









MQ介绍
什么是MQ,为什么要用MQ?
MQ:MessageQueue ,消息队列。可以分为两个部分来理解:队列,是一种FIFO(先进先出)的数据结构。消息:不同应用程序之间传递的数据。这里不同的应用包含不同语言编写的程序。
总的来说,就是将消息以队列的形式存储起来,并且在不同程序之间进行传递,这样就成了MessageQueue.也就是MQ。
MQ的作用
- 削峰
- 解耦
- 解耦
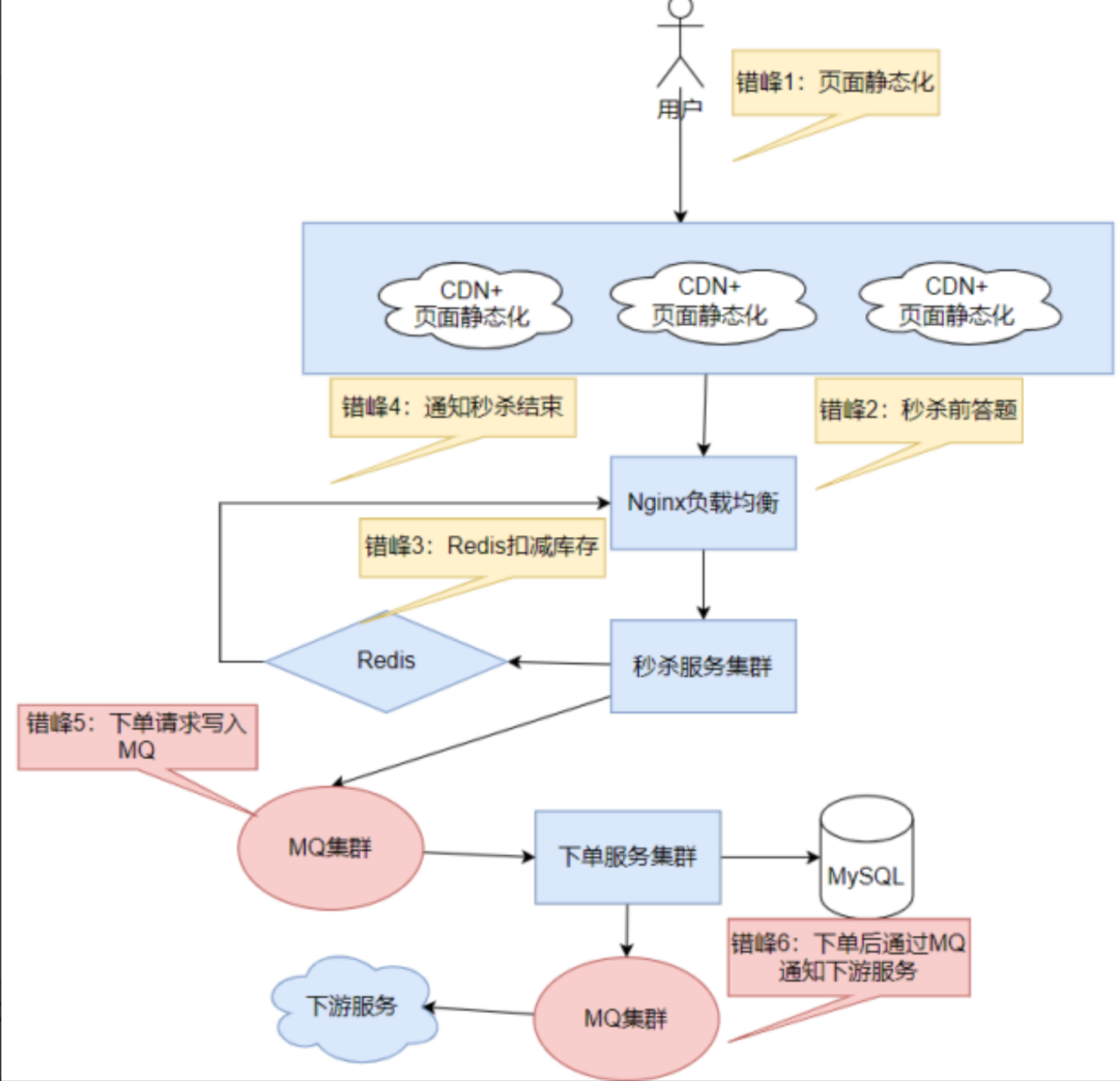
MQ 是为了在不影响应用程序的正常运行,并且能够异步处理消息,且进行流量削峰的场景下而生的中间件服务,MQ中间件在很多业务场景中扮演着重要的角色,例如:下图就是一个典型的秒杀场景业务图:
MQ 的优缺点
缺点
- 系统可用性降低:系统引入的外部依赖增多,系统的稳定性就会变差,一旦MQ宕机,对业务会产生影响,这时就需要考虑如何保证MQ的高可用了。
- 系统复杂度提高:引入MQ后系统的复杂度会大大提高,以前服务之间可以进行同步的服务调用。引入了MQ 之后,会变成异步调用。数据链路就会变得更加复杂。并且会带来一系列问题:
- 消息如何高效存储
- 如何定期维护
- 如何监控
- 如何溯源
- 如何保证消息不丢失
- 如何保证消息不回重复调用
- 如何保证消息的顺序
- 等等一系列的问题
- 消息的安全性问题:引入了MQ 之后,消息会在MQ中存储起来。这时就会带来很多网络造成的数据安全问题:
- 消息如何高效存储
- 如何定期维护
- 如何监控
- 如何溯源
- 如何保证消息不丢失
- 如何保证消息不回重复调用
- 如何保证消息的顺序
- 等等一系列的问题
安装RabbitMQ服务
- 安装erlang erlang 的下载地址https://github.com/rabbitmq/erlang-rpm/releases
rpm -ivh erlang-25.2.2-1.el9.x86_64.rpm
- 验证Erlang是否安装成功
erl -version
- 安装MQ,RPM 下载 https://github.com/rabbitmq/rabbitmq-server/releases
rpm -ivh rabbitmq-server-3.11.10-1.el8.noarch.rpm
- MQ常见的维护命令
service rabbitmq-server start #启动Rabbitmq服务。启动应用之前要先启动服务。rabbitmq-server -deched --后台启动RabbitMQ应用
rabbitmqctl start_app #启动Rabbitmq
rabbitmqctl stop #关闭Rabbitmq
rabbitmqctl status # 查看RabbitMQ服务状态。
- 启用RabbitMQ 管理插件
rabbitmq-plugin senable rabbitmq_management
- 插件激活后,就可以访问RabbitMQ的Web控制台了。访问端口15672。RabbitMQ提供的默认用户是
guest,密码guest。
Exchange和Queue
RabbitMQ 中的消息都是通过Queue队列进行传递的。这个Queue其实就是一个典型的(FIFO)先进先出的队列数据接口。而Exchange 交换机则是用来辅助进行消息分发的。Exchange和Queue 之间会建立一种绑定关系,通过绑定关系,Exchange交换机里发送的消息可以分发到不同的Queue上。
对于队列有Classic、Quorum、Stream三种类型。其中Classic和Quorum两种类型,使用上几乎没有什么区别。但是Stream队列就无法直接消费消息了。并且每种不同类型队列的可选参数也有很多不同。
队列Queue既可以发消息,也可收消息。而Exchange只是用来辅助发送消息的。
Echange
echange交换及既然可以绑定一个队列,当然也可以绑定更多的队列。而Exchange起到的作用,就是将发送到Exchange上的消息转发到绑定的队列上,在具体使用时,通常只有消息生产者与Exchange打交道,而消费者,则并不需要与Exchanged打交道,只要从Queue中消费消息就可以了
另外,Exchange 并不只是简单的将消息全部转发给Queue,在实际应用中,Exchange与Queue之间可以建立不同类型的绑定关系。然后通过一些不同的策略,选择将消息转发到哪些Queue上。这时候,Message上的几个没有用上的参数,向Routing key ,Headers,Properties等参数就可以排上用场了。
Connection和Channel
针对这两个概念可以这样理解:一个Connection可以理解为一个客户端应用,就像一个客户端连接到Mysql 数据库一样,而一个客户端可以创建多个Channel,用来与RabbitMQ及逆行交互。
使用代码来完成对MQTT操作的示例
- Maven依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.9.0</version>
</dependency>
- 创建消费者
public class FirstConsumer{
private static final String HOST_NAME="192.168.65.112"; privatestaticfinalintHOST_PORT=5672;
private static final String QUEUE_NAME="test2";
public static final String USER_NAME="admin";
public static final String PASSWORD="admin";
public static final String VIRTUAL_HOST="/mirror";
public static void main(String[]args)throwsException{
ConnectionFactoryfactory=newConnectionFactory(); factory.setHost(HOST_NAME);
factory.setPort(HOST_PORT);
factory.setUsername(USER_NAME);
