







文章目录
参考牛客网高级项目教程
狂神说Elasticsearch教程笔记
尚硅谷Elasticsearch教程笔记
1. 认识Elasticsearch
1. Elasticsearch简介
- Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了具有 HTTP Web 界面和无架构 JSON
文档的分布式,多租户能力的全文搜索引擎。 Elasticsearch 是用 Java 开发的,根据 Apache 许可
条款作为开源发布

- 一个分布式的、Restful风格的搜索引擎。
- 支持对各种类型的数据的检索。
- 能够安全可靠地获取任何来源、任何格式的数据,
- 然后实时地对数据进行搜索、分析和可视化。
- 搜索速度快,可以提供实时的搜索服务。
- 便于水平扩展。
- 本身扩展性很好,可以扩展到上百台服务器,
- 处理 PB 级别的数据
2. ES特点-为何使用ES
2.1 全文搜索引擎
目前主流网站搜索策略
- Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,
- 我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;
- 对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
传统数据库的问题
-
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。
- 进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。
- 建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
-
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
问题解决策略及全文搜索引擎的原理
- 为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎 。
- 它的工作原理:
- 计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,
- 指明该词在文章中出现的次数和位置,
- 因为文本出现的次数越多那么就越匹配,越匹配的话得分就越高。就会拍到越前面去。
- 记录出现的位置是为了以后高亮显示的时候用的
- 当用户查询时,检索程序就根据事先建立的索引进行查找,
- 并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
2.2 Elasticsearch 与 Solr
Lucene
