







 本文详细介绍了如何在Windows环境下配置MapReduce的本地运行模式,包括基础环境配置和代码数据准备。通过本地模式,可以简化程序的调试过程,避免了打包、上传和数据准备到HDFS的复杂步骤。内容涵盖了环境配置的四个步骤,以及Mapper、Reducer、Driver代码的编写,并指导在maven工程中设置输入和输出路径。
本文详细介绍了如何在Windows环境下配置MapReduce的本地运行模式,包括基础环境配置和代码数据准备。通过本地模式,可以简化程序的调试过程,避免了打包、上传和数据准备到HDFS的复杂步骤。内容涵盖了环境配置的四个步骤,以及Mapper、Reducer、Driver代码的编写,并指导在maven工程中设置输入和输出路径。
本地运行模式将给mapreduce程序编写与调试带来极大遍历,不然还要打包、上传、数据准备到hdfs等多步骤,很是耗时。这里的本地是程序在本地运行,同时输入数据和输入数据也是在本地。同时还可以进行断点debug。
一、基础环境配置
要在本地运行,需要配置windows所需的运行库,步骤如下:
1、下载解压hadoop-common-2.6.0-bin-master
我的路径是:D:\installs\hadoop-common-2.6.0-bin-master
下载链接:https://github.com/steveloughran/winutils
2、将路径配置到环境变量
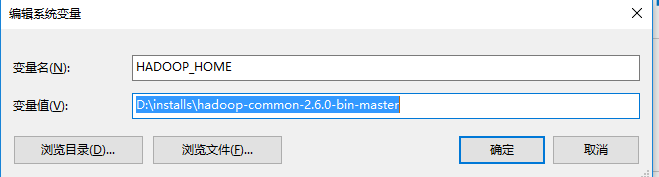
3、将bin添加到Path
![]()
4、将bin中的hadoop.dll复制到C:\Windows\System32
二、代码及数据
Mapper
package com.bigdata.train.practice.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @ Author:
* @ Description:
* @ Date:17:57 2019/6/10
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3547
3547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