factory.setPassword(PASSWORD);
factory.setVirtualHost(VIRTUAL_HOST);
Connectionconnection=factory.newConnection();
Channelchannel=connection.createChannel();
/**
*声明一个对列。几个参数依次为:队列名,durable是否实例化;exclusive:是否独占;autoDelete:是否自动删除;arguments:参数
*这几个参数跟创建队列的页面是一致的。
*如果Broker上没有队列,那么就会自动创建队列。
*但是如果Broker上已经由了这个队列。那么队列的属性必须匹配,否则会报错。 */
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
//每个worker同时最多只处理一个消息
channel.basicQos(1);
//回调函数,处理接收到的消息
Consumer myconsumer=new DefaultConsumer(channel){
@Override
public void handleDelivery(StringconsumerTag,Envelopeenvelope,
AMQP.BasicPropertiesproperties,byte[]body) throwsIOException{
System.out.println("========================");
StringroutingKey=envelope.getRoutingKey();
System.out.println("routingKey>"+routingKey);
StringcontentType=properties.getContentType();
System.out.println("contentType>"+contentType);
longdeliveryTag=envelope.getDeliveryTag();
System.out.println("deliveryTag>"+deliveryTag);
System.out.println("content:"+newString(body,"UTF-8"));
//(processthemessagecomponentshere...)
channel.basicAck(deliveryTag,false);
}
}
//从test1队列接收消息
channel.basicConsume(QUEUE_NAME,myconsumer);
}
}
RabbitMQ的消息流转模型
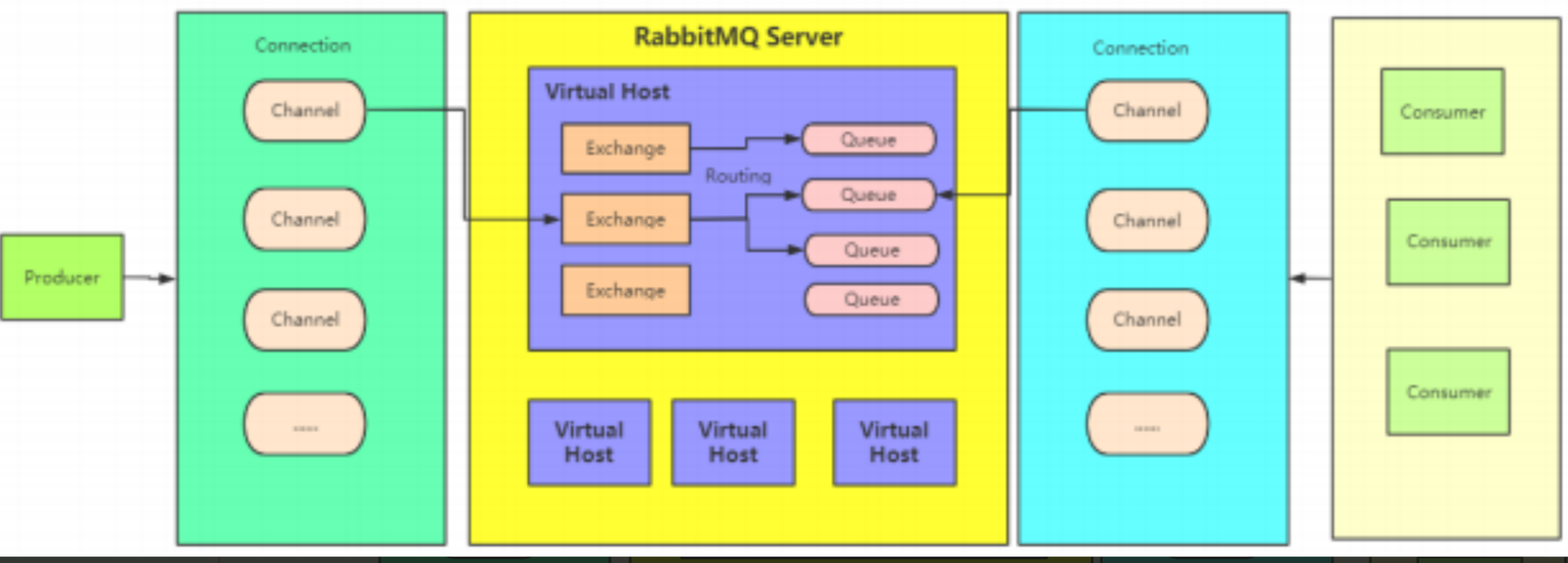
- 服务器Broker
- 搭建一个RabbitMQ server 的服务器称为Broker。
- 虚拟主机 virtual Host
- RabbitMQ处于服务器复用的想法,可以在一个RabbitMQ集群中划分出多个虚拟主机。每一个虚拟主机都有全套的基础服务组件,针对每个虚拟主机进行权限以及数据的分配。不同虚拟主机值之间是完全隔离的,如果不考虑资源分配的情况,一个虚拟主机就可以当成一个独立的RabbitMQ服务使用
- 链接Connection
- 客户端与RabbitMQ 进行交互,首先需要建立一个TPC 的链接,这个连接就是Connection,既然是通道,就需要尽量在停止使用时要管理,释放资源。
- 信道Channel
- 一旦客户端与RabbitMQ 建立了链接,就会分配一个AMQO的信道Channel,每个信道都会分配一个唯一的信道ID,可以理解为是客户端与RabbitMQ 进行数据交互的通道。
- RabbitMQ 为了减少性能开销,也会在Connection中建立多个Channe,这样方便客户端进行多线程链接,这些链接会复用统一Contection的TCP通道。
- 交换机Exchange
- Exchange是RabbitMQ 进行数据路由的重要组件,消息发送到RabbitMQ中后,会首先进入一个交换机 ,然后交换机负责将不同的数据转到不同的队列中。RabbitMQ 中有多种不同类型的交换机来支持不同的路由策略。
- 交换机多用来与生产者打交道,生产者发送的消息通过Exchange交换机分配到不同的Queue队列中上,对于消费者来说,通常只需要关注自己感兴趣的队列就可以了
- 队列 Queue
- Queue是实际保存数据的最小单位,Queue不需要在Exchange也可以独立工作,只不过通常在业务场景中会增加Exchange实现更复杂的消息分配策略。Queue天生就具有FIFO 顺序,消息最终都会分发到不同的Queue当中,然后才被消费者进行消费处理。这也是最近RabbitMQ功能改动最大的地方,最为常用的是经典队列Classic。
RabbitMQ 常用的消息场景
Hello World

最直接方式就是P端发送一个消息到一个指定的Queue,中间不需要任何Exchange规则,c端按Queue方式进行消费
其中的关键代码:
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
channel.basicPublish("",QUEUE_NAME,null,message.getBytes("UTF-8"));
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
Work Queues 工作序列

这是RabbitMQ最基础也是最常用的一种工作机制。工作任务模式,由一个领导部署一个任务,由下面多个员工来进行完成
也就是消息生产者Producer将消息发送到队列Queue中,多个Consumer同时往队列上消费消息。
关键代码:
channel.queueDeclare(TASK_QUEUE_NAME,true,false,false,null);//任务一般是不能因为消息中间件的服务而被耽误的,所以durable设置成了true,这样,即使rabbitMQ服务断了,这个消息也不会消失
channel.basicPublish("",TASK_QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes("UTF-8"));
