






项目实战:
秒杀:spring-boot-seckill: 从0到1构建分布式秒杀系统,脱离案例讲架构都是耍流氓,交流群:933593697
RuoYi: 🎉 基于SpringBoot的权限管理系统 易读易懂、界面简洁美观。 核心技术采用Spring、MyBatis、Shiro没有任何其它重度依赖。直接运行即可用
logback:掘金
Spring Boot 日志配置(超详细)_inke的博客-CSDN博客_springboot日志
https://github.com/hansonwang99/Spring-Boot-In-Action
GitHub - CodingDocs/springboot-guide: SpringBoot2.0+从入门到实战!
目录
2.1.4 queue???queue的子接口及实现类有哪些?
2.4.5 无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁
6.3.3 Parallel Scavenge 收集器(新生代)
一、各知识点综述链接
知识总结:GitHub - Snailclimb/JavaGuide: 「Java学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!
项目:掘金
Javadoop_首页 TCP/IP协议 (图解+秒懂+史上最全) - 疯狂创客圈 - 博客园 JDK和JRE有什么区别? - Java面试题
sql:史上最简单MySQL教程详解(进阶篇)之事务处理_Newtol的博客-CSDN博客
springboot:基于SpringBoot开发一套完整的项目(一)准备工作_渡西湖-CSDN博客_springboot开发
spring boot项目:给大家推荐8个SpringBoot精选项目 - 柒's Blog
给大家推荐8个SpringBoot精选项目 - 柒's Blog
springboot源码:SpringBoot 源码解读_hongtinghua的博客-CSDN博客_springboot 源码 SpringBoot2 | SpringBoot启动流程源码分析(一)_程序员阿康-CSDN博客_springboot源码深度解析 紧急整理了 20 道 Spring Boot 面试题,我经常拿来面试别人!_weixin_34367257的博客-CSDN博客
springboot在idea中设置了热部署不生效:springboot 热部署没用_SpringBoot 热部署及自动编译不生效解决方法_马渊程的博客-CSDN博客
线程池:java四种线程池的使用 - zincredible - 博客园 2020最新Java线程池入门(超详细)_王傲旗的大数据之路-CSDN博客_java 线程池
NIO:Java常见面试题汇总-----------Java基础(NIO与IO的区别)_知行流浪-CSDN博客 NIO与IO的区别_Mr孔先森-CSDN博客_nio和io的区别 Java面试常考的 BIO,NIO,AIO 总结_小树的博客-CSDN博客_bio nio
ElasticSearch:ElasticSearch从入门到精通,史上最全(持续更新,未完待续,每天一点点)_Null的博客-CSDN博客_elastic stack 从入门到精通
Rabbit MQ:RabbitMQ快速入门(详细)_kavito的博客-CSDN博客_rabbitmq rabbitMQ入门详解,大神勿喷。。。自己总结的_cugb1004101218的专栏-CSDN博客 为什么要使用RabbitMQ? - 知乎
mybatis:Java2020面试总结-----Mybatis原理_IT民工的博客-CSDN博客 Mybatis工作原理_Morty的技术乐园-CSDN博客_mybatis工作原理 《深入理解mybatis原理》 MyBatis的架构设计以及实例分析_我的程序人生(亦山札记)-CSDN博客_mybatis 原理
http://www.starfish.ink/interview/Java-Basics-FAQ.html
mysql:
in/exists:Sql 语句中 IN 和 EXISTS 的区别及应用_jcpp9527的博客-CSDN博客_exists
覆盖索引:覆盖索引_maquealone的博客-CSDN博客_覆盖索引
联合索引:多个单列索引和联合索引的区别详解_Abysscarry的博客-CSDN博客_联合索引和单个索引区别
kafka:同事三面阿里,竟挂在了Kafka;哭诉让我帮他找份Kafka面试题_Java_supermanNO1的博客-CSDN博客 kafka经典面试知识,你都知道吗? - 知乎
token机制:什么是token及怎样生成token_weixin_30828379的博客-CSDN博客
java token 缓存_【Java】微服务中服务端是否需要对token进行存储_天猪飞翔的博客-CSDN博客
掘金
rest和rpc:掘金
面试准备——rpc面试题 - o_0的园子 - 博客园
掘金
二、基础
2.1 集合
2.1.1 集合总览
 https://blog.csdn.net/diweikang/article/details/88381601
https://blog.csdn.net/diweikang/article/details/88381601
java集合超详解_feiyan的博客-CSDN博客_java集合

集合的遍历方式:foreach、iterator、下标(list独有);
Collection是集合类的上级接口,继承与他有关的接口主要有List和Set
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全等操作重写equals就必须重写hashCode
2.1.2 Iterator
https://blog.csdn.net/a1439775520/article/details/95377398
Java 迭代器Iterator的详解_重心开始,重新开始-CSDN博客
Collection的父接口. 实现了Iterable的类就是可迭代的.并且支持增强for循环。该接口只有一个方法即获取迭代器的方法iterator()可以获取每个容器自身的迭代器Iterator。(Collection)集合容器都需要获取迭代器(Iterator)于是在5.0后又进行了抽取将获取容器迭代器的iterator()方法放入到了Iterable接口中。Collection接口进程了Iterable,所以Collection体系都具备获取自身迭代器的方法,只不过每个子类集合都进行了重写(因为数据结构不同)
如果调用remove之前没有调用next是不合法的,会抛出IllegalStateException
Java集合框架关系图_diweikang的博客-CSDN博客_java集合体系结构图
也就是说如果实现Iterator接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历过的元素不会再遍历到,通常无序集合实现的都是这个接口,比如HashSet,HashMap;
而实现了ListIterator接口的集合,可以双向遍历,既可以通过next()访问下一个元素,又可以通过previous()访问前一个元素,比如List。Iterator和Iterable的区别:
1). Iterator是迭代器接口,而Iterable是为了只要实现该接口就可以使用foreach进行迭代。2). Iterable中封装了Iterator接口,只要实现了Iterable接口的类,就可以使用Iterator迭代器了。
3). 集合Collection、List、Set都是Iterable的实现类,所以他们及其他们的子类都可以使用foreach进行迭代。
4). Iterator中核心的方法next()、hasnext()、remove()都是依赖当前位置,如果这些集合直接实现Iterator,则必须包括当前迭代位置的指针。当集合在方法间进行传递的时候,由于当前位置不可知,所以next()之后的值,也不可知。而实现Iterable则不然,每次调用都返回一个从头开始的迭代器,各个迭代器之间互不影响。
2.1.3 comparable & comparator
详解Java中Comparable和Comparator接口的区别_牵着蜗牛_去散步-CSDN博客_comparable和comparator接口的区别
若一个类实现了Comparable接口,就意味着“该类支持排序”。此外,“实现Comparable接口的类的对象”可以用作“有序映射(如TreeMap)”中的键或“有序集合(TreeSet)”中的元素,而不需要指定比较器。
接口中通过x.compareTo(y)来比较x和y的大小。若返回负数,意味着x比y小;返回零,意味着x等于y;返回正数,意味着x大于y。
Comparator 是比较器接口。我们若需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口);那么,我们可以建立一个“该类的比较器”来进行排序。这个“比较器”只需要实现Comparator接口即可。也就是说,我们可以通过“实现Comparator类来新建一个比较器”,然后通过该比较器对类进行排序。
2.1.4 queue???queue的子接口及实现类有哪些?


Java Queue类_浅夏琉殇的博客-CSDN博客_java queue 实现类
压入元素(添加):add()、offer()
相同:未超出容量,从队尾压入元素,返回压入的那个元素。
区别:在超出容量时,add()方法会对抛出异常,offer()返回false弹出元素(删除):remove()、poll()
相同:容量大于0的时候,删除并返回队头被删除的那个元素。
区别:在容量为0的时候,remove()会抛出异常,poll()返回false获取队头元素(不删除):element()、peek()
相同:容量大于0的时候,都返回队头元素。但是不删除。
区别:容量为0的时候,element()会抛出异常,peek()返回null。
2.1.5 HashMap
Java集合之一—HashMap_深入浅出学JAVA-CSDN博客_hashmap
【java】HashMap 一遍就懂!!!!_疯-CSDN博客_hashmap
put():
在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
JAVA1.7 public V put(K key, V value) { //如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold, //此时threshold为initialCapacity 默认是1<<4(24=16) if (table == EMPTY_TABLE) { inflateTable(threshold); } //如果key为null,存储位置为table[0]或table[0]的冲突链上 if (key == null) return putForNullKey(value); int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀 int i = indexFor(hash, table.length);//获取在table中的实际位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败 addEntry(hash, key, value, i);//新增一个entry return null; }JAVA1.8 public V put(K key, V value) { // 对key的hashCode()做hash return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 步骤①:tab为空则创建 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 步骤②:计算index,并对null做处理 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 步骤③:节点key存在,直接覆盖value if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 步骤④:判断该链为红黑树 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 步骤⑤:该链为链表 else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key,value,null); //链表长度大于8转换为红黑树进行处理 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // key已经存在直接覆盖value if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 步骤⑥:超过最大容量 就扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,比如toSize=13,则capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
确定储存位置流程:
HashMap中hash(Object key)原理,为什么(hashcode >>> 16)。_杨涛的博客的博客-CSDN博客
扩容resize:
JAVA1.7 void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); } void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已) for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。 e.next = newTable[i]; newTable[i] = e; e = next; } } }为什么HashMap的数组长度一定保持2的次幂:
有利于hash值的均匀分布;因为计算出key的hash值后要和数组长度进行位运算,当数组长度的低位全为1时更能保留hash值原有特性,使得其在数组上均匀分布;
在扩容时也能减少重算数据hash值的时间成本;在jdk1.7resize时,需要重算旧数组每个值的hash值再放入新数组,在jdk1.8扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”;
get:
get方法的实现相对简单,key(hashcode)–>hash–>indexFor–>最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。
多线程下HashMap存在的并发问题:
1、丢失元素
当多线程同时put值的时候,若发生hash碰撞,可能多个元素都落在链表的头部,从而造成元素覆盖(hashcode相同而eques值不同的元素)。列如:线程A put一个元素a ,线程B put一个元素b,a,b 发生hansh碰撞,本应该在map是链表的形式存在,但是可能线程A和线程B同时put到链表的第一个位置,从而后来者覆盖前者元素造成元素丢失。
2、hash链表成环
jdk1.8的hashmap采用的是尾插法,不会有链表成环的问题。(lohead和lotail没有采用next引用,是怎么关联到一起的???)
遍历方式:
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator(); while (entryIterator.hasNext()) { Map.Entry<String, Integer> next = entryIterator.next(); System.out.println("key=" + next.getKey() + " value=" + next.getValue()); } Iterator<String> iterator = map.keySet().iterator(); while (iterator.hasNext()){ String key = iterator.next(); System.out.println("key=" + key + " value=" + map.get(key)); }通常使用第一种 EntrySet 进行遍历,效率更高;


2.1.6 ConcurrentHashMap
ConcurrentHashMap 面试题_学习使我可乐的博客-CSDN博客_concurrenthashmap面试题
Java并发包concurrent——ConcurrentHashMap_上善若水的木偶戏-CSDN博客
Java8 ConcurrentHashMap详解_好好学java-CSDN博客
JDK1.7之前的ConcurrentHashMap使用分段锁机制实现,JDK1.8则使用数组+链表+红黑树数据结构和CAS原子操作实现ConcurrentHashMap;
初始化:
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) // Use at least as many bins initialCapacity = concurrencyLevel; // as estimated threads long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); this.sizeCtl = cap; }在构造ConcurrentHashMap时,并不会对hash表(Node<K, V>[] table)进行初始化,hash表的初始化是在插入第一个元素时进行的。在put操作时,如果检测到table为空或其长度为0时,则会调用initTable()方法对table进行初始化操作。(HashMap逻辑相同)
链表-红黑树转换逻辑:
当链表长度超过8时,首先会检查hash表的大小是否大于等于MIN_TREEIFY_CAPACITY,默认值为64,如果小于该值,则表示不需要转化为红黑树结构,直接将hash表扩容即可。
如果当前table的长度大于64,则使用CAS获取指定的Node节点,然后对该节点通过synchronized加锁,由于只对一个Node节点加锁,因此该操作并不影响其他Node节点的操作,因此极大的提高了ConcurrentHashMap的并发效率。加锁之后,便是将这个Node节点所在的链表转换为TreeBin结构的红黑树。
然后,在table中删除元素时,如果元素所在的红黑树节点个数小于6,则会触发红黑树向链表结构转换。
put():
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); // 得到 hash 值 int hash = spread(key.hashCode()); // 用于记录相应链表的长度 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果数组"空",进行数组初始化 if (tab == null || (n = tab.length) == 0) // 初始化数组,后面会详细介绍 tab = initTable(); // 找该 hash 值对应的数组下标,得到第一个节点 f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 如果数组该位置为空, // 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了 // 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容 else if ((fh = f.hash) == MOVED) // 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了 tab = helpTransfer(tab, f); else { // 到这里就是说,f 是该位置的头结点,而且不为空 V oldVal = null; // 获取数组该位置的头结点的监视器锁 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表 // 用于累加,记录链表的长度 binCount = 1; // 遍历链表 for (Node<K,V> e = f;; ++binCount) { K ek; // 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // 到了链表的最末端,将这个新值放到链表的最后面 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // 红黑树 Node<K,V> p; binCount = 2; // 调用红黑树的插值方法插入新节点 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } // binCount != 0 说明上面在做链表操作 if (binCount != 0) { // 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8 if (binCount >= TREEIFY_THRESHOLD) // 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换, // 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树 // 具体源码我们就不看了,扩容部分后面说 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } // addCount(1L, binCount); return null; }put操作大致可分为以下几个步骤:
计算key的hash值,即调用speed()方法计算hash值;
获取hash值对应的Node节点位置,此时通过一个循环实现。有以下几种情况:
1. 如果table表为空,则首先进行初始化操作,初始化之后再次进入循环获取Node节点的位置;
2.如果table不为空,但没有找到key对应的Node节点,则直接调用casTabAt()方法插入一个新节点,此时不用加锁;
3.如果table不为空,且key对应的Node节点也不为空,但Node头结点的hash值为MOVED(-1),则表示需要扩容,此时调用helpTransfer()方法进行扩容;
4.其他情况下,则直接向Node中插入一个新Node节点,此时需要对这个Node链表或红黑树通过synchronized加锁。
插入元素后,判断对应的Node结构是否需要改变结构,如果需要则调用treeifyBin()方法将Node链表升级为红黑树结构;
最后,调用addCount()方法记录table中元素的数量。
size():
JDK1.8的ConcurrentHashMap中保存元素的个数的记录方法也有不同,首先在添加和删除元素时,会通过CAS操作更新ConcurrentHashMap的baseCount属性值来统计元素个数。但是CAS操作可能会失败,因此,ConcurrentHashMap又定义了一个CounterCell数组来记录CAS操作失败时的元素个数。因此,ConcurrentHashMap中元素的个数则通过如下方式获得:元素总数 = baseCount + sum(CounterCell)
final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } public long mappingCount() { long n = sumCount(); return (n < 0L) ? 0L : n; // ignore transient negative values }size只能获取int范围内的ConcurrentHashMap元素个数;而如果hash表中的数据过多,超过了int类型的最大值,则推荐使用mappingCount()方法获取其元素个数。
2.2 并发
2.2.1 volatile关键字
Java并发编程:volatile关键字解析 - Matrix海子 - 博客园
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义: 1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。 2)禁止进行指令重排序。
2.2.2 线程池
Java线程池详解_分享传递价值-CSDN博客_java线程池
优势:
降低资源消耗:减少频繁创建和销毁线程的资源消耗;
提高响应速度:避免了创建线程的时间消耗,提高响应速度;
提高线程的管理性:使用线程池进行统一管理,便于系统的监控和调优;重要参数:
corePoolSize:核心线程数,也是线程池中常驻的线程数,线程池初始化时默认是没有线程的,当任务来临时才开始创建线程去执行任务
maximumPoolSize:最大线程数,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
keepAliveTime:非核心线程的空闲时间超过keepAliveTime就会被自动终止回收掉,注意当corePoolSize=maxPoolSize时,keepAliveTime参数也就不起作用了(因为不存在非核心线程);
unit:keepAliveTime的时间单位
workQueue:用于保存任务的队列,可以为无界、有界、同步移交三种队列类型之一,当池子里的工作线程数大于corePoolSize时,这时新进来的任务会被放到队列中
threadFactory:创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建
handler:线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy流程图:
队列:
SynchronousQueue(同步移交队列):队列不作为任务的缓冲方式,可以简单理解为队列长度为零
LinkedBlockingQueue(无界队列):队列长度不受限制,当请求越来越多时(任务处理速度跟不上任务提交速度造成请求堆积)可能导致内存占用过多或OOM
ArrayBlockintQueue(有界队列):队列长度受限,当队列满了就需要创建多余的线程来执行任务;
PriorityBlockingQueue:类似于LinkedBlockingQueue,但是其所含对象的排序不是FIFO,而是依据对象的自然顺序或者构造函数的Comparator决定
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。创建方式:
JAVA中创建线程池的五种方法及比较 - PC君 - 博客园
线程池创建方式总共可分为两种:通过工具类Executors和类ThreadPoolExecutor自定义。Executors底层一共有4种创建线程池的方式,这4种是通过调用不用入参的ThreadPoolExecutor()构造函数实现的。newCachedThreadPool(可缓存) :因为SynchronousQueue队列不保持它们,直接提交给线程,相当于队列大小为0,而最大线程数为Integer.MAX_VALUE,所以线程不足时,会一直创建新线程,等到线程空闲时,又有60秒存活时间,从而实现了一个可缓存的线程池。
创建方式 核心线程数 最大线程数 等待时间 阻塞队列 newCachedThreadPool 0 Integer.MAX_VALUE 60L SynchronousQueue newFixedThreadPool nThreads nThreads 0 LinkedBlockingQueue newScheduledThreadPool corePoolSize Integer.MAX_VALUE 0 DelayedWorkQueue newSingleThreadExecutor 1 1 0 LinkedBlockingQueue newFixedThreadPool(定长):因为核心线程数与最大线程数相同,所以线程池的线程数是固定的,而且没有限制队列的大小,所以多余的任务均会被放到队列排队,从而实现一个固定大小,可控制并发数量的线程池。
newScheduledThreadPool(定时):因为使用了延迟队列,只有在延迟期满时才能从中提取到元素,从而实现定时执行的线程池。而周期性执行是配合上层封装的其他类来实现的,可以看ScheduledExecutorService类的scheduleAtFixedRate方法。
newSingleThreadExecutor(单例):因为核心线程数与最大线程数相同,均为1,所以线程池的线程数是固定的1个,而且没有限制队列的大小,所以多余的任务均会被放到队列排队,从而实现一个单线程按指定顺序执行的线程池。
《阿里巴巴Java开发手册》规范:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executors返回的线程池对象的弊端如下:
FixedThreadPool和SingleThreadPool:允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
CachedThreadPool和ScheduledThreadPool:允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。拒绝策略:
AbortPolicy:拒绝并抛出异常。
CallerRunsPolicy: 重试提交当前的任务,即再次调用运行该任务的execute()方法。(后面排队的线程就在那儿等着。被拒绝的任务在主线程中运行,所以主线程就被阻塞了,别的任务只能在被拒绝的任务执行完之后才会继续被提交到线程池执行。)
DiscardOldestPolicy: 抛弃队列头部(最旧)的一个任务,并执行当前任务。
DiscardPolicy: 抛弃当前任务。线程池复用原理
通过将任务与线程解耦,不采取常规的Thread.start()运行任务,而是让每一个线程去执行“循环任务”,检查是否有任务需要执行,若有就直接运行(即调用run方法?)为什么先添加队列而不是先创建最大线程
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源;
阻塞队列自带阻塞和唤醒功能,不需要额外处理,无任务执行时,线程池利用阻塞队列的take方法挂起,从而维持核心线程的存活,不至于一致占用cpu资源。

2.2.3 线程
进程和线程的深入理解_luhao19980909的博客-CSDN博客_进程与线程
线程、进程的联系
线程是进程的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程
线程、进程的区别
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位;
开销方面:每个进程都有独立的代码和数据空间(程序上下文),进程之间切换开销大;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小;
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行);
内存分配:系统为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源;
包含关系:线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程;创建线程四种方式
JAVA中创建线程的三种方法及比较 - PC君 - 博客园
1、线程池创建
springboot线程池的使用和扩展 - J'KYO - 博客园
2、继承Thread类
创建一个任务类集成Thread,创建的任务类对象即线程对象public class TestThread extends Thread { public void run() { for (int i = 0; i < 20; i++) { // 与Thread.currentThread().getName()相同 System.out.println(this.getName() + " " + i); } } public static void main(String[] args) { TestThread t1 = new TestThread(); TestThread t2 = new TestThread(); t1.start(); t2.start(); } }3、实现Runnable接口
创建一个任务类,实现Runnable接口,创建一个任务类的对象,将任务类的对象作为参数,创建一个Thread类对象,该Thread类对象才是真正的线程对象。public class TestThread implements Runnable { public void run() { for (int i = 0; i < 20; i++) { // 获取线程名称,默认格式:Thread-0 System.out.println(Thread.currentThread().getName() + " " + i); } } public static void main(String[] args) { TestThread tt1 = new TestThread(); TestThread tt2 = new TestThread(); // 可为线程添加名称:Thread t1 = new Thread(tt1, "线程1"); Thread t1 = new Thread(tt1); Thread t2 = new Thread(tt2); t1.start(); t2.start(); } }4、通过Callable和Future
创建一个任务类,实现Callable接口,并实现call()方法,创建一个任务类的对象,并使用FutureTask类来包装任务类的对象,该FutureTask对象封装了任务类对象中call()方法的返回值,将FutureTask类的对象作为参数,创建一个Thread类对象,该Thread类对象才是真正的线程对象;调用FutureTask类对象的get()方法来获取线程执行的返回值,即任务类对象中call()方法的返回值。public class TestThread implements Callable<Integer> { public Integer call() { int i = 0; for (i = 0; i < 20; i++) { if (i == 5) break; System.out.println(Thread.currentThread().getName() + " " + i); } return i; } public static void main(String[] args) { TestThread tt = new TestThread(); FutureTask<Integer> ft = new FutureTask<Integer>(tt); Thread t = new Thread(ft); t.start(); try { System.out.println(Thread.currentThread().getName() + " " + ft.get()); } catch (Exception e) { e.printStackTrace(); } } }后三种创建方式比较
1、继承Thread类方式:
(1)优点:编写简单,任务类中访问当前线程时,可以直接使用this关键字。
(2)缺点:任务类即线程类已经继承了Thread类,所以不能再继承其他父类。
2、实现Runnable接口的方式:
(1)优点:任务类只实现了Runnable接口,还可以继承其他类。这种方式,可以多个线程对象共享一个任务类对象,即多线程共享一份资源的情况,如下:TestThread tt1 = new TestThread(); Thread t1 = new Thread(tt1); Thread t2 = new Thread(tt1); t1.start(); t2.start();(2)缺点:编写稍微复杂,任务类中访问当前线程时,必须使用Thread.currentThread()方法。
3、通过Callable和Future的方式:
(1)优点:任务类只实现了Callable接口,还可以继承其他类,同样多线程下可共享同一份资源,这种方式还有返回值,并且可以抛出返回值的异常。
(2)缺点:编写复杂,任务类中访问当前线程时,必须使用Thread.currentThread()方法。线程状态及方法
创建--就绪--运行--阻塞--死亡
Thread之一:线程生命周期及六种状态 - duanxz - 博客园
2.2.4 ThreadLocal
Java面试必问,ThreadLocal终极篇 - 简书
面试题 - ThreadLocal详解_秋夫人-CSDN博客_threadlocal面试题
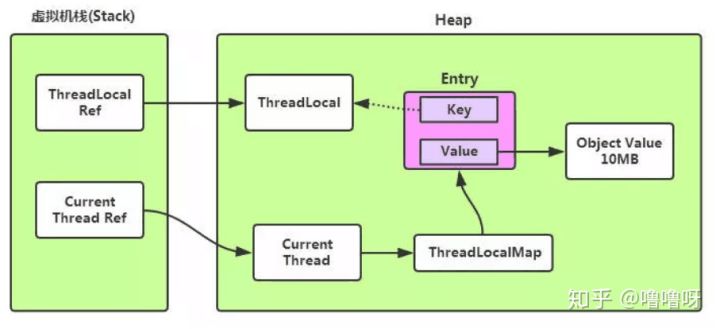
1.ThreadLocal 是线程局部变量,这个变量与普通变量的区别,在于每个访问该变量的线程,在线程内部都会初始化一个独立的变量副本,只有该线程可以访问【get() or set()】该变量,ThreadLocal实例通常声明为 private static。
2.线程在存活并且ThreadLocal实例可被访问时,每个线程隐含持有一个线程局部变量副本,当线程生命周期结束时,ThreadLocal的实例的副本跟着线程一起消失,被GC垃圾回收(除非存在对这些副本的其他引用)ThreadLocal虽然叫线程局部变量,但是实际上它并不存放任何的信息,可以这样理解:它是线程(Thread)操作ThreadLocalMap中存放的变量的桥梁。它主要提供了初始化、set()、get()、remove()几个方法。这样说可能有点抽象,下面画个图说明一下在线程中使用ThreadLocal实例的set()和get()方法的简单流程图。
ThreadLocal 是基于 ThreadLocalMap 实现的,而 ThreadLocalMap 是一个类似 map 结构,没有实现 map 接口,但是同样会产生 Hash 冲突,不同的是 HashMap 才用的是链地址法,即数组加链表, 而 ThreadLocalMap 采用的是开放地址法,当发生 hash 冲突的时候,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止
内存泄漏
ThreadLocal自身并不储存值,而是作为一个key来让线程从ThreadLocal获取value。Entry是中的key是弱引用,所以jvm在垃圾回收时如果外部没有强引用来引用它,ThreadLocal必然会被回收。但是,作为ThreadLocalMap的key,ThreadLocal被回收后,ThreadLocalMap就会存在null,但value不为null的Entry。若当前线程一直不结束,可能是作为线程池中的一员,线程结束后不被销毁,或者分配(当前线程又创建了ThreadLocal对象)使用了又不再调用get/set方法,就可能引发内存泄漏。其次,就算线程结束了,操作系统在回收线程或进程的时候不是一定杀死线程或进程的,在繁忙的时候,只会清除线程或进程数据的操作,重复使用线程或进程(线程id可能不变导致内存泄漏)。因此,key弱引用并不是导致内存泄漏的原因,而是因为ThreadLocalMap的生命周期与当前线程一样长,并且没有手动删除对应value。
那么,为什么要将Entry中的key设为弱引用?相反,设置为弱引用的key能预防大多数内存泄漏的情况。如果key 使用强引用,引用的ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。如果key为弱引用,引用的ThreadLocal的对象被回收了,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被GC回收。value在下一次ThreadLocalMap调用set,get,remove的时候会被清除。
如何避免:在使用完ThreadLocal时,及时调用它的的remove方法清除数据。