- 它们都是围绕核心底层搜索库 - Lucene构建的
- 由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,
- 对于数据的操作 修改、添加、保存、查询等等都十分类似

优点和缺点比较
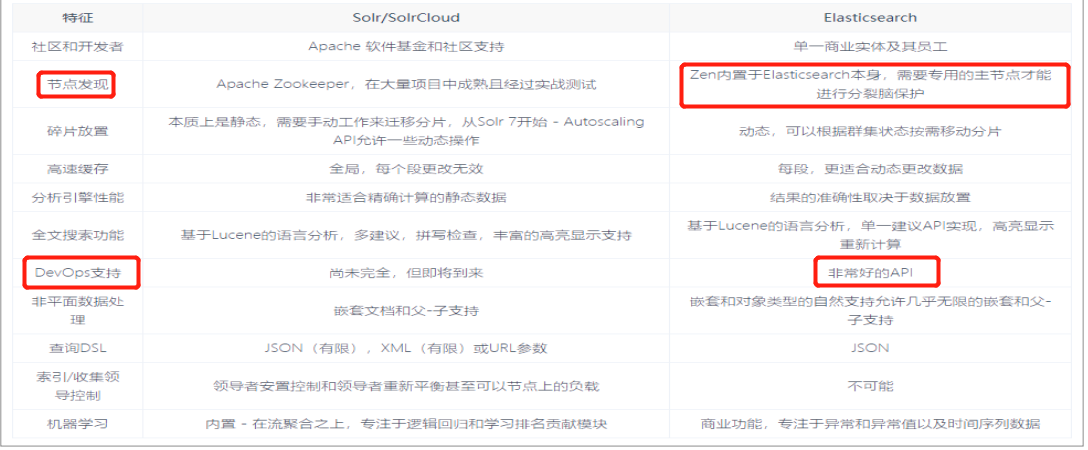
- 1、es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
- 2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
- 3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
- 4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提
供,例如图形化界面需要kibana友好支撑 - 5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
- 6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,
- 而 Elasticsearch相对开发维护者较少,发展更快
2.3 为何使用Elasticsearch
-
系统中的数据, 随着业务的发展,时间的推移, 将会非常多,
-
而业务中往往采用模糊查询进行数据的搜索, 而模糊查询会导致查询引擎放弃索引,导致系统查询数据时都是全表扫描,在百万级别的数据库中,查询效率是非常低下的,
-
而我们使用 ES 做一个全文索引,将经常查询的系统功能的某些字段,
-
例如本项目中的帖子,帖子的数据放进ES索引库里,可以根据帖子主题和内容的关键字快速查询
-
比如说电商系统的商品表中商品名,描述、价格还有 id 这些字段我们放入 ES 索引库里,可以提高查询速度。
-
3. ES核心概念
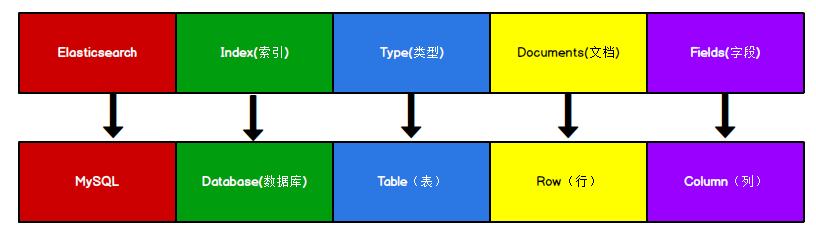
版本区别
- ES7.几的时候 Type 就用使用-doc 来代替,即Type逐渐弱化,索引对应一张表
- 到了 8.几的时候就使用。一条 document 对象就代表的一条记录。
3.1 索引Index
基本概念
-
一个索引就是一个拥有几分相似特征的文档的集合。
- 比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
- 一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除(CRUD)的时候,都要使用到这个名字。
- 在一个集群中,可以定义任意多的索引。
-
能搜索的数据必须索引,这样的好处是可以提高查询速度,
