







 本文介绍了随机森林算法,通过使用多个决策树并进行有放回抽样创建随机训练集,增强了模型对数据变化的鲁棒性。随机森林通过特征子集选择和投票机制,使得单一决策树的弱点得以分散,从而提高预测准确性。
本文介绍了随机森林算法,通过使用多个决策树并进行有放回抽样创建随机训练集,增强了模型对数据变化的鲁棒性。随机森林通过特征子集选择和投票机制,使得单一决策树的弱点得以分散,从而提高预测准确性。
使用一个决策树对数据的小变化非常敏感,这时可以使用多个决策树,称树的集合(tree ensemble)。如下图,猫猫分类问题中,若改变一只猫的特征,得到的将是两种完全不同的决策树,这使算法没那么健壮。
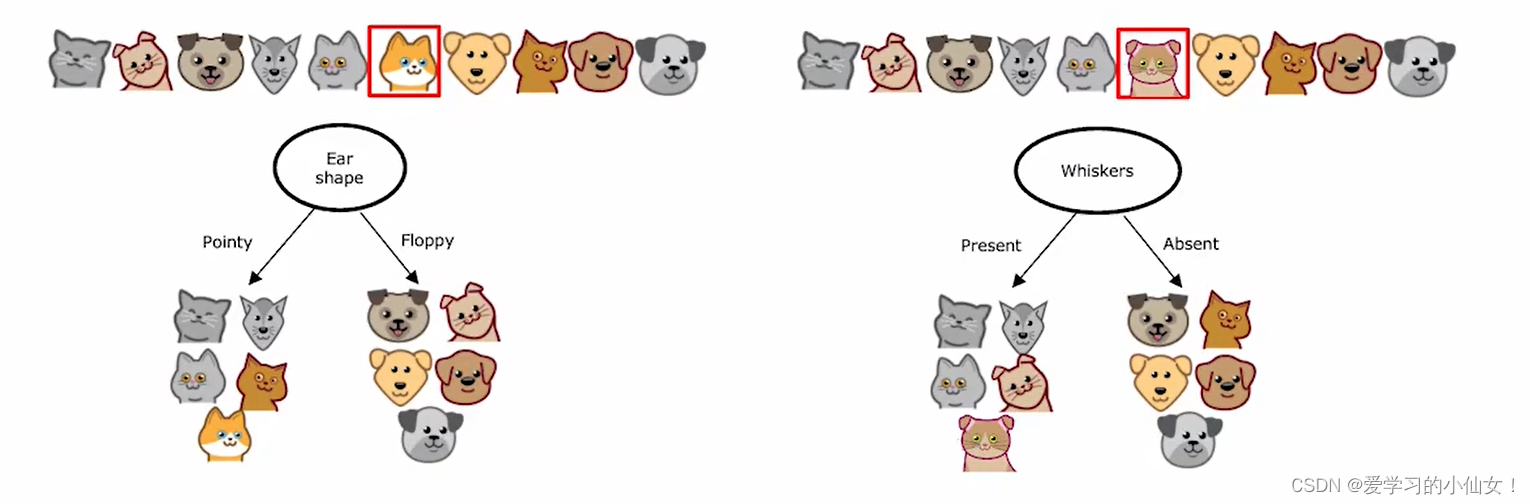