2.2.4 为什么wait方法在Obejct中不在Thread类中
2.2.5 进程间通信模式、线程间通信模式
2.3 IO模型
2.3.1 NIO
10 个最高频的 Java NIO 面试题剖析!_GitChat-CSDN博客
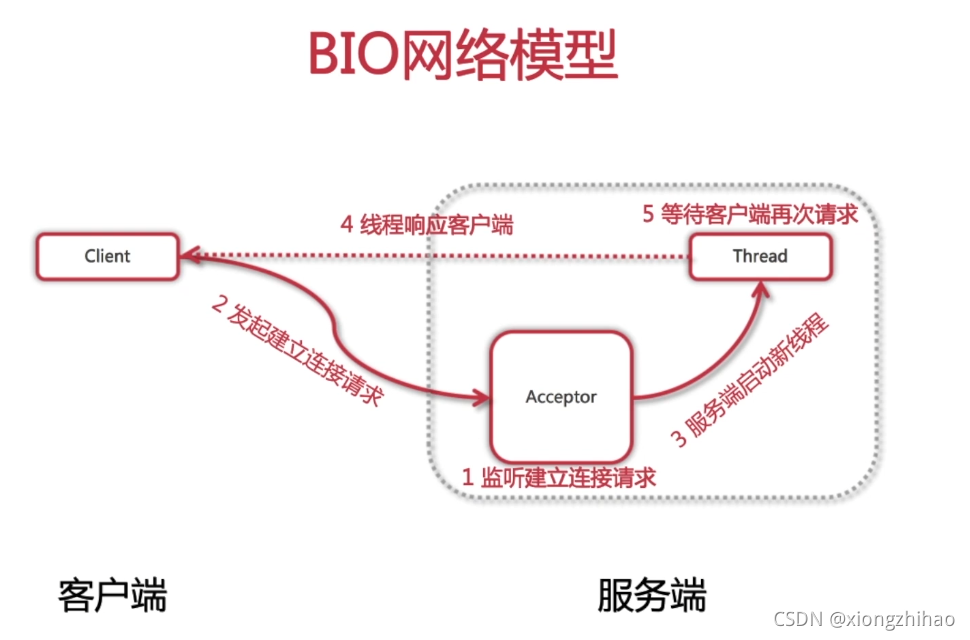
BIO 就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。它的优点就是代码比较简单、直观;缺点就是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
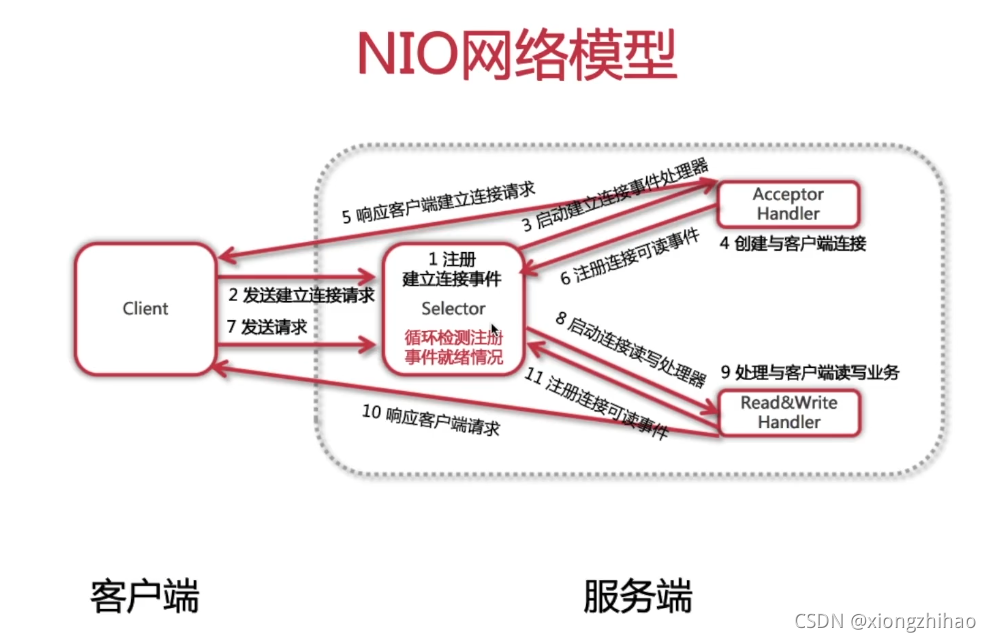
NIO 是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
AIO 是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,因此人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
file读写最简洁方式// 读取文件 byte[] bytes = Files.readAllBytes(Paths.get("d:\\io.txt")); // 写入文件 Files.write(Paths.get("d:\\io.txt"), "追加内容".getBytes(), StandardOpenOption.APPEND);Java面试常考的 BIO,NIO,AIO 总结_小树的博客-CSDN博客_bio nio
BIO,NIO,AIO整理(全称,介绍,区别)_光辉晨少的博客-CSDN博客_bio
Java常见面试题汇总-----------Java基础(NIO与IO的区别)_知行流浪-CSDN博客
Java BIO (blocking I/O): 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO (non-blocking I/O): 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO(NIO.2) (Asynchronous I/O) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,https://blog.csdn.net/mashaokang1314/article/details/88636371
一个IO操作实际上是被分为两步的,就拿处理网络数据来说。第一步:发起IO请求,第二部实际的IO操作。
阻塞IO和非阻塞IO的区别在于第一步;发起IO请求线程是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞IO;否则就是非阻塞IO;
同步IO和非同步IO的区别在于第二步;如果实际的IO读写阻塞请求进程,那么就是同步IO,因此阻塞IO、非阻塞IO、IO复用都是同步IO;如果不阻塞,而是由操作系统帮你做完再将结果返回给你,那么就是异步IO。
Tomcat默认使用NIO
1、BIO中的流程应该是接收到请求之后直接把请求扔给线程池去做处理,在这个情况下一个连接即需要一个线程来处理,线程既需要读取数据还需要处理请求,线程占用时间长,很容易达到最大线程;
2、NIO的流程的不同点在于Poller类采用了多路复用模型,即Poller类只有检查到可读或者可写的连接时才把当前连接扔给线程池来处理,这样的好处是大大节省了连接还不能读写时的处理时间(如读取请求数据),也就是说NIO“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。
BIO
Acceptor每接收到一个连接请求就创建一个线程进行响应,并阻塞,直到客户端发送数据;
NIO
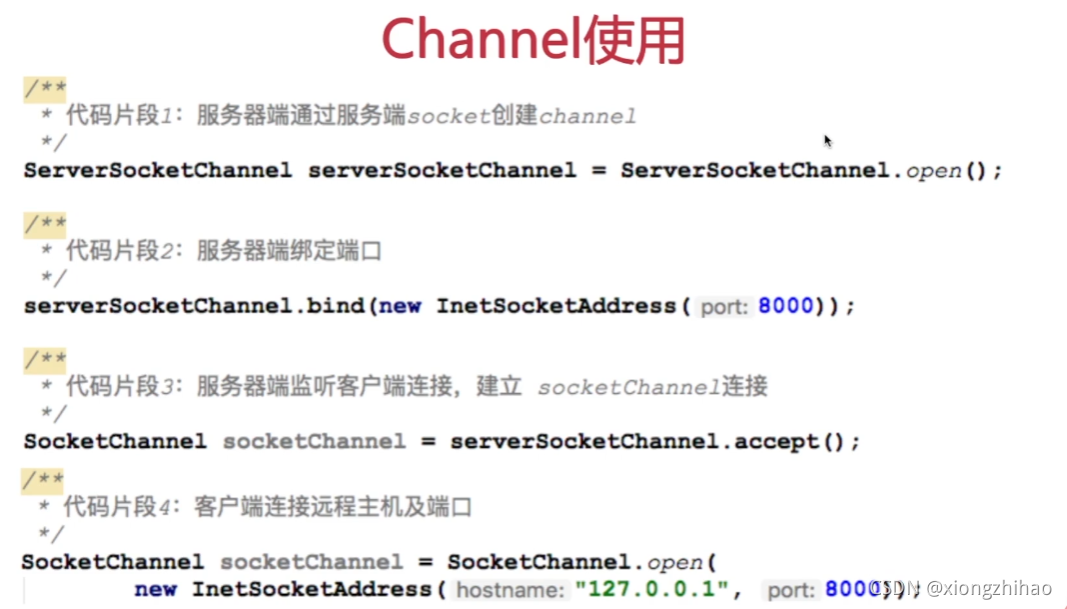
核心实现类:Channel通道、Buffer缓冲、Selector选择器(多路复用器)
Channel:双向性、非阻塞性、操作唯一性(通过buffer读写)
Buffer:一块内存区域,用于读写Channel中的数据。(NIO为buffer提供了除了布尔类型的所有基本类型数据的实现类)
4个属性:Capacity(容量)、Position(位置)、Limit(上限)、Mark(标记)
Selector:NIO的基石,用于检测I/O是否就绪。SelectionKey的4个监听就绪事件:connect连接就绪、accept接收就绪、read读就绪、write写就绪。
/** * 启动 */ public void start() throws IOException { /** * 1. 创建Selector */ Selector selector = Selector.open(); /** * 2. 通过ServerSocketChannel创建channel通道 */ ServerSocketChannel serverSocketChannel = ServerSocketChannel.open(); /** * 3. 为channel通道绑定监听端口 */ serverSocketChannel.bind(new InetSocketAddress(8000)); /** * 4. **设置channel为非阻塞模式** */ serverSocketChannel.configureBlocking(false); /** * 5. 将channel注册到selector上,监听连接事件 */ serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT); System.out.println("服务器启动成功!"); /** * 6. 循环等待新接入的连接 */ for (;;) { // while(true) c for;; /** * TODO 获取可用channel数量 */ int readyChannels = selector.select(); /** * TODO 为什么要这样!!? */ if (readyChannels == 0) continue; /** * 获取可用channel的集合 */ Set<SelectionKey> selectionKeys = selector.selectedKeys(); Iterator iterator = selectionKeys.iterator(); while (iterator.hasNext()) { /** * selectionKey实例 */ SelectionKey selectionKey = (SelectionKey) iterator.next(); /** * **移除Set中的当前selectionKey** */ iterator.remove(); /** * 7. 根据就绪状态,调用对应方法处理业务逻辑 */ /** * 如果是 接入事件 */ if (selectionKey.isAcceptable()) { acceptHandler(serverSocketChannel, selector); } /** * 如果是 可读事件 */ if (selectionKey.isReadable()) { readHandler(selectionKey, selector); } } } }NIO缺陷:
NIO类库和API繁杂,门槛高、工作量大、开发难度较大
Linux中的epoll bug,即Selector空轮询,导致CPU100%;




2.3.2 epoll/poll/select
深入理解select、poll和epoll及区别_$好记性还是要多记录$-CSDN博客_epoll和select的区别
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
2、FD剧增后带来的IO效率问题
3、 消息传递方式综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
2.3.3 Netty
对NIO做了封装,具备API简单、门槛低、性能高、成熟稳定等特点
2.4 锁
java中的各种锁详细介绍 - JYRoy - 博客园
Synchronized的原理及自旋锁,偏向锁,轻量级锁,重量级锁的区别_Kirito_j的博客-CSDN博客_轻量级锁和自旋锁的区别
并发编程之 Java 三把锁_ignore-CSDN博客
2.4.1 CAS
Java中CAS详解_jayxu无捷之径的博客-CSDN博客_cas
CAS操作原理:
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该 位置的值。CAS 用于同步的方式是从地址 V 读取值 A,执行多步计算来获得新值 B,然后使用 CAS 将 V 的值从 A 改为 B。如果 V 处的值尚未同时更改,则 CAS 操作成功。
整个J.U.C都是建立在CAS之上的,因此对于synchronized阻塞算法,J.U.C在性能上有了很大的提升。缺点:
1. ABA问题
2. 循环时间长,开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
3. 只能保证一个共享变量的原子操作:对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性
2.4.2 锁分类

2.4.3 乐观锁、悲观锁
锁从宏观上分为乐观锁、悲观锁。
乐观锁是一种乐观思想,认为读多写少,遇到并发写的可能性低,每次取数据都认为别人不会修改,所以不会上锁,在更新的时候会判断一下在此期间别人有没有去更新这个数据;采用CAS实现。
悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁;java中的悲观锁就是synchronized。AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如RetreenLock。
2.4.4 自旋锁、适应性自旋锁
线程阻塞代价
java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在用户态与核心态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
如果线程状态切换是一个高频操作时,这将会消耗很多CPU处理时间;
如果对于那些需要同步的简单的代码块,获取锁挂起操作消耗的时间比用户代码执行的时间还要长,这种同步策略显然非常糟糕的。自旋锁定义
自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换的消耗。自旋锁优缺点
优点: 自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
缺点:自旋锁的缺点很明显就是容易造成CPU的空转,因为自旋是一直占着CPU做无用功的,所以如果锁的竞争很激烈,并且每个线程需要的执行时间占用锁的时间很长,就不适合用自旋锁。自适应性自旋锁
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock和MCSlock
2.4.5 无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁
Java并发——Synchronized关键字和锁升级,详细分析偏向锁和轻量级锁的升级_tongdanping的博客-CSDN博客
这四种锁是指锁的状态,专门针对synchronized的。
synchronize锁的三种使用场景:
Synchronized修饰普通同步方法:锁对象是当前实例对象;
Synchronized修饰静态同步方法:锁对象是当前的类Class对象;
Synchronized修饰同步代码块:锁对象是Synchronized后面括号里配置的对象,这个对象可以是某个对象(xlock),也可以是某个类(Xlock.class);
注意:
使用synchronized修饰类和对象时,由于类对象和实例对象分别拥有自己的监视器锁,因此不会相互阻塞。
使用使用synchronized修饰实例对象时,如果一个线程正在访问实例对象的一个synchronized方法时,其它线程不仅不能访问该synchronized方法,该对象的其它synchronized方法也不能访问,因为一个对象只有一个监视器锁对象,但是其它线程可以访问该对象的非synchronized方法。Java对象头:
对象是存放在堆内存中的,对象大致可以分为三个部分,分别是对象头、实例变量和填充字节。
对象头是由MarkWord和Klass Point(类型指针)组成,其中Klass Point是是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,Mark Word用于存储对象自身的运行时数据。
实例变量存储的是对象的属性信息,包括父类的属性信息,按照4字节对齐。
填充字符,因为虚拟机要求对象字节必须是8字节的整数倍,填充字符就是用于凑齐这个整数倍的。
64位虚拟机:Monitor:
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。
Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。无锁:
无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。上面我们介绍的CAS原理及应用即是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。偏向锁:
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不再通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态。撤销偏向锁后恢复到无锁(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
偏向锁在JDK 6及以后的JVM里是默认启用的。可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态。轻量级锁:
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,然后拷贝对象头中的Mark Word复制到锁记录中。
拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。
如果轻量级锁的更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明多个线程竞争锁。
若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。重量级锁:
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。优缺点:
综上,偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。而轻量级锁是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。重量级锁是将除了拥有锁的线程以外的线程都阻塞。
锁升级
偏向锁升级:当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致(还是线程1获取锁对象),则无需使用CAS来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
轻量锁升级:线程1获取轻量级锁时会先把锁对象的对象头MarkWord复制一份到线程1的栈帧中创建的用于存储锁记录的空间(称为DisplacedMarkWord),然后使用CAS把对象头中的内容替换为线程1存储的锁记录(DisplacedMarkWord)的地址;
如果在线程1复制对象头的同时(在线程1CAS之前),线程2也准备获取锁,复制了对象头到线程2的锁记录空间中,但是在线程2CAS的时候,发现线程1已经把对象头换了,线程2的CAS失败,那么线程2就尝试使用自旋锁来等待线程1释放锁。
但是如果自旋的时间太长也不行,因为自旋是要消耗CPU的,因此自旋的次数是有限制的,比如10次或者100次,如果自旋次数到了线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时又有一个线程3过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。锁粗化、锁消除




2.4.6 公平锁、非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
2.4.7 可重入锁
可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock(默认非公平锁)和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。如上图所示 :类中的两个方法都是被内置锁synchronized修饰的,doSomething()方法中调用doOthers()方法。因为内置锁是可重入的,所以同一个线程在调用doOthers()时可以直接获得当前对象的锁,进入doOthers()进行操作。
如果是一个不可重入锁,那么当前线程在调用doOthers()之前需要将执行doSomething()时获取当前对象的锁释放掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。原理
重入锁实现可重入性原理或机制是:每一个锁关联一个线程持有者和计数器,当计数器为 0 时表示该锁没有被任何线程持有,那么任何线程都可能获得该锁而调用相应的方法;当某一线程请求成功后,JVM会记下锁的持有线程,并且将计数器置为 1;此时其它线程请求该锁,则必须等待;而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增;当线程退出同步代码块时,计数器会递减,如果计数器为 0,则释放该锁。
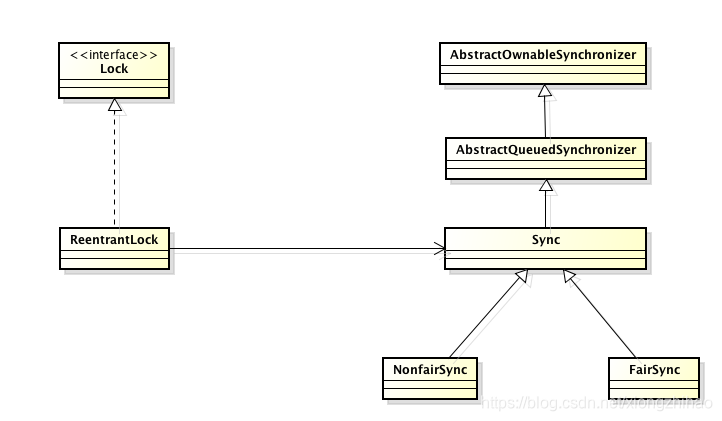
2.4.8 读写锁(共享锁、互斥锁)
独享锁
独享锁也叫排他锁、写锁、互斥锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。共享锁
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。锁降级
锁升级是synchronized关键字在jdk1.6之后做的优化,锁降级是指读写锁中写锁降级为读锁。
写线程获取写入锁后可以获取读取锁, 然后释放写入锁, 这样就从写入锁变成了读取锁, 从而实现锁降级的特征。
该过程与获取写锁之后将其释放,最后在获取读锁的过程相比,前者能够感知到自己对该变量做的相关操作,因为释放写锁后,如果其它线程T直接获取该对象的写锁,则会对该对象的值进行修改,本线程S再读取该值时,会获取到T修改后的值,而不能获取S修改后的值。
应用场景: 对于数据比较敏感, 需要在对数据修改以后, 获取到修改后的值, 并进行接下来的其它操作。
https://www.jianshu.com/p/91a38adc89e5
锁降级详解_cisco_huang的博客-CSDN博客public class LockDegrade { public static void main(String[] args) { ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(); Lock writeLock = reentrantReadWriteLock.writeLock(); Lock readLock = reentrantReadWriteLock.readLock(); writeLock.lock(); readLock.lock(); writeLock.unlock(); readLock.unlock(); System.out.println("程序正常运行"); } }
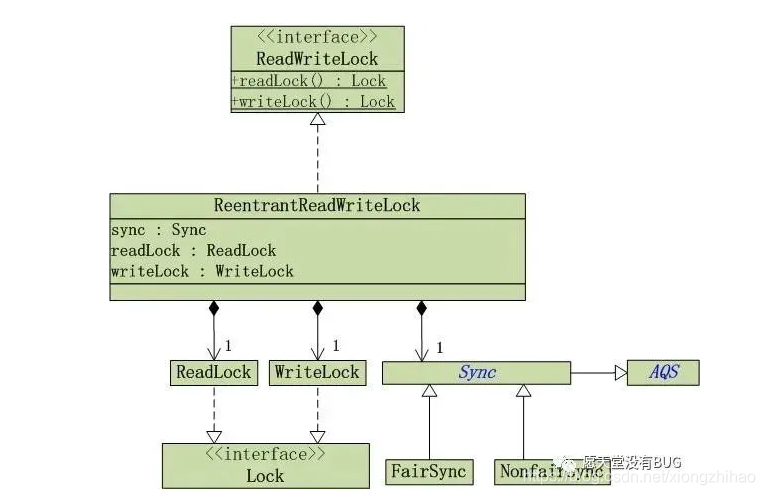
2.4.9 AQS
AQS(面试)详解_渣渣-CSDN博客_aqs
REDIS6_分布式存储极致性能目录_所得皆惊喜-CSDN博客
死磕 java同步系列之AQS终篇(面试) - 彤哥读源码 - 博客园(1)AQS是Java中几乎所有锁和同步器的一个基础框架,这里说的是“几乎”,因为有极个别确实没有通过AQS来实现;
(2)AQS中维护了一个队列,这个队列使用双链表实现,用于保存等待锁排队的线程;
(3)AQS中维护了一个状态变量,控制这个状态变量就可以实现加锁解锁操作了;
AQS主要使用了模板设计模式,部分方法需要子类实现
AQS原理浅析_m_xiaoer的博客-CSDN博客_aqs原理
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
AQS,它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。这里volatile是核心关键词,具体volatile的语义,在此不述。state的访问方式有三种:
getState()
setState()
compareAndSetState()AQS通过维护一个volatile修饰的共享变量state和双向队列CLH来实现加锁操作。线程尝试获取锁首先读取state变量,如果为1,说明线程占用,将该线程封装成NOde加点加入CLH队列,如果为0,采用CAS,若CAS成功,则获取锁成功,将state置为1.
2.4.10 sychronized和lock对比
https://blog.csdn.net/significantfrank/article/details/80399179
Java的三把锁:synchronized 关键字、ReentrantLock 重入锁、ReadWriteLock 读写锁
Synchronized(内置锁)
- 优点:实现简单,语义清晰,便于JVM堆栈跟踪;加锁解锁过程由JVM自动控制,提供了多种优化方案。
- 缺点:不能进行高级功能(定时,轮询和可中断等)。Lock
- 优点:可定时的、可轮询的与可中断的锁获取操作,提供了读写锁、公平锁和非公平锁
- 缺点:需手动释放锁unlock,不适合JVM进行堆栈跟踪。在一些内置锁无法满足需求的情况下,ReentrantLock可以作为一种高级工具。当需要一些高级功能时才应该使用ReentrantLock,这些功能包括:可定时的,可轮询的与可中断的锁获取操作,公平队列,以及非块结构的锁。否则,还是应该优先使用Synchronized
(1) synchronized 是Java的一个内置关键字,而ReentrantLock是Java的一个类。
(2) synchronized只能是非公平锁。而ReentrantLock可以实现公平锁和非公平锁两种。
(3) synchronized不能中断一个等待锁的线程,而Lock可以中断一个试图获取锁的线程。
(4) synchronized不能设置超时,而Lock可以设置超时。
(5) synchronized会自动释放锁,而ReentrantLock不会自动释放锁,必须手动释放,否则可能会导致死锁。
2.5 设计模式
2.5.1 单例模式
单例模式的五种写法_absolute_chen的博客-CSDN博客_单例模式
懒汉式
线程不安全public class Demo{ private static Demo instance; private Demo(){} public static Demo getInstance(){ if(instance == null){ instance = new Demo(); } return instance; } }饿汉式
浪费空间public class Demo{ private static Demo instance = new Demo(); private Demo(){} public static Demo getInstance(){ return instance; } }双检索式
public class Demo{ private static Demo instance; private Demo(){} public static Demo getInstance(){ if(instance == null){ sychronized (Demo.class) { if(instance == null){ instance = new Demo(); } } } return instance; } }此种方法有隐患,在多线程访问时,若进行了重排序将出现问题,需要对实例变量加上volatile修饰(禁止重排序):private volatile static Demo instance;
Java中的双重检查锁(double checked locking) - Decouple - 博客园静态内部类
枚举
总结下,一般情况下,懒汉式(包含线程安全和线程不安全梁总方式)都比较少用;饿汉式和双检锁都可以使用,可根据具体情况自主选择;在要明确实现 lazy loading 效果时,可以考虑静态内部类的实现方式;若涉及到反序列化创建对象时,大家也可以尝试使用枚举方式。


2.5.2 代理模式
详解java动态代理机制以及使用场景(一)_远方和诗 的博客-CSDN博客_java动态代理应用场景
JDK动态代理和CGlib代理 - 知乎
静态代理和动态代理的区别和联系 - jason.bai - 博客园
2.5.3 工厂模式
java工厂模式三种详解(部分转载)_llussize的博客-CSDN博客_java工厂模式
简单工厂模式、工厂模式以及抽象工厂模式(具体)_cosmos_lee-CSDN博客_简单工厂模式和工厂模式
2.6 其他
2.6.1 匿名内部类、函数式接口
2.6.2 Linux
linux 信号9和信号15,kill -9 和 kill -15 的区别_西屋厨电的博客-CSDN博客
总结:kill命令用于终止Linux进程,默认情况下,如果不指定信号,kill 等价于kill -15。kill -15执行时,系统向对应的程序发送SIGTERM(15)信号,该信号是可以被执行、阻塞和忽略的,所以应用程序接收到信号后,可以做一些准备工作,再进行程序终止。有的时候,kill -15无法终止程序,因为他可能被忽略,这时候可以使用kill -9,系统会发出SIGKILL(9)信号,该信号不允许忽略和阻塞,所以应用程序会立即终止。这也会带来很多副作用,如数据丢失等,所以,在非必要时,不要使用kill -9命令,尤其是那些web应用、提供RPC服务、执行定时任务、包含长事务等应用中,因为kill -9 没给spring容器、tomcat服务器、dubbo服务、流程引擎、状态机等足够的时间进行收尾。
2.6.3 守护线程
【java 多线程】守护线程与非守护线程_lc1010078424的博客-CSDN博客_非守护线程
Java中有两类线程:User Thread(用户线程)、Daemon Thread(守护线程)用户线程即运行在前台的线程,而守护线程是运行在后台的线程。 守护线程作用是为其他前台线程的运行提供便利服务,而且仅在普通、非守护线程仍然运行时才需要,比如垃圾回收线程就是一个守护线程。当VM检测仅剩一个守护线程,而用户线程都已经退出运行时,VM就会退出,因为没有如果没有了被守护这,也就没有继续运行程序的必要了。如果有非守护线程仍然存活,VM就不会退出。
守护线程并非只有虚拟机内部提供,用户在编写程序时也可以自己设置守护线程。用户可以用Thread的setDaemon(true)方法设置当前线程为守护线程。
虽然守护线程可能非常有用,但必须小心确保其他所有非守护线程消亡时,不会由于它的终止而产生任何危害。因为你不可能知道在所有的用户线程退出运行前,守护线程是否已经完成了预期的服务任务。一旦所有的用户线程退出了,虚拟机也就退出运行了。 因此,不要在守护线程中执行业务逻辑操作(比如对数据的读写等)。
2.6.4 序列化
private static final long serialVersionUID = 1L;_dancheguiji的博客-CSDN博客 private static final long serialVersionUID在实现序列化的类中出现的意义_my zone-CSDN博客
三、Redis
3.1 基础
3.1.1 Redis数据结构
String 类型的底层实现只有一种数据结构。而 List、Hash、Set 和 Sorted Set ,都有两种底层实现结构,称为集合类型,它们的特点是一个键对应了一个集合的数据。
Redis 使用了一个哈希表来保存所有键值对。不管值是 String,还是集合类型,哈希桶中的元素都是指向它们的指针。rehash
产生hash冲突时,redis采用下拉链表解决,当链表过长时,会进行rehash。Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
1、给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
2、把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
3、释放哈希表 1 的空间。
在第二步中如果一次性将数据拷贝如哈希表2,会造成线程阻塞,因此redis采用渐进式rehash:
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。压缩列表
压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量(即entryN的地址)和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,复杂度就是 O(N) 。跳表
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。
操作复杂度
单元素操作是基础;
范围操作非常耗时;
统计操作通常高效;
例外情况只有几个。
单元素操作,是指每一种集合类型对单个数据实现的增删改查操作(O(1)-O(M))。范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据(O(N))。统计操作,是指集合类型对集合中所有元素个数的记录(O(1))。例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表等。
List 类型,它的两种底层实现结构:双向链表和压缩列表的操作复杂度都是 O(N)。建议是因地制宜地使用 List 类型。例如,既然它的 POP/PUSH 效率很高,那么就将它主要用于 FIFO 队列场景,而不是作为一个可以随机读写的集合。




3.1.2 为什么Redis速度快
线程情况
Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。Redis快速原因
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。还有就是单线程避免了多线程切换带来的消耗。
单线程避免了多线程切换带来的消耗。
内存数据库,访问速度快;
优秀的数据结构;
3.1.3 多路复用
基本 IO 模型与阻塞点
以 Get 请求为例,Redis需要监听客户端请求(bind/listen),和客户端建立连接(accept),从 socket 中读取请求(recv),解析客户端发送请求(parse),根据请求类型读取键值数据(get),最后给客户端返回结果,即向 socket 中写回数据(send)。
在这里的网络 IO 操作中,有潜在的阻塞点,分别是 accept() 和 recv()。当 Redis 监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在 accept() 函数这里,导致其他客户端无法和 Redis 建立连接。类似的,当 Redis 通过 recv() 从一个客户端读取数据时,如果数据一直没有到达,Redis 也会一直阻塞在 recv()。这就导致 Redis 整个线程阻塞,无法处理其他客户端请求,效率很低。socket非阻塞模式
在 socket 模型中,不同操作调用后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用 accept() 方法接收到达的客户端连接,并返回已连接套接字。
针对监听套接字,我们可以设置非阻塞模式:当 Redis 调用 accept() 但一直未有连接请求到达时,Redis 线程可以返回处理其他操作,而不用一直等待。但是,你要注意的是,调用 accept() 时,已经存在监听套接字了。
虽然 Redis 线程可以不用继续等待,但是总得有机制继续在监听套接字上等待后续连接请求,并在有请求时通知 Redis。类似的,我们也可以针对已连接套接字设置非阻塞模式:Redis 调用 recv() 后,如果已连接套接字上一直没有数据到达,Redis 线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知 Redis。基于多路复用的高性能 I/O 模型
Linux 中的 IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
下图就是基于多路复用的 Redis IO 模型。图中的多个 FD 就是刚才所说的多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。此时,Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
那么,回调机制是怎么工作的呢?其实,select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。
同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。I/O三种多路复用机制select/poll/epoll区别:select、poll、epoll之间的区别(搜狗面试) - aspirant - 博客园



3.1.4 Redis持久化-AOF日志
概念
AOF( Append Only File)日志是写后日志,即先把数据写入内存,然后才记录日志。
AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。优点
写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志中,否则,系统就会直接向客户端报错。
所以,Redis 使用写后日志这一方式的一大好处是,可以避免出现记录错误命令的情况。除此之外,AOF 还有一个好处:它是在命令执行后才记录日志,所以不会阻塞当前的写操作。缺点与风险
如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数据就有丢失的风险。
其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行了。三种写回策略
其实,对于这个问题,AOF 机制给我们提供了三个选择,也就是 AOF 配置项 appendfsync 的三个可选值。
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
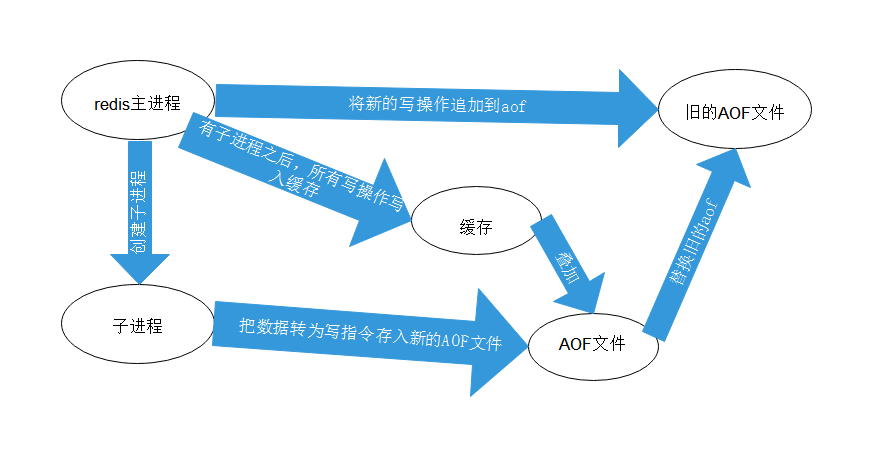
AOF 重写机制
当AOF文件过大时,追加记录或者宕机加载效率会非常低下,当文件大小超过一定阈值时,会触发AOF重写机制。
AOF重写并不需要对原有AOF文件进行任何的读取,写入,分析等操作,这个功能是通过读取服务器当前的数据库状态,并将其对应的set命令写入新建的AOF文件。
重写的过程总结为“一个拷贝,两处日志”。
“一个拷贝”就是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
“两处日志”又是什么呢?因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,第一处日志就是指正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。这样一来,即使宕机了,这个 AOF 日志的操作仍然是齐全的,可以用于恢复。而第二处日志,就是指新的 AOF 重写日志。这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。
总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;然后,使用两个日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行数据重写,所以,这个过程并不会阻塞主线程。

