # waiting for result?
None] # result
while 1:
try:
isFailure = isinstance(result, failure.Failure)
if isFailure:
result = result.throwExceptionIntoGenerator(g)
else:
result = g.send(result)
except StopIteration:
# fell off the end, or "return" statement
deferred.callback(None)
return deferred
except _DefGen_Return, e:
appCodeTrace = exc_info()[2].tb_next
if isFailure:
appCodeTrace = appCodeTrace.tb_next
if appCodeTrace.tb_next.tb_next:
ultimateTrace = appCodeTrace
while ultimateTrace.tb_next.tb_next:
ultimateTrace = ultimateTrace.tb_next
filename = ultimateTrace.tb_frame.f_code.co_filename
lineno = ultimateTrace.tb_lineno
warnings.warn_explicit(
"returnValue() in %r causing %r to exit: "
"returnValue should only be invoked by functions decorated "
"with inlineCallbacks" % (
ultimateTrace.tb_frame.f_code.co_name,
appCodeTrace.tb_frame.f_code.co_name),
DeprecationWarning, filename, lineno)
deferred.callback(e.value)
return deferred
except:
deferred.errback()
return deferred
if isinstance(result, Deferred):
# a deferred was yielded, get the result.
def gotResult(r):
if waiting[]:
waiting[] = False
waiting[1] = r
else:
_inlineCallbacks(r, g, deferred)
result.addBoth(gotResult)
if waiting[]:
waiting[] = False
return deferred
result = waiting[1]
waiting[] = True
waiting[1] = None
return deferred
|
首先知道,_inlineCallbacks这个函数的3个参数接受的分别是上一次这个generator返回的结果(result),这个generator(g),还有这个generator对应的defer(deferred)。
首先,这个函数第一次调用是从inlineCallbacks(注意区分有没有下划线开头)里面调过来的。所以第一次调用的时候,result是None,而g是一个开没有开始执行的generator。
而最重要的就是7-11行的代码。
- 首先7行的代码就是取得result的类型信息。这样需要注意的是,如果异步调用返回的是一个错误的结果,那么类型就是
failure.Failure。如果是正常的话,就不是failure.Failure。 - 8-11行:接着就根据result的类型来进行不同的处理。如果result是failure的话,那么就调用
result.throwExceptionIntoGenerator(g),这个函数的作用就是将result对应的异常抛进g里面。
如果result的类型不是failure的话,那么就是正常的结果。所以就直接用g.send(result)来将结果传进这个generator里面。注意到,当第一次调用_inlineCallbacks的时候,result是None,所以第一次调用相当于调用下面的代码:g.send(None)。这个用法是正确的,因为当generator还没有开始的时候,g.send()只能传None这样的参数。
接下来最重要的就是39到46行的代码。注意到上面对generator的操作会返回一个这个yield的值。如果yield出来的一个defer,那么表示这个时候yield后面跟的是一个异步调用,所以这个时候,_inlineCallbacks会将一个gotResult函数传进这个defer里面,这样当异步调用完成的时候,gotResult就会被调用并处理调用的结果。
在gotResult里面,忽略掉if waiting那一段,其实最后的就是调用回_inlineCallback自己。所以现在我们大概可以有下面一个执行顺序了:
当我们调用downloadVideoFromShortUrlAsync的时候,最开始的时候是在inlineCallbacks的里面调用了一次这个函数,而一个generator在开始的时候是直接返回一个generator object的。这个时候inlineCallbacks就调用了_inlineCallbacks(None, gen, Deferred())。
这时进到_inlineCallbacks里面的时候就会走到11行,就是result = g.send(None)。这个语句是成立的。这个时候downloadVideoFromShortUrlAsync就开始运行,直到调用到transformShortUrlAsync并且返回一个defer。这个时候就继续走到48行。也就是在这个defer上面添加gotResult函数。那么当这个defer被调用(也就是结果获得)的时候,gotResult就会获得这个结果,并继续执行downloadVideoFromShortUrlAsync下面的代码。
分析
正如前面所讲,有了inlineCallbacks之后,其实自己定义的函数并没有变成异步,只不过他将函数里面调用异步函数的地方自动的做了回调的处理,从而使得函数本身以一种“奇怪”的方式异步执行。
为什么可以有这种效果呢?我觉得主要有以下几点:
- AIO,也就是异步IO。这个可以说是实现这种语法结果的必要条件,因为当我们从调用异步函数的地方获得了一个defer之后,这时候并没有获得结果。而结果会在未来的某个时刻获得。而我们需要在获得结果的那个时刻,函数余下的部分可以继续执行,而这一个就是AIO的用法,我们就可以把获得结果的处理部分当做回调那样传递给这个IO操作,让他自动的在操作完成的时候调用这个回调。而在twisted里面,AIO的是使用事件循环来实现的。
- generator。这个并不是实现
inlineCallbacks这种语法结构的必要条件,就像Jscex里面就是通过修改语法树的方式来实现,因为Javascript里面是没有generator的。但是有了generator之后,就会发现实现这个结构会异常的简单,就像本身就应该是这么写的一样。可以说generator对于基于回调的一些实现都是很好的实现利器,至少我在inlineCallbacks这部分是真正的感受到了generator带来的方便。
所以主要还是AIO的功劳,就像在Node.js里面,实现类似的功能是比较方便的,因为Node.js本身的IO都是AIO,所以只要修改语法树,就是可以达到这种效果。
转载:http://airekans.github.io/python/2012/07/17/inlinecallbacks/















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