channel.queueDeclare(TASK_QUEUE_NAME,true,false,false,null);
channel.basicQos(1);
channel.basicConsume(TASK_QUEUE_NAME,false,consumer);
详细说明:
首先,Consumer端的autoArk字段设置的false,这表示cunsumer在接收到消息后不会自动反馈到服务器已消费了Message,而要改在对message处理完成了之后,在调用channel.basicAck来通知服务器已经消费了该message,这样即使Consumer在执行message的过程中出现了问题,也不会造成message被忽略,因为没有ack的message会被服务重新投递。
这里经常会出现一个很常见的BUG:如果所有的consumer都忘记调用basicAck了,就会造成message不同的分发,也就造成不断的消耗系统资源,这也就是Poison Message (毒消息)
其次,官方特意提到的Message的持久性,关键的message不能因为服务器出现问题而忽略,还要注意,官方特意提到,所有的queue是不能被多次定义的。如果一个queue在开始创建时被声明了durable,那么再次声明这个queue时,即使声明为not durable 。那这个queue 的结果也是durable的。
然后,是中间件最为关键的分发方式,这里RabbitMQ 默认采用的是fair dispatch 也叫round-robin 模式。 就是把消息进行轮询,在所有的consumer中轮流发送。这种方式,没有考虑消息处理的复杂度以及consumer 的处理能力,而他们改进后的方法,是consumer 可以向服务器声明一个prefetchCount ,这里可以称作预处理能力值。channel.basicQos(prefetchCount);表示当前这个Consumer可以同时处理几个message
Publish和Subscribe 订阅发布机制
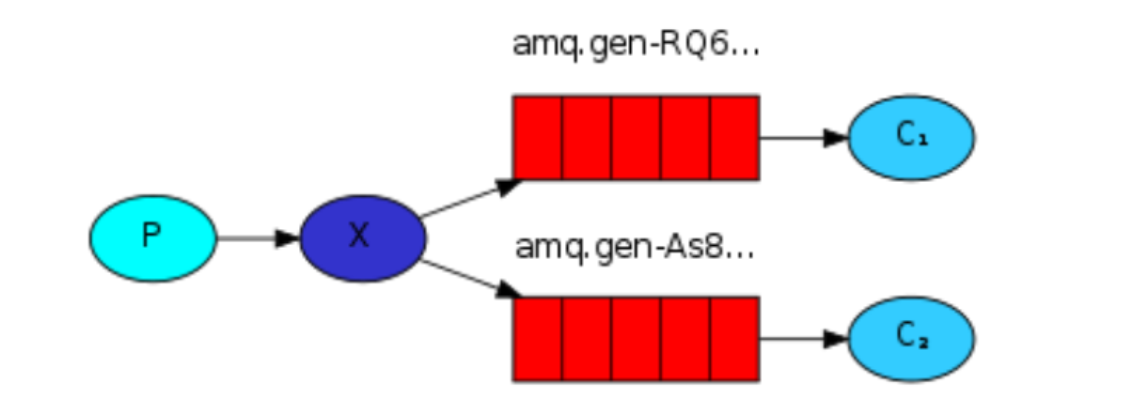
这种机制是对上面的一种补充,也就是把Preducer 和consumer 进行进一步解耦,producer 只负责发送消息,至于消息进入那个Queue ,由Exchange来分配。如上图,就是把producer 发送的消息,交由exchange同时发送给两个queue 里,然后由不同的consumer 去进行消费。
关键代码
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
channel.basicPublish(EXCHANGE_NAME,"",null,message.getBytes("UTF-8"));
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
StringqueueName=channel.queueDeclare().getQueue();
channel.queueBind(queueName,EXCHANGE_NAME,"");
关键处就是type为”fanout” 的exchange,这种类型的exchange只负责往所有已绑定的队列上发送消息。
Routing 基于由内容的路由
type为”direct” 的exchange
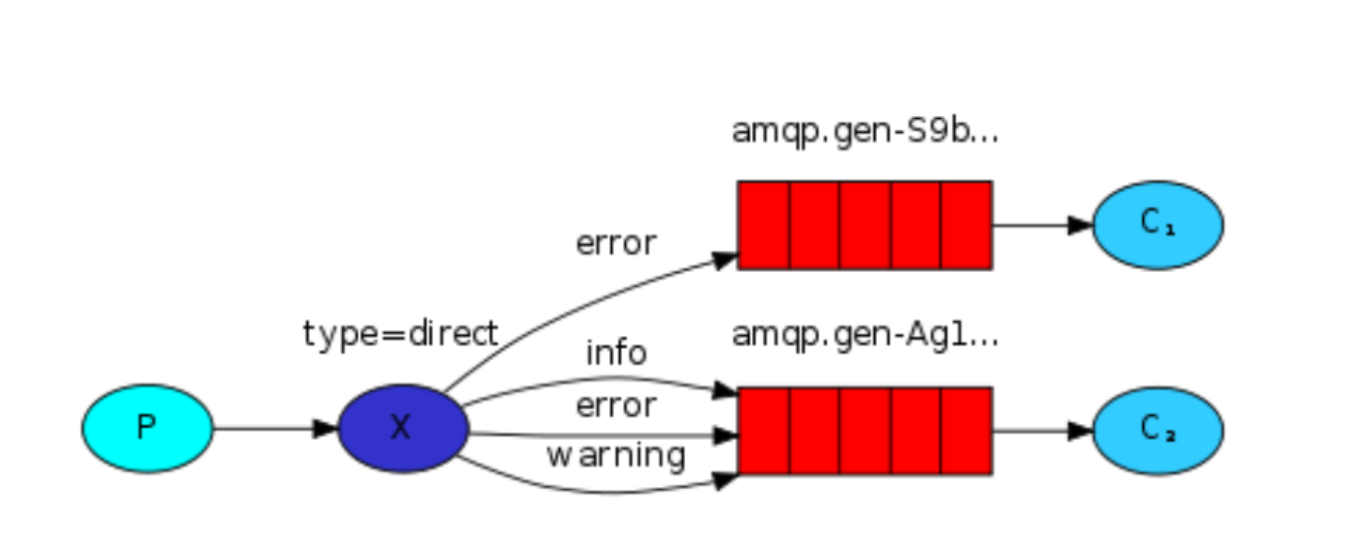
这是根据Publish和Subscribe的基础上,增加了一个路由配置,指定exchange如何将不同类别的消息分发到不同的queue上。
关键代码
channel.exchangeDeclare(EXCHANGE_NAME,"direct");
channel.basicPublish(EXCHANGE_NAME,routingKey,null,message.getBytes("UTF-8"));
channel.exchangeDeclare(EXCHANGE_NAME,"direct");
channel.queueBind(queueName,EXCHANGE_NAME,routingKey1);
channel.queueBind(queueName,EXCHANGE_NAME,routingKey2);
channel.basicConsume(queueName,true,consumer);
Topics 基于会话的路由
type 为 topic 的exchange
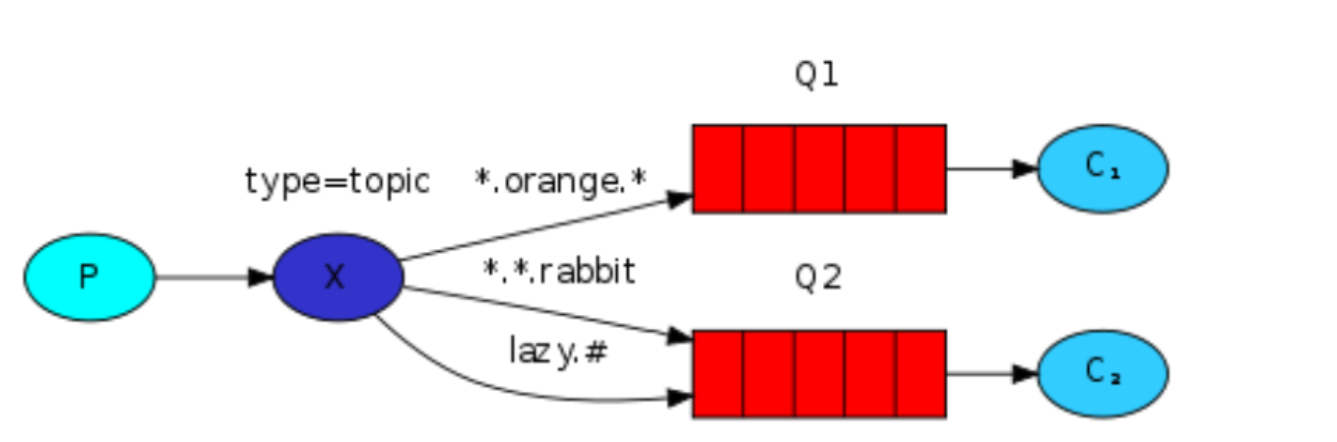
这种模式就是在Routing 模式的基础上,对routingkey 进行了模糊匹配,单词之间用,隔开。* 表示具有一个具体的单词,# 表示0个或多个单词
关键代码
channel.exchangeDeclare(EXCHANGE_NAME,"topic");
channel.basicPublish(EXCHANGE_NAME,routingKey,null,message.getBytes("UTF-8"));
channel.exchangeDeclare(EXCHANGE_NAME,"topic");
channel.queueBind(queueName,EXCHANGE_NAME,routingKey1);
channel.queueBind(queueName,EXCHANGE_NAME,routingKey2);
channel.basicConsume(queueName,true,consumer);
Publisher Confirms 发送者消息确认
RabbitMQ 的消息可靠性是非常高的,但是他们以往的机制都是保证消息发送到了MQ 之后,可以推送到消费者,不会丢失消息。但是发送者发送消息是否成功是没有保证的。
发送者确认模式默认是不开启的,所以需要开启发送确认模式,需要收到在channel 中声明。
channel.confirmSelect();
在官方的示例中,重点解释了三种策略
- 单条消息发布,就是发布一条消息确认一条消息
核心代码
for(inti=0;i<MESSAGE_COUNT;i++){
Stringbody=String.valueOf(i);
channel.basicPublish("",queue,null,body.getBytes());