- 比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。
Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能。
物理设计
-
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,
-
如果你创建索引,那么索引将会有个多个个分片 ( primary shard ,又称主分片 ) 构成的
- 即有多个空间来存
-
每一个主分片会有一个副本 ( replica shard ,又称复制分片 )
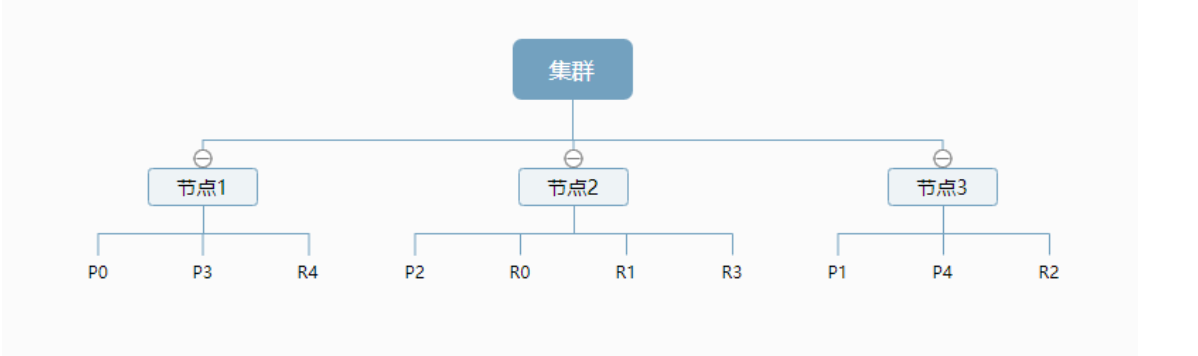
-
elasticsearch 在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
-
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某
个节点挂掉 了,数据也不至于丢失。 -
实际上,一个分片是一个Lucene索引,
- 一个包含倒排索引的文件目录,
- 倒排索引的结构使 得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
逻辑设计
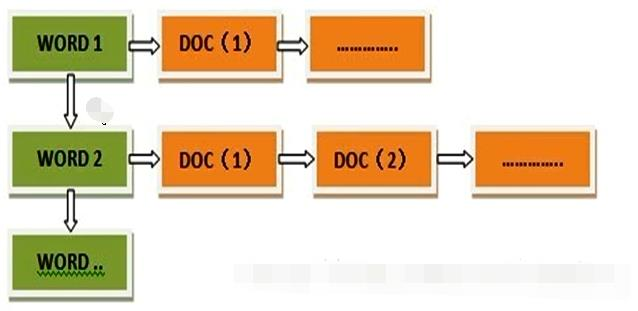
- 一个索引类型中,包含多个文档,比如说文档1,文档2。
- 当我们索引一篇文档时,可以通过这样的一各顺序找到 它: 索引 ▷ 类型 ▷ 文档ID ,
- 通过这个组合我们就能索引到某个具体的文档。 注意**:ID不必是整数,实际上它是个字 符串**
倒排索引
- 传统的数据库每个字段存储单个值,但这对全文检索并不够。
- 文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值的能力。
- 最好的支持是==一个字段多个值需求的数据结构是倒排索引==。
倒排索引原理
-
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
-
见其名,知其意,有倒排索引,肯定会对应有正向索引。正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
-
所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。
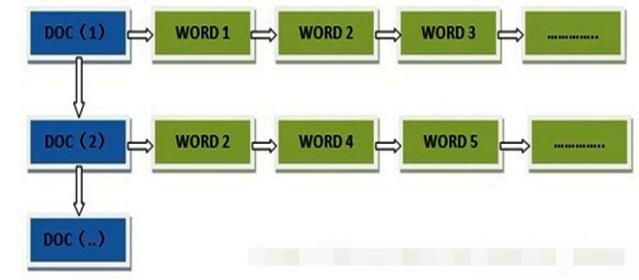
-
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,
-
即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