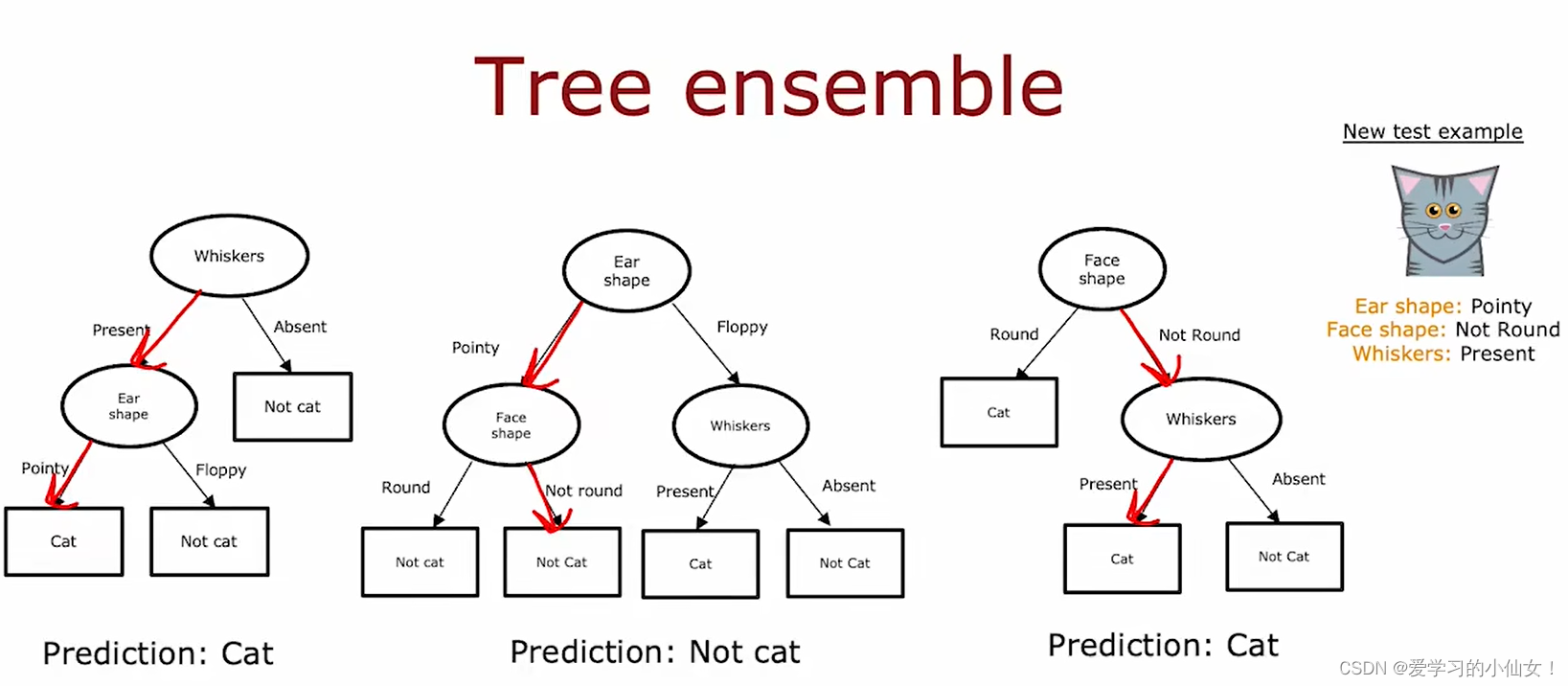
使用一个树集合(tree ensemble),集合中每个树预测的结果可能不同,由每个树进行投票,最多的是 cat, 所以结果就是cat。
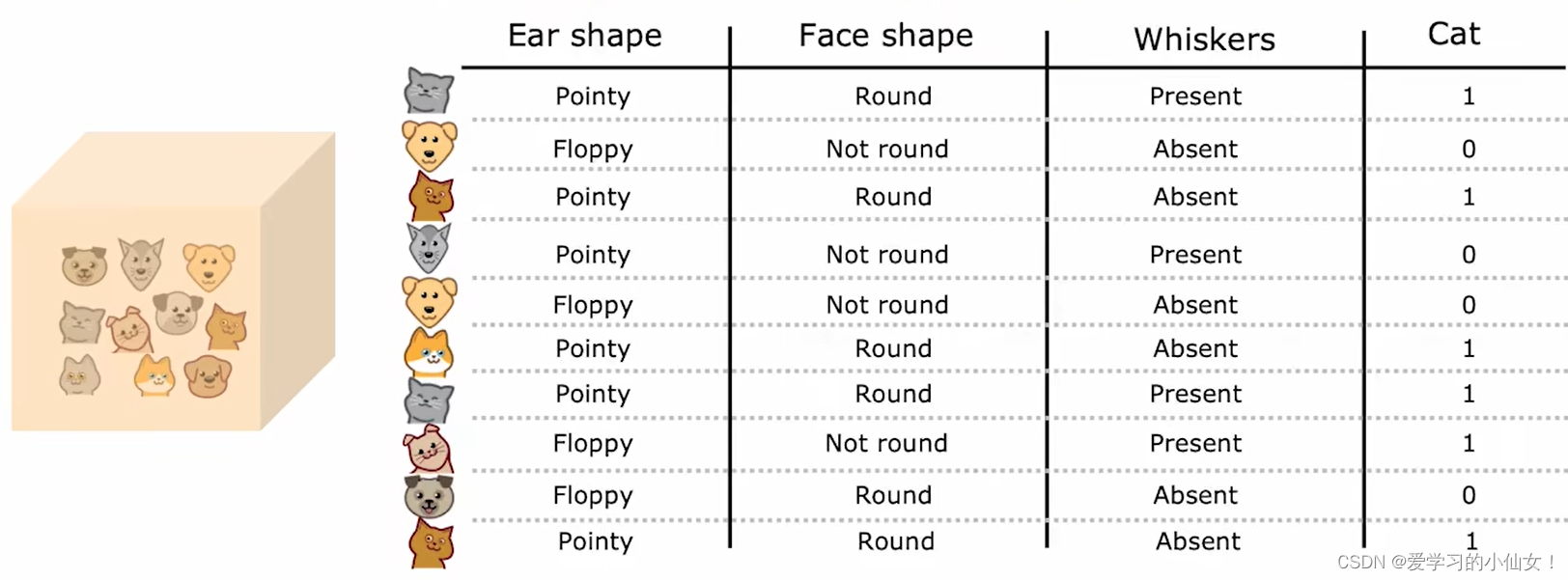
有放回抽样(sampling with replacement),这里 replacement 指的是抽一次之后把抽出来的放回去再继续抽。构建随机训练集,如下图,每次从十个样本里抽一个直到抽够十个,是有放回抽样,所以抽出来的可能有重复。
随机森林算法
假设有一个大小为 m 的训练集,做 B 次这样的操作:有放回抽样
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