channel.waitForConfirmsOrDie(5_000);
}
channel.waitForConfirmsOrDie(5_000),这个方法就会在Channel端等待RabbitMQ 给出一个想用,用来表明这个消息已经正确发送到了RabbitMQ服务器端,但是需要注意的是,这个方法会同步阻塞Channel,在等待确认期间,channel将不再继续发送消息,也就是说会明显降低集群的发送速度即吞吐量。
关于官方的解释:其实Channel的工作是异步的,会将Channel阻塞住,然后异步等待服务器端发送了确认通知,才会解除阻塞。但是我们在使用时可以将其当作同步工具来看待。如果到了超时时间,还没有收到服务器的确认机制,那就会抛出异常,然后通常在这个异常的方式记录错误日志或者尝试重发消息,但是重试时一定一定不要让程序陷入死循环。
- 批量发送消息
在之前单条确认机制会对系统的吞吐量造成很大的影响,所以稍微中和一点的方式就是发送一批消息后,然后在进行一个确认。
核心代码
intbatchSize=100;
intoutstandingMessageCount=0;
longstart=System.nanoTime();
for(inti=0;i<MESSAGE_COUNT;i++){
Stringbody=String.valueOf(i);
ch.basicPublish("",queue,null,body.getBytes());
outstandingMessageCount++;
if(outstandingMessageCount==batchSize){
ch.waitForConfirmsOrDie(5_000);
outstandingMessageCount=0;
}
}
if(outstandingMessageCount>0){
ch.waitForConfirmsOrDie(5_000);
}
这种方式可以稍微缓解下发送者确认模式对吞吐量的影响,但是也有个固有的问题,当确认出现异常时,发送者只知道这一批消息出现了问题,而无法确认具体时那条消息出了问题。
- 异步确认消息
实现的方式也比较简单,就是在Producer中的channel中注册监听器来对消息进行确认,核心代码就一个
channel.addConfirmListener(ConfirmCallbackvar1,ConfirmCallbackvar2);
这里注册两个,指的是,成功一个,失败一个。
- 上面三种方式的区别
这三种机制都能够提升Producer 发送消息的安全性,通常情况下,第三种异步确认机制性能是最好的。
SpringBoot 集成RabbitMQ
maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
配置关键参数:
spring:
rabbitmq:
host: "localhost"
port: 5672
username: "admin"
password: "secret"
发送消息
import org.springframework.amqp.core.AmqpAdmin;
import org.springframework.amqp.core.AmqpTemplate;
import org.springframework.stereotype.Component;
@Component
public class MyBean {
private final AmqpAdmin amqpAdmin;
private final AmqpTemplate amqpTemplate;
public MyBean(AmqpAdmin amqpAdmin, AmqpTemplate amqpTemplate) {
this.amqpAdmin = amqpAdmin;
this.amqpTemplate = amqpTemplate;
}
public void someMethod() {
this.amqpAdmin.getQueueInfo("someQueue");
}
public void someOtherMethod() {
this.amqpTemplate.convertAndSend("hello");
}
}
接收消息
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
public class MyBean {
@RabbitListener(queues = "someQueue", containerFactory = "myFactory")
public void processMessage(String content) {
// ...
}
}
配置文件
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.boot.autoconfigure.amqp.SimpleRabbitListenerContainerFactoryConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration(proxyBeanMethods = false)
public class MyRabbitConfiguration {
@Bean
public SimpleRabbitListenerContainerFactory myFactory(SimpleRabbitListenerContainerFactoryConfigurer configurer) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
ConnectionFactory connectionFactory = getCustomConnectionFactory();
configurer.configure(factory, connectionFactory);
factory.setMessageConverter(new MyMessageConverter());
return factory;
}
private ConnectionFactory getCustomConnectionFactory() {
return ...