3.1.5 Redis持久化-RDB快照
[Redis]Redis持久化之RDB快照_GanZiQim的技术备忘录-CSDN博客
RDB(Redis DataBase),内存快照,将某一时刻存在于内存中的数据保存到本地文件中,快照文件以.rdb后缀保存。
具体过程:
1、Redis调用fork创建一个子进程。(父子进程共享内存,直至其中一个进程对内存进行了写操作,父进程要更改其中某片数据时(如执行一个写命令 ),操作系统会将该片数据复制一份以保证子进程的数据不受影响)
2、子进程负责将数据写入一个临时文件,父进程则继续处理数据库读写请求。
3、完全写入成功后,调用rename将新的RDB文件替换原来的RDB文件。
和 AOF 相比,RDB 记录的是某一时刻的数据,并不是操作,所以,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复。
数据范围
Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中。创建快照
Redis提供了两条命令用于手动创建快照,分别是 save 和 bgsave。
save:调用SAVE命令时,Redis会执行同步保存,阻塞所有客户端,不再响应客户端发送的请求。SAVE命令一般来说只用于没有足够内存执行BGSAVE命令,或者对于等待保存占用的时间不敏感时才会使用。调用SHUTDOWN命令关闭服务器时也会先执行一次SAVE命令。在主线程中执行,会导致阻塞;
bgsave:调用BGSAVE命令时,会创建一个子进程,在后台异步地保存当前数据库中的数据,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。优点
通过合理的配置,可以让Redis每隔一段时间就保存一次数据库副本,也可以很方便地将数据还原到特定的时间点。
RDB文件相比AOF占用的空间更小,恢复数据的速度也更快。
如果创建RDB文件时出现了错误,Redis不会将它用于替换原来的文件,所以出错时不会影响到之前保存的版本。缺点
如果硬件、系统、Redis三者其中之一出现问题而崩溃,Redis会丢失全部数据,保留下来的数据只有上一个时间点创建的快照。如果数据对于应用程序来说非常重要,那么出现错误时的损失会非常大。
fork子进程占用的内存随着数据库中数据的增加而增加,耗费的时间也会越来越多。与AOF的结合
在两次快照之间,如果发生宕机,数据库只保存有上一时间节点的快照,会遗失该节点到此刻的数据变化。对此,若采用高频率的快照,会带来两方面问题:频繁进行写操作对磁盘造成压力;bgsave子进程不会阻塞主程序,但主程序在执行fork操作时会阻塞,内存越大,阻塞时间越长。
对此,采用AOF日志和内存快照混用方法:内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。如下图所示,T1 和 T2 时刻的修改,用 AOF 日志记录,等到第二次做全量快照时,就可以清空 AOF 日志,因为此时的修改都已经记录到快照中了,恢复时就不再用日志了。


3.2 主从复制、哨兵机制与集群
Redis架构模型:单机模式、主从模式、哨兵模式、集群模式
3.2.1 主从复制
Redis 具有高可靠性,又是什么意思呢?其实,这里有两层含义:一是数据尽量少丢失,二是服务尽量少中断。
AOF 和 RDB 保证了前者,而对于后者,Redis 的做法就是增加副本冗余量,将一份数据同时保存在多个实例上。即使有一个实例出现了故障,需要过一段时间才能恢复,其他实例也可以对外提供服务,不会影响业务使用。读写模式
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
读操作:主库、从库都可以接收;
写操作:首先到主库执行,然后,主库将写操作同步给从库。第一次同步流程
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
在第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
(具体流程和报文含义看极客)主从级联模式
主从库间第一次数据同步是全量复制,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。如果从库数量很多,就会导致主库忙于 fork 子进程生成 RDB 文件。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。对此,采用“主 - 从 - 从”模式。
“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
主从库连接断开
一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
这个过程中存在着风险点,最常见的就是网络断连或阻塞。如果网络断连,主从库之间就无法进行命令传播了,客户端就可能从从库读到旧数据。
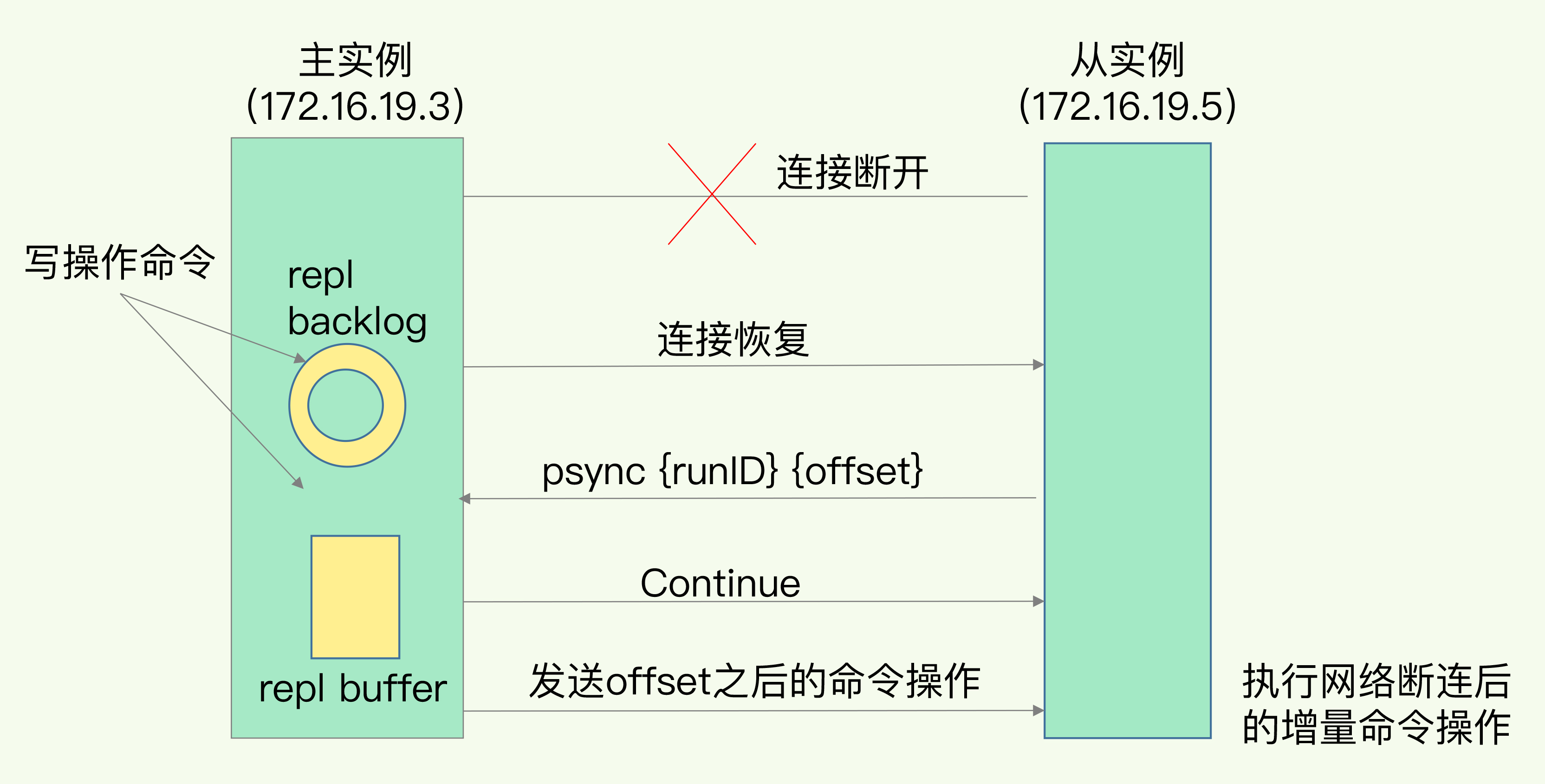
在 Redis 2.8 之前,如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制。从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。增量复制
增量复制只会把主从库网络断连期间主库收到的命令,同步给从库。
当主从库断连后,主库会把断连期间收到的写操作命令,写入 replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
主库对应的偏移量是 master_repl_offset, 从库的偏移量 slave_repl_offse。在网络断连阶段,主库可能会收到新的写操作命令,所以,一般来说,master_repl_offset 会大于 slave_repl_offset。恢复连接后,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。
增量复制流程图:
增量复制风险
因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。
对此,可以适当调整和缓冲空间大小有关的 repl_backlog_size 这个参数。小结
Redis 的主从库同步有三种模式:全量复制、基于长连接的命令传播,以及增量复制。
使用建议:
一个 Redis 实例的数据库不要太大,一个实例大小在几 GB 级别比较合适,这样可以减少 RDB 文件生成、传输和重新加载的开销。
另外,为了避免多个从库同时和主库进行全量复制,给主库过大的同步压力,我们也可以采用“主 - 从 - 从”这一级联模式,来缓解主库的压力。【Redis】主从同步可能遇到的坑 - 扯 - 博客园z
主从复制可能存在的问题:
主从数据不一致、从库读取到过期数据




3.2.2 哨兵机制
在Redis主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的这三个问题:主库真的挂了吗?该选择哪个从库作为主库?怎么把新主库的相关信息通知给从库和客户端呢?
基本流程
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从库实例运行的同时,它也在运行。哨兵主要负责的就是三个任务:监控、选主(选择主库)和通知。
监控是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。如果没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为“下线状态”;若主库下线,将开始自动切换主库的流程。
主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库。
在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行 replicaof 命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。
通知任务相对来说比较简单,哨兵只需要把新主库信息发给从库和客户端,让它们和新主库建立连接就行,并不涉及决策的逻辑。但是,在监控任务中,哨兵需要判断主库是否处于下线状态;在选主任务中,哨兵也要决定选择哪个从库实例作为主库。
监控
主观下线
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况。如果PING 命令的响应超时了,哨兵就会先把它标记为“主观下线”。
如果从库被标记为“主观下线”,将会直接被认为已下线;若主库被标记为“主观下线”,由于主库下线需要进行选主、主从切换、通知,这会带来额外开销,所以还需要其他辅助来确认是否真正下线,以此来避免因集群网络压力较大、网络拥塞等因素造成的误判。
客观下线
哨兵机制通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。在主库被标记为“主观下线”后,还需要进行“客观下线”的判断在确认主库是否下线。
“客观下线”即进行多次“主观下线”判断。比如,当有 N 个哨兵实例时,要有 N/2 + 1 个(用户自定义)实例判断主库为“主观下线”,才能最终判定主库为“客观下线”。这样一来,就可以减少误判的概率,也能避免误判带来的无谓的主从库切换。选主
在多个从库中,先按照一定的筛选条件,把不符合条件的从库去掉。然后,我们再按照一定的规则,给剩下的从库逐个打分,将得分最高的从库选为新主库。
筛选
除了要检查从库的当前在线状态,还要判断它之前的网络连接状态。如果从库总是和主库断连,而且断连次数超出了一定的阈值,我们就有理由相信,这个从库的网络状况并不是太好,就可以把这个从库筛掉了。
打分
可以分别按照三个规则依次进行三轮打分:从库优先级、从库复制进度以及从库 ID 号。只要在某一轮中,有从库得分最高,那么它就是主库了,选主过程到此结束。


3.2.3 哨兵集群
基于 pub/sub 机制的哨兵集群组成
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制。
哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信息(IP 和端口)。同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
除了哨兵实例,我们自己编写的应用程序也可以通过 Redis 进行消息的发布和订阅。所以,为了区分不同应用的消息,Redis 会以频道的形式,对这些消息进行分门别类的管理。所谓的频道,实际上就是消息的类别。当消息类别相同时,它们就属于同一个频道。反之,就属于不同的频道。只有订阅了同一个频道的应用,才能通过发布的消息进行信息交换。
哨兵除了彼此之间建立起连接形成集群外,还需要和从库建立连接。这是因为,在哨兵的监控任务中,它需要对主从库都进行心跳判断,而且在主从库切换完成后,它还需要通知从库,让它们和新主库进行同步。
哨兵是如何知道从库的 IP 地址和端口:
这是由哨兵向主库发送 INFO 命令来完成的。哨兵 2 给主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵。
基于 pub/sub 机制的客户端事件通知
客户端通过该机制监控了解哨兵进行主从切换的过程。
从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。
具体的操作步骤是,客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。由哪个哨兵执行主从切换
确定由哪个哨兵执行主从切换的过程,和主库“客观下线”的判断过程类似,也是一个“投票仲裁”的过程。
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
投票依据:发现“主观下线”的哨兵会自荐成为Leader。哨兵如果没有给自己投票,就会把票投给第一个给它发送投票请求的哨兵。后续再有投票请求来,哨兵就拒接投票了。
如果第一次投票没有结果,哨兵集群会等待一段时间(也就是哨兵故障转移超时时间的 2 倍),再重新选举。这是因为,哨兵集群能够进行成功投票,很大程度上依赖于选举命令的正常网络传播。如果网络压力较大或有短时堵塞,就可能导致没有一个哨兵能拿到半数以上的赞成票。所以,等到网络拥塞好转之后,再进行投票选举,成功的概率就会增加。
需要注意的是,如果哨兵集群只有 2 个实例,此时,一个哨兵要想成为 Leader,必须获得 2 票,而不是 1 票。所以,如果有个哨兵挂掉了,那么,此时的集群是无法进行主从库切换的。因此,通常我们至少会配置 3 个哨兵实例。



3.2.4 切片集群
为了保存大量数据,我们使用了大内存云主机和切片集群两种方法。实际上,这两种方法分别对应着 Redis 应对数据量增多的两种方案:纵向扩展(scale up)和横向扩展(scale out)。
纵向扩展
升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。
纵向扩展的好处是,实施起来简单、直接。不过,这个方案也面临两个潜在的问题。第一个问题是,当使用 RDB 对数据进行持久化时,如果数据量增加,需要的内存也会增加,主线程 fork 子进程时就可能会阻塞(比如刚刚的例子中的情况)。不过,如果你不要求持久化保存 Redis 数据,那么,纵向扩展会是一个不错的选择。不过,这时,你还要面对第二个问题:纵向扩展会受到硬件和成本的限制。这很容易理解,毕竟,把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了。横向扩展
即切片集群,也叫分片集群,就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。
与纵向扩展相比,横向扩展是一个扩展性更好的方案。这是因为,要想保存更多的数据,采用这种方案的话,只用增加 Redis 的实例个数就行了,不用担心单个实例的硬件和成本限制。在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。数据切片和实例的对应分布关系
Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
具体的映射过程分为两大步:首先根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数。(在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。)
客户端如何定位数据
在定位键值对数据时,它所处的哈希槽是可以通过计算得到的,这个计算可以在客户端发送请求时来执行。但是,要进一步定位到实例,还需要知道哈希槽分布在哪个实例上。
一般来说,客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。但是,在集群刚刚创建的时候,每个实例只知道自己被分配了哪些哈希槽,是不知道其他实例拥有的哈希槽信息的。
那么,客户端为什么可以在访问任何一个实例时,都能获得所有的哈希槽信息呢?这是因为,Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
在集群中,实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
Redis Cluster 方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令。
当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。


3.3 实践应用
3.3.1 过期策略
Redis过期策略 实现原理_xiangnan129的专栏-CSDN博客_redis过期原理
在使用redis时,一般会设置一个过期时间,当然也有不设置过期时间的,也就是永久不过期。设置过期时间
expire key time(以秒为单位)--这是最常用的方式
setex(String key, int seconds, String value)--字符串独有的方式
注:除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间。如果没有设置时间,那缓存就是永不过期。如果设置了过期时间,之后又想让缓存永不过期,使用persist key。三种过期策略:
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key定时器的创建耗时。若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重。懒汉式删除(惰性删除)
含义:key过期的时候不删除,每次通过key获取值的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在通过key取值的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)定期删除
含义:每隔一段时间执行一次删除过期key操作
优点:通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点;定期删除过期key--处理"懒汉式删除"的缺点
缺点:在内存友好方面,不如"定时删除"(会造成一定的内存占用,但是没有懒汉式那么占用内存); 在CPU时间友好方面,不如"懒汉式删除"(会定期的去进行比较和删除操作,cpu方面不如懒汉式,但是比定时好)
难点:合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了),每次执行时间太长,或者执行频率太高对cpu都是一种压力。每次进行定期删除操作执行之后,需要记录遍历循环到了哪个标志位,以便下一次定期时间来时,从上次位置开始进行循环遍历。Redis采用的过期策略
懒汉式删除+定期删除
懒汉式删除流程:
a. 在进行get或setnx等操作时,先检查key是否过期;
b. 若过期,删除key,然后执行相应操作;
c. 若没过期,直接执行相应操作;
定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key):
a. 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
b. 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体是下边的描述)
b1. 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
b2. 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
b3. 判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。在使用懒汉式删除+定期删除时,控制时长和频率这个尤为关键,需要结合服务器性能,已经并发量等情况进行调整。
3.3.2 内存淘汰策略
Redis的过期策略以及内存淘汰机制_Felix-CSDN博客_redis内存淘汰机制
8种淘汰策略
no-eviction:当内存不足以容纳新写入数据时,新写入操作会报错,无法写入新数据,一般不采用。
allkeys-lru:当内存不足以容纳新写入数据时,移除最近最少使用的key,这个是最常用的allkeys-random:当内存不足以容纳新写入的数据时,随机移除key
allkeys-lfu:当内存不足以容纳新写入数据时,移除最不经常(最少)使用的key
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的key中,移除最近最少使用的key。
volatile-random:内存不足以容纳新写入数据时,在设置了过期时间的key中,随机移除某个key 。
volatile-lfu:当内存不足以容纳新写入数据时,在设置了过期时间的key中,移除最不经常(最少)使用的key
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,优先移除过期时间最早(剩余存活时间最短)的key。执行内存淘汰策略时机
redis.conf配置文件中的 maxmemory 属性限定了 Redis 最大内存使用量,当占用内存大于maxmemory的配置值时会执行内存淘汰策略。内存淘汰策略的配置
内存淘汰机制由redis.conf配置文件中的maxmemory-policy属性设置,没有配置时默认为no-eviction模式。淘汰策略的执行过程
客户端执行一条命令,导致Redis需要增加数据(比如set key value);
Redis会检查内存使用情况,如果内存使用超过 maxmemory,就会按照配置的置换策略maxmemory-policy删除一些key;
再执行新的数据的set操作;LRU【最近最久未使用】
标准LRU算法:把数据存放在链表中按照“最近访问”的顺序排列,当某个key被访问时就将此key移动到链表的头部,保证了最近访问过的元素在链表的头部或前面。当链表满了之后,就将"最近最久未使用"的,即链表尾部的元素删除,再将新的元素添加至链表头部。
因为标准LRU算法需要消耗大量的内存,所以Redis采用了一种近似LRU的做法:给每个key增加一个大小为24bit的属性字段,代表最后一次被访问的时间戳。然后随机采样出5个key,淘汰掉最旧的key,直到Redis占用内存小于maxmemory为止。其中随机采样的数量可以通过Redis配置文件中的 maxmemory_samples 属性来调整,默认是5,采样数量越大越接近于标准LRU算法,但也会带来性能的消耗。
在Redis 3.0以后增加了LRU淘汰池,进一步提高了与标准LRU算法效果的相似度。淘汰池即维护的一个数组,数组大小等于抽样数量 maxmemory_samples,在每一次淘汰时,新随机抽取的key和淘汰池中的key进行合并,然后淘汰掉最旧的key,将剩余较旧的前面5个key放入淘汰池中待下一次循环使用。假如maxmemory_samples=5,随机抽取5个元素,淘汰池中还有5个元素,相当于变相的maxmemory_samples=10了,所以进一步提高了与LRU算法的相似度。LFU【最近最少使用】
假设在位置※时需要删除一个元素,对比A和B,如果使用LRU,那么删除的应该是A,因为A上次被访问距现在的时间更长,但我们发现这是不合理的,因为其实A元素被访问更频繁、更热点,所以我们实际希望删除的是B,保留A,LFU就是为应对这种情况而生的。
在Redis LFU算法中,为每个key维护了一个计数器,每次key被访问的时候,计数器增大,计数器越大,则认为访问越频繁。但其实这样会有问题:
1、因为访问频率是动态变化的,前段时间频繁访问的key,之后也可能很少再访问(如微博热搜)。为了解决这个问题,Redis记录了每个key最后一次被访问的时间,随着时间的推移,如果某个key再没有被访问过,计数器的值也会逐渐降低。
2、新生key问题,对于新加入缓存的key,因为还没有被访问过,计数器的值如果为0,就算这个key是热点key,因为计数器值太小,也会被淘汰机制淘汰掉。为了解决这个问题,Redis会为新生key的计数器设置一个初始值。
上面说过在Redis LRU算法中,会给每个key维护一个大小为24bit的属性字段,代表最后一次被访问的时间戳。在LFU中也维护了这个24bit的字段,不过被分成了16 bits与8 bits两部分:
16 bits 8 bits
+--------------------+------------+
+ Last decr time | LOG_C |
+--------------------+------------+
其中高16 bits用来记录计数器的上次缩减时间,时间戳,单位精确到分钟。低8 bits用来记录计数器的当前数值。
在redis.conf配置文件中还有2个属性可以调整LFU算法的执行参数:lfu-log-factor、lfu-decay-time。其中lfu-log-factor用来调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。lfu-decay-time是一个以分钟为单位的数值,用来调整counter的缩减速度。
3.3.3 缓存穿透、缓存雪崩、缓存击穿
原文链接:https://blog.csdn.net/zeb_perfect/article/details/54135506
缓存处理流程
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
1.使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
2. "提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
3. "永远不过期":
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期;
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
4. 资源保护:
采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。

3.3.4 缓存预热、缓存更新、缓存降级
当下热点词再学:redis缓存预热、更新、降级,限流_看,未来的博客-CSDN博客
缓存预热
系统冷启动:
当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,这种情况就叫“系统冷启动”,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
解决方案
提前给redis中嵌入部分数据,再提供服务。因为数据量太大了,肯定不可能将所有数据都写入redis,第一耗费的时间太长了,第二redis根本就容纳不下所有的数据。
所以,需要更具当天的具体访问情况,统计出频率较高的热数据。然后将访问频率较高的热数据写入到redis,如果说热数据也比较多,我们也得多个服务并行的读取数据去写,并行的分布式的缓存预热。然后将嵌入的热数据的redis对外提供服务,这样就不至于冷启动,直接让数据库崩溃了。缓存更新
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。如何解决并发场景下更新操作的双写一致是缓存系统的一个重要知识点。
即数据一致性,在开头的那篇博客里已经讲得挺详尽了。
那就再提一嘴,延时双删,这里就不展开了,挺多的。缓存降级
就是压力过大服务器扛不住,需要适当的取舍。
降级:就是在高并发高负载情况下,选择动态的关闭一下不重要的服务,拒绝访问等,来为重要的服务节省资源,比如电商平台秒杀当天可关闭推荐等功能。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
限流
如果降级解决不了的压力,那就只有限流了。
限流之前在MQ的那篇文章里面有讲过:消息队列:解耦、异步、削峰,现有MQ对比以及新手入门该如何选择MQ?
限流:就相当于调整水龙头的大小,使得访问请求量控制在一定范围。
对于比较关键又高并发的服务,比如秒杀,不能通过缓存和降级方式解决,至少不够解决太大并发量。这时候就需要限流了。
3.3.5 数据一致性
当遇到数据更新时,缓存和数据库的更新、删除顺序对并发访问有较大影响,大致有如下几种策略:
先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?有如下两点原因。
原因一(线程安全角度)
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
原因二(业务场景角度)
写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。先删除缓存,再更新数据库
假设线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,那么这个时候,线程 B 会发现缓存缺失,就只能去数据库读取。
这会带来两个问题:线程 B 读取到了旧值;线程 B 是在缓存缺失的情况下读取的数据库,所以,它还会把旧值写入缓存,这可能会导致其他线程从缓存中读到旧值。等到线程 B 从数据库读取完数据、更新了缓存后,线程 A 才开始更新数据库,此时,缓存中的数据是旧值,而数据库中的是最新值,两者就不一致了。
解决办法:延迟双删
在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作。
之所以要加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程 A 再进行删除。所以,线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间。这个时间怎么确定呢?建议你在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,以此为基础来进行估算。先更新数据库值,再删除缓存值
如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。不过,在这种情况下,如果其他线程并发读缓存的请求不多,那么,就不会有很多请求读取到旧值。而且,线程 A 一般也会很快删除缓存值,这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。
小结



3.3.6 与memcache区别
https://blog.csdn.net/liuerchong/article/details/107923555
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,redis可以持久化其数据
2)、数据支持类型 memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结构的存储
3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4). value 值大小不同:Redis 最大可以达到 512M;memcache 只有 1mb。
5)redis的速度比memcached快很多
6)Redis支持数据的备份,即master-slave模式的数据备份。https://blog.csdn.net/lhx574938077/article/details/81838819
从数据结构上来说,redis在kv模式上,支持5中数据结构,String、list、hash、set、zset,并支持很多相关的计算,比如排序、阻塞等,而memcache只支持kv简单存储。所以当你的缓存中不只需要存储kv模型的数据时,redis丰富的数据操作空间,绝对是非常好的选择,另外说一句,利用redis可以高效的实现类似于单集群下的阻塞队列、锁及线程通信等功能。
从可靠性的角度来说,redis支持持久化,有快照和AOF两种方式,而memcache是纯的内存存储,不支持持久化的。
从内存管理方面来说,redis也有自己的内存机制,redis采用申请内存的方式,会把带过期时间的数据存放到一起,redis理论上能够存储比物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上。而memcache把所有的数据存储在物理内存里。memcache使用预分配池管理,会提前把内存分为多个slab,slab又分成多个不等大小的chunk,chunk从最小的开始,根据增长因子增长内存大小。redis更适合做数据存储,memcache更适合做缓存,memcache在存储速度方面也会比redis这种申请内存的方式来的快。
从数据一致性来说,memcache提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 redis是串行操作,所以不用考虑数据一致性的问题。
从IO角度来说,选用的I/O多路复用模型,虽然单线程不用考虑锁等问题,但是还要执行kv数据之外的一些排序、聚合功能,复杂度比较高。memcache也选用非阻塞的I/O多路复用模型,速度更快一些。
从线程角度来说,memcahce使用多线程,主线程listen,多个worker子线程执行读写,可能会出现锁冲突。redis是单线程的,这样虽然不用考虑锁对插入修改数据造成的时间的影响,但是无法利用多核提高整体的吞吐量,只能选择多开redis来解决。
从集群方面来说,redis天然支持高可用集群,支持主从,而memcache需要自己实现类似一致性hash的负载均衡算法才能解决集群的问题,扩展性比较低。
另外,redis集成了事务、复制、lua脚本等多种功能,功能更全。redis功能这么全,是不是什么情况下都使用redis就行了呢?
非也,redis确实比memcache功能更全,集成更方便,但是memcache相比redis在内存、线程、IO角度来说都有一定的优势,可以利用cpu提高机器性能,在不考虑扩展性和持久性的访问频繁的情况下,只存储kv格式的数据,建议使用memcache,memcache更像是个缓存,而redis更偏向与一个存储数据的系统。但是,觉得不要拿redis当数据库用!!!
3.3.7 Redis数据结构适用场景
https://blog.csdn.net/liuerchong/article/details/107923555
String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适—取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。高级的4种:
HyperLogLog:通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有0.81%标准差(standard error)的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
Geo:redis 3.2 版本的新特性。可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作:获取2个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。Bitmap:位图。
Stream:主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
3.4 杂
redis常见面试题集锦_liuerchong的博客-CSDN博客
Redis 常见性能问题
Redis原子性
Redis事务
四、网络
4.1 基础
4.1.1 网络七层模型
ISO七层模型_Rui_Freely的博客-CSDN博客_iso七层模型


