






动态规划思想:用后续状态估算当前状态,即用上一轮的数据估算下一轮的数据。
基于动态规划的强化学习算法主要有两种:一是策略迭代,二是价值迭代。
一、 策略迭代
策略迭代由两部分组成,策略评估和策略提升。策略评估用于评估给定策略下的状态价值函数,策略提升用于在给定状态函数下优化策略。
1. 策略评估
目标:给定策略下,通过初始样本和环境进行交互,推测该策略对应的每一个状态的价值函数。
条件:状态转移概率已知,奖励已知
价值函数更新:已知动作空间、状态转移概率、各状态的奖励,随机初始化一个策略、初始各个状态的价值函数为0,根据策略基于上述环境遍历计算一轮各状态的价值函数。然后更新后的价值状态函数和原来的差异不大,那么直接估算出状态价值函数;否则继续拿更新后的状态价值函数做新一轮的更新。 其中,基于下式我们可以对状态价值函数进行更新,也就是可以用上一轮的状态价值函数去重新计算新的状态价值函数。
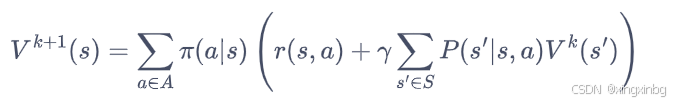
2. 策略提升
目标:已知状态价值函数,基于已知的策略,求解出一个较优的确定性策略(非随机策略),在该确定性策略下个各状态能够获得更高的状态价值函数
条件:状态价值函数已知,状态转移矩阵已知,奖励已知
策略提升:由于状态价值函数已知,我们可以推导出每个状态下各个动作的动作价值函数。所以这个较优的确定性策略就是,在每个状态下执行动作价值函数最大的那个动作。
3. 策略迭代
策略迭代的思想是,随机初始化一个策略,通过策略评估确定基于该策略的状态价值函数,然后基于该状态价值函数进行策略提升求解出更优的策略,再基于这个更优的策略求解新的状态价值函数...直到求解出的新策略和旧策略相同,表示收敛。
二、 价值迭代
策略迭代的缺点:多次策略评估收敛性太慢,计算量大
价值迭代的思路:将策略提升融入策略评估中,即在策略评估中没有固定的策略,在每一轮的价值函数迭代过程,也都是策略向更优更新过程,直到价值函数收敛表示策略已达到最优,最后由价值函数倒退策略函数即可。
每个价值函数迭代过程如下函数更新,即用旧一轮的价值函数评估更优策略下的新价值函数
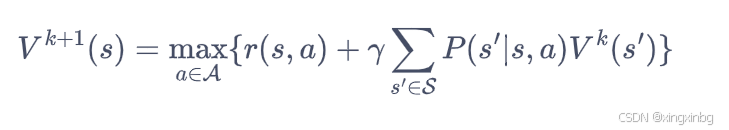


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