3.2 类型Type
-
在一个索引中,你可以定义一种或多种类型。
-
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。
-
不同的版本,类型发生了不同的变化。
版本 Type 5.x 支持多种 type 6.x 只能有一种 type 7.x 默认不再支持自定义索引类型(默认类型为: _doc)
-
3.3 文档Document
-
一个文档是一个可被索引的基础信息单元,也就是一条数据。
- 比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。
-
文档以JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。
-
在一个 index/type 里面,你可以存储任意多的文档。
3.4 字段Field
- 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
3.5 集群
- 由各台服务器组成
- 一个集群就是==由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能==。
3.6 节点
- 每一台服务器
- 而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的
3.7 分片Shards
-
一个索引可以存储超出单个节点硬件限制的大量数据。
比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。 为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。 当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的`索引`,这个`索引`可以被放置到集群中的任何节点上。 -
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
- 至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
-
被混淆的概念是,
- 一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。
- 一个Elasticsearch 索引 是分片的集合。
- 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
3.8 副本Replicas
-
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于
离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的, Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。 -
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。
- 因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
- 在分片/节点失败的情况下,提供了高可用性。
-
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
3.9 分配Allocation
- 将分片分配给某个节点的过程,
- 包括分配主分片或者副本。
- 如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
3.10 映射Mapping
-
mapping 是处理数据的方式和规则方面做一些限制
如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的, 其它就是处理 ES 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
2. ES的安装配置与插件安装
1. ES的Windows安装
-
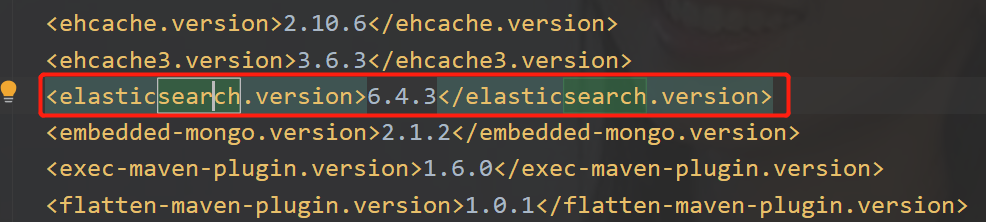
1、因项目中之前用的SpringBoot版本兼容的是6.3.0的版本,因此,也下载安装此版本
-
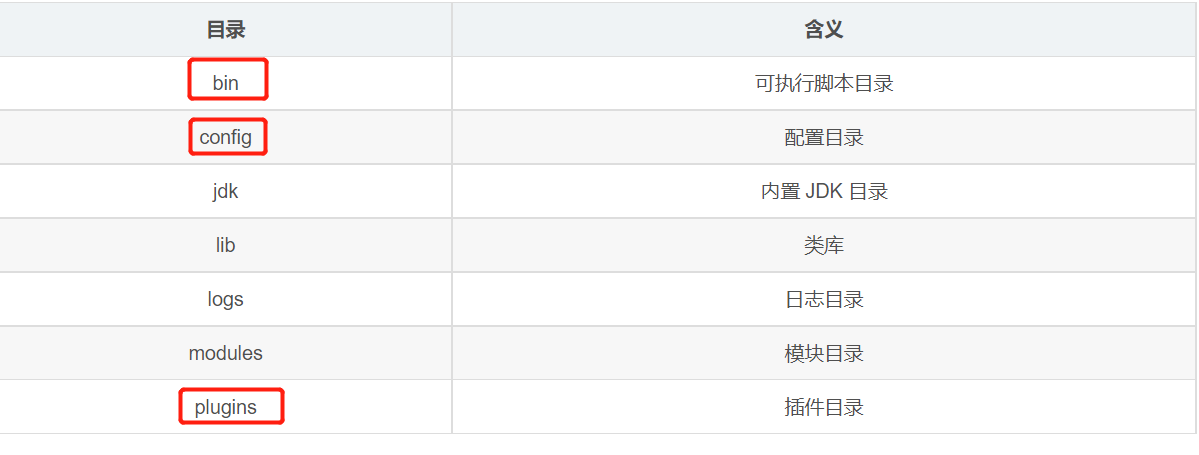
2、Windows 版的 Elasticsearch 压缩包,解压即安装完毕,解压后的 Elasticsearch 的目录结构如下 :
-
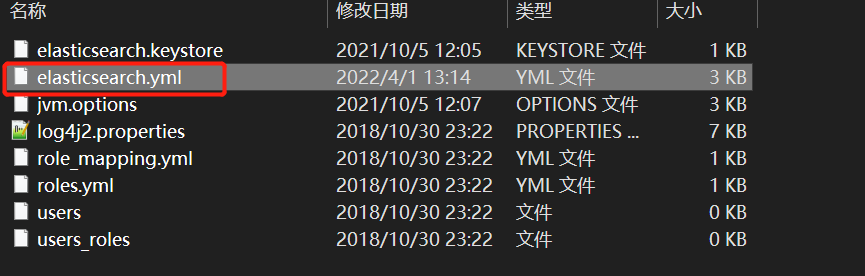
3、修改配置文件-配置集群名、数据库文件储存位置以及日志存放位置
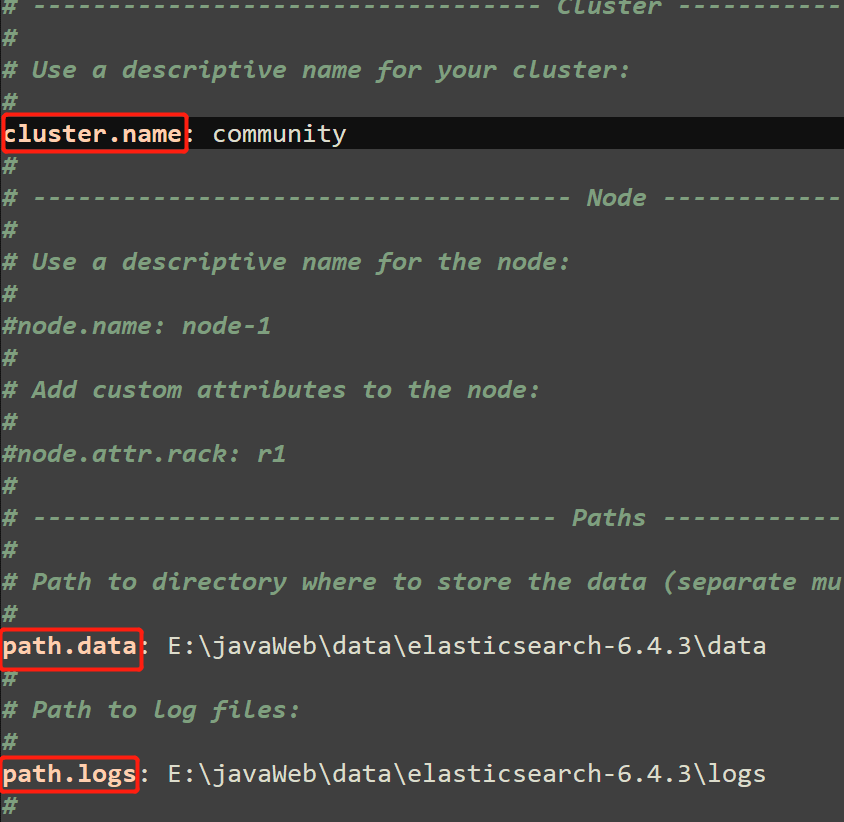
-
4、注意:
- 9300 端口为 Elasticsearch 集群间组件的通信端口
- 9200 端口为浏览器访问的 http协议 RESTful 端口。
-
5、配置环境变量-方便快速在cmd操作ES
elasticsearch.bat
-
6、进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务
- 打开浏览器,输入地址: http://localhost:9200,测试返回结果,返回结果如下:
{ "name" : "j8dm6vN", "cluster_name" : "community", "cluster_uuid" : "_-2NBqCVQgOJF68t3N-R7A", "version" : { "number" : "6.4.3", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "fe40335", "build_date" : "2018-10-30T23:17:19.084789Z", "build_snapshot" : false, "lucene_version" : "7.4.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
2. IK分词器插件 的安装
2.1 什么是IK分词插件
-
分词:即把一段中文或者别的划分成一个个的关键字,
我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作, 默认的中文分词是将每个字看成一个词,比如 "互联网春招" 会被分为"互","联","网" "招","聘",这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。 -
IK提供了两个分词算法:
-
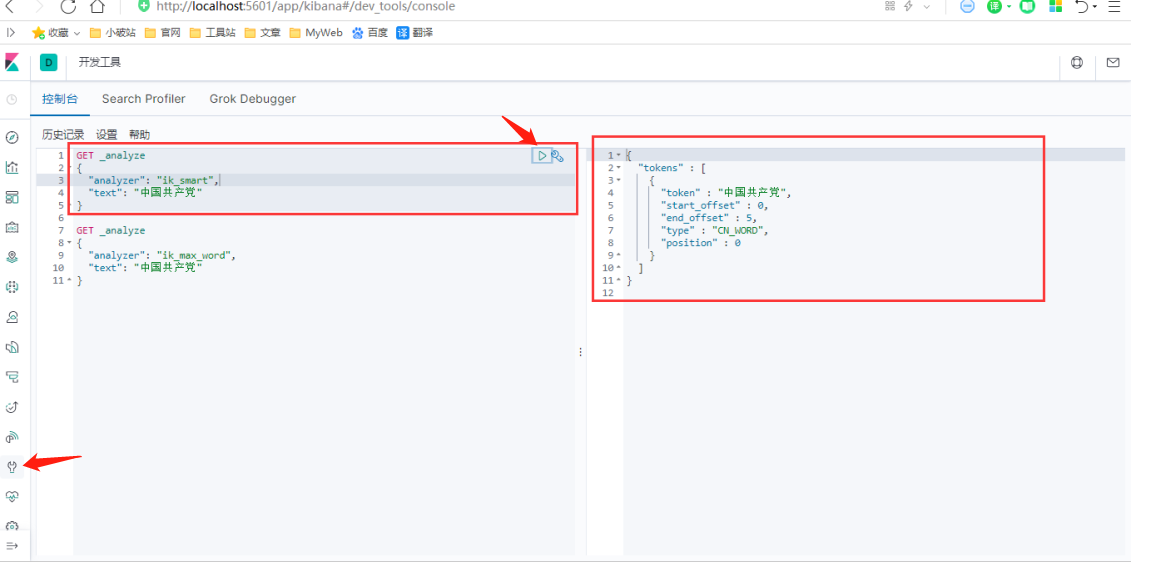
ik_smart
-
ik_smart 为最少切分,优先匹配最长词 ,一般用作查询时的分词匹配,可以减少查询范围
-
-
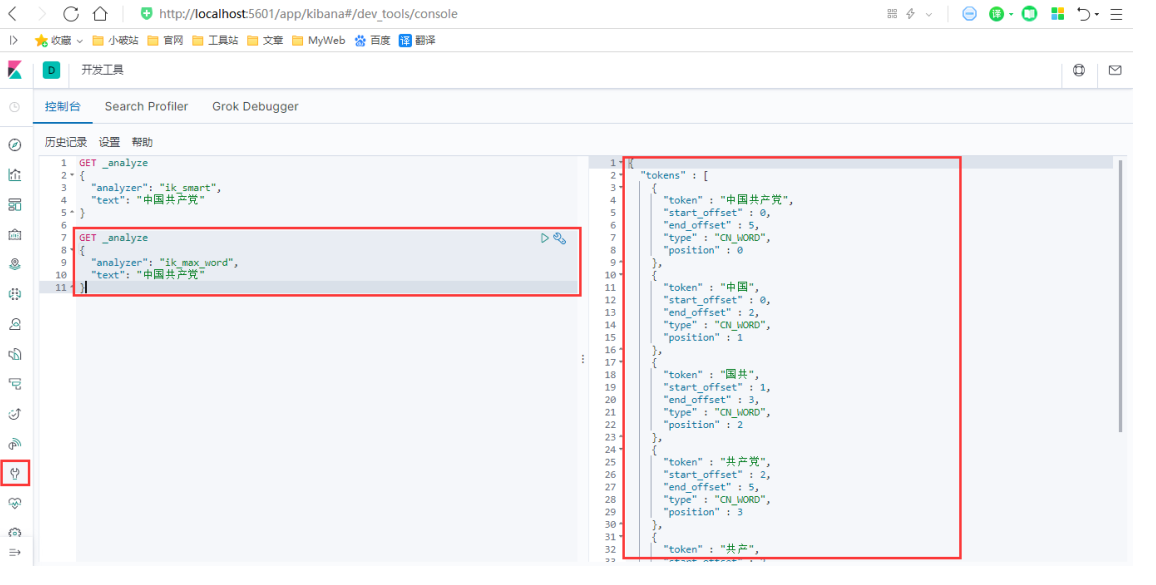
ik_max_word
-
ik_max_word为最细粒度划分!,一般用作储存文档时的分词匹配,尽可能储存更多可能的搜索数据
-
-
2.2 分词器的安装
-
1、下载ik分词器的包,Github地址:https://github.com/medcl/elasticsearch-analysis-ik/
- (版本要对应)
-
2、下载后解压,并将目录拷贝到ElasticSearch根目录下的 plugins 目录中。
-
3、启动 ElasticSearch 服务,在启动过程中,你可以看到正在加载"analysis-ik"插件的提示信息,
- 服务启动后,在命令行运行 elasticsearch-plugin list 命令,确认 ik 插件安装成功。
2.3 自定义分词器的词库
步骤:
-
(1)进入elasticsearch/plugins/ik/config目录
-
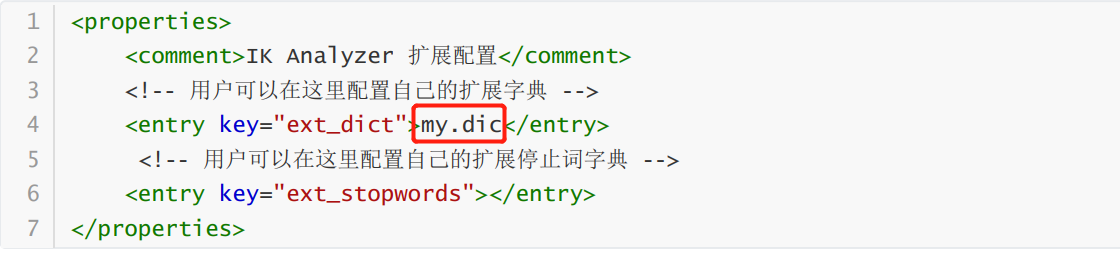
(2)新建一个my.dic文件,编辑要添加的自定义词语
-
(3)修改IKAnalyzer.cfg.xml(在ik/config目录下)
- 修改完配置重新启动elasticsearch,再次测试!
发现监视了我们自己写的规则文件:

- 修改完配置重新启动elasticsearch,再次测试!