4.1.2 HTTP协议内容
http请求报文格式和响应报文格式_bamboo_cqh的博客-CSDN博客_报文格式
工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP 协议采用请求/响应模型。客户端向服务器发送一个请求报文,服务器以一个状态作为响应。
以下是 HTTP 请求/响应的步骤:
● 客户端连接到web服务器:HTTP 客户端与web服务器建立一个 TCP 连接;
● 客户端向服务器发起 HTTP 请求:通过已建立的TCP 连接,客户端向服务器发送一个请求报文;
● 服务器接收 HTTP 请求并返回 HTTP 响应:服务器解析请求,定位请求资源,服务器将资源副本写到 TCP 连接,由客户端读取;
● 释放 TCP 连接:若connection 模式为close,则服务器主动关闭TCP 连接,客户端被动关闭连接,释放TCP 连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
● 客户端浏览器解析HTML内容:客户端将服务器响应的 html 文本解析并显示;主要特点:
支持客户/服务器模式。
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。为了解决这个问题, Web程序引入了Cookie机制来维护状态。HTTP 持久连接
HTTP1.0 使用的是非持久连接,主要缺点是客户端必须为每一个待请求的对象建立并维护一个新的连接,即每请求一个文档就要有两倍RTT 的开销。因为同一个页面可能存在多个对象,所以非持久连接可能使一个页面的下载变得十分缓慢,而且这种短连接增加了网络传输的负担。HTTP1.1 使用持久连接keepalive,所谓持久连接,就是服务器在发送响应后仍然在一段时间内保持这条连接,允许在同一个连接中存在多次数据请求和响应,即在持久连接情况下,服务器在发送完响应后并不关闭TCP 连接,而客户端可以通过这个连接继续请求其他对象。GET和POST区别
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中;
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制;
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值;
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码;
4.1.3 HTTP协议报文格式
HTTP协议报文解析_yutiab69的博客-CSDN博客_http协议报文
HTTP 报文由请求行、请求头和请求体 3 个部分组成请求报文:
请求行:请求行由方法字段、URL 字段 和HTTP 协议版本字段 3 个部分组成,他们之间使用空格隔开。常用的 HTTP 请求方法有 GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT;
请求头:
请求报文示例:POST /search HTTP/1.1 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-silverlight, application/x-shockwave-flash, */* Referer: http://www.google.cn/ Accept-Language: zh-cn Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld) Host: www.google.cn Connection: Keep-Alive Cookie: PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g; NID=31=ojj8d-IygaEtSxLgaJmqSjVhCspkviJrB6omjamNrSm8lZhKy_yMfO2M4QMRKcH1g0iQv9u-2hfBW7bUFwVh7pGaRUb0RnHcJU37y- FxlRugatx63JLv7CWMD6UB_O_r hl=zh-CN&source=hp&q=domety响应报文:
响应状态码:
状态代码由服务器发出,以响应客户端对服务器的请求。
1xx(信息):收到请求,继续处理
2xx(成功):请求已成功接收,理解和接受
3xx(重定向):需要采取进一步措施才能完成请求
4xx(客户端错误):请求包含错误的语法或无法满足
5xx(服务器错误):服务器无法满足明显有效的请求
响应报文示例:HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Content-Type: text/html; charset=UTF-8 Content-Encoding: UTF-8 Content-Length: 138 Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux) ETag: "3f80f-1b6-3e1cb03b" Accept-Ranges: bytes Connection: close <html> <head> <title>An Example Page</title> </head> <body> Hello World, this is a very simple HTML document. </body> </html>HTTP与HTTPs协议区别:
http是超文本传输协议,是明文传输; https是在HTTP协议上加上SSL构成的安全传输协议;
https需要CA证书;
连接方式不同,http和https默认端口为80和443,https在http和tcp/ip间加上了SSL协议;




4.1.4 TCP协议
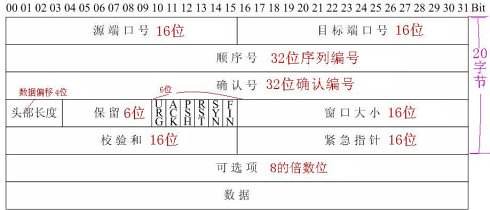
TCP报文格式详解_arthur.dy.lee的专栏-CSDN博客_tcp报文
1、端口号:用来标识同一台计算机的不同的应用进程。
1)源端口:源端口和IP地址的作用是标识报文的返回地址。
2)目的端口:端口指明接收方计算机上的应用程序接口。
TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。
2、序号和确认号:是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。e.g.一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
3、数据偏移/首部长度:4bits。由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8 = 60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
4、保留:为将来定义新的用途保留,现在一般置0。
5、控制位:URG ACK PSH RST SYN FIN,共6个,每一个标志位表示一个控制功能。
1)URG:紧急指针标志,为1时表示紧急指针有效,为0则忽略紧急指针。
2)ACK:确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段。
3)PSH:push标志,为1表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队。
4)RST:重置连接标志,用于重置由于主机崩溃或其他原因而出现错误的连接。或者用于拒绝非法的报文段和拒绝连接请求。
5)SYN:同步序号,用于建立连接过程,在连接请求中,SYN=1和ACK=0表示该数据段没有使用捎带的确认域,而连接应答捎带一个确认,即SYN=1和ACK=1。
6)FIN:finish标志,用于释放连接,为1时表示发送方已经没有数据发送了,即关闭本方数据流。
6、窗口:滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个16bit字段,因而窗口大小最大为65535。
7、校验和:奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
8、紧急指针:只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
9、选项和填充:最常见的可选字段是最长报文大小,又称为MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志为1的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是32位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证TCP头是32的整数倍。
10、数据部分: TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。TCP与UDP区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接;
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付;
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的;UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信;
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节;
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道;

4.2 网络
4.2.1 浏览器访问web过程
在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立 TCP 连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP 连接;
6、浏览器将该 html 文本并显示内容;
4.2.2 TCP三次握手四次挥手
TCP/IP协议 (图解+秒懂+史上最全) - 疯狂创客圈 - 博客园
问题:
问题(1):为什么关闭连接的需要四次挥手,而建立连接却只要三次握手呢?
问题(2):为什么连接建立的时候是三次握手,可以改成两次握手吗?
问题(3):为什么主动断开方在TIME-WAIT状态必须等待2MSL的时间?
问题(4):如果已经建立了连接,但是Client端突然出现故障了怎么办?


4.2.3 SSL
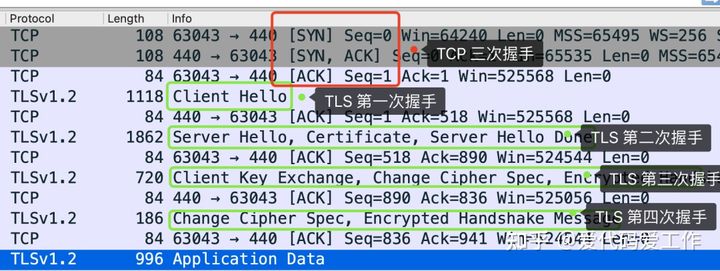
给面试官上一课:HTTPS是先进行TCP三次握手,再进行TLS四次握手 - 知乎
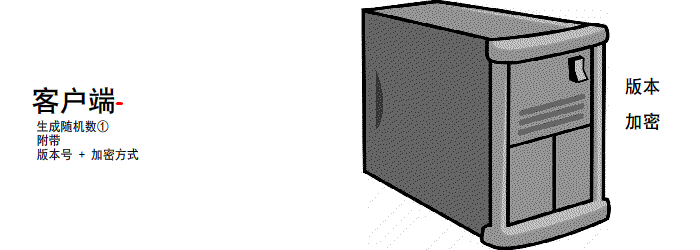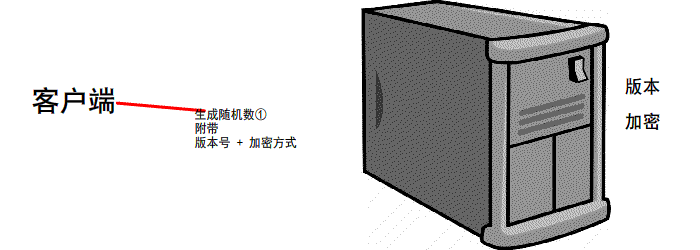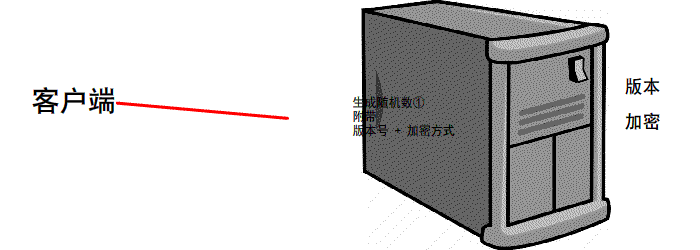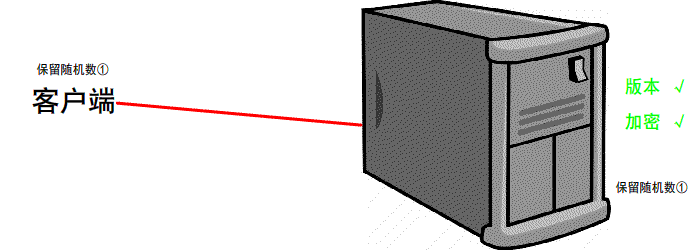
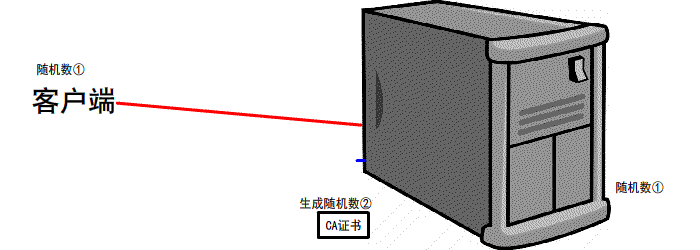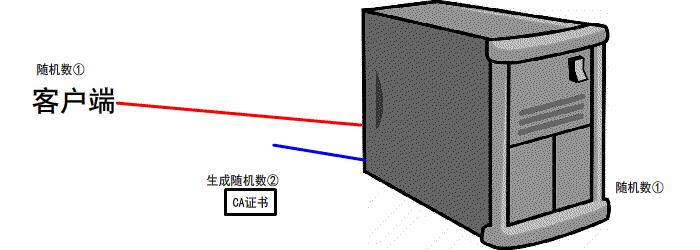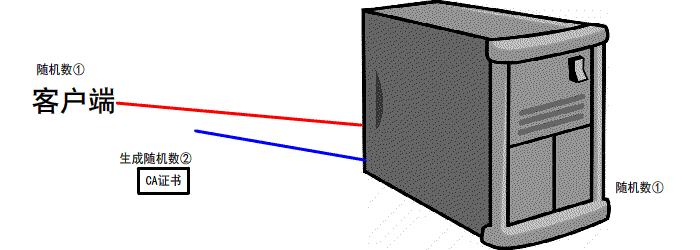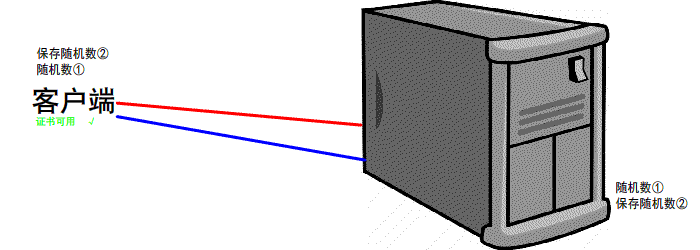
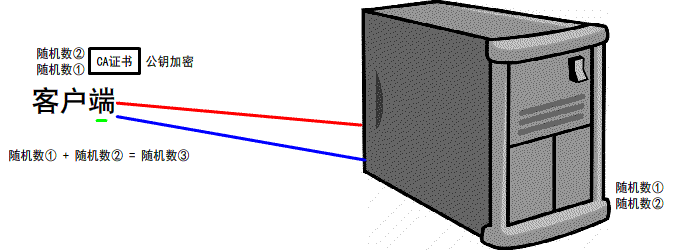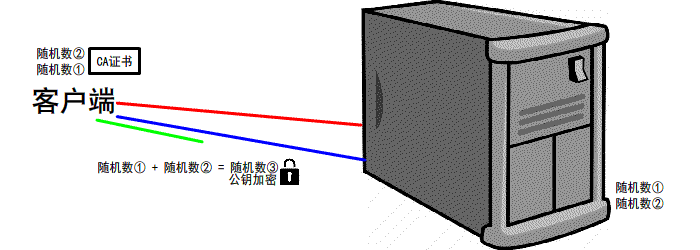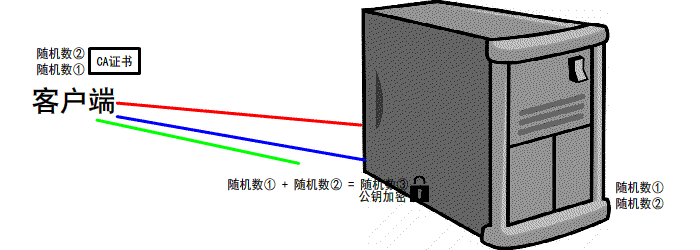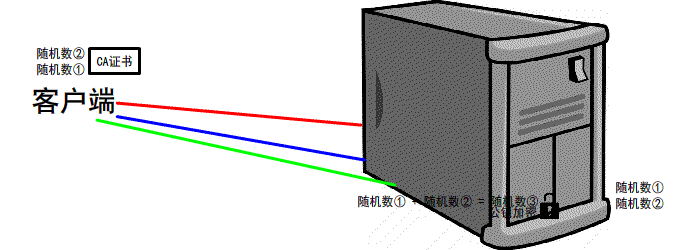
https://www.jianshu.com/p/6811285c577d第一次握手
有客户端生成随机数,并且携带着 版本号 以及 加密的方式
由服务器判断是否是 可用的/支持的 加密方式
if 版本号+加密方式 可用 那么可以 继续进行下一步操作
反之 本次 握手结束
第二次握手
服务器会 生成第二个 随机数 并且 携带者CA证书 发送给客户端
if 证书有效/可用
继续下一步操作
反之 本次握手结束
第三次握手
客户端 生成 第三个 随机数 并且值得一提的是 第三次的报文是可以携带数据的
并且使用CA证书中的公钥进行加密 再次发送给服务器
同时发送前2次 的信息 摘要 由服务器再次验证
服务器 会接收到 这第三个随机数 并且利用 证书中的私钥将其 解密
最后双方都会生成 一个对话秘钥
扩充: 我们前2次的过程是明文的 最后一次是加密的(公钥加密,私钥解密.非对称加密)
先进行TCP三次握手,再进行SSL校验
4.2.4 网络拥塞(拥塞控制)
TCP的拥塞控制(详解)_努力进阶的小菜鸟-CSDN博客_tcp拥塞控制
网络拥塞
对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏。TCP的四种拥塞控制算法:
慢开始、拥塞控制、快重传、快恢复总则:
在tcp双方建立逻辑链接关系时, 拥塞窗口cwnd的值被设置为1,还需设置慢开始门限ssthresh,在执行慢开始算法时,发送方每收到一个对新报文段的确认时,就把拥塞窗口cwnd的值加一,然后开始下一轮的传输,当拥塞窗口cwnd增长到慢开始门限值时,就使用拥塞避免算法。慢开始
假设当前发送方拥塞窗口cwnd的值为1,而发送窗口swnd等于拥塞窗口cwnd,因此发送方当前只能发送一个数据报文段(拥塞窗口cwnd的值是几,就能发送几个数据报文段),接收方收到该数据报文段后,给发送方回复一个确认报文段,发送方收到该确认报文后,将拥塞窗口的值变为2。发送方再次发送2个报文段且接收方收到后,会回复2个确认报文段,发送方将cwnd置未4。
当拥塞窗口cwnd的值已经等于慢开始门限值ssthresh时,改用拥塞避免算法。拥塞避免:
也就是每个传输轮次,拥塞窗口cwnd只能线性加一,而不是像慢开始算法时,每个传输轮次,拥塞窗口cwnd按指数增长。同理,16+1……直至到达24,假设24个报文段在传输过程中丢失4个,接收方只收到20个报文段,给发送方依次回复20个确认报文段,一段时间后,丢失的4个报文段的重传计时器超时了,发送方判断可能出现拥塞,开启超时重传机制:更改cwnd和ssthresh并重新开始慢开始算法。在网络传输中,个别报文段因意外丢失,而非网络拥塞导致接收方无法接受,此时若直接采用超时重传将cwnd置为1将严重影响传输效率,对此引入快重传和快开始机制。
快速重传:
发送方发送1号数据报文段,接收方收到1号报文段后给发送方发回对1号报文段的确认,在1号报文段到达发送方之前,发送方还可以将发送窗口内的2号数据报文段发送出去,接收方收到2号报文段后给发送方发回对2号报文段的确认,在2号报文段到达发送方之前,发送方还可以将发送窗口内的3号数据报文段发送出去。
假设该报文丢失,发送方便不会发送针对该报文的确认报文给发送方,发送方还可以将发送窗口内的4号数据报文段发送出去,接收方收到后,发现这不是按序到达的报文段,因此给发送方发送针对2号报文段的重复确认,表明我现在希望收到的是3号报文段,但是我没有收到3号报文段,而收到了未按序到达的报文段。对此,发送方还可以继续发送5号、6号报文段,接收方收到后,发现这不是按序到达的报文段,因此给发送方发送两次没有收到3号报文段,而收到了未按序到达的报文段。
此时,发送方收到了累计3个连续的针对2号报文段的重复确认,立即重传3号报文段,接收方收到后,给发送方发回针对6号报文的确认,表明,序号到6为至的报文都收到了,这样就不会造成发送方对3号报文的超时重传,而是提早收到了重传。快恢复:






4.2.5 滑动窗口(流量控制)
TCP-IP详解:滑动窗口(Sliding Window)_深邃 精致 内涵 坚持-CSDN博客_滑动窗口
滑动窗口是TCP协议中的概念,为了保证TCP的可靠性,在早期的TCP通信中,发送方发送一段报文后,需收到接收方发送的ACK报文才能再次发送下一报文,这严重影响通信性能,因此引出滑动窗口概念。
让发送的每一个包都有一个id,接收端必须对每一个包进行确认,这样设备A一次多发送几个片段,而不必等候ACK,同时接收端也要告知它能够收多少,这样发送端发起来也有个限制,当然还需要保证顺序性,不要乱序,对于乱序的状况,我们可以允许等待一定情况下的乱序,比如说先缓存提前到的数据,然后去等待需要的数据,如果一定时间没来就DROP掉,来保证顺序性!
发送端在发送消息后会维持一个计时器,当计时器超时还未收到ACK时,会进行重传。发送端数据分类
1. Sent and Acknowledged:这些数据表示已经发送成功并已经被确认的数据,比如图中的前31个bytes,这些数据其实的位置是在窗口之外了,因为窗口内顺序最低的被确认之后,要移除窗口,实际上是窗口进行合拢,同时打开接收新的带发送的数据;
2. Send But Not Yet Acknowledged:这部分数据称为发送但没有被确认,数据被发送出去,没有收到接收端的ACK,认为并没有完成发送,这个属于窗口内的数据。
3. Not Sent,Recipient Ready to Receive:这部分是尽快发送的数据,这部分数据已经被加载到缓存中,也就是窗口中了,等待发送,其实这个窗口是完全有接收方告知的,接收方告知还是能够接受这些包,所以发送方需要尽快的发送这些包;
4. Not Sent,Recipient Not Ready to Receive: 这些数据属于未发送,同时接收端也不允许发送的,因为这些数据已经超出了发送端所接收的范围。接收端数据分类
1. Received and ACK Not Send to Process:这部分数据属于接收了数据但是还没有被上层的应用程序接收,也是被缓存在窗口内;
2. Received Not ACK: 已经接收并,但是还没有回复ACK,这些包可能输属于Delay ACK的范畴了;
3. Not Received:有空位,还没有被接收的数据。发送方的窗口大小值是由接收方在三次握手的时候进行通告的,同时在接收过程中也不断的通告可以发送的窗口大小,来进行适应。
滑动窗口原理
TCP并不是每一个报文段都会回复ACK的,可能会对两个报文段发送一个ACK,也可能会对多个报文段发送1个ACK【累计ACK】,比如说发送方有1/2/3 3个报文段,先发送了2,3 两个报文段,但是接收方期望收到1报文段,这个时候2,3报文段就只能放在缓存中等待报文1的空洞被填上,如果报文1,一直不来,报文2/3也将被丢弃,如果报文1来了,那么会发送一个ACK对这3个报文进行一次确认。

4.2.6 拥塞控制和流量控制
TCP之 流量控制(滑动窗口)和 拥塞控制(拥塞控制的工作过程)_dangzhangjing97的博客-CSDN博客_tcp流量控制和拥塞控制
相同点
都是为了解决丢包问题;
实现机制都是让发送方发送的更慢、更少;不同点
(1)丢包位置不同
流量控制丢包位置是在接收端上
拥塞控制丢包位置是在路由器上
(2)作用的对象不同
流量控制的对象是接收方,怕发送方发的太快,使得接收方来不及处理
拥塞控制的对象是网络,怕发送发发的太快,造成网络拥塞,使得网络来不及处理联系
拥塞控制通常表示的是一个全局性的过程,它会涉及到网络中所有的主机、所有的路由器和降低网络传输性能的所有因素;
流量控制发生在发送端和接收端之间,只是点到点之间的控制。

五、SpringBoot
5.1 SpringMVC
应用问题:掘金
5.1.1 响应流程
掘金
工作原理
响应流程
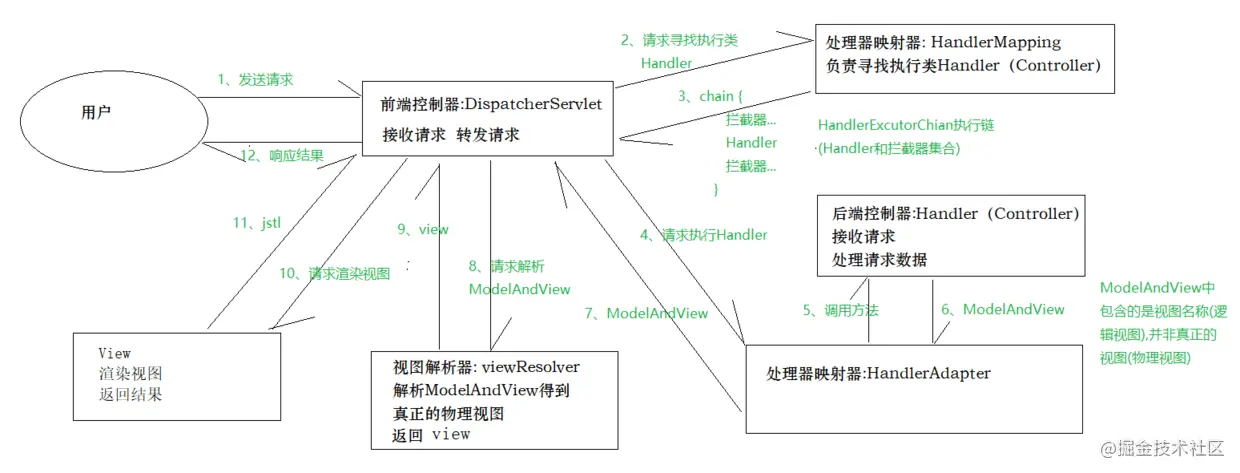
⑴ 用户发送请求至DispatcherServlet。
⑵ DispatcherServlet收到请求调用HandlerMapping查询具体的Handler。
⑶ HandlerMapping找到具体的处理器(具体配置的是哪个处理器的实现类),生成处理器对象及处理器拦截器(HandlerExcutorChain包含了Handler以及拦截器集合)返回给DispatcherServlet。
⑷ DispatcherServlet接收到HandlerMapping返回的HandlerExcutorChain后,调用HandlerAdapter请求执行具体的Handler(Controller)。
⑸ HandlerAdapter经过适配调用具体的Handler(Controller即后端控制器)。
⑹ Controller执行完成返回ModelAndView(其中包含逻辑视图和数据)给HandlerAdaptor。
⑺ HandlerAdaptor再将ModelAndView返回给DispatcherServlet。
⑻ DispatcherServlet请求视图解析器ViewReslover解析ModelAndView。
⑼ ViewReslover解析后返回具体View(物理视图)到DispatcherServlet。
⑽ DispatcherServlet请求渲染视图(即将模型数据填充至视图中) 根据View进行渲染视图。
⑾ 将渲染后的视图返回给DispatcherServlet。
⑿ DispatcherServlet将响应结果返回给用户。
5.1.2 核心组件
掘金
(1)前端控制器DispatcherServlet(配置即可)
功能:中央处理器,接收请求,自己不做任何处理,而是将请求发送给其他组件进行处理。
DispatcherServlet 是整个流程的控制中心。
(2)处理器映射器HandlerMapping(配置即可)
功能:根据DispatcherServlet发送的url请求路径查找Handler
常见的处理器映射器:BeanNameUrlHandlerMapping,SimpleUrlHandlerMapping,
ControllerClassNameHandlerMapping,DefaultAnnotationHandlerMapping(不建议使用)
(3)处理器适配器HandlerAdapter(配置即可)
功能:按照特定规则(HandlerAdapter要求的规则)去执行Handler。
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展多个适配器对更多类型的处理器进行执行。
常见的处理器适配器:HttpRequestHandlerAdapter,SimpleControllerHandlerAdapter,AnnotationMethodHandlerAdapter
(4)处理器Handler即Controller(程序猿编写)
功能:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler。
(5)视图解析器ViewReslover(配置即可)
功能:进行视图解析,根据逻辑视图名解析成真正的视图。
ViewResolver负责将处理结果生成View视图,ViewResolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。
springmvc框架提供了多种View视图类型,如:jstlView、freemarkerView、pdfView...
(6)视图View(程序猿编写)
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
5.1.3 SpringMVC对并发请求的处理
springMVC一个Controller处理所有用户请求的并发问题_u010523770的专栏-CSDN博客
有状态和无状态的对象基本概念:
有状态对象(Stateful Bean),就是有实例变量的对象 ,可以保存数据,是非线程安全的。一般是prototype scope。
无状态对象(Stateless Bean),就是没有实例变量的对象,不能保存数据,是不变类,是线程安全的。一般是singleton scope。对于那些会以多线程运行的单例类
局部变量不会受多线程影响,
成员变量会受到多线程影响。多个线程调用同一个对象的同一个方法:
如果方法里无局部变量,那么不受任何影响;
如果方法里有局部变量,只有读操作,不受影响;存在写操作,考虑多线程影响值;例如Web应用中的Servlet,每个方法中对局部变量的操作都是在线程自己独立的内存区域内完成的,所以是线程安全的。 对于成员变量的操作,可以使用ThreadLocal来保证线程安全。
springMVC中,一般Controller、service、DAO层的scope均是singleton;由于Spring MVC默认是Singleton的,所以会产生一个潜在的安全隐患。根本核心是instance变量保持状态的问题。这意味着每个request过来,系统都会用原有的instance去处理,这样导致了两个结果:
一是我们不用每次创建Controller,
二是减少了对象创建和垃圾收集的时间;
由于只有一个Controller的instance,当多个线程同时调用它的时候,它里面的instance变量就不是线程安全的了,会发生窜数据的问题。当然大多数情况下,我们根本不需要考虑线程安全的问题,比如dao,service等,除非在bean中声明了实例变量。因此,我们在使用spring mvc 的contrller时,应避免在controller中定义实例变量。有几种解决方法:
1、在控制器中不使用实例变量
2、将控制器的作用域从单例改为原型,即在spring配置文件Controller中声明 scope="prototype",每次都创建新的controller
3、在Controller中使用ThreadLocal变量这几种做法有好有坏,第一种,需要开发人员拥有较高的编程水平与思想意识,在编码过程中力求避免出现这种BUG,而第二种则是容器自动的对每个请求产生一个实例,由JVM进行垃圾回收,因此做到了线程安全。
使用第一种方式的好处是实例对象只有一个,所有的请求都调用该实例对象,速度和性能上要优于第二种,不好的地方,就是需要程序员自己去控制实例变量的状态保持问题。第二种由于每次请求都创建一个实例,所以会消耗较多的内存空间。
所以在使用spring开发web 时要注意,默认Controller、Dao、Service都是单例的
5.2 注解
5.2.1 @SpringBootApplication
https://blog.csdn.net/qq_36994125/article/details/103984736
@EnableAutoConfiguration的使用和原理_liangsheng_g的专栏-CSDN博客_enableautoconfiguration 使用
https://blog.csdn.net/zxc123e/article/details/80222967
@SpringBootConfiguration
此注解核心为@Configuration,派生自@component注解。
在启动类里加了@Configuration意味着启动类也是一个IOC容器的配置类。
任何一个加了@Configuration注解的类都是一个IOC容器配置类,在这个配置类中任何添加了@Bean注解的方法的返回值都会定义一个bean注册到spring容器管理,方法名默认是这个bean的id。相当于xml中的<bean id=“xxx” class=“xxx.xxx.xxx”/>@ComponentScan
ComponentScan注解的主要作用是扫描指定路径下标识了需要装配的类(默认扫描当前类路径),自动装配到Spring IOC容器管理。
标识需要装配的类主要形式是:@Component、@Repository、@Service、@Controller以及派生自@Component注解的注解。@EnableAutoConfiguration
自动导入应用程序所需的所有Bean——这依赖于Spring Boot在类路径中的查找。
此注解中最关键的是@Import(AutoConfigurationImportSelector.class),借助AutoConfigurationImportSelector,@EnableAutoConfiguration可以帮助SpringBoot应用将所有符合条件的@Configuration配置都加载到当前SpringBoot创建并使用的IoC容器。
在AutoConfigurationImportSelector类中通过Spring原有的工具类方法SpringFactoriesLoader.loadFactoryNames()
把spring-boot-autoconfigure.jar中/META-INF路径下的spring.factories文件中的org.springframework.boot.autoconfigure.EnableAutoConfiguration栏下每一个xxxAutoConfiguration都加载到容器中。@Autowired、@Resource
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了。@Resource有两个属性是比较重要的,分别是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
区别:
@Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
@Autowired默认按类型装配(这个注解是属于spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:@Autowired () @Qualifier ( "baseDao" ) private BaseDao baseDao;@Resource(这个注解属于J2EE的),默认按照名称进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource (name= "baseDao" ) private BaseDao baseDao;推荐使用:@Resource注解在字段上,这样就不用写setter方法了,并且这个注解是属于J2EE的,减少了与spring的耦合。这样代码看起就比较优雅。
@Configuration
配置类一@Configuration - LittleDonkey - 博客园
starter机制:
starter是spring boot项目的开箱即用机制,使得我们在开发业务时能方便的使用各种第三方中间件,也可以使用自己实现的starter依赖包,从而不需要过多的框架依赖的配置。
starer是spring boot中一个很重要的概念,starter相当于一个模块,它能将所需要的的依赖整合在一起并对模块内的bean自动装配到spring IOC容器,使用者只需要在maven中依赖相应的starter包并无需做过多的依赖即可进行开发。
starer就是结合自动装配和装配配置的实现,自己可创建项目结合spring boot注解加spring.factories和外部化配置实现自己的starer包。
原文链接:https://blog.csdn.net/qq_36994125/article/details/103984736
spring如何保证多线程的安全性
Spring如何保证线程安全_疯一样的女子-CSDN博客_spring如何保证线程安全
5.2.2 SpringBoot事务
当 Transactional 碰到锁,有个大坑!_Java后端技术-CSDN博客
SpringBoot事务Transaction 你真的懂了么?_菜鸟逆袭之路-CSDN博客
Spring中@Transactional什么时候开启事务?_Ydoing的专栏-CSDN博客
spring的事务是什么?与数据库的事务是否一样 - 南哥的天下 - 博客园数据库事务和spring事务的区别 - 小甜瓜安东泥 - 博客园
https://blog.csdn.net/acmman/article/details/82926410
为了确保springboot在操作数据库的一致性,需要进行事务控制。
Spring事务管理可以分为两种:编程式以及声明式。
编程式事务:使用编写代码的方式,进行事务的控制。
声明式事务:一般通过切面编程(AOP)的方式,注入到要操作的逻辑的前后,将业务逻辑与事务处理逻辑解耦。
由于使用声明式事务可以保证业务代码逻辑不会受到事务逻辑的污染, 所以在实际的工程中使用声明式事务比较多。
对于声明式事务的实现,在Java工程中一般有有两种方式:
(1)使用配置文件(XML)进行事务规则相关规则的声明;
(2)使用@Transactional注解进行控制。@Transactional
@Transactional不仅可以注解在方法上,也可以注解在类上。当注解在类上的时候意味着此类的所有public方法都是开启事务的。如果类级别和方法级别同时使用了@Transactional注解,则使用在方法级别的注解会重载类级别的注解。(在方法完成后事务才会结束,(提交或者回滚),所以需注意事务与锁的配合使用)
原理
在一个方法上加了@Transaction注解后,Spring会基于这个类生成一个代理对象,会将这个代理对象作为bean,当在使用这个代理对象的方法时,如果这个方法上存在@Transaction注解,那么代理逻辑会先把事务的自动提交设置为false,然后再去执行原本的业务逻辑方法,如果执行业务逻辑方法没有出现异常,那么代理逻辑中就会将事务进行提交,如果执行业务逻辑方法出现了异常,那么则会将事务进行回滚。
隔离级别
DEFAULT :这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是: READ_COMMITTED 。
READ_UNCOMMITTED :该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。
READ_COMMITTED :该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
REPEATABLE_READ :该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。
SERIALIZABLE :所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
指定方法:通过使用 isolation 属性设置,例如:
@Transactional(isolation = Isolation.DEFAULT)
传播行为
REQUIRED :如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
SUPPORTS :如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
MANDATORY :如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
REQUIRES_NEW :创建一个新的事务,如果当前存在事务,则把当前事务挂起。
NOT_SUPPORTED :以非事务方式运行,如果当前存在事务,则把当前事务挂起。
NEVER :以非事务方式运行,如果当前存在事务,则抛出异常。
NESTED :如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED 。
指定方法:通过使用 propagation 属性设置,例如:
@Transactional(propagation = Propagation.REQUIRED)在Spring Boot中使用@Transactional注解,只需要在启动类上添加@EnableTransactionManagement注解开启事务支持。
spring事务传播性理解 - longtengdama - 博客园
5.3 Spring
谈谈你对spring aop的理解_流离岁月的博客-CSDN博客_谈谈你对aop的理解
Spring常见面试题(2021最新版) - 简书
关于Spring面试题(2021)_呆呆啊噗g的博客-CSDN博客
Spring中Bean的生命周期是怎样的?_sinat_23619409的博客-CSDN博客_spring框架bean生命周期Spring框架中Bean的创建过程
Spring三级缓存解决循环依赖_傅红雪的专栏-CSDN博客
什么是循环依赖,Spring是如何解决的,为什么要使用三级缓存来解决,二级缓存不能吗_a15119273009的博客-CSDN博客
Spring中 BeanFactory和ApplicationContext的区别_慕课手记
5.4 Mybatis
5.5 面试
谈谈你对spring aop的理解_流离岁月的博客-CSDN博客_谈谈你对aop的理解
关于Spring面试题(2021)_呆呆啊噗g的博客-CSDN博客
Spring中Bean的生命周期是怎样的?_sinat_23619409的博客-CSDN博客_spring框架bean生命周期
Spring三级缓存解决循环依赖_傅红雪的专栏-CSDN博客
什么是循环依赖,Spring是如何解决的,为什么要使用三级缓存来解决,二级缓存不能吗_a15119273009的博客-CSDN博客
Spring中 BeanFactory和ApplicationContext的区别_慕课手记
2021年SpringBoot面试题30道_码农阿斌的博客-CSDN博客
六、虚拟机-JVM
https://blog.csdn.net/TJtulong/article/details/89598598
JDK、JRE与JVM之间的关系:
JDK全程为Java SE Development Kit(Java开发工具),提供了编译和运行Java程序所需的各种资源和工具,包括:JRE+java开发工具。
JRE全称为Java runtime environment(Java运行环境),包括:虚拟机+java的核心类库。
JVM是运行Java程序的核心虚拟机。
6.1 内存管理
6.1.1 内存模型
一文搞懂JVM内存结构__Rt-CSDN博客_jvm内存结构
程序计数器
程序计数器时线程独有的,用于记录当前线程所执行的字节码的行号指示器。此区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。如果线程执行的是java方法,这个计数器记录的是正在执行的虚拟字节码指令的地址。如果正在执行的是native方法,那么这个计数器的值为undefined。本地方法栈
用于调用本地方法服务。虚拟机栈
JVM 虚拟机栈详解_奔波儿灞-CSDN博客_jvm虚拟机栈
每当一个新的线程被创建时,Java 虚拟机都会分配一个虚拟机栈。Java虚拟机栈是以帧为单位来保存线程的运行状态。Java栈只会有两种操作:以帧为单位进行压栈跟出栈。
某个线程正在执行的方法称为当前方法。每个方法执行都要创建一个栈帧,方法执行完毕,栈帧销毁。每当线程调用当前方法时,都会将新栈帧压入,成为当前帧。jvm会使用它来存储我们的形参,局部变量,中间运行结果等,是线程独有的。
执行结束返回的方式会有两种,一种是 retuen正常返回,另外一种是通过异常来返回。无论哪种方式虚拟机都会释放弹出当前帧,这样上一个方法就成为了当前帧。
如果栈满了,StackOverFlowError,递归调用很常见。Java堆
堆是Java虚拟机所管理的内存中最大的一块存储区域。堆内存被所有线程共享。主要存放使用new关键字创建的对象。所有对象实例以及数组都要在堆上分配。
Java堆分为年轻代(Young Generation)和老年代(Old Generation);年轻代又分为伊甸园(Eden)和幸存区(Survivor区);幸存区又分为From Survivor空间和 To Survivor空间。年轻代存储“新生对象”,我们新创建的对象存储在年轻代中。当年轻内存占满后,会触发Minor GC,清理年轻代内存空间。老年代存储长期存活的对象和大对象。年轻代中存储的对象,经过多次GC后仍然存活的对象会移动到老年代中进行存储。老年代空间占满后,会触发Full GC。
注:Full GC是清理整个堆空间,包括年轻代和老年代。如果Full GC之后,堆中仍然无法存储对象,就会抛出OutOfMemoryError异常。
方法区
方法区同 Java 堆一样是被所有线程共享的区间,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码。更具体的说,静态变量+常量+类信息(版本、方法、字段等)+运行时常量池存在方法区中。常量池是方法区的一部分。也可能会抛出OutOfMemoryError异常。
JDK1.8 使用元空间 MetaSpace 替代方法区,元空间并不在 JVM中,而是使用本地内存。JDK1.8移除方法区,引进元空间概念