}
}
RabbitMQ 集群
如何保证RabbitMQ 服务的高可用
默认的普通集群模式:
这种模式使用Erlang语言天生具备的集群方式搭建。这种集群模式下,集群的各个节点之间只会有相同 的元数据,即队列结构,而消息不会进行冗余,只存在一个节点中。消费时,如果消费的不是存有数据
的节点, RabbitMQ会临时在节点之间进行数据传输,将消息从存有数据的节点传输到消费的节点. 很显然,这种集群模式的消息可靠性不是很高。因为如果其中有个节点服务宕机了,那这个节点上的数据就无法消费了,需要等到这个节点服务恢复后才能消费,而这时,消费者端已经消费过的消息就有可能给不了服务端正确应答,服务起来后,就会再次消费这些消息,造成这部分消息重复消费。 另外,如果消息没有做持久化,重启就消息就会丢失。
并且,这种集群模式也不支持高可用,即当某一个节点服务挂了后,需要手动重启服务,才能保证这一 部分消息能正常消费。
所以这种集群模式只适合一些对消息安全性不是很高的场景。而在使用这种模式时,消费者应该尽量的连接上每一个节点,减少消息在集群中的传输。
镜像模式:
搭建了普通集群之后再补充搭建。其本质区别在于,这种模式会在镜像节点中间主动进行消息同步,而不是在客户端拉取消息时临时同步。
并且在集群内部有一个算法会选举产生master和slave,当一个master挂了后,也会自动选出一个来。 从而给整个集群提供高可用能力。
这种模式的消息可靠性更高,因为每个节点上都存着全量的消息。而他的弊端也是明显的,集群内部的网络带宽会被这种同步通讯大量的消耗,进而降低整个集群的性能。这种模式下,队列数量最好不要过
多。
搭建集群
- 需要同步集群节点中的cookie
默认会在 /var/lib/rabbitmq/目录下生成一个.erlang.cookie。 里面有一个字符串。我们要做的就是保证集群中三个节点的这个cookie字符串一致。 (Linux 使用SCP 命令进行文件复制)
- 将work1 的服务添加到work2的集群中
需要保证work2的集群可以正常工作
[root@worker1 rabbitmq]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@worker1 ...
[root@worker1 rabbitmq]# rabbitmqctl join_cluster --ram rabbit@worker2
Clustering node rabbit@worker1 with rabbit@worker2
[root@worker1 rabbitmq]# rabbitmqctl start_app
Starting node rabbit@worker1 ...
–ram 表示以Ram节点加入集群。RabbitMQ的集群节点分为disk和ram。disk节点会将元数据保存到硬盘当中,而ram节点只是在内存中保存元数据。
1、由于ram节点减少了很多与硬盘的交互,所以,ram节点的元数据使用性能会比较高。但是,同时,这也意味着元数据的安全性是不如disk节点的。在我们这个集群中,worker1和worker3都以ram节点的身份加入到worker2集群里,因此,是存在单点故障的。如果worker2节点服务崩溃,那么元数据就有可能丢失。在企业进行部署时,性能与安全性需要自己进行平衡。
2、这里说的元数据仅仅只包含交换机、队列等的定义,而不包含具体的消息。因此,ram节点的性能提升,仅仅体现在对元数据进行管理时,比如修改队列queue,交换机exchange,虚拟机vhosts等时,与消息的生产和消费速度无关。
3、如果一个集群中,全部都是ram节点,那么元数据就有可能丢失。这会造成集群停止之后就启动不起来了。RabbitMQ会尽量阻止创建一个全是ram节点的集群,但是并不能彻底阻止。所以,综合考虑,官方其实并不建议使用ram节点,更推荐保证集群中节点的资源投入,使用disk节点。
- 也可以用后台指令查看集群状态 rabbitmqctl cluster_status
搭建镜像集群
- 我们首先创建一个/mirror的虚拟主机,然后再添加给对应的镜像策略:
[root@worker2 rabbitmq]# rabbitmqctl add_vhost /mirror
Adding vhost "/mirror" ...
[root@worker2 rabbitmq]# rabbitmqctl set_policy ha-all --vhost "/mirror" "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/mirror" ...
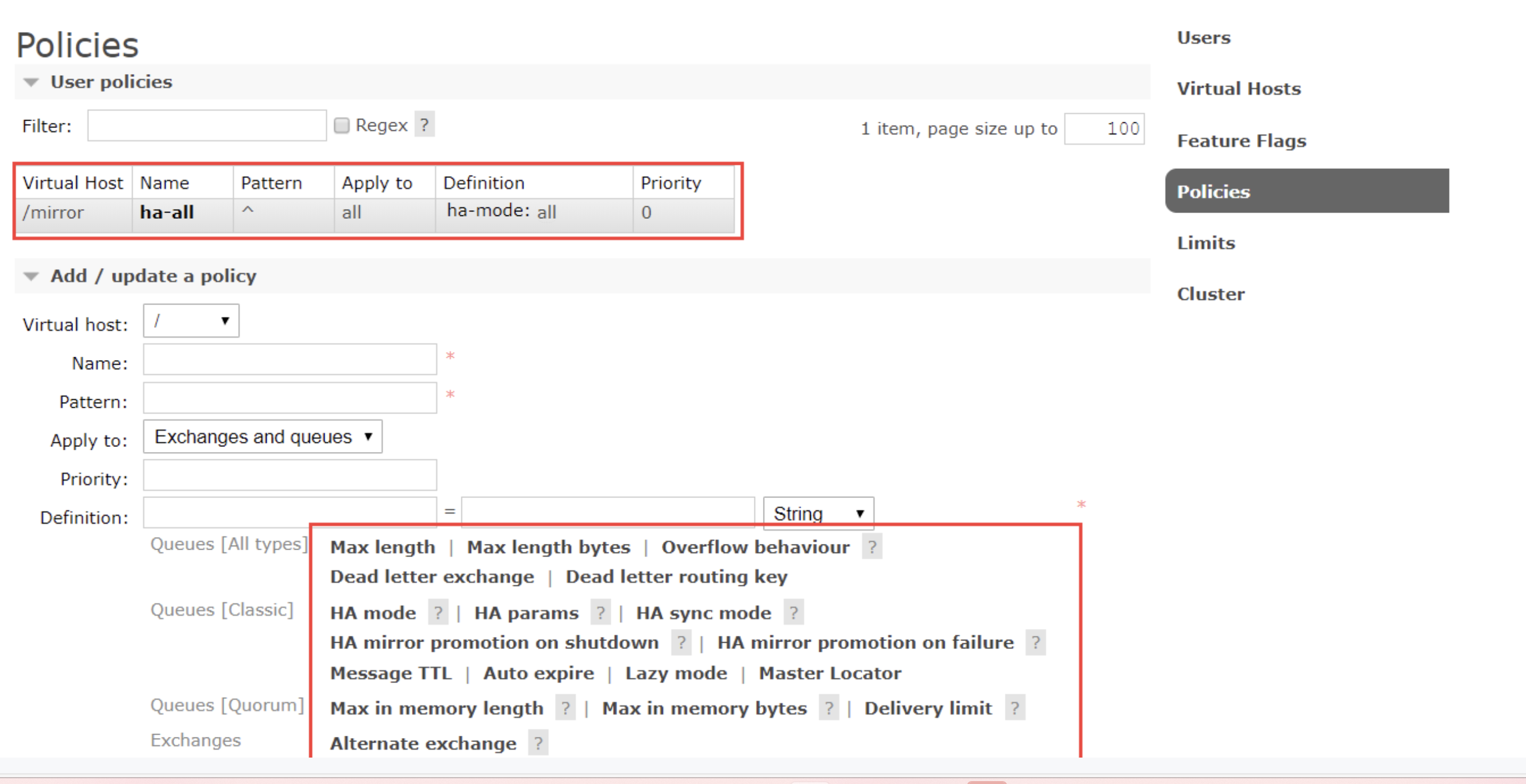
这些参数需要大致了解下。其中,pattern是队列的匹配规则, ^表示全部匹配。 ^ ha \ 这样的配置表示以ha开头。通常就用虚拟主机来区分就够了,这个队列匹配规则就配置成全匹配。