3. 安装Postman客户端工具
-
如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。
-
软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。 Postman 中文版能够发送任何类型的 HTTP 请求 (GET, HEAD, POST, PUT…),不仅能够表单提交,且可以附带任意类型请求体。
3. ES的使用测试
3.1 RESTful 风格说明
-
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。
-
它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
-
在服务器端,应用程序状态和功能可以分为各种资源
资源是一个有趣的概念实体,它向客户端公开。 资源的例子有:应用程序对象、数据库记录、算法等等。 每个资源都使用 URI(Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、 PUT、 POST 和DELETE。 -
在 REST 样式的 Web 服务中,每个资源都有一个地址。
资源本身都是方法调用的目标,方法列表对所有资源都是一样的。 这些方法都是标准方法,包括 HTTP GET、 POST、PUT、 DELETE,还可能包括 HEAD 和 OPTIONS。 简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径, 以及对资源进行的操作(增删改查)。 -
REST 样式的 Web 服务若有返回结果,大多数以JSON字符串形式返回。
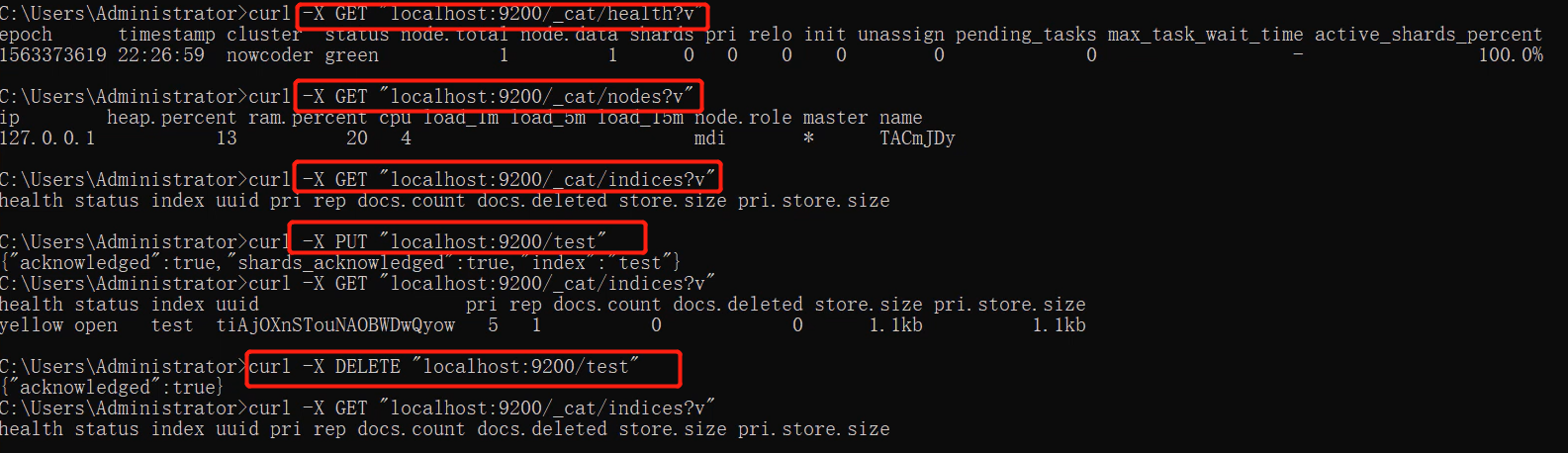
3.2 在cmd中操作ES
3.2 在Postman客户端基于Rest风格操作ES
索引-创建 PUT:
localhost:9200/索引名
- # 注意:创建索引库的分片数7.0后的版本默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片

- 如果重复发 PUT 请求 : localhost:9200/test 添加索引,会返回错误信息 :
索引-查询GET
localhost:9200/_cat/indices?v
-
在 Postman 中,向 ES 服务器发 GET 请求 : localhost:9200/_cat/indices?v
- 这里请求路径中的**_cat 表示查看的意思**, indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下 :


localhost:9200/单个索引
-
查看单个索引

索引-删除 DELETE
localhost:9200/test
- 删除指定索引
{
"acknowledged": true
}
文档-创建(Put & Post)
localhost:9200/索引名/_doc/文档id
localhost:9200/索引名/_doc
-
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/shopping/_doc/1,请求体JSON内容为:
-
如果没有创建索引,会自动创建主题
-
如果创建的文档,没有指定ID号,必须为POST请求,系统会自动创建随机id号
-
如果创建的文档,指定了ID号,必须为PUT请求
-
由于6之后的版本,逐渐弃用了类型,因此,统一类型设定为_doc
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
-
先在body中填入文档中要保存的数据

-
提交后的结果:
{ "_index": "shopping",//索引 "_type": "_doc", //类型-文档 "_id": "1", //唯一标识,可以类比为 MySQL 中的主键,未指定就随机生成 "_version": 1, //版本 "result": "created",//结果,这里的 create 表示创建成功 "_shards": { "total": 2, //分片 - 总数 "successful": 1, //分片 - 成功 "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
文档-查询 GET
localhost:9200/索引名/_doc/文档id
-
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
在 Postman 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_doc/1 。
返回结果如下:
{ "_index": "shopping", "_type": "_doc", "_id": "1", "_version": 1, "found": true, // true 表示查找到, false 表示未查找到 "_source": { "title": "小米手机", "category": "小米", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3999 } }
localhost:9200/索引名/_search
-
查看索引下所有数据,没有条件查询,即查询所有,
-
向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_search。
返回结果如下:
{ "took": 72, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 2, // 查询到几个文档数据-即几条数据 "max_score": 1, "hits": [ // 展示每条数据信息 { "_index": "shopping", "_type": "_doc", "_id": "1", "_score": 1, "_source": { "title": "小米手机", "category": "小米", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3999 } }, { "_index": "shopping", "_type": "_doc", "_id": "L4lJ5H8BkFmE3HU_nkTn", // POST请求,id随机生成 "_score": 1, "_source": { "title": "小米手机", "category": "小米", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3999 } } ] } }
文档-删除 DELETE
localhost:9200/索引名/_doc/文档id
-
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
-
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://127.0.0.1:9200/shopping/_doc/1
-
返回结果:
{ "_index": "shopping", "_type": "_doc", "_id": "1", "_version": 2, "result": "deleted", // 表示删除成功 "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 1 }
全量修改 & 局部修改 POST
全量修改
-
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
-
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/shopping/_doc/1
-
请求体JSON内容为:
{ "title":"华为手机", "category":"华为", "images":"http://www.gulixueyuan.com/hw.jpg", "price":1999.00 } -
修改成功后,服务器响应结果:
{ "_index": "shopping", "_type": "_doc", "_id": "1", "_version": 2, "result": "updated", // 表示更新完成 "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 4, "_primary_term": 1 }
局部修改
localhost:9200/索引名/_doc/1/_update
-
修改数据时,也可以只修改某一给条数据的局部信息
-
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/shopping/_update/1。
-
请求体JSON内容为:
{ "doc": { "title":"小米手机", "category":"小米" } } -
返回结果:
{ "_index": "shopping", "_type": "_doc", "_id": "1", "_version": 3, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 5, "_primary_term": 1 }
条件查询 & 分页查询 & 查询排序 GET
URL带参查询
-
查找category为小米的文档,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search?q=category:小米,返回结果如下:
{ "took": 59, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 2, // 查询两个结果 "max_score": 0.36464313, "hits": [ { "_index": "shopping", "_type": "_doc", "_id": "L4lJ5H8BkFmE3HU_nkTn", "_score": 0.36464313, "_source": { "title": "小米手机", "category": "小米", "images": "http://www.gulixueyuan.com/xm.jpg", "price": 3999 } }, { "_index": "shopping", "_type": "_doc", "_id": "1", "_score": 0.36464313, "_source": { "title": "小米手机", "category": "小米", "images": "http://www.gulixueyuan.com/hw.jpg", "price": 1999 } } ] } } -
上述为URL带参数形式查询,这很容易让不善者心怀恶意,或者参数值出现中文会出现乱码情况。为了避免这些情况,我们可用使用带JSON请求体请求进行查询。
请求体带参组合查询
-
接下带JSON请求体,还是查找category为小米的文档,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "query":{ "multi_match":{ "query":"小米" "fields":["title", "category"] } } }
分页查询
-
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "query":{ "match_all":{} }, "from":0, // 起始页 "size":2 // limit }
查询排序
-
如果你想通过排序查出价格最高的手机,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{ "query":{ "match_all":{} }, "sort":{ "price":{ "order":"desc" } } }















 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