6.1.2 对象结构
Java对象由对象头、实例数据、对齐填充字节三部分组成。
对象头
Mark Word
类型指针klass
对象头的另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例
数组长度(只有数组对象有)
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度。实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。对齐填充字节
第三部分对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的倍数(1倍或者2倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。

6.1.3 对象创建
创建流程
对象内存分配
两种方式:指针碰撞和空闲列表。我们具体使用的哪一种,就要看我们虚拟机中使用的是什么垃圾回收机制了,如果有压缩整理,可以使用指针碰撞的分配方式。
指针碰撞:假设Java堆中内存是绝对规整的,所有用过的内存度放一边,空闲的内存放另一边,中间放着一个指针作为分界点的指示器,所分配内存就仅仅是把哪个指针向空闲空间那边挪动一段与对象大小相等的举例,这种分配方案就叫指针碰撞
空闲列表:有一个列表,其中记录中哪些内存块有用,在分配的时候从列表中找到一块足够大的空间划分给对象实例,然后更新列表中的记录,这就叫做空闲列表。对象的访问定位
对象的访问定位有两种方式:句柄访问和直接指针访问
句柄访问:Java堆中会划分出一块内存来作为句柄池,引用变量中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息。一个句柄又包含了两个地址,一个对象实例数据,一个是对象类型数据(这个在方法区中,因为类字节码文件就放在方法区中)。
直接指针访问:引用变量中存储的就直接是对象地址了,在堆中不会分句柄池,直接指向了对象的地址,对象中包含了对象类型数据的地址。HotSpot采用直接定位


6.2 垃圾回收算法
6.2.1 判断垃圾对象
java 对象存活分析——引用计数法&可达性分析_QuinnNorris的博客-CSDN博客
引用计数法
引用计数法的逻辑非常简单,但是存在问题,java并不采用这种方式进行对象存活判断。
引用计数法的逻辑是:在堆中存储对象时,在对象头处维护一个counter计数器,如果一个对象增加了一个引用与之相连,则将counter++。如果一个引用关系失效则counter–。如果一个对象的counter变为0,则说明该对象已经被废弃,不处于存活状态。
这种方法来标记对象的状态会存在很多问题:
1、jdk从1.2开始增加了多种引用方式:软引用、弱引用、虚引用,且在不同引用情况下程序应进行不同的操作。如果我们只采用一个引用计数法来计数无法准确的区分这么多种引用的情况。
引用计数法无法解决多种类型引用的问题。但这并不是致命的,因为我们可以通过增加逻辑区分四种引用情况,虽然麻烦一些但还算是引用计数法的变体,真正让引用计数法彻底报废的下面的情况。
2、如果一个对象A持有对象B,而对象B也持有一个对象A,那发生了类似操作系统中死锁的循环持有,这种情况下A与B的counter恒大于1,会使得GC永远无法回收这两个对象。https://blog.csdn.net/weixin_40000131/article/details/111284776 强引用: 只要引用存在,垃圾回收器永远不会回收 Object obj = new Object(); //可直接通过obj取得对应的对象 如obj.equels(new Object()); 而这样 obj对象对后面new Object的一个强引用,只有当obj这个引用被释放之后,对象才会被释放掉,这也是我们经常所用到的编码形式。 软引用: ( 如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。) 非必须引用,内存溢出之前进行回收,可以通过以下代码实现 Object obj = new Object(); SoftReference<Object> sf = new SoftReference<Object>(obj); obj = null; sf.get();//有时候会返回null 这时候sf是对obj的一个软引用,通过sf.get()方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象时,则返回null; 软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。 弱引用: (在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。) 第二次垃圾回收时回收,可以通过如下代码实现 Object obj = new Object(); WeakReference<Object> wf = new WeakReference<Object>(obj); obj = null; wf.get();//有时候会返回null wf.isEnQueued();//返回是否被垃圾回收器标记为即将回收的垃圾 弱引用是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时,将返回null。 弱引用主要用于监控对象是否已经被垃圾回收器标记为即将回收的垃圾,可以通过弱引用的isEnQueued方法返回对象是否被垃圾回收器标记。 虚引用: 垃圾回收时回收,无法通过引用取到对象值,可以通过如下代码实现 Object obj = new Object(); PhantomReference<Object> pf = new PhantomReference<Object>(obj); obj=null; pf.get();//永远返回null pf.isEnQueued();//返回是否从内存中已经删除 虚引用是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引用。 虚引用主要用于检测对象是否已经从内存中删除。可达性分析
在主流的商用程序语言中(Java和C#),都是使用可达性分析算法判断对象是否存活的。这个算法的基本思路就是通过一系列名为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的,下图对象object5, object6, object7虽然有互相判断,但它们到GC Roots是不可达的,所以它们将会判定为是可回收对象。
如下情况的对象可以作为GC Roots:
虚拟机栈(栈桢中的本地变量表)中的引用的对象
方法区中的类静态属性引用的对象
方法区中的常量引用的对象
本地方法栈中JNI(Native方法)的引用的对象

6.2.2 标记清除算法
标记清除算法是最基础的垃圾回收算法,分为两个阶段:标记阶段和清除阶段。
标记阶段的任务是标记出所有需要被回收的对象,清除阶段就是回收被标记的对象所占用的空间。
标记-清除算法实现起来比较容易,但是有一个比较严重的问题就是容易产生内存碎片,碎片太多可能会导致后续过程中需要为大对象分配空间时无法找到足够的空间而提前触发新的一次垃圾收集动作。
6.2.3 复制算法
复制算法是将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,浪费较大。
6.2.4 标记整理算法
为了解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。该算法标记阶段和Mark-Sweep一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存。
先标记,再整理,再清除。
6.2.5 分代收集算法
分代收集算法是目前大部分JVM的垃圾收集器采用的算法。
它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),老年代的特点是每次垃圾收集时只有少量对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收,那么就可以根据不同代的特点采取最适合的收集算法。
目前大部分垃圾收集器对于新生代都采取复制算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少,但是实际中并不是按照1:1的比例来划分新生代的空间的,一般来说是将新生代划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将Eden和Survivor中还存活的对象复制到另一块Survivor空间中,然后清理掉Eden和刚才使用过的Survivor空间。
而由于老年代的特点是每次回收都只回收少量对象,一般使用的是标记-整理算法(压缩法)。
6.2.6 Minor GC、Full GC
https://blog.csdn.net/YHYR_YCY/article/details/52566105
JVM: GC过程总结(minor GC 和 Full GC)_H.SH的博客-CSDN博客GC机制
从:“什么时候”,“对什么东西”,“做了什么”三个方面来具体分析。
第一:“什么时候”即就是GC触发的条件。GC触发的条件有两种。(1)程序调用System.gc时可以触发(会建议JVM进行垃圾回收,不代表一定会进行GC);(2)系统自身来决定GC触发的时机。
系统判断GC触发的依据:根据Eden区和From Space区的内存大小来决定。当内存大小不足时,则会启动GC线程并停止应用线程。
第二:“对什么东西”笼统的认为是Java对象并没有错。但是准确来讲,GC操作的对象分为:通过可达性分析法无法搜索到的对象和可以搜索到的对象。对于搜索不到的方法进行标记。
第三:“做了什么”最浅显的理解为释放对象。但是从GC的底层机制可以看出,对于可以搜索到的对象进行复制操作,对于搜索不到的对象,调用finalize()方法进行释放。
具体过程:当GC线程启动时,会通过可达性分析法把Eden区和From Space区的存活对象复制到To Space区,然后把Eden Space和From Space区的对象释放掉。当GC轮训扫描To Space区一定次数后,把依然存活的对象复制到老年代,然后释放To Space区的对象。
对于用可达性分析法搜索不到的对象,GC并不一定会回收该对象。要完全回收一个对象,至少需要经过两次标记的过程。
第一次标记:对于一个没有其他引用的对象,筛选该对象是否有必要执行finalize()方法,如果没有执行必要,则意味可直接回收。(筛选依据:是否复写或执行过finalize()方法;因为finalize方法只能被执行一次)。如果对象没有重写finalize方法或者finalize方法已经被调用过了,那么finalize方法就是没有必要执行的,没有必要执行finalize方法的对象就会被直接回收。
第二次标记:如果被筛选判定位有必要执行,则会放入FQueue队列,并自动创建一个低优先级的finalize线程来执行释放操作。如果在一个对象释放前被其他对象引用,则该对象会被移除FQueue队列。Minor GC
1、在初始阶段,新创建的对象被分配到Eden区,survivor的两块空间都为空。
Eden和survivor的from、to区大小比例为:8:1:1
2、当Eden区满了的时候,minor garbage 被触发 。
3、经过扫描与标记,存活的对象被复制到S0,不存活的对象被回收, 并且存活的对象年龄都增大一岁。
4、在下一次的Minor GC中,Eden区的情况和上面一致,没有引用的对象被回收,存活的对象被复制到survivor区。当Eden 和 s0区空间满了,S0的所有的数据都被复制到S1,需要注意的是,在上次minor GC过程中移动到S0中的两个对象在复制到S1后其年龄要加1。此时Eden区S0区被清空,所有存活的数据都复制到了S1区,并且S1区存在着年龄不一样的对象。
5、再下一次MinorGC则重复这个过程,这一次survivor的两个区对换,存活的对象被复制到S0,存活的对象年龄加1,Eden区和另一个survivor区被清空。
6、再经过几次Minor GC之后,当存活对象的年龄达到一个阈值之后(-XX:MaxTenuringThreshold默认是15),就会被从年轻代Promotion到老年代。
7、随着MinorGC一次又一次的进行,不断会有新的对象被promote到老年代。
8、上面基本上覆盖了整个年轻代所有的回收过程。最终,MajorGC将会在老年代发生,老年代的空间将会被清除和压缩(标记-清除或者标记整理)。
从上面的过程可以看出,Eden区是连续的空间,且Survivor总有一个为空。经过一次GC和复制,一个Survivor中保存着当前还活着的对象,而Eden区和另一个Survivor区的内容都不再需要了,可以直接清空,到下一次GC时,两个Survivor的角色再互换。因此,这种方式分配内存和清理内存的效率都极高,这种垃圾回收的方式就是著名的“停止-复制(Stop-and-copy)”清理法(将Eden区和一个Survivor中仍然存活的对象拷贝到另一个Survivor中),这不代表着停止复制清理法很高效,其实,它也只在这种情况下(基于大部分对象存活周期很短的事实)高效,如果在老年代采用停止复制,则是非常不合适的。Full GC
在发生Minor GC时,虚拟机会检查每次晋升进入老年代的大小是否大于老年代的剩余空间大小,如果大于,则直接触发一次Full GC,否则,就查看是否设置了-XX:+HandlePromotionFailure(允许担保失败),如果允许,则只会进行MinorGC,此时可以容忍内存分配失败;**如果不允许,则仍然进行Full GC(**这代表着如果设置-XX:+Handle PromotionFailure,则触发MinorGC就会同时触发Full GC,哪怕老年代还有很多内存,所以,最好不要这样做)。GC触发条件
Minor GC触发条件:Eden区满时;
Full GC触发条件:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法去空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。对象进入老年代的四种情况
(1) 假如进行Minor GC时发现,存活的对象在ToSpace区中存不下,那么把存活的对象存入老年代;
(2) 大对象直接进入老年代:假设新创建的对象很大,比如为5M(这个值可以通过PretenureSizeThreshold这个参数进行设置,默认3M),那么即使Eden区有足够的空间来存放,也不会存放在Eden区,而是直接存入老年代;
(3) 长期存活的对象将进入老年代:此外,如果对象在Eden出生并且经过1次Minor GC后仍然存活,并且能被To区容纳,那么将被移动到To区,并且把对象的年龄设置为1,对象没"熬过"一次Minor GC(没有被回收,也没有因为To区没有空间而被移动到老年代中),年龄就增加一岁,当它的年龄增加到一定程度(默认15岁,配置参数-X:MaxTenuringThreshold),就会被晋升到老年代中;
(4) 动态对象年龄判定:还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于Survivor空间的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认);看完不清楚可查看:
Minor GC、Major GC、Full GC、分配担保 - 反光的小鱼儿 - 博客园1.Java堆内存的新生代Survivor区“To”被填满了,to区中的有的对象年龄还没被复制15次,也会被移动到年老代中吗?2.触发Minor GC时一定会让From和To互换角色吗?_luoailong的博客-CSDN博客_survivor区满了

6.3 垃圾收集器
JVM几种常见的垃圾收集器总结_To be a great coder-CSDN博客_垃圾收集器
6.3.1 Serial收集器(新生代)
Serial 即串行的意思,也就是说它以串行的方式执行,它是单线程的收集器,只会使用一个线程进行垃圾收集工作,GC 线程工作时,其它所有线程都将停止工作。
使用复制算法收集新生代垃圾。
它的优点是简单高效,在单个 CPU 环境下,由于没有线程交互的开销,因此拥有最高的单线程收集效率,所以,它是 Client 场景下的默认新生代收集器。
显式的使用该垃圾收集器作为新生代垃圾收集器的方式:-XX:+UseSerialGC

6.3.2 ParNew收集器(新生代)
就是 Serial 收集器的多线程版本,但要注意一点,ParNew 在单核环境下是不如 Serial 的,在多核的条件下才有优势。
使用复制算法收集新生代垃圾。
Server 场景下默认的新生代收集器,除了性能原因外,主要是因为除了 Serial 收集器,只有它能与 CMS 收集器配合使用。
显式的使用该垃圾收集器作为新生代垃圾收集器的方式:-XX:+UseParNewGC

6.3.3 Parallel Scavenge 收集器(新生代)
同样是多线程的收集器,其它收集器目标是尽可能缩短垃圾收集时用户线程的停顿时间,而它的目标是提高吞吐量(吞吐量 = 运行用户程序的时间 / (运行用户程序的时间 + 垃圾收集的时间))。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,适合在后台运算而不需要太多交互的任务。
使用复制算法收集新生代垃圾。
显式的使用该垃圾收集器作为新生代垃圾收集器的方式:-XX:+UseParallelGCParNew和Parallel Scavenge收集器两者都是复制算法,都是并行处理,但是不同的是,paralel scavenge 可以设置最大gc停顿时间(-XX:MaxGCPauseMills)以及gc时间占比(-XX:GCTimeRatio),

6.3.4 Serial Old 收集器(老年代)
Serial 收集器的老年代版本,Client 场景下默认的老年代垃圾收集器。
使用标记-整理算法收集老年代垃圾。
显式的使用该垃圾收集器作为老年代垃圾收集器的方式:-XX:+UseSerialOldGC

6.3.5 Parallel Old 收集器(老年代)
Parallel Scavenge 收集器的老年代版本。
在注重吞吐量的场景下,可以采用 Parallel Scavenge + Parallel Old 的组合。
使用标记-整理算法收集老年代垃圾。
显式的使用该垃圾收集器作为老年代垃圾收集器的方式:-XX:+UseParallelOldGC

6.3.6 CMS收集器(老年代)
CMS(Concurrent Mark Sweep),收集器几乎占据着 JVM 老年代收集器的半壁江山,它划时代的意义就在于垃圾回收线程几乎能做到与用户线程同时工作。
使用标记-清除算法收集老年代垃圾。
工作流程主要有如下 4 个步骤:
初始标记: 仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿(Stop-the-world)
并发标记: 进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿
重新标记: 为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿(Stop-the-world)
并发清除: 清理垃圾,不需要停顿
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
但 CMS 收集器也有如下缺点:
吞吐量低、无法处理浮动垃圾、标记 - 清除算法带来的内存空间碎片问题;
显式的使用该垃圾收集器作为老年代垃圾收集器的方式:-XX:+UseConcMarkSweepGC

6.3.7 G1收集器(新生代 + 老年代)
优势:并行(多核CPU)与并发;
分代收集(新生代和老年代区分不明显);
空间整合;
限制收集范围,可预测的停顿。
步骤:初始标记、并发标记、最终标记和筛选回收。



6.4 类加载机制
jvm之java类加载机制和类加载器(ClassLoader)的详解_翻过一座座山-CSDN博客_类加载器
6.4.1 类加载过程
加载
加载指的是将类的class文件读入到内存,并为之创建一个java.lang.Class对象,也就是说,当程序中使用任何类时,系统都会为之建立一个java.lang.Class对象。
类的加载由类加载器完成,类加载器通常由JVM提供,这些类加载器也是前面所有程序运行的基础,JVM提供的这些类加载器通常被称为系统类加载器。除此之外,开发者可以通过继承ClassLoader基类来创建自己的类加载器。
通过使用不同的类加载器,可以从不同来源加载类的二进制数据,通常有如下几种来源。
从本地文件系统加载class文件,这是前面绝大部分示例程序的类加载方式。
从JAR包加载class文件,这种方式也是很常见的,前面介绍JDBC编程时用到的数据库驱动类就放在JAR文件中,JVM可以从JAR文件中直接加载该class文件。
通过网络加载class文件。
把一个Java源文件动态编译,并执行加载。
类加载器通常无须等到“首次使用”该类时才加载该类,Java虚拟机规范允许系统预先加载某些类。链接
当类被加载之后,系统为之生成一个对应的Class对象,接着将会进入连接阶段,连接阶段负责把类的二进制数据合并到JRE中。类连接又可分为如下3个阶段。
1)验证:验证阶段用于检验被加载的类是否有正确的内部结构,并和其他类协调一致。Java是相对C++语言是安全的语言,例如它有C++不具有的数组越界的检查。这本身就是对自身安全的一种保护。验证阶段是Java非常重要的一个阶段,它会直接的保证应用是否会被恶意入侵的一道重要的防线,越是严谨的验证机制越安全。验证的目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。其主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
四种验证做进一步说明:
文件格式验证:主要验证字节流是否符合Class文件格式规范,并且能被当前的虚拟机加载处理。例如:主,次版本号是否在当前虚拟机处理的范围之内。常量池中是否有不被支持的常量类型。指向常量的中的索引值是否存在不存在的常量或不符合类型的常量。
元数据验证:对字节码描述的信息进行语义的分析,分析是否符合java的语言语法的规范。
字节码验证:最重要的验证环节,分析数据流和控制,确定语义是合法的,符合逻辑的。主要的针对元数据验证后对方法体的验证。保证类方法在运行时不会有危害出现。
符号引用验证:主要是针对符号引用转换为直接引用的时候,是会延伸到第三解析阶段,主要去确定访问类型等涉及到引用的情况,主要是要保证引用一定会被访问到,不会出现类等无法访问的问题。
2)准备:准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在Java堆中。
这里所设置的初始值通常情况下是数据类型默认的零值(如0、0L、null、false等),而不是被在Java代码中被显式地赋予的值。
3)解析:将类的二进制数据中的符号引用替换成直接引用。说明一下:符号引用:符号引用是以一组符号来描述所引用的目标,符号可以是任何的字面形式的字面量,只要不会出现冲突能够定位到就行。布局和内存无关。直接引用:是指向目标的指针,偏移量或者能够直接定位的句柄。该引用是和内存中的布局有关的,并且一定加载进来的。

6.4.2 类加载时机
类加载有如下几种时机:
创建类的实例,也就是new一个对象
访问某个类或接口的静态变量,或者对该静态变量赋值
调用类的静态方法
反射(Class.forName("com.lyj.load"))
初始化一个类的子类(会首先初始化子类的父类)
JVM启动时标明的启动类,即文件名和类名相同的那个类除此之外,下面几种情形需要特别指出:
对于一个final类型的静态变量,如果该变量的值在编译时就可以确定下来,那么这个变量相当于“宏变量”。Java编译器会在编译时直接把这个变量出现的地方替换成它的值,因此即使程序使用该静态变量,也不会导致该类的初始化。反之,如果final类型的静态Field的值不能在编译时确定下来,则必须等到运行时才可以确定该变量的值,如果通过该类来访问它的静态变量,则会导致该类被初始化。
6.4.3 类加载器
类加载器负责加载所有的类,其为所有被载入内存中的类生成一个java.lang.Class实例对象。一旦一个类被加载如JVM中,同一个类就不会被再次载入了。正如一个对象有一个唯一的标识一样,一个载入JVM的类也有一个唯一的标识。在Java中,一个类用其全限定类名(包括包名和类名)作为标识;但在JVM中,一个类用其全限定类名和其类加载器作为其唯一标识。
JVM预定义有三种类加载器,当一个 JVM启动的时候,Java开始使用如下三种类加载器:
1)根类加载器(bootstrap class loader):它用来加载 Java 的核心类,是用原生代码来实现的,并不继承自 java.lang.ClassLoader(负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类)。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。
2)扩展类加载器(extensions class loader):它负责加载JRE的扩展目录,lib/ext或者由java.ext.dirs系统属性指定的目录中的JAR包的类。由Java语言实现,父类加载器为null。
3)系统类加载器(system class loader):被称为系统(也称为应用)类加载器,它负责在JVM启动时加载来自Java命令的-classpath选项、java.class.path系统属性,或者CLASSPATH换将变量所指定的JAR包和类路径。程序可以通过ClassLoader的静态方法getSystemClassLoader()来获取系统类加载器。如果没有特别指定,则用户自定义的类加载器都以此类加载器作为父加载器。由Java语言实现,父类加载器为ExtClassLoader。类加载器加载Class大致要经过如下8个步骤:
1、检测此Class是否载入过,即在缓冲区中是否有此Class,如果有直接进入第8步,否则进入第2步。
2、如果没有父类加载器,则要么Parent是根类加载器,要么本身就是根类加载器,则跳到第4步,如果父类加载器存在,则进入第3步。
3、请求使用父类加载器去载入目标类,如果载入成功则跳至第8步,否则接着执行第5步。
4、请求使用根类加载器去载入目标类,如果载入成功则跳至第8步,否则跳至第7步。
5、当前类加载器尝试寻找Class文件,如果找到则执行第6步,如果找不到则执行第7步。
6、从文件中载入Class,成功后跳至第8步。
7、抛出ClassNotFountException异常。
8、返回对应的java.lang.Class对象。
6.4.4 类加载机制(双亲委任)
全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
双亲委派:所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
缓存机制:缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。双亲委派机制:
其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。
双亲委派机制的优势:采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
JVM - 双亲委派机制的优势和劣势_后端学习-CSDN博客_双亲委派机制的缺点