然后几个关键的参数:
HA mode: 可选值 all , exactly, nodes。生产上通常为了保证高可用,就配all
- all : 队列镜像到集群中的所有节点。当新节点加入集群时,队列也会被镜像到这个节点。
- exactly : 需要搭配一个数字类型的参数(ha-params)。队列镜像到集群中指定数量的节点。如果集群内节点数少于这个数字,则队列镜像到集群内的所有节点。如果集群内节点少于这个数,当一个包含镜像的节点停止服务后,新的镜像就不会去另外找节点进行镜像备份了。
- nodes: 需要搭配一个字符串类型的参数。将队列镜像到指定的节点上。如果指定的队列不在集群中,不会报错。当声明队列时,如果指定的所有镜像节点都不在线,那队列会被创建在发起声明的客户端节点上。
还有其他很多参数,可以后面慢慢再了解。
常见的高可用集群方案
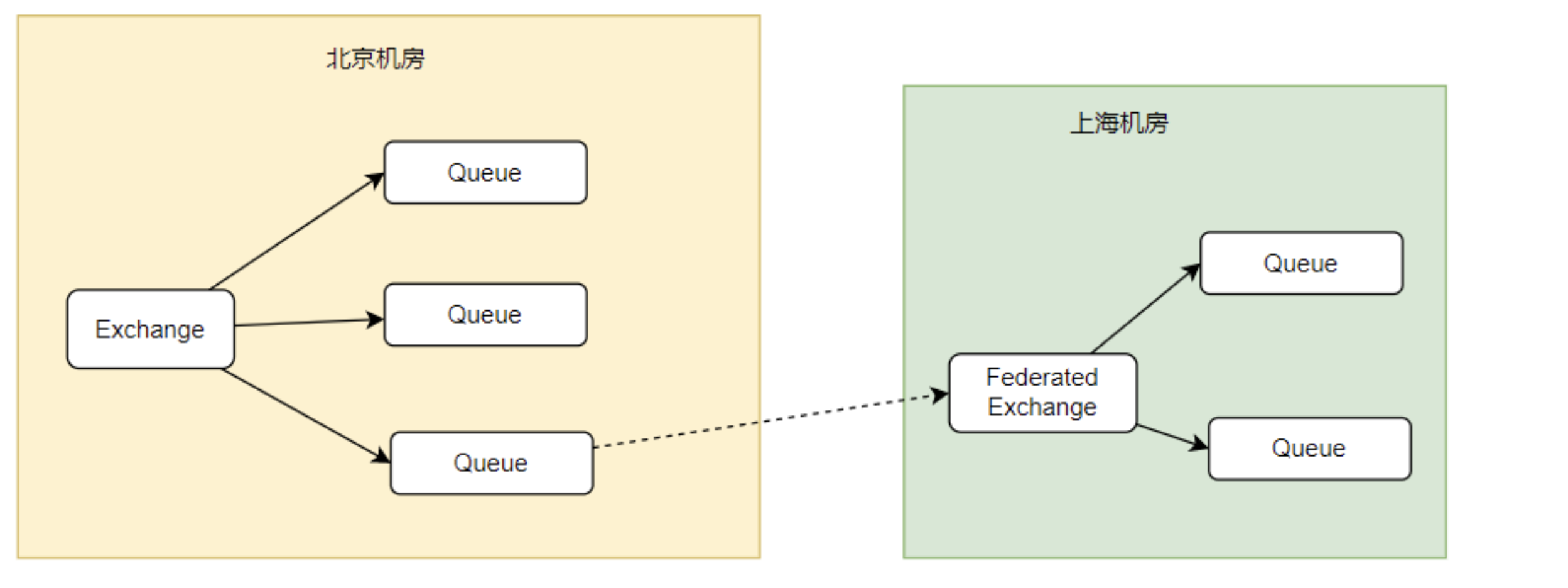
使用Federation联邦插件给关键的RabbitMQ服务搭建一个备份服务
镜像集群+Haproxy+keepalived
有了镜像集群之后,客户端应用就可以访问RabbitMQ集群中任意的一个节点了。但是,不管访问哪个服务,如果这个服务崩溃了,虽然RabbitMQ集群不会丢失消息,另一个服务也可以正常使用,但是客户端还是需要主动切换访问的服务地址。
为了防止这种情况情况,可以在RabbitMQ之前部署一个Haproxy,这是一个TCP负载均衡工具。应用程序只需要访问haproxy的服务端口,Haproxy会将请求以负载均衡的方式转发到后端的RabbitMQ服务上。
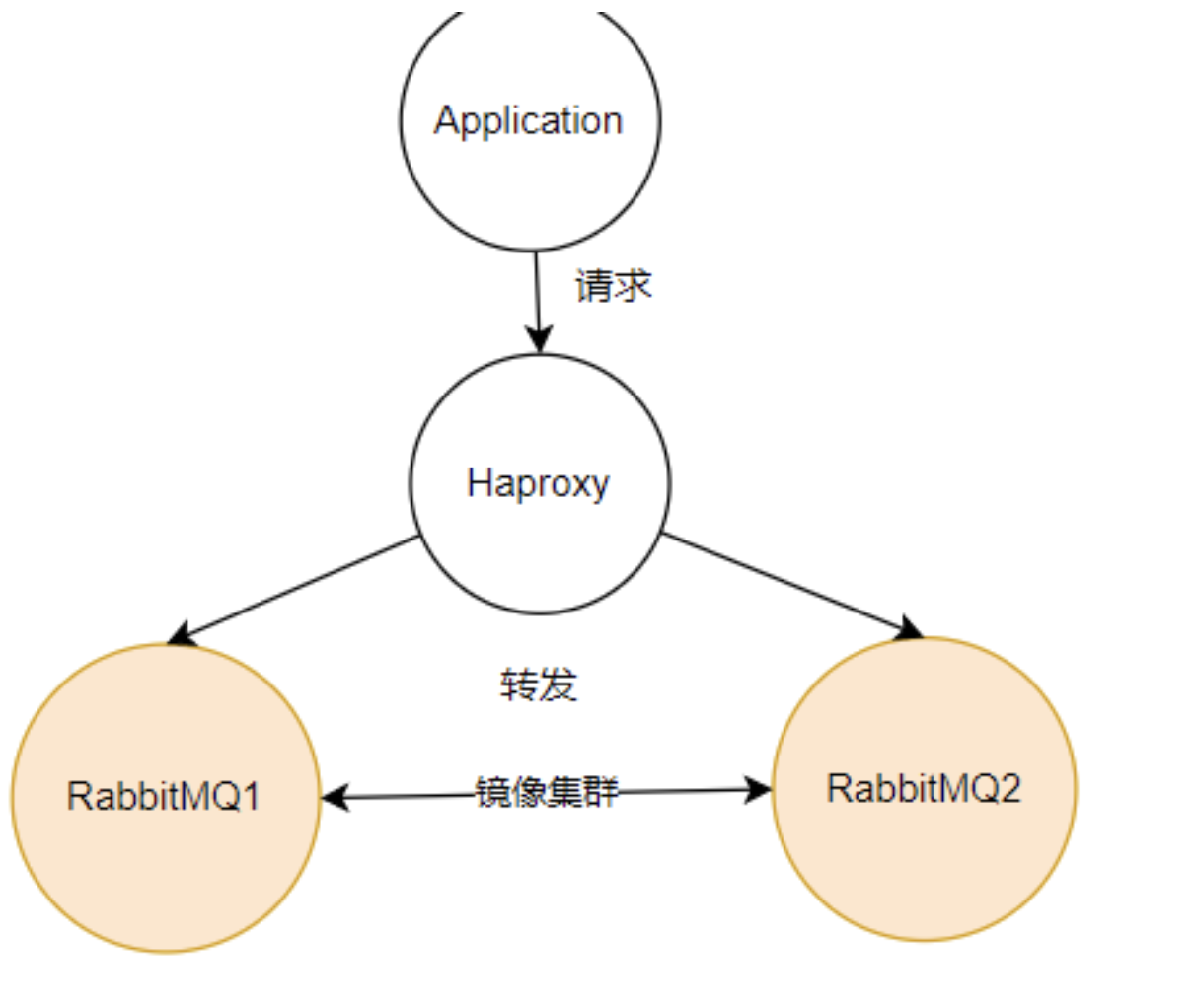
有了haproxy后,如果某一个RabbitMQ服务崩溃了,Haproxy会将请求往另外一个RabbitMQ服务转发,这样应用程序就不需要做IP切换了。此时,对于RabbitMQ来说,整个集群的服务是稳定的。
Haproxy是一个免费开源的负载均衡工具。类似的工具还有很多,比如F5,nginx等。
RabbitMQ 的备份
- abbitMQ有一个data目录会保存分配到该节点上的所有消息。
我们的实验环境中,默认是在/var/lib/rabbitmq/mnesia目录下这个目录里面的备份分为两个部分,一个是元数据(定义结构的数据),一个是消息存储目录。

而对于消息,可以手动进行备份恢复
其实对于消息,由于MQ的特性,是不建议进行备份恢复的。而RabbitMQ如果要进行数据备份恢复,也非常简单。
首先,要保证要恢复的RabbitMQ中已经有了全部的元数据,这个可以通过上一步的json文件来恢复。
然后,备份过程必须要先停止应用。如果是针对镜像集群,还需要把整个集群全部停止。
最后,在RabbitMQ的数据目录中,有按virtual hosts组织的文件夹。你只需要按照虚拟主机,将整个文件夹复制到新的服务中即可。持久化消息和非持久化消息都会一起备份。 我们实验环境的默认目录是/var/lib/rabbitmq/mnesia/rabbit@worker2/msg_stores/vhosts
RabbitMQ 如何保证消息不丢失
- 先确认哪些环节会有丢消息的可能
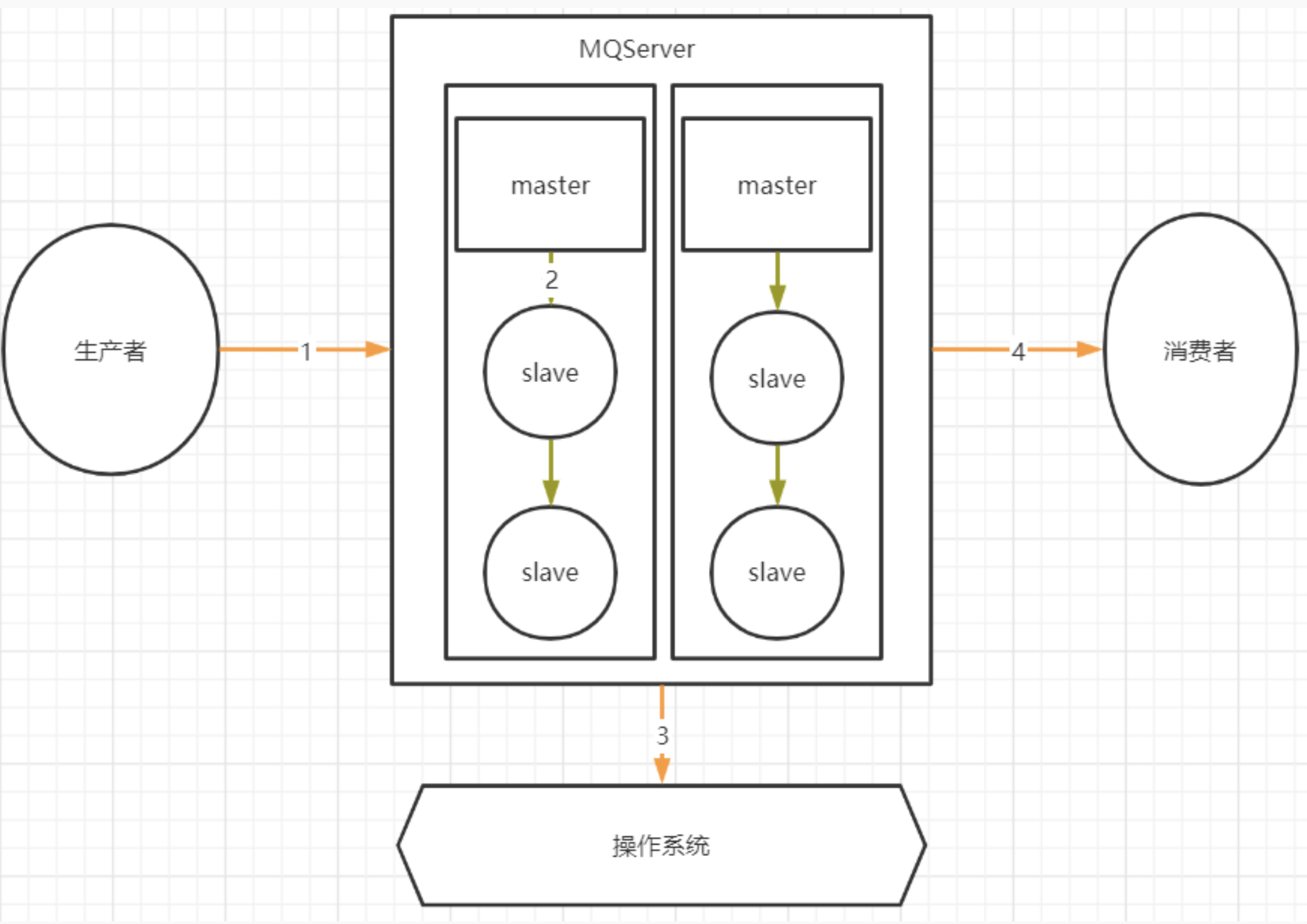
其中,1,2,4三个场景都是跨网络的,而跨网络就肯定会有丢消息的可能。
然后关于3这个环节,通常MQ存盘时都会先写入操作系统的缓存page cache中,然后再由操作系统异步的将消息写入硬盘。这个中间有个时间差,就可能会造成消息丢失。如果服务挂了,缓存中还没有来得及写入硬盘的消息就会丢失。这也是任何用户态的应用程序无法避免的。
对于任何MQ产品,都应该从这四个方面来考虑数据的安全性。那我们看看用RabbitMQ时要如何解决这个问题。
- RabbitMQ 消息零丢失的方案
- 生产者保证消息正确发送到RabbitMQ
RabbitMQ的生产者确认机制分为同步确认和异步确认。同步确认主要是通过在生产者端使用Channel.waitForConfirmsOrDie()指定一个等待确认的完成时间。异步确认机制则是通过channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2)在生产者端注入两个回调确认函数。第一个函数是在生产者消息发送成功时调用,第二个函数则是生产者消息发送失败时调用。两个函数需要通过sequenceNumber自行完成消息的前后对应。sequenceNumber的生成方式需要通过channel的序列获取。int sequenceNumber = channel.getNextPublishSeqNo();
- RabbitMQ 消息存盘不丢失
这个在RabbitMQ中比较好处理,对于Classic经典队列,直接将队列声明成为持久化队列即可。而新增的Quorum队列和Stream队列,都是明显的持久化队列,能更好的保证服务端消息不会丢失