6.5 杂
finalize:
GC垃圾回收过处理可达性分析算法中不可达的对象被标记成需要回收, 一但垃圾回收器准备释放对象占用的内存会经理两个过程
finalize方法没有被虚拟机调用过,那么先调用对象的finalize方法。本次不再处理等待下一次垃圾回收处理;
finalize方法调用过一次后,再次垃圾回收释放对象占用的内存。
垃圾回收器要回收对象的时候,首先要调用这个类的finalize方法(你可以 写程序验证这个结论),一般的纯Java编写的Class不需要重新覆盖这个方法,因为Object已经实现了一个默认的,除非我们要实现特殊的功能(这 里面涉及到很多东西,比如对象空间树等内容)。
不过用Java以外的代码编写的Class(比如JNI,C++的new方法分配的内存),垃圾回收器并不能对这些部分进行正确的回收,这时就需要我们覆盖默认的方法来实现对这部分内存的正确释放和回收(比如C++需要delete)。
七、Kafka
7.1 基础
7.1.1 概念
Kafka 是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
消息
Kafka 中的数据单元被称为消息,也被称为记录,可以把它看作数据库表中某一行的记录。批次
为了提高效率, 消息会分批次写入 Kafka,批次就代指的是一组消息。主题
消息的种类称为主题(Topic),可以说一个主题代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表。分区
主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序生产者
向主题发布消息的客户端应用程序称为生产者(Producer),生产者用于持续不断的向某个主题发送消息。消费者
订阅主题消息的客户端程序称为消费者(Consumer),消费者用于处理生产者产生的消息。消费者群组
生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。偏移量
偏移量(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。broker
一个独立的 Kafka 服务器就被称为broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 集群
broker 是集群的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。副本
Kafka 中消息的备份又叫做副本(Replica),副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。重平衡
Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
7.1.2 特性(设计原则)
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。
容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
高并发: 支持数千个客户端同时读写
7.1.3 使用场景与消息队列模式
一般应用于活动跟踪、传递消息、度量指标、日志记录、流式处理、限流削峰。
Kafka 的消息队列一般分为两种模式:点对点模式和发布订阅模式;
Kafka 是支持消费者群组的,也就是说 Kafka 中会有一个或者多个消费者,如果一个生产者生产的消息由一个消费者进行消费的话,那么这种模式就是点对点模式;如果一个生产者或者多个生产者产生的消息能够被多个消费者同时消费的情况,这样的消息队列成为发布订阅模式的消息队列。
7.1.4 系统架构
如上图所示,一个典型的 Kafka 集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
7.2 面试问题
Kafka常见面试题_徐周的博客-CSDN博客_kafka面试题
kafka专题:kafka的消息丢失、重复消费、消息积压等线上问题汇总及优化_知识分子_的博客-CSDN博客
7.2.1 小结
Kafka具备着高吞吐低延迟(快:顺序读写、零拷贝、压缩、批量发送)、高伸缩性(每个主题有多个分区,每个分区可分布在不同broker中)、持久性(允许持久化储存)、容错性(集群中某个节点宕机,kafka能继续正常运行:leader选举)、高并发(支持上千个客户端同时读写)。
kafka作用:缓冲和消峰、解耦和易扩展、消息队列、日志记录;
7.2.2 零拷贝技术
零拷贝:
Kafka零拷贝 - 简书幂等性:
大厂面试Kafka,一定会问到的幂等性 - 君銆 - 博客园
如何保证Kafka消息不被重复消费?(如何保证消息消费时的幂等性)_wwwwww33的博客-CSDN博客_kafka如何保证不重复消费事务:
Kafka科普系列 | Kafka中的事务是什么样子的?_朱小厮的博客-CSDN博客_kafka事务副本同步机制:
选举机制:
浅谈Kafka选举机制_不清不慎的博客-CSDN博客_kafka选举机制
Kafka 集群controller的选举过程如下 :
每个Broker都会在Controller Path (/controller)上注册一个Watch。
当前Controller失败时,对应的Controller Path会自动消失(因为它是ephemeral Node),此时该Watch被fire,所有“活”着的Broker都会去竞选成为新的Controller(创建新的Controller Path),但是只会有一个竞选成功(这点由Zookeeper保证)。
竞选成功者即为新的Leader,竞选失败者则重新在新的Controller Path上注册Watch。因为Zookeeper的Watch是一次性的,被fire一次之后即失效,所以需要重新注册。Kafka partition leader的选举过程如下 (由controller执行):
从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
调用配置的分区选择算法选择分区的leader
7.2.3 分区概念
kafka分区----分区如何分配到broker----生产者分区策略----消费者消费策略 - 小沙一粒 - 博客园
分区如何分配到broker
实际上在Kafka集群中,每一个Broker都有均等分配Partition的Leader机会,kafka是先随机挑选一个broker放置分区0,然后再按顺序放置其他分区,副本也是一样的情况。第一个放置的分区副本一般都是 Leader,其余的都是 Follow 副本。生产者分区策略
消费者分区策略
range策略(平铺)
轮询策略roudRobin


7.2.4 消息的顺序性
Kafka可以保证消息在一个Partition分区内的顺序性,无法保证一个topic内不同的partition之间的顺序性。如果生产者按照顺序发送消息,Kafka将按照这个顺序将消息写入分区,消费者也会按照同样的顺序来读取消息(通过自增偏移量)。
kafka想要保证消息顺序,是需要牺牲一定性能的,方法就是一个消费者,消费一个分区,可以保证消费的顺序性。
Kafka如何保证消息的顺序性 - 开顺 - 博客园生产者对消息的顺序性
Kafka生产者对于消息顺序性的最佳实践_futao__的博客-CSDN博客
7.2.5 消息重复、消息丢失
生产者消息丢失
通过ack=0、1、-1机制实现生产者重复生产消息
消费者重复消费
在kafka的消费者中,有一个非常关键的机制,那就是offset机制。它使得Kafka在消费的过程中即使挂了或者引发再均衡问题重新分配Partation,当下次重新恢复消费时仍然可以知道从哪里开始消费。它好比看一本书中的书签标记,每次通过书签标记(offset)就能快速找到该从哪里开始看(消费)。
Kafka对于offset的处理有两种提交方式:(1) 自动提交(默认的提交方式) (2) 手动提交(可以灵活地控制offset)(1) 自动提交偏移量:
对于自动提交偏移量,如果auto_commit_interval_ms的值设置的过大,当消费者在自动提交偏移量之前异常退出,将导致kafka未提交偏移量,进而出现重复消费的问题,所以建议auto_commit_interval_ms的值越小越好。
(2) 手动提交偏移量:
鉴于Kafka自动提交offset的不灵活性和不精确性(只能是按指定频率的提交),Kafka提供了手动提交offset策略。手动提交能对偏移量更加灵活精准地控制,以保证消息不被重复消费以及消息不被丢失。
对于手动提交offset主要有3种方式:1.同步提交 2.异步提交 3.异步+同步 组合的方式提交
1.同步手动提交偏移量
同步模式下提交失败的时候一直尝试提交,直到遇到无法重试的情况下才会结束,同时同步方式下消费者线程在拉取消息会被阻塞,在broker对提交的请求做出响应之前,会一直阻塞直到偏移量提交操作成功或者在提交过程中发生异常,限制了消息的吞吐量。
2.异步手动提交偏移量+回调函数 异步手动提交offset时,消费者线程不会阻塞,提交失败的时候也不会进行重试,并且可以配合回调函数在broker做出响应的时候记录错误信息。
对于异步提交,由于不会进行失败重试,当消费者异常关闭或者触发了再均衡前,如果偏移量还未提交就会造成偏移量丢失。
3.异步+同步 组合的方式提交偏移量
针对异步提交偏移量丢失的问题,通过对消费者进行异步批次提交并且在关闭时同步提交的方式,这样即使上一次的异步提交失败,通过同步提交还能够进行补救,同步会一直重试,直到提交成功。
https://blog.csdn.net/weixin_44120629/article/details/88789511

7.2.6 消息堆积
八、杂
8.1 Tomcat系列
8.1.1 Tomcat服务器
Nginx和Apache和Tomcat的区别及优缺点_林长有的博客-CSDN博客_nginx和tomcat区别
Apache
Apache HTTP Server(简称Apache)是Apache软件基金会的一个开放源码的网页,它是一个模块化的服务器,可以运行在几乎所有广泛使用的计算机平台上。其属于应用服务器。
Apache支持模块多,性能稳定,Apache本身是静态解析,适合静态HTML、图片等,但可以通过扩展脚本、模块等支持动态页面等。
缺点:配置相对复杂,自身不支持动态页面。
优点:相对于Tomcat服务器来说处理静态文件是它的优势,速度快。Apache是静态解析,适合静态HTML、图片等。
(Apche可以支持PHPcgiperl,但是要使用Java的话,你需要Tomcat在Apache后台支撑,将Java请求由Apache转发给Tomcat处理。)Nginx
Nginx是俄罗斯人编写的十分轻量级的HTTP服务器,Nginx,它的发音为“engine X”,是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP 代理服务器。其特点是占有内存少,并发能力强,易于开发,部署方便。Nginx 支持多语言通用服务器。
缺点:Nginx 只适合静态和反向代理。
优点:负载均衡、反向代理、处理静态文件优势。Nginx 处理静态请求的速度高于Apache。
Nginx有动态分离机制,静态请求直接就可以通过Nginx处理,动态请求才转发请求到后台交由Tomcat进行处理。
Nginx配置:https://blog.csdn.net/qq_42030417/article/details/83185809Tomcat
Tomcat 是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目。Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器。
Tomcat是应用(Java)服务器,它只是一个Servlet(JSP也翻译成Servlet)容器,可以认为是Apache的扩展,但是可以独立于Apache运行。
缺点:可以说Tomcat 只能用做java服务器
优点:动态解析容器,处理动态请求,是编译JSP/Servlet的容器。高性能服务器
Tomcat处理html的能力不如Apache和nginx,tomcat处理静态内容的速度不如apache和nginx。Tomcat接受的最大并发数有限,连接数过多,会导致tomcat处于"僵尸"状态,对后续的连接失去响应,需要结合nginx一起使用。
在这种架构中,当haproxy或nginx作为前端代理时,如果是静态内容,如html、css等内容,则直接交给静态服务器处理;如果请求的图片等内容,则直接交给图片服务器处理;如果请求的是动态内容,则交给tomcat服务器处理,不过在tomcat服务器上,同时运行着nginx服务器,此时的nginx作为静态服务器,它不处理静态请求,它的作用主要是接受请求,并将请求转发给tomcat服务器的,除此之外,nginx没有任何作用。
Tomcat线程模型
BIO:
一个线程处理一个请求。缺点:并发量高时,线程数较多,浪费资源。
Tomcat7或以下,在Linux系统中默认使用这种方式。
NIO:
利用Java的异步IO处理,可以通过少量的线程处理大量的请求。
Tomcat8在Linux系统中默认使用这种方式。
Tomcat7必须修改Connector配置来启动:
connectionTimeout=“20000” redirectPort=“8443”/>
在NIO模型中,接收连接的地方不需要增加线程来接收数据包,但在接收数据包后,后面每一个http请求都会开一个线程处理。
APR:
即Apache Portable Runtime,从操作系统层面解决io阻塞问题。
Linux如果安装了apr和native,Tomcat7或Tomcat8在Linux系统中默认使用这种方式。Tomcat NIO执行流程
https://blog.csdn.net/qq_31086797/article/details/107703053
1、创建一个Acceptor线程来接收用户连接,接收到之后扔到events queue队列里面,默认情况下只有一个线程来接收
2、创建Poller线程,数量小于等于2,Poller对象是NIO的核心,在Poller中,维护了一个Selector对象;当Poller从队列中取出socket后,注册到该Selector中;然后通过遍历Selector,找出其中可读的socket,然后扔到线程池中处理相应请求,这就是典型的NIO多路复用模型。
3、扔到线程池中的SocketProcessorBase处理请求。
相较于BIO模型的tomcat,NIO的优势分析:
1、BIO中的流程应该是接收到请求之后直接把请求扔给线程池去做处理,在这个情况下一个连接即需要一个线程来处理,线程既需要读取数据还需要处理请求,线程占用时间长,很容易达到最大线程
2、NIO的流程的不同点在于Poller类采用了多路复用模型,即Poller类只有检查到可读或者可写的连接时才把当前连接扔给线程池来处理,这样的好处是大大节省了连接还不能读写时的处理时间(如读取请求数据),也就是说NIO“读取socket并交给Worker中的线程”这个过程是非阻塞的,当socket在等待下一个请求或等待释放时,并不会占用工作线程,因此Tomcat可以同时处理的socket数目远大于最大线程数,并发性能大大提高。

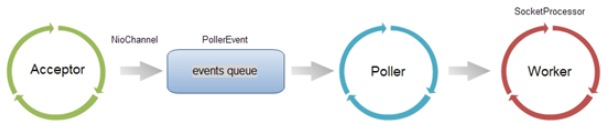
8.1.2 Servlet
Servlet
Java Servlet(Java服务器小程序)是一个基于Java技术的Web组件,运行在服务器端,它由Servlet容器所管理,用于生成动态的内容。 Servlet是平台独立的Java类,编写一个Servlet,实际上就是按照Servlet规范编写一个Java类。Servlet被编译为平台独立 的字节码,可以被动态地加载到支持Java技术的Web服务器中运行。Servlet容器
Servlet容器也叫做Servlet引擎,是Web服务器或应用程序服务器的一部分,用于在发送的请求和响应之上提供网络服务,解码基于 MIME的请求,格式化基于MIME的响应。Servlet没有main方法,不能独立运行,它必须被部署到Servlet容器中,由容器来实例化和调用 Servlet的方法(如doGet()和doPost()),Servlet容器在Servlet的生命周期内包容和管理Servlet。在JSP技术 推出后,管理和运行Servlet/JSP的容器也称为Web容器。Servlet生命周期
(1)加载和实例化
当Servlet容器启动或客户端发送一个请求时,Servlet容器会查找内存中是否存在该Servlet实例,若存在,则直接读取该实例响应请求;如果不存在,就创建一个Servlet实例。(2) 初始化
实例化后,Servlet容器将调用Servlet的init()方法进行初始化(一些准备工作或资源预加载工作)。
(3)服务
初始化后,Servlet处于能响应请求的就绪状态。当接收到客户端请求时,调用service()的方法处理客户端请求,HttpServlet的service()方法会根据不同的请求 转调不同的doXXX()方法。
(4)销毁
当Servlet容器关闭时,Servlet实例也随时销毁。其间,Servlet容器会调用Servlet 的destroy()方法去判断该Servlet是否应当被释放(或回收资源)。Servlet、SpringMVC区别
Servlet:单例,不安全。性能最好,处理Http请求的标准,只处理doPost(),doGet()方法。
SpringMVC:单例,不安全。开发效率高(好多共性的东西都封装好了,是对Servlet的封装,核心的DispatcherServlet最终继承自HttpServlet)。DispatcherServlet又叫前端控制器,能过滤处理所有的请求方法。DispatcherServlet还能查询HandlerMapping查找到相应的handler,进而调用相应的service和Dao。
这两者的关系,就如同MyBatis和JDBC,一个性能好,一个开发效率高,是对另一个的封装。


8.1.3 Tomcat、Servlet处理流程
当用户从浏览器向服务器发起一个请求,通常会包含如下信息:【http://hostname: port /contextpath/servletpath】。hostname 和 port 是用来与服务器建立 TCP 连接。而后面的【/contextpath/servletpath】即【 URL 】才是用来选择服务器中的哪个子容器来服务用户的请求。
Tomcat服务器本质是通过ServerSocket与客户端进行通信,要进行通信首先就要进行TCP连接。
Tomcat 一接受到请求首先将会创建 【org.apache.coyote.Request】 和 【org.apache.coyote.Response】,这两个类是 Tomcat 内部使用的描述一次请求和相应的信息类它们是一个轻量级的类,它们作用就是在服务器接收到请求后,经过简单解析将这个请求快速的分配给后续线程去处理,所以它们的对象很小,很容易被 JVM 回收。
Tomcat有两个核心组件,Connecter和Container。Connecter将在某个指定的端口上侦听客户请求,接收浏览器的发过来的 tcp 连接请求,创建一个 Request 和 Response 对象分别用于和请求端交换数据,Request包含了用户的请求信息,Response负责记录了服务器的答复内容。然后会产生一个线程来处理这个请求并把产生的 Request 和 Response 对象传给Container处理。 Connector 最重要的功能就是接收连接请求然后分配线程让 Container 来处理这个请求,所以这必然是多线程的,多线程的处理是 Connector 设计的核心。
接下去当交给一个用户线程去处理这个请求时又创建 【org.apache.catalina.connector.Request】 和 【org.apache.catalina.connector.Response】 对象。这两个对象一直穿越整个 Servlet 容器,直到要传给 Servlet。
当Connector处理完后会调用Container的invoke()方法,你可以想象Container容器里有一条管道,管道上有很多阀门,每个阀门都会根据request进行一些操作,request和response请求会依次经过这些阀门,而Servlet就是该管道的最后一道阀门,之前的阀门就是filter。
九、MySQL
9.1 基础
9.1.1 前言
架构是客户端/服务器架构,它的服务器程序直接和我们存储的数据打交道,然后可以有好多客户端程序连接到这个服务器程序,发送增删改查的请求,然后服务器就响应这些请求,从而操作它维护的数据。和微信一样,
MySQLMySQL的每个客户端都需要提供用户名密码才能登录,登录之后才能给服务器发请求来操作某些数据。流程
服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是连接管理、解析与优化、存储引擎。
处理连接:客户端进程可以采用我们上边介绍的
TCP/IP、命名管道或共享内存、Unix域套接字这几种方式之一来与服务器进程建立连接,每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互。在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证。
查询缓存:MySQL服务器程序会把刚刚处理过的查询请求和结果缓存起来,如果下一次有一模一样的请求过来,直接从缓存中查找结果就好,这个查询缓存可以在不同客户端之间共享。ySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销,比如每次都要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
语法解析:MySQL服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上来。
查询优化:MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是啥样的。我们可以使用EXPLAIN语句来查看某个语句的执行计划。不同作用范围的系统变量
查询系统变量:SHOW VARIABLES LIKE '%engine';GLOBAL:全局变量,影响服务器的整体操作。
SESSION:会话变量,影响某个客户端连接的操作。(注:SESSION有个别名叫LOCAL)
在服务器启动时,会将每个全局变量初始化为其默认值(可以通过命令行或选项文件中指定的选项更改这些默认值)。然后服务器还为每个连接的客户端维护一组会话变量,客户端的会话变量在连接时使用相应全局变量的当前值初始化。
在服务器程序运行期间通过客户端程序设置系统变量的语法:SET [GLOBAL|SESSION] 系统变量名 = 值; SET GLOBAL default_storage_engine = MyISAM;如果某个客户端改变了某个系统变量在`GLOBAL`作用范围的值,并不会影响该系统变量在当前已经连接的客户端作用范围为`SESSION`的值,只会影响后续连入的客户端在作用范围为`SESSION`的值。
- 有一些系统变量只具有
GLOBAL作用范围,比方说max_connections,表示服务器程序支持同时最多有多少个客户端程序进行连接。- 有一些系统变量只具有
SESSION作用范围,比如insert_id,表示在对某个包含AUTO_INCREMENT列的表进行插入时,该列初始的值。有一些系统变量的值既具有
GLOBAL作用范围,也具有SESSION作用范围,比如我们前边用到的default_storage_engine,而且其实大部分的系统变量都是这样的,有些系统变量是只读的,并不能设置值,比如版本号。
状态变量
为了让我们更好的了解服务器程序的运行情况,MySQL服务器程序中维护了好多关于程序运行状态的变量,它们被称为状态变量。比方说Threads_connected表示当前有多少客户端与服务器建立了连接。
由于状态变量是用来显示服务器程序运行状况的,所以它们的值只能由服务器程序自己来设置。与系统变量类似,状态变量也有GLOBAL和SESSION两个作用范围的,所以查看状态变量的语句可以这么写:SHOW [GLOBAL|SESSION] STATUS [LIKE 匹配的模式]; SHOW STATUS LIKE 'thread%';字符集
ASCII字符集:共收录128个字符,包括空格、标点符号、数字、大小写字母和一些不可见字符。由于总共才128个字符,所以可以使用1个字节来进行编码。ISO 8859-1字符集:共收录256个字符,是在ASCII字符集的基础上又扩充了128个西欧常用字符(包括德法两国的字母),也可以使用1个字节来进行编码。这个字符集也有一个别名latin1。GB2312字符集:收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母。其中收录汉字6763个,其他文字符号682个。同时这种字符集又兼容ASCII字符集,所以在编码方式上显得有些奇怪:如果该字符在ASCII字符集中,则采用1字节编码;否则采用2字节编码。
如何区分某个字节代表一个单独的字符还是代表某个字符的一部分呢:`ASCII`字符集只收录128个字符,使用0~127就可以表示全部字符,所以如果某个字节是在0~127之内的,就意味着一个字节代表一个单独的字符,否则就是两个字节代表一个单独的字符。GBK字符集:GBK字符集只是在收录字符范围上对GB2312字符集作了扩充,编码方式上兼容GB2312。utf8字符集:收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容ASCII字符集,采用变长编码方式,编码一个字符需要使用1~4个字节。
其实准确的说,utf8只是Unicode字符集的一种编码方案,Unicode字符集可以采用utf8、utf16、utf32这几种编码方案,utf8使用1~4个字节编码一个字符,utf16使用2个或4个字节编码一个字符,utf32使用4个字节编码一个字符。MYSQL中:utf8mb3:阉割过的utf8字符集,只使用1~3个字节表示字符。
utf8mb4:正宗的utf8字符集,使用1~4个字节表示字符。
在MySQL中utf8是utf8mb3的别名。比较规则
- 比较规则名称以与其关联的字符集的名称开头。如上图的查询结果的比较规则名称都是以
utf8开头的。- 后边紧跟着该比较规则主要作用于哪种语言,比如
utf8_polish_ci表示以波兰语的规则比较,utf8_spanish_ci是以西班牙语的规则比较,utf8_general_ci是一种通用的比较规则。- 名称后缀意味着该比较规则是否区分语言中的重音、大小写啥的,
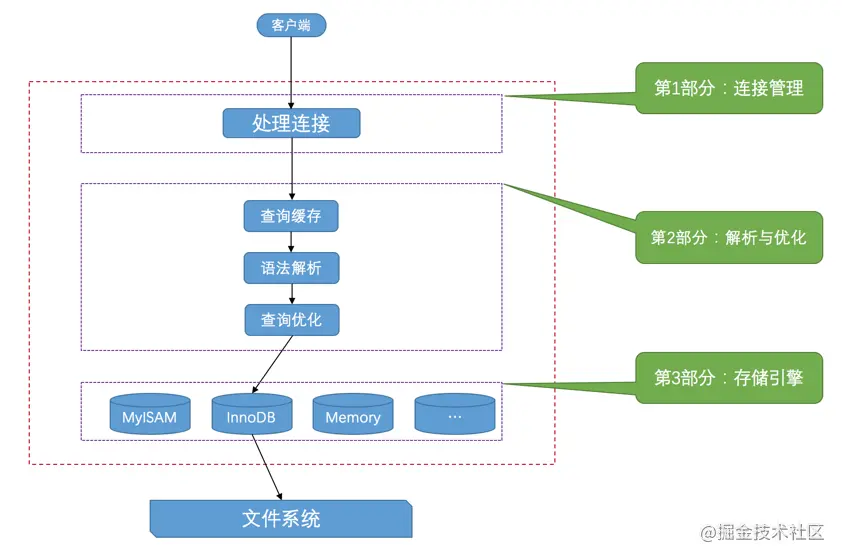
9.2 InnoDB
9.2.1 简介 行格式是否需要看??????
InnoDB页简介是一个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。
InnoDB
由于磁盘读写很慢,InnoDB采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB。也就是在一般情况下,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。行格式
4种不同类型的行格式,分别是Compact、Redundant、Dynamic和Compressed行格式。
创建或修改表的语句中指定行格式:CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称 ALTER TABLE 表名 ROW_FORMAT=行格式名称
9.2.2 不同引擎的区别
a
9.2.3 InnoDB数据页结构
数据页代表的这块
16KB大小的存储空间可以被划分为多个部分
创建 page_demo表,并以此为例:
mysql> CREATE TABLE page_demo( -> c1 INT, -> c2 INT, -> c3 VARCHAR(10000), -> PRIMARY KEY (c1) -> ) CHARSET=ascii ROW_FORMAT=Compact; Query OK, 0 rows affected (0.03 sec)首先分析行记录格式。
记录头
插入4条记录后:
delete_mask:这个属性标记着当前记录是否被删除,占用1个二进制位,值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了。
这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。min_rec_mask:B+树的每层非叶子节点中的最小记录都会添加该标记。
n_owned:当此纪录为槽点时,表示该槽包含几条记录;非槽点为0。heap_no:这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本页中的位置分别是:2、3、4、5。InnoDB自动给每个页里边儿加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录。
是的,记录也可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录的大小从小到大依次递增。
由于这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分,如图所示:(最小记录和最大记录的heap_no值分别是0和1)
record_type:这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type值都是0,而最小记录和最大记录的record_type值分别为2和3。至于record_type为1的情况,我们之后在说索引的时候会重点强调的。next_record:它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。可以通过一条记录找到它的下一条记录,即构成一个链表。但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个next_record起到的作用,我们用箭头来替代一下next_record中的地址偏移量:
若删除第2条记录,链表形式为:
Page Directory(页目录)
设计规则:
1、将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组。
2、每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录。
3、将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的Page Directory,也就是页目录(此时应该返回头看看页面各个部分的图)。页面目录中的这些地址偏移量被称为槽(英文名:Slot),所以这个页面目录就是由槽组成的。
对每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。所以分组是按照下边的步骤进行的:
初始情况下一个数据页里只有最小记录和最大记录两条记录,它们分属于两个分组。
之后每插入一条记录,都会从
页目录中找到主键值比本记录的主键值大并且差值最小的槽,然后把该槽对应的记录的n_owned值加1,表示本组内又添加了一条记录,直到该组中的记录数等于8个。在一个组中的记录数等于8个后再插入一条记录时,会将组中的记录拆分成两个组,一个组中4条记录,另一个5条记录。这个过程会在
页目录中新增一个槽来记录这个新增分组中最大的那条记录的偏移量。
在一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。
通过记录的next_record属性遍历该槽所在的组中的各个记录。Page Header(页面头部)
用于存储的数据页中记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等。(详见掘金记录页部分)File Header(文件头部)
描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁等。(详见掘金记录页部分)File Trailer
我们知道InnoDB存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计InnoDB的大叔们在每个页的尾部都加了一个File Trailer部分,这个部分由8个字节组成,可以分成2个小部分。
前4个字节代表页的校验和
这个部分是和File Header中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说LSN是个什么意思,所以大家可以先不用管这个属性。

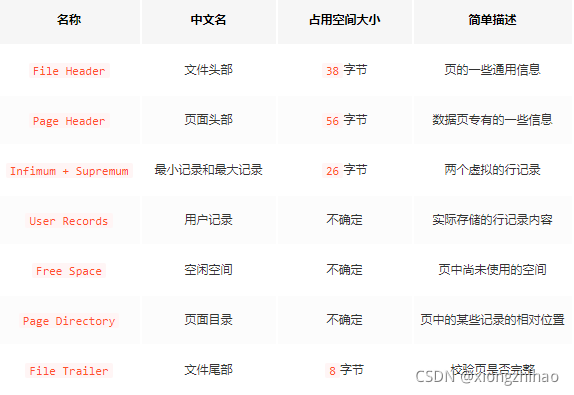
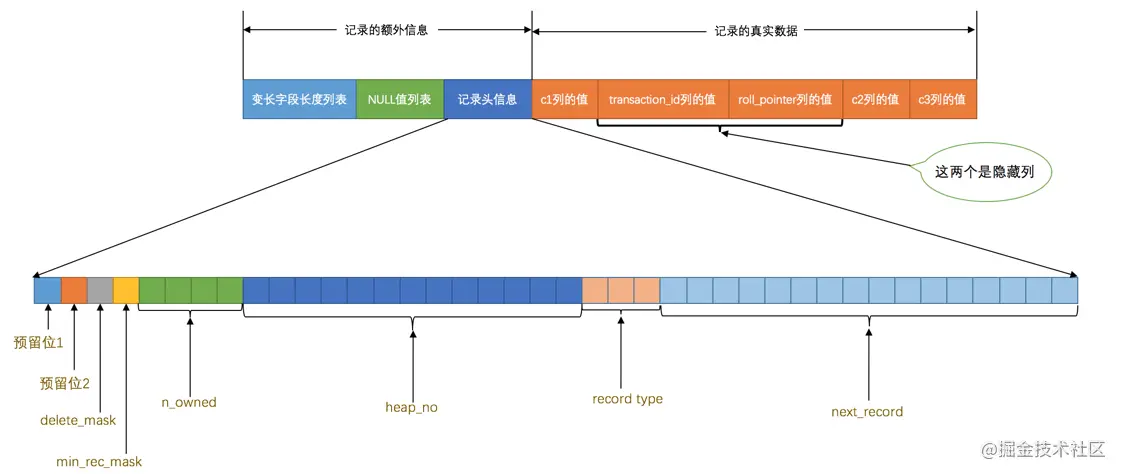
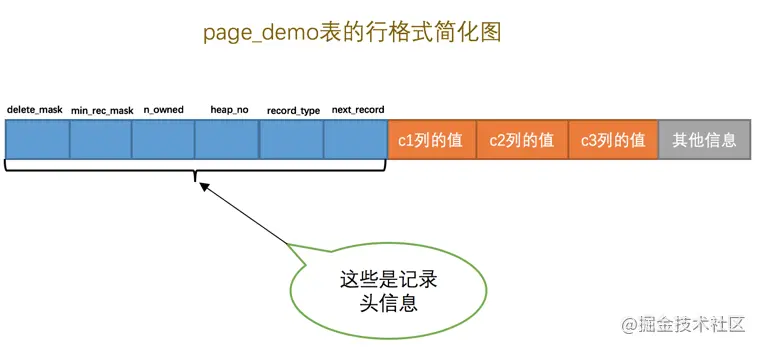



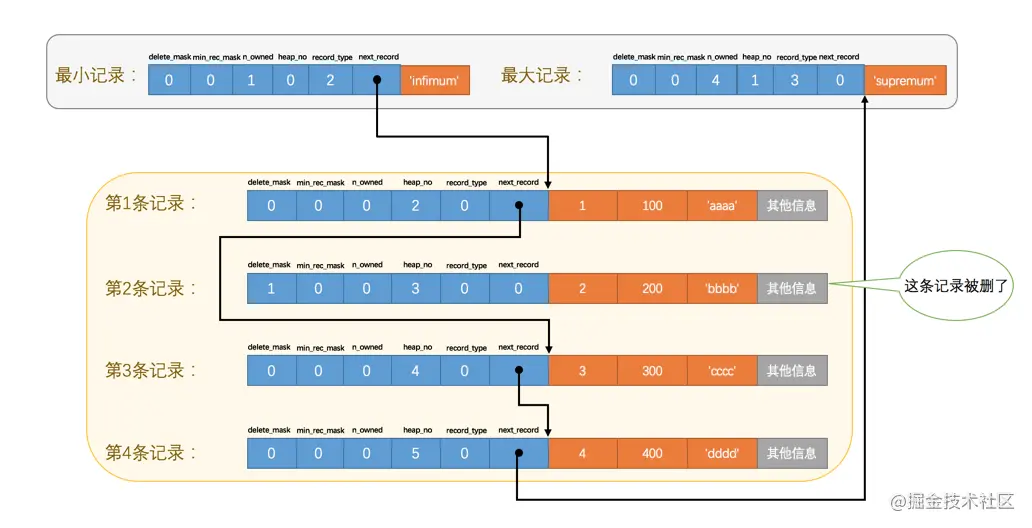
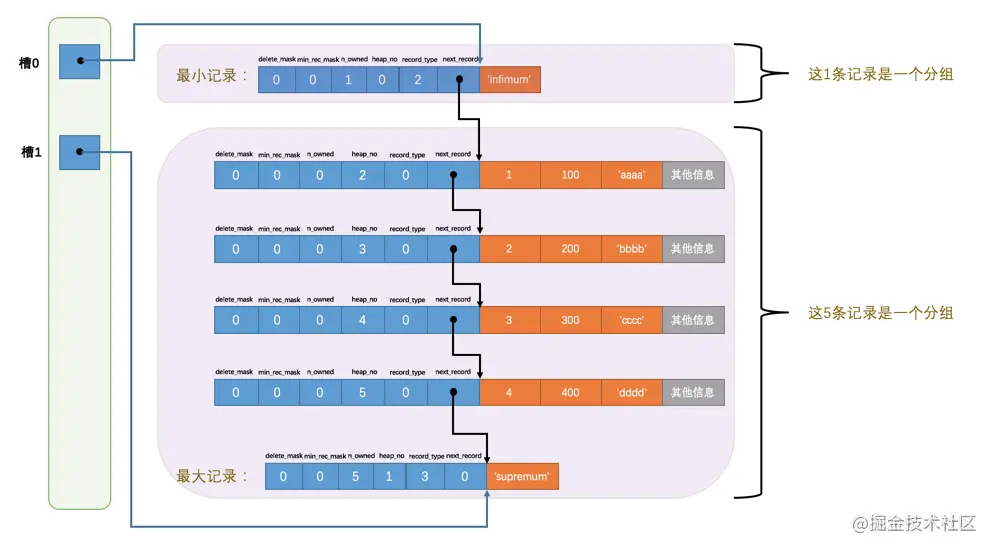

9.3 索引
9.3.1 没有索引的查找
在一个页中的查找
假设目前表中的记录比较少,所有的记录都可以被存放到一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况:
以主键为搜索条件
这个查找过程我们已经很熟悉了,可以在
页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。以其他列作为搜索条件
对非主键列的查找的过程可就不这么幸运了,因为在数据页中并没有对非主键列建立所谓的
页目录,所以我们无法通过二分法快速定位相应的槽。这种情况下只能从最小记录开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。在很多页中查找
大部分情况下我们表中存放的记录都是非常多的,需要好多的数据页来存储这些记录。在很多页中查找记录的话可以分为两个步骤:
- 定位到记录所在的页。(从第一个页沿着双向链表一直往下找)
- 从所在的页内中查找相应的记录。
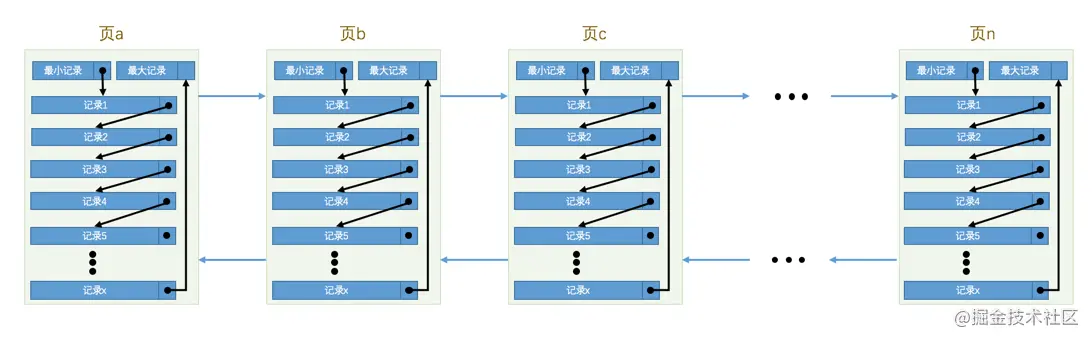
9.3.2 索引
下图表示简化后的行记录与页表示格式:
创建索引的前提:
- 下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
假如页10最多只能放3条记录,新插入一条记录时:
- 给所有的页建立一个目录项
比方以找主键值为
20的记录为例,具体查找过程分两步:
1、先从目录项中根据二分法快速确定出主键值为20的记录在目录项3中(因为12 < 20 < 209),它对应的页是页9;
2、再根据前边说的在页中查找记录的方式去页9中定位具体的记录。
至此,针对数据页做的简易目录就搞定了。这个目录有一个别名,称为索引。InnoDB中的索引方案
由于数据库中的表记录会时常增删,且伴随着数据量的增大,需要非常大的连续的存储空间才能把所有的目录项都放下。对此,InnoDB采用了用户记录和目录项记录分离的方式,采用记录头信息里的record_type属性标识:
0:普通的用户记录
1:目录项记录
2:最小记录
3:最大记录
目录项记录的record_type值是1,而普通用户记录的record_type值是0。
目录项记录只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有InnoDB自己添加的隐藏列。
记录头信息中有一个叫min_rec_mask的属性,只有在存储目录项记录的页中的主键值最小的目录项记录的min_rec_mask值为1,其他别的记录的min_rec_mask值都是0。b+树
当数据量很大时,目录项记录页也会变多,由于这些目录页地址相互之间不连续,为了快速定位目录页,将该目录页再抽象一层高级目录:
即b+树:
b+树的形成
实际上B+树的形成过程是这样的:
每当为某个表创建一个
B+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录。随后向表中插入用户记录时,先把用户记录存储到这个
根节点中。当
根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。这个过程需要大家特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的
根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。在对数据库的操作中,如果不使用索引,那将进行全表扫描,效率非常慢;
在查找数据的过程中,最耗时的是机械寻址过程,为了减少这部分的损耗,我们要尽量减少磁盘I/O。同时,磁盘在读取过程中会进行预读,所以我们采取b+树索引来提高读取效率。
b+树将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。同时,在非叶子节点只储存索引,在叶子节点储存数据,以此来减少磁盘I/O。
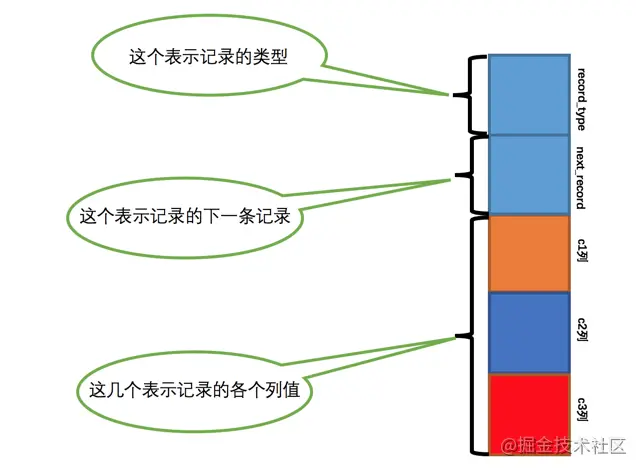
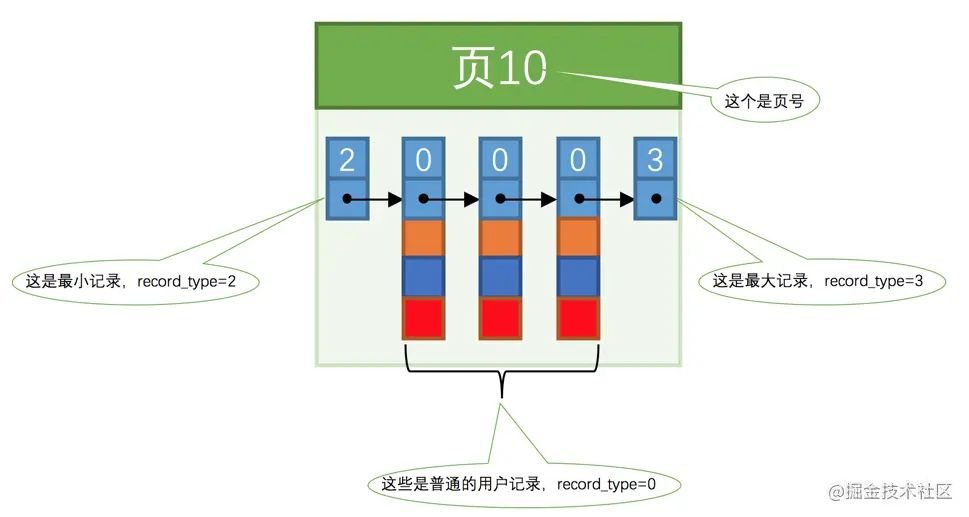
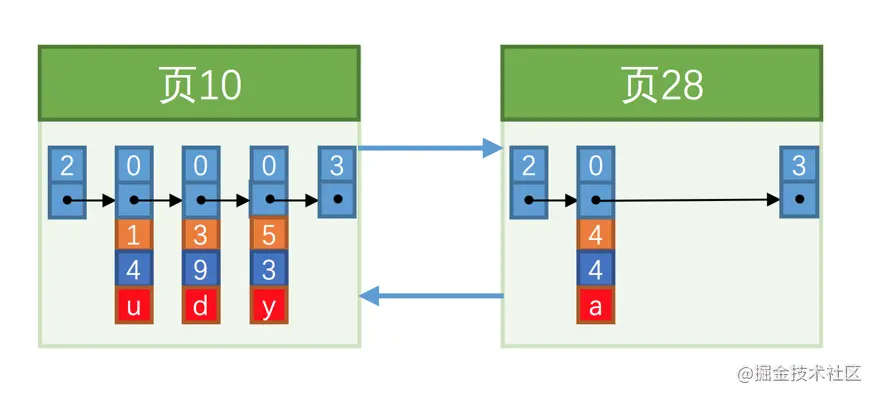
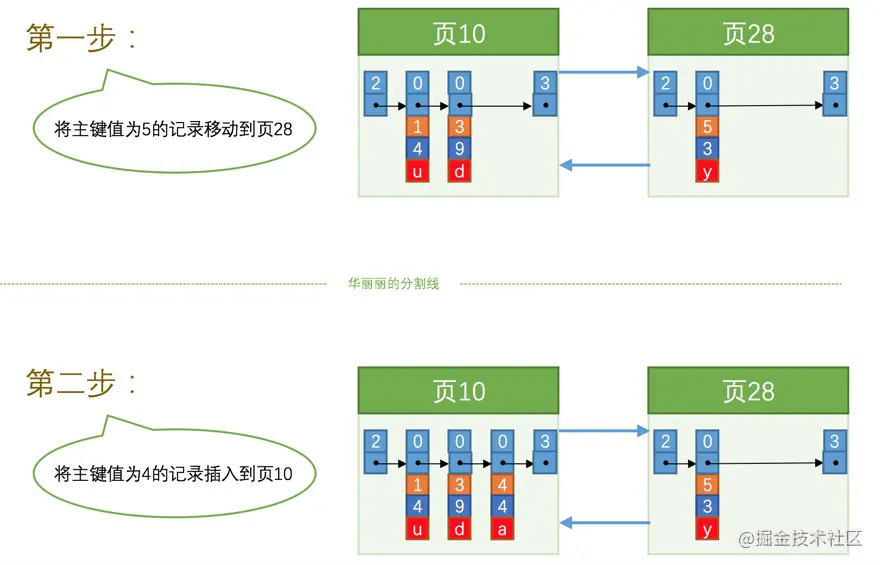
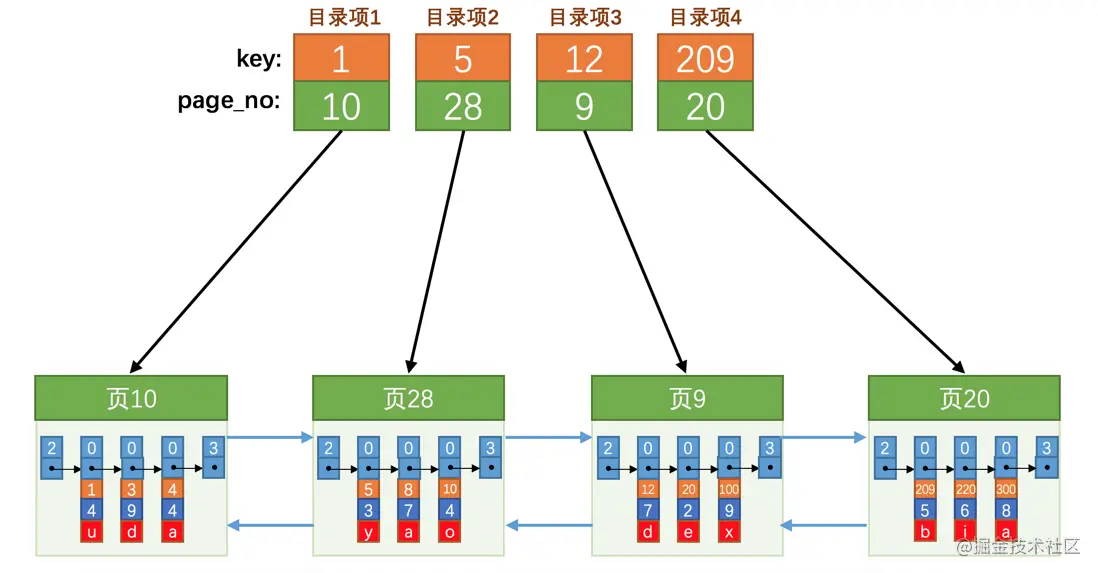
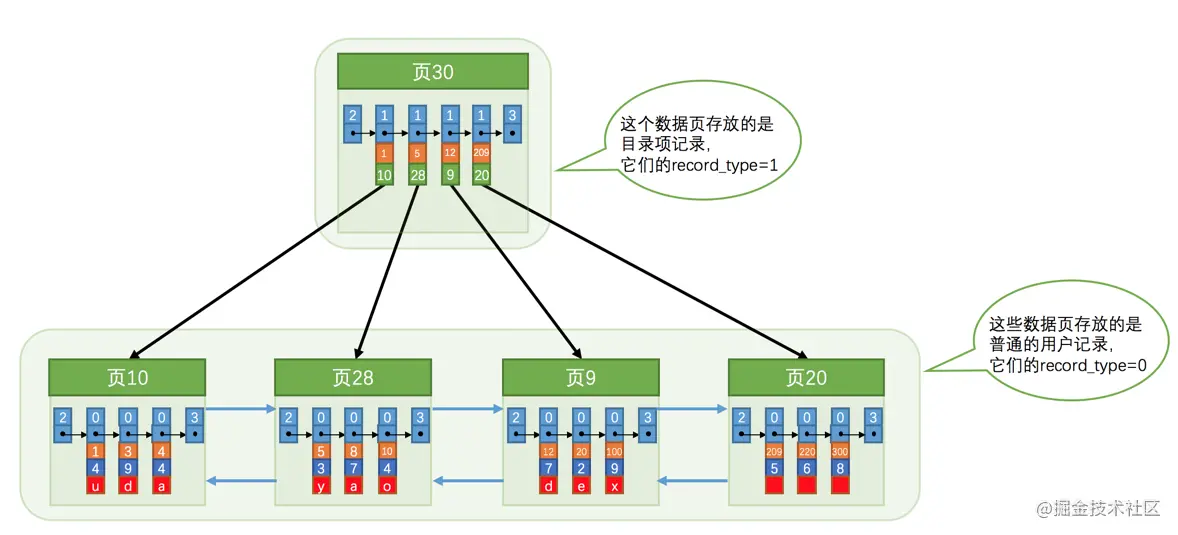
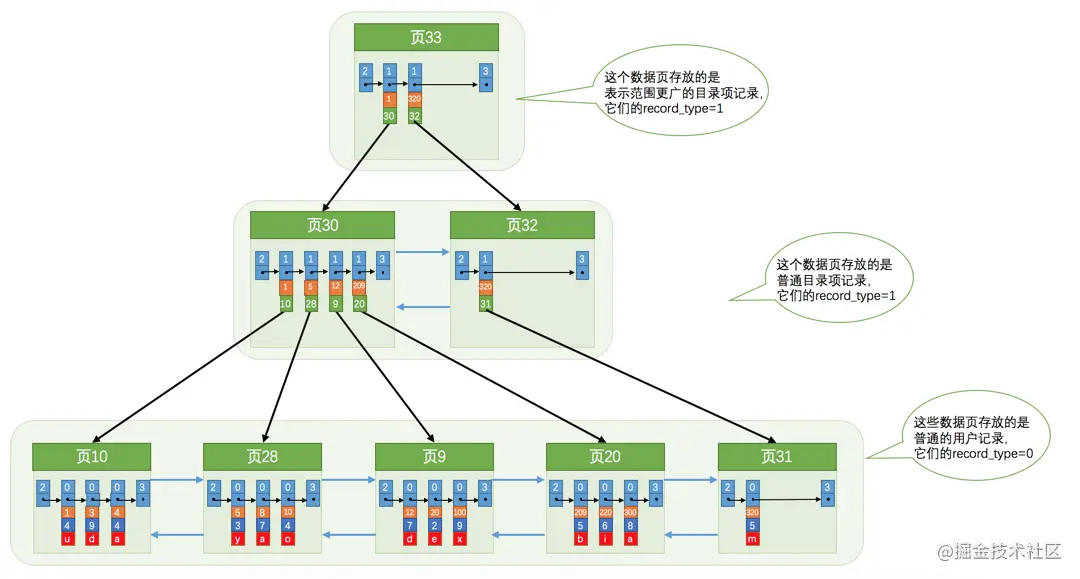