- RabbitMQ 主从消息同步时不丢失
首先他的普通集群模式,消息是分散存储的,不会主动进行消息同步了,是有可能丢失消息的。而镜像模式集群,数据会主动在集群各个节点当中同步,这时丢失消息的概率不会太高。
另外,启用Federation联邦机制,给包含重要消息的队列建立一个远端备份,也是一个不错的选择。
- RabbitMQ 消费者不丢失消息
RabbitMQ在消费消息时可以指定是自动应答,还是手动应答。如果是自动应答模式,消费者会在完成业务处理后自动进行应答,而如果消费者的业务逻辑抛出异常,RabbitMQ会将消息进行重试,这样是不会丢失消息的,但是有可能会造成消息一直重复消费。
channel.basicConsume(queueName, false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
BasicProperties properties, byte[] body)
throws IOException {
long deliveryTag = envelope.getDeliveryTag();
channel.basicAck(deliveryTag, false);
}
});
channel.basicConsume(queueName, true, myconsumer);
另外这个应答模式在SpringBoot集成案例中,也可以在配置文件中通过属性spring.rabbitmq.listener.simple.acknowledge-mode 进行指定。可以设定为 AUTO 自动应答; MANUAL 手动应答;NONE 不应答; 其中这个NONE不应答,就是不启动应答机制,RabbitMQ只管往消费者推送消息后,就不再重复推送消息了,相当于RocketMQ的sendoneway, 这样效率更高,但是显然会有丢消息的可能。
e. 任何用户态的应用程序都无法保证绝对的数据安全,所以,备份与恢复的方案也需要考虑到。
如何保证消息的幂等
RabbitMQ的重试机制
当消费者消费消息处理业务逻辑时,如果抛出异常,或者不向RabbitMQ返回响应,默认情况下,RabbitMQ会无限次数的重复进行消息消费。
处理幂等问题,首先要设定RabbitMQ的重试次数。在SpringBoot集成RabbitMQ时,可以在配置文件中指定spring.rabbitmq.listener.simple.retry开头的一系列属性,来制定重试策略。
然后,需要在业务上处理幂等问题
处理幂等问题的关键是要给每个消息一个唯一的标识。
在SpringBoot框架集成RabbitMQ后,可以给每个消息指定一个全局唯一的MessageID,在消费者端针对MessageID做幂等性判断。
关键代码:
ssage message2 = MessageBuilder.withBody(message.getBytes()).setMessageId(UUID.randomUUID().toString()).build();
rabbitTemplate.send(message2);
//消费者获取MessageID,自己做幂等性判断
@RabbitListener(queues = "fanout_email_queue")
public void process(Message message) throws Exception {
// 获取消息Id
String messageId = message.getMessageProperties().getMessageId();
...
}
要注意下这里用的message要是org.springframework.amqp.core.Message
在原生API当中,也是支持MessageId的。当然,在实际工作中,最好还是能够添加一个具有业务意义的数据作为唯一键会更好,这样能更好的防止重复消费问题对业务的影响。比如,针对订单消息,那就用订单ID来做唯一键。在RabbitMQ中,消息的头部就是一个很好的携带数据的地方。
// ==== 发送消息时,携带sequenceNumber和orderNo
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.deliveryMode(MessageProperties.PERSISTENT_TEXT_PLAIN.getDeliveryMode());
builder.priority(MessageProperties.PERSISTENT_TEXT_PLAIN.getPriority());
//携带消息ID
builder.messageId(""+channel.getNextPublishSeqNo());
Map<String, Object> headers = new HashMap<>();
//携带订单号
headers.put("order", "123");
builder.headers(headers);
channel.basicPublish("", QUEUE_NAME, builder.build(), message.getBytes("UTF-8"));
// ==== 接收消息时,拿到sequenceNumber
Consumer myconsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
BasicProperties properties, byte[] body)
throws IOException {
//获取消息ID
System.out.println("messageId:"+properties.getMessageId());
//获取订单ID
properties.getHeaders().forEach((key,value)-> System.out.println("key: "+key +"; value: "+value));
// (process the message components here ...)
//消息处理完后,进行答复。答复过的消息,服务器就不会再次转发。
//没有答复过的消息,服务器会一直不停转发。
channel.basicAck(deliveryTag, false);
}
};
channel.basicConsume(QUEUE_NAME, false, myconsumer);
如何保证消息的顺序’
在某些场景下,需要保证消息顺序,例如:
- 一个下单的过程,需要先完成扣款,然后减库存,最后通知快递发货。
这个顺序不能乱,如果 每个步骤都是异步的话,那这一组消息就必须保证他们的消费顺序是一致的。
但是在RabbitMQ当中,针对消息顺序的设计是比较弱的,唯一比较好的策略就是 单队列+单消息推送。即一组有序的消息 ,只能发送到一个消息队列中,利用队列的FIFO机制来保证消息顺序不能错乱。但是这种方式是以极度消耗性能为代价的。一般情况应该尽可能的避免这种场景。
然后在消费者进行消费时,保证只有一个消费者,同时指定prefetch属性为1,即每次RabbitMQ都只往客户端推送一个消息。像这样:
spring.rabbitmq.listener.simple.prefetch=1
而在多队列情况下,如何保证消息的顺序性,目前使用RabbitMQ的话,还没有比较好的解决方案。在使用时,应该尽量避免这种情况。
关于RabbitMQ的数据堆积问题
RabbitMQ一直以来都有一个缺点,就是对于消息堆积问题的处理不好。当RabbitMQ中有大量消息堆积时,整体性能会严重下降。而目前新推出的Quorum队列以及Stream队列,目的就在于解决这个核心问题。但是这两种队列的稳定性和周边生态都还不够完善,目前大部分企业还是围绕Classic经典队列构建应用。因此,在使用RabbitMQ时,还是要非常注意消息堆积的问题。尽量让消息的消费速度和生产速度保持一致。
而如果确实出现了消息堆积比较严重的场景,就需要从数据流转的各个环节综合考虑,设计适合的解决方案。
首先在消息生产者端:
对于生产者端,最明显的方式自然是降低消息生产的速度。但是,生产者端产生消息的速度通常是跟业务息息相关的,一般情况下不太好直接优化。但是可以选择尽量多采用批量消息的方式,降低IO频率。
然后在RabbitMQ服务端:
从前面的分享中也能看出,RabbitMQ本身其实也在着力于提高服务端的消息堆积能力。对于消息堆积严重的队列,可以预先添加懒加载机制,或者创建Sharding分片队列,这些措施都有助于优化服务端的消息堆积能力。另外,尝试使用Stream队列,也能很好的提高服务端的消息堆积能力。
接下来在消息消费者端:
要提升消费速度最直接的方式,就是增加消费者数量了。尤其当消费端的服务出现问题,已经有大量消息堆积时。这时,可以尽量多的申请机器,部署消费端应用,争取在最短的时间内消费掉积压的消息。但是这种方式需要注意对其他组件的性能压力。
对于单个消费者端,可以通过配置提升消费者端的吞吐量。例如
# 单次推送消息数量
spring.rabbitmq.listener.simple.prefetch=1
# 消费者的消费线程数量
spring.rabbitmq.listener.simple.concurrency=5
灵活配置这几个参数,能够在一定程度上调整每个消费者实例的吞吐量,减少消息堆积数量。
当确实遇到紧急状况,来不及调整消费者端时,可以紧急上线一个消费者组,专门用来将消息快速转录。保存到数据库或者Redis,然后再慢慢进行处理。
















 3194
3194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