9.3.3 索引分类
聚簇索引
B+树本身就是一个目录,或者说本身就是一个索引。它有两个特点:
1、使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。
各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
2、B+树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建(后边会介绍索引相关的语句),InnoDB存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在InnoDB存储引擎中,聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。如果我们没有为某个表显式的定义主键,并且表中也没有定义Unique键,那么InnoDB会自动的为表添加一个称之为row_id的隐藏列作为主键。
二级索引
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。如果我们想以别的列作为搜索条件,需要建立二级索引(辅助索引),该索引与聚集索引不同:
B+树的叶子节点存储的并不是完整的用户记录,而只是c2列+主键这两个列的值。
目录项记录中不再是主键+页号的搭配,而变成了c2列+页号的搭配。
采用该类索引查找数据步骤:
在二级索引的b+树中确定目录项记录页---->通过目录项记录页确定用户记录真实所在的页---->在真实存储用户记录的页中定位到具体的记录---->找到该记录对应的索引值---->再根据索引值回到聚簇索引所在的b+树种查找记录(回表)。
当索引列值相同时,新插入的列插入位置会引起争议,为了避免这种情况, 在二级索引中目录项的记录项还应包括主键值。
联合索引
可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照c2和c3列的大小进行排序,这个包含两层含义:
先把各个记录和页按照c2列进行排序。
在记录的c2列相同的情况下,采用c3列进行排序。
以c2和c3列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引。它的意思与分别为c2和c3列分别建立索引的表述是不同的。
覆盖索引
为了避免回表操作带来的性能损耗,可以使查询列表里只包含索引列来实现。
建立联合索引(name,birthday,phone_number)SELECT name, birthday, phone_number FROM person_info WHERE name > 'Asa' AND name < 'Barlow'只查找了3个索引列,在联合索引的叶子节点中即可获取,避免回表操作。
唯一索引
允许有多个NULL存在MyISAM索引介绍
MyISAM索引方案虽然也使用树形结构,但是却将索引和数据分开存储:
- 将表中的记录按照记录的插入顺序单独存储在一个文件中,称之为
数据文件。这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少记录就成了。我们可以通过行号而快速访问到一条记录。使用
MyISAM存储引擎的表会把索引信息另外存储到一个称为索引文件的另一个文件中。MyISAM会单独为表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是主键值 + 行号的组合。也就是先通过索引找到对应的行号,再通过行号去找对应的记录!这一点和
InnoDB是完全不相同的,在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引!如果有需要的话,我们也可以对其它的列分别建立索引或者建立联合索引,原理和
InnoDB中的索引差不多,不过在叶子节点处存储的是相应的列 + 行号。这些索引也全部都是二级索引。
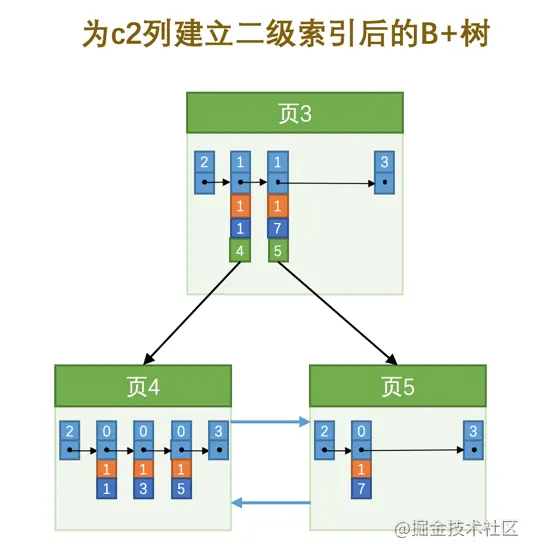
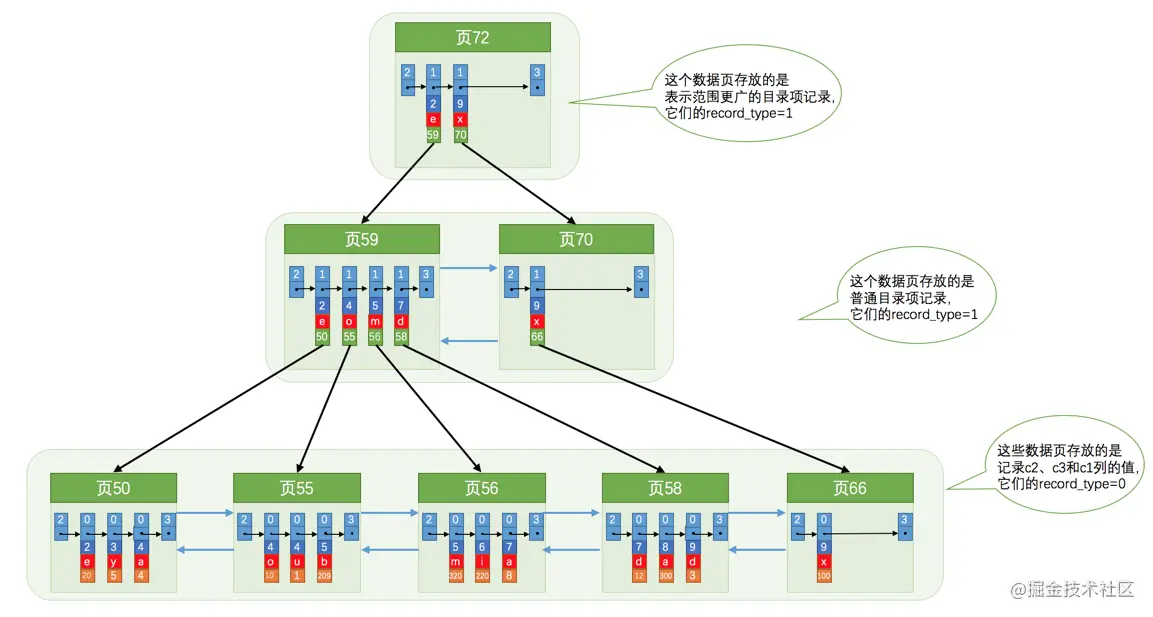
9.3.4 索引的使用
前情概要:
每个索引都对应一棵
B+树,B+树分为好多层,最下边一层是叶子节点,其余的是内节点。所有用户记录都存储在B+树的叶子节点,所有目录项记录都存储在内节点。
InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录。我们可以为自己感兴趣的列建立
二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再到聚簇索引中查找完整的用户记录。
B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。通过索引查找记录是从
B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory(页目录),所以在这些页面中的查找非常快。索引代价
空间代价
时间代价:每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。联合索引适用条件
使用联合索引必须满足最左匹配原则,即查询语句的条件必须按联合索引最左边的索引开始匹配。查询条件的顺序可以不匹配联合索引内索引列的顺序(MYSQL查询优化器会进行优化),但必须从最左端开始包含。匹配列前缀
对于字符串类型的索引列来说,我们只匹配它的前缀也是可以快速定位记录的(使用索引),比方说我们想查询名字以'As'开头的记录,那就可以这么写查询语句:SELECT * FROM person_info WHERE name LIKE 'As%';如果只给出后缀或者中间的某个字符串,
MySQL就无法快速定位记录位置了,只能进行全表扫描。比如这样:SELECT * FROM person_info WHERE name LIKE '%As%';匹配范围值
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';查询步骤:
- 通过B+树在叶子节点中找到第一条
name值大于Asa的二级索引记录,读取该记录的主键值进行回表操作,获得对应的聚簇索引记录后发送给客户端。- 根据上一步找到的记录,沿着记录所在的链表向后查找(同一页面中的记录使用单向链表连接起来,数据页之间用双向链表连接起来)下一条二级索引记录,判断该记录是否符合name < 'Barlow'条件,如果符合,则进行回表操作后发送至客户端。
- 重复上一步骤,直到某条二级索引记录不符合name <'Barlow'条件为止。
在使用联合进行范围查找的时候需要注意,如果对多个列同时进行范围查找的话,只有对索引最左边的那个列进行范围查找的时候才能用到
B+树索引,SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';对于联合索引来说,只能用到
name列的部分,而用不到birthday列的部分,因为只有name值相同的情况下才能用birthday列的值进行排序。
但是如果左边的列是精确查找,右边的列进行范围查找能使用联合索引。用于排序
当查询语句中使用order by进行排序时,一般情况下,只能把记录都加载到内存中,再用一些排序算法,比如快速排序、归并排序、吧啦吧啦排序等等在内存中对这些记录进行排序,有的时候可能查询的结果集太大以至于不能在内存中进行排序的话,还可能暂时借助磁盘的空间来存放中间结果(在内存中或者磁盘上进行排序的方式统称为文件排序)。SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;如果建立联合索引(name, birthday, phone_number),上述查询将直接返回联合索引叶子节点对应的主键,再回表返回数据。
不能使用索引进行排序情况
- 在使用联合索引情况下,各列排序方式不同,ASC、DESC混用;
- 排序列包含非同一个索引的列;
- 排序列使用了复杂的表达式,如:
SELECT * FROM person_info ORDER BY UPPER(name) LIMIT 10;用于分组
SELECT name, birthday, phone_number, COUNT(*) FROM person_info GROUP BY name, birthday, phone_number此语句将先后进行3次分组操作:先以name分组,在name的分组中再对birthday分组,在birthday的分组中再对phone_number分组。
回表的代价
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';使用上述语句查询时,首先将采用二级索引查询符合条件的name列对应的主键id。 由于该叶子节点顺序连续,集中分布在一个或几个数据页中,采用顺序I/O方式即可读取,速度较快。由于主键Id并不相连,对应的数据记录可能分布在不连续的页,所以访问方式为随机I/O,速度较慢。
整个过程使用了一个二级索引,一个聚簇索引。访问二级索引使用顺序I/O,访问聚簇索引使用随机I/O。需要回表的记录越多,使用二级索引的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用二级索引。比方说name值在Asa~Barlow之间的用户记录数量占全部记录数量90%以上,那么如果使用idx_name_birthday_phone_number索引的话,有90%多的id值需要回表,这不是吃力不讨好么,还不如直接去扫描聚簇索引(也就是全表扫描)。
那什么时候采用全表扫描的方式,什么时候使用采用二级索引 + 回表的方式去执行查询呢?这个就是传说中的查询优化器做的工作,查询优化器会事先对表中的记录计算一些统计数据,然后再利用这些统计数据根据查询的条件来计算一下需要回表的记录数,需要回表的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引 + 回表的方式。如何挑选索引
- 只为用于搜索、排序或分组的列创建索引
考虑列的基数:列的基数指的是某一列中不重复数据的个数,即数据区分度,基数太小列的建立索引效果可能不好。- 索引列的类型尽量小:数据越小,查询越快,同时一个数据也能放下更多的记录,减小磁盘I/O消耗。
- 索引字符串值的前缀:如果索引过长,会过多占用数据页空间,且做字符串时也会耗时更久。所以建议对较长字符串做索引字符串前缀处理。(不支持索引排序)
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)- 让索引列在比较表达式中单独出现:
WHERE my_col * 2 < 4 此种情况存储引擎会依次遍历所有的记录,计算这个表达式的值是不是小于4,用不到索引;建议修改为WHERE my_col < 4/2- 主键插入顺序:对于一个使用
InnoDB存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。如果插入的主键值忽大忽小,可能会造成页面分裂,引起性能损耗。- 避免冗余和复杂索引:如:
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
9.3.4 访问方法
MySQL执行查询语句的方式称之为访问方法或者访问类型。
const通过主键或者唯一二级索引列来定位一条记录的访问方法定义为:
const,意思是常数级别的,代价是可以忽略不计的。ref
对某个普通的二级索引列与常数进行等值比较,比如这样:SELECT * FROM single_table WHERE key1 = 'abc';对于这个查询,我们当然可以选择全表扫描来逐一对比搜索条件是否满足要求,我们也可以先使用二级索引找到对应记录的
id值,然后再回表到聚簇索引中查找完整的用户记录。由于普通二级索引并不限制索引列值的唯一性,所以可能找到多条对应的记录,也就是说使用二级索引来执行查询的代价取决于等值匹配到的二级索引记录条数。如果匹配的记录较少,则回表的代价还是比较低的,所以MySQL可能选择使用索引而不是全表扫描的方式来执行查询。设计MySQL的大叔就把这种搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为:ref。ref_or_null
SELECT * FROM single_table WHERE key1 = 'abc' OR key1 IS NULL;当使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问方法就称为
ref_or_null。range
之前介绍的几种访问方法都是在对索引列与某一个常数进行等值比较的时候才可能使用到。SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);可以使用全表扫描的方式来执行这个查询,不过也可以使用
二级索引 + 回表的方式执行。如果采用二级索引 + 回表的方式来执行的话,那么此时需要匹配某个或某些范围的值。这种利用索引进行范围匹配的访问方法称之为:range。index
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';由于
key_part2并不是联合索引idx_key_part最左索引列,所以我们无法使用ref或者range访问方法来执行这个语句。但是这个查询符合下边这两个条件:
它的查询列表只有3个列:
key_part1,key_part2,key_part3,而索引idx_key_part又包含这三个列。搜索条件中只有
key_part2列。这个列也包含在索引idx_key_part中。也就是说我们可以直接通过遍历
idx_key_part索引的叶子节点的记录来比较key_part2 = 'abc'这个条件是否成立,把匹配成功的二级索引记录的key_part1,key_part2,key_part3列的值直接加到结果集中就行了。由于二级索引记录比聚簇索记录小的多(聚簇索引记录要存储所有用户定义的列以及所谓的隐藏列,而二级索引记录只需要存放索引列和主键),而且这个过程也不用进行回表操作,所以直接遍历二级索引比直接遍历聚簇索引的成本要小很多,设计MySQL的大叔就把这种采用遍历二级索引记录的执行方式称之为:index。all
全表扫描,对于InnoDB表来说也就是直接扫描聚簇索引,设计MySQL的大叔把这种使用全表扫描执行查询的方式称之为:all。索引合并:Intersection合并、Union合并、Sort-Union合并
Intersection合并 ?????
SELECT * FROM single_table WHERE key1 = 'a' AND key3 = 'b';假设这个查询使用
Intersection合并的方式执行的话,那这个过程就是这样的:
从idx_key1二级索引对应的B+树中取出key1 = 'a'的相关记录。
从idx_key3二级索引对应的B+树中取出key3 = 'b'的相关记录。
计算出这两个结果集中id值的交集。
回表操作。
另一种方式是只根据某个搜索条件去读取一个二级索引,然后回表后再过滤另外一个搜索条件,相比于此种方式,索引合并效率更高,因为二级索引是顺序I/O,回表是随机I/O。
Intersection索引合并条件:??????
情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况(若不是全部列)。
情况二:主键列可以是范围匹配。
部分情况下可用联合索引替代Intersection索引合并。Union合并
SELECT * FROM single_table WHERE key1 = 'a' OR key3 = 'b'
Union索引合并条件
情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
情况二:主键列可以是范围匹配
情况三:使用Intersection索引合并的搜索条件Sort-Union合并
Union索引合并的使用条件太苛刻,必须保证各个二级索引列在进行等值匹配的条件下才可能被用到。
我们把上述这种先按照二级索引记录的主键值进行排序,之后按照Union索引合并方式执行的方式称之为Sort-Union索引合并,很显然,这种Sort-Union索引合并比单纯的Union索引合并多了一步对二级索引记录的主键值排序的过程。
9.4 表连接
连接过程
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';执行上述语句, 第一个需要查询的表t1称为驱动表,t2称为被驱动表。
- 根据t1.m1>1到t1中查询到匹配记录,假如有两条:ti.m1=2, ti.m1=3
- 对t1查询到的值,分别带入到t2中进行查询
即上述语句需要在t1中查询1次,在t2中查询2次。(尽量减少对被驱动表的访问次数)
连接分类
内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。对于
外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。左外连接:选取左侧的表为驱动表。
右外连接:选取右侧的表为驱动表。
过滤条件 on与where区别
WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。内连接中的WHERE子句和ON子句是等价的。左连接:SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; 右连接:SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件]; 内连接:SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件]; 内连接:SELECT * FROM t1, t2;
9.5 MySQL优化
9.5.1 基于成本的优化
成本
I/O成本:我们的表经常使用的MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中然后再操作。这个从磁盘到内存这个加载的过程损耗的时间称之为I/O成本。
CPU成本:读取以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称之为CPU成本。优化步骤
在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案,这个成本最低的方案就是所谓的执行计划,之后才会调用存储引擎提供的接口真正的执行查询,这个过程总结一下就是这样:
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价:查询成本=
I/O成本+CPU成本,所以计算全表扫描的代价需要两个信息:聚簇索引占用的页面数、该表中的记录数。聚簇索引的页面数量 = Data_length(占用储存空间数,从表信息中获取)÷ 16 ÷ 1024 = 97- 计算使用不同索引执行查询的代价:从第1步分析我们得到,上述查询可能使用到
idx_key1和idx_key2这两个索引,我们需要分别分析单独使用这些索引执行查询的成本,最后还要分析是否可能使用到索引合并。这里需要提一点的是,MySQL查询优化器先分析使用唯一二级索引的成本,再分析使用普通索引的成本- 对比各种执行方案的代价,找出成本最低的那一个
连接查询成本
连接查询的成本计算公式是这样的:
连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 x 单次访问被驱动表的成本
9.5.2 基于规则优化
MYSQL会依据一些规则,对执行的查询语句进行一定优化,转换成某种可以比较高效执行的形式,这个过程也可以被称作
查询重写。下面是查询重写的几种规则:条件化简
移除无效括号,如:((a = 5 AND b = c) OR ((a > c) AND (c < 5)))
常量传递,如:a = 5 AND b > a ----> a = 5 AND b > 5
等值传递,如:a = b and b = c and c = 5 ---> a = 5 and b = 5 and c = 5
移除无效条件,如:(a < 1 and b = b) OR (a = 6 OR 5 != 5)
表达式计算,如:a = 5 + 1 ---> a = 6
如果某个列并不是以单独的形式作为表达式的操作数时,比如出现在函数中,出现在某个更复杂表达式中,优化器是不会尝试对这些表达式进行化简的。所以尽量让索引列以单独的形式出现在表达式中。HAVING子句和WHERE子句的合并
如果查询语句中没有出现诸如SUM、MAX等等的聚集函数以及GROUP BY子句,优化器就把HAVING子句和WHERE子句合并起来。常量表检测
设计MySQL的大叔觉得下边这两种查询运行的特别快:
- 查询的表中一条记录没有,或者只有一条记录。
使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表。
这两种查询花费的时间特别少,少到可以忽略,所以也把通过这两种方式查询的表称之为
常量表(英文名:constant tables)。优化器在分析一个查询语句时,先首先执行常量表查询,然后把查询中涉及到该表的条件全部替换成常数,最后再分析其余表的查询成本。外连接消除
我们前边说过,内连接的驱动表和被驱动表的位置可以相互转换,而左(外)连接和右(外)连接的驱动表和被驱动表是固定的。这就导致内连接可能通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2 WHERE t2.m2 = 2;我们把这种在外连接查询中,指定的
WHERE子句中包含被驱动表中的列不为NULL值的条件称之为空值拒绝(英文名:reject-NULL)。在被驱动表的WHERE子句符合空值拒绝的条件后,外连接和内连接可以相互转换。这种转换带来的好处就是查询优化器可以通过评估表的不同连接顺序的成本,选出成本最低的那种连接顺序来执行查询。子查询
名词
标量子查询:只返回一个单一值的子查询
行子查询:返回一条记录的子查询,不过这条记录需要包含多个列
列子查询:查询出一个列的数据,不过这个列的数据需要包含多条记录
表子查询:子查询的结果既包含很多条记录,又包含很多个列
不相关子查询:如果子查询可以单独运行出结果,而不依赖于外层查询的值,我们就可以把这个子查询称之为不相关子查询相关子查询:如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称之为
相关子查询子查询语法
SELECT子句中
FROM子句中
WHERE或ON子句中:子查询的结果只能返回一个单一的值或者只能是一条记录SELECT (SELECT m1 FROM t1 LIMIT 1); SELECT m, n FROM (SELECT m2 + 1 AS m, n2 AS n FROM t2 WHERE m2 > 2) AS t; SELECT * FROM t1 WHERE m1 IN (SELECT m2 FROM t2);子查询在布尔表达式中应用 SELECT * FROM t1 WHERE m1 < (SELECT MIN(m2) FROM t2); SELECT * FROM t1 WHERE (m1, n1) = (SELECT m2, n2 FROM t2 LIMIT 1); SELECT * FROM t1 WHERE (m1, n1) IN (SELECT m2, n2 FROM t2); SELECT * FROM t1 WHERE m1 > ANY(SELECT m2 FROM t2); 存在一个即为true SELECT * FROM t1 WHERE m1 > (SELECT MIN(m2) FROM t2); SELECT * FROM t1 WHERE m1 > (SELECT MIN(m2) FROM t2); SELECT * FROM t1 WHERE m1 > ALL(SELECT m2 FROM t2); 全部成立才为true SELECT * FROM t1 WHERE EXISTS (SELECT 1 FROM t2); 只要(SELECT 1 FROM t2)这个查询中有记录,那么整个EXISTS表达式的结果就为TRUE。注意事项:
子查询必须用小括号扩起来。
在SELECT子句中的子查询必须是标量子查询
在想要得到标量子查询或者行子查询,但又不能保证子查询的结果集只有一条记录时,应该使用LIMIT 1语句来限制记录数量。
对于[NOT] IN/ANY/SOME/ALL子查询来说,子查询中不允许有LIMIT语句
子查询语句中的order by、distinct等语句没有意义子查询执行方式
不相关标量子查询、行子查询的执行方式SELECT * FROM s1 WHERE key1 = (SELECT common_field FROM s2 WHERE key3 = 'a' LIMIT 1);先单独执行
(SELECT common_field FROM s2 WHERE key3 = 'a' LIMIT 1)这个子查询.
然后在将上一步子查询得到的结果当作外层查询的参数再执行外层查询SELECT * FROM s1 WHERE key1 = ...。
可以当作两个单表查询。相关的标量子查询或者行子查询
SELECT * FROM s1 WHERE key1 = (SELECT common_field FROM s2 WHERE s1.key3 = s2.key3 LIMIT 1);
先从外层查询中获取一条记录,本例中也就是先从
s1表中获取一条记录。然后从上一步骤中获取的那条记录中找出子查询中涉及到的值,本例中就是从
s1表中获取的那条记录中找出s1.key3列的值,然后执行子查询。最后根据子查询的查询结果来检测外层查询
WHERE子句的条件是否成立,如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。再次执行第一步,获取第二条外层查询中的记录,依次类推~
IN子查询优化
不相关IN子查询SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a');对于不相关的
IN子查询来说,如果单独执行子查询后的结果集太多的话,就会导致这些问题:
结果集太多,可能内存中都放不下~
对于外层查询来说,如果子查询的结果集太多,那就意味着
IN子句中的参数特别多,这就导致:
无法有效的使用索引,只能对外层查询进行全表扫描。
在对外层查询执行全表扫描时,由于
IN子句中的参数太多,这会导致检测一条记录是否符合和IN子句中的参数匹配花费的时间太长。为了解决此问题,MySQL提出不直接将不相关子查询的结果集当作外层查询的参数,而是将该结果集写入一个临时表里:
该临时表的列就是子查询结果集中的列。
写入临时表的记录会被去重。
一般情况下子查询结果集不会大的离谱,所以会为它建立基于内存的使用
Memory存储引擎的临时表,而且会为该表建立哈希索引。把这个将子查询结果集中的记录保存到临时表的过程称之为
物化(英文名:Materialize)。为了方便起见,我们就把那个存储子查询结果集的临时表称之为物化表。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行IN语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
.................................详细内容请看原著
小结:
如果
IN子查询符合转换为semi-join的条件,查询优化器会优先把该子查询转换为semi-join,然后再考虑下边5种执行半连接的策略中哪个成本最低:
- Table pullout
- DuplicateWeedout
- LooseScan
- Materialization
- FirstMatch
选择成本最低的那种执行策略来执行子查询。
如果
IN子查询不符合转换为semi-join的条件,那么查询优化器会从下边两种策略中找出一种成本更低的方式执行子查询:
- 先将子查询物化之后再执行查询
- 执行
IN to EXISTS转换。
9.5.3 explain
9.5.4 optimizer trace
9.6 Buffer Pool
对于使用
InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的。InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘IO的开销了。
设计InnoDB的大叔为了缓存磁盘中的页,在MySQL服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做Buffer Pool(中文名是缓冲池)。为了更好的管理这些在Buffer Pool中的缓存页,为每一个缓存页都创建了一些所谓的控制信息,包括该页所属的表空间编号、页号、缓存页在Buffer Pool中的地址、链表节点信息、一些锁信息以及LSN信息等。每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块。在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。结构如下:
free链表管理
当我们最初启动MySQL服务器的时候,需要完成对Buffer Pool的初始化过程,就是先向操作系统申请Buffer Pool的内存空间,然后把它划分成若干对控制块和缓存页。随着程序运行,在向buffer pool中放入数据页时,如何知道哪些数据页空闲?对此,引入free链表(空闲链表)概念:把所有空闲的缓存页对应的控制块作为一个节点放到一个链表中。
链表的基节点占用的内存空间并不包含在为
Buffer Pool申请的一大片连续内存空间之内,而是单独申请的一块内存空间。
有了这个free链表之后事儿就好办了,每当需要从磁盘中加载一个页到Buffer Pool中时,就从free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上(就是该页所在的表空间、页号之类的信息),然后把该缓存页对应的free链表节点从链表中移除。缓存页的哈希处理
当我们需要访问某个页中的数据时,就会把该页从磁盘加载到Buffer Pool中,如果该页已经在Buffer Pool中的话直接使用就可以了。
如何判断该页是否存在于buffer pool中?
我们其实是根据表空间号 + 页号来定位一个页的。所以我们可以用表空间号 + 页号作为key,缓存页作为value创建一个哈希表,在需要访问某个页的数据时,进行hash判断即可。flush链表的管理
如果我们修改了Buffer Pool中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为脏页(英文名:dirty page)。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步。
再创建一个存储脏页的链表,凡是修改过的缓存页对应的控制块都会作为一个节点加入到一个链表中,因为这个链表节点对应的缓存页都是需要被刷新到磁盘上的,所以也叫flush链表。链表的构造和free链表大致相同。
LRU链表的管理
- 简单的LRU链表
当Buffer Pool中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。按照最近最少使用的原则去淘汰缓存页的,所以这个链表可以被称为LRU链表(Least Recently Used)。
当我们需要访问某个页时,把该缓存页调整到LRU链表的头部,这样LRU链表尾部就是最近最少使用的缓存页。当Buffer Pool中的空闲缓存页使用完时,直接淘汰LRU链表的尾部缓存页。
划分区域的LRU链表
简单的
LRU链表使用会存在部分问题,如以下两种情况:
情况一:InnoDB提供了一个看起来比较贴心的服务——预读(英文名:read ahead)。所谓预读,就是InnoDB认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到Buffer Pool中。根据触发方式的不同,预读分为线性预读和随机预读。
线性预读:设计InnoDB的大叔提供了一个系统变量innodb_read_ahead_threshold,如果顺序访问了某个区(extent)的页面超过这个系统变量的值,就会触发一次异步读取下一个区中全部的页面到Buffer Pool的请求,注意异步读取意味着从磁盘中加载这些被预读的页面并不会影响到当前工作线程的正常执行。
随即预读:如果Buffer Pool中已经缓存了某个区的13个连续的页面,不论这些页面是不是顺序读取的,都会触发一次异步读取本区中所有其的页面到Buffer Pool的请求。设计InnoDB的大叔同时提供了innodb_random_read_ahead系统变量,它的默认值为OFF。如果我们想开启该功能,可以通过修改启动参数或者直接使用SET GLOBAL命令把该变量的值设置为ON。
若采用简单的LRU链表,预读的页都会放到LRU链表的头部,但是如果此时Buffer Pool的容量不太大而且很多预读的页面都没有用到的话,这就会导致处在LRU链表尾部的一些缓存页会很快的被淘汰掉,会大大降低缓存命中率。
情况二:某些查询语句需要全表扫描。扫描全表意味着将访问到该表所在的所有页!这些页将全部被加载到Buffer Pool中。此时,其他查询语句在执行时又得执行一次从磁盘加载到Buffer Pool的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把Buffer Pool中的缓存页换一次血,这严重的影响到其他查询对Buffer Pool的使用,从而大大降低了缓存命中率。
总结以上两种情况,即加载到buffer pool的页不一定能用上、会有命中率低的页加载到buffer pool并把命中率高的页顶替掉。
对此,设计InnoDB的大叔把这个LRU链表按照一定比例分成两截,分别是:
一部分存储使用频率非常高的缓存页,所以这一部分链表也叫做热数据,或者称young区域。
另一部分存储使用频率不是很高的缓存页,所以这一部分链表也叫做冷数据,或者称old区域。
我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的。
对此,对上述两种情况进行优化:
针对预读的页面可能不进行后续访问情况的优化
设计InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。
咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的。更进一步优化LRU链表
对于young区域的缓存页来说,我们每次访问一个缓存页就要把它移动到LRU链表的头部,这样开销太大。毕竟在young区域的缓存页都是热点数据,也就是可能被经常访问的。为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页位于young区域的1/4的后边,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从而提升性能(也就是说如果某个缓存页对应的节点在young区域的1/4中,再次访问该缓存页时也不会将其移动到LRU链表头部)。刷新脏页到磁盘
后台有专门的线程每隔一段时间负责把脏页刷新到磁盘,这样可以不影响用户线程处理正常的请求。主要有两种刷新路径:
从LRU链表的冷数据中刷新一部分页面到磁盘。
后台线程会定时从LRU链表尾部开始扫描一些页面,扫描的页面数量可以通过系统变量innodb_lru_scan_depth来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称之为BUF_FLUSH_LRU。
从flush链表中刷新一部分页面到磁盘。
后台线程也会定时从flush链表中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为BUF_FLUSH_LIST。多个Buffer Pool实例
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数
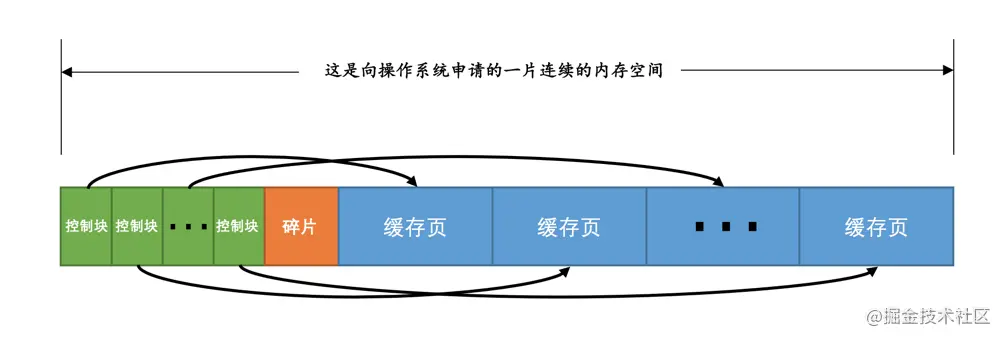
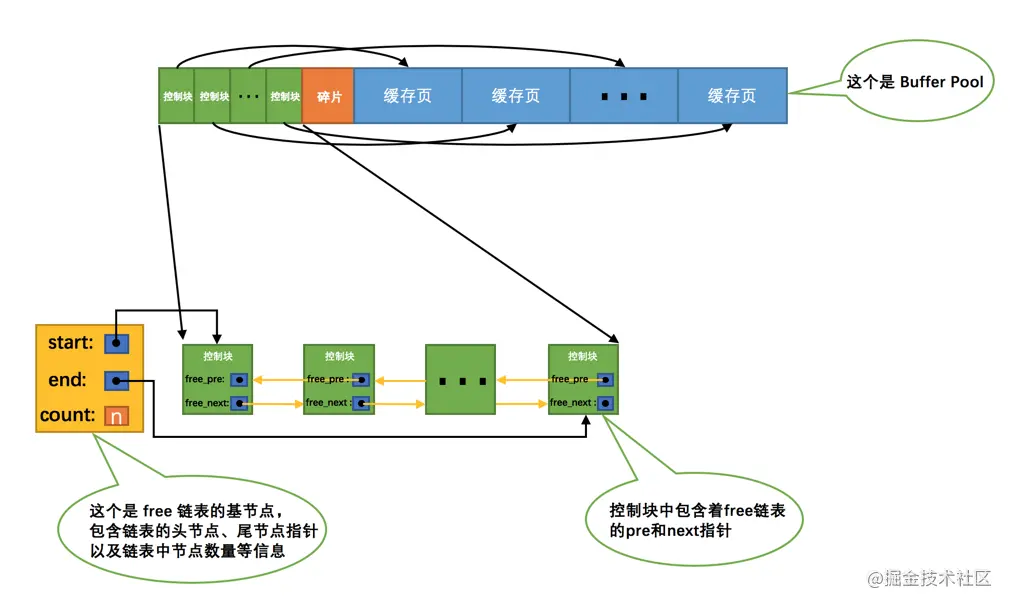
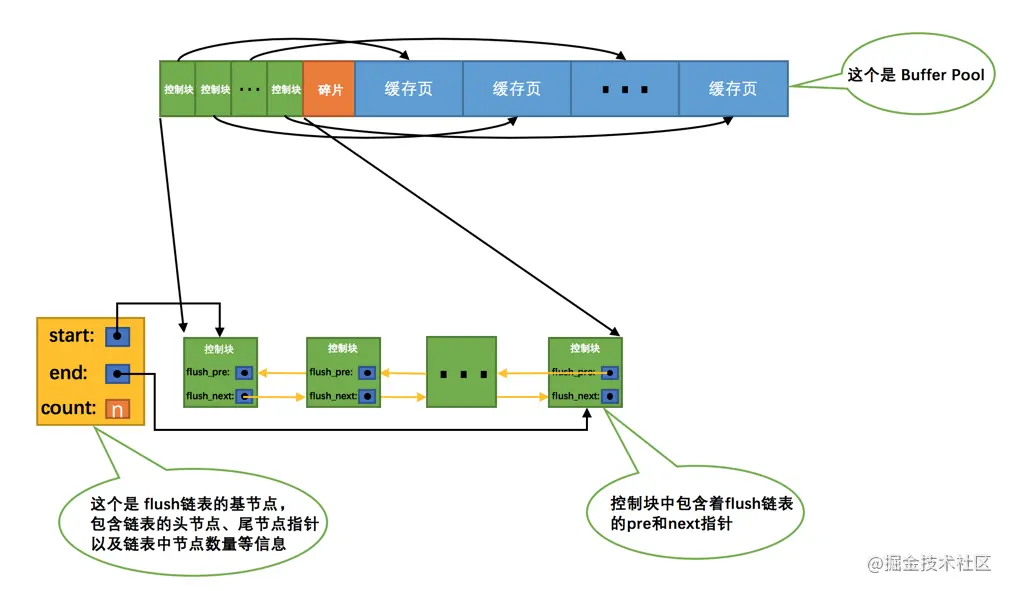
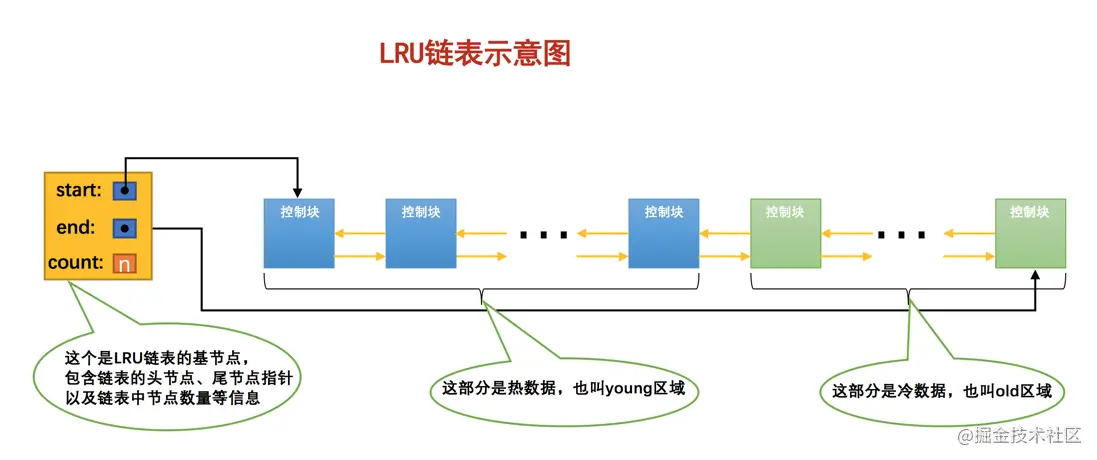
9.7 事务
9.7.1 事务简介
四大特性
数据库操作过程中需要满足4个特性:原子性(Atomicity)、隔离性(Isolation)、一致性(Consistency)和持久性(Durability)。把需要保证原子性、隔离性、一致性和持久性的一个或多个数据库操作称之为一个事务(transaction)。事务状态
事务有如下几个状态:
活动的(active):事务对应的数据库操作正在执行过程中时,我们就说该事务处在活动的状态。
部分提交的(partially committed):当事务中的最后一个操作执行完成,但由于操作都在内存中执行,所造成的影响并没有刷新到磁盘时,我们就说该事务处在部分提交的状态。
失败的(failed):当事务处在活动的或者部分提交的状态时,可能遇到了某些错误(数据库自身的错误、操作系统错误或者直接断电等)而无法继续执行,或者人为的停止当前事务的执行,我们就说该事务处在失败的状态。
中止的(aborted):如果事务执行了半截而变为失败的状态,需要撤销失败事务对当前数据库造成的影响。把这个撤销的过程称之为回滚。当回滚操作执行完毕时,也就是数据库恢复到了执行事务之前的状态,我们就说该事务处在了中止的状态。
提交的(committed):当一个处在部分提交的状态的事务将修改过的数据都同步到磁盘上之后,我们就可以说该事务处在了提交的状态。
事务的操作
开启事务BEGIN; select..... START TRANSACTION; select.....以上两种方式均可开启事务,START TRANSACTION可以在后面添加修饰符限制事务权限:
READ ONLY(只读)
READ WRITE(读写)
WITH CONSISTENT SNAPSHOT(一致性读)
提交事务:commit
回滚:rollbackMySQL中并不是所有存储引擎都支持事务的功能,目前只有InnoDB和NDB存储引擎支持。
自动提交
MySQL中有系统变量autocommit,表示自动提交,默认打开。默认情况下,如果我们不显式的使用START TRANSACTION或者BEGIN语句开启一个事务,那么每一条语句都算是一个独立的事务,这种特性称之为事务的自动提交。
如果我们想关闭这种自动提交的功能,可以使用下边两种方法之一:
显式的的使用
START TRANSACTION或者BEGIN语句开启一个事务。这样在本次事务提交或者回滚前会暂时关闭掉自动提交的功能。
把系统变量
autocommit的值设置为OFF。
隐式提交
当我们使用START TRANSACTION或者BEGIN语句开启了一个事务,或者把系统变量autocommit的值设置为OFF时,事务就不会进行自动提交,但是如果我们输入了某些语句之后就会悄悄的提交掉,就像我们输入了COMMIT语句了一样,这种因为某些特殊的语句而导致事务提交的情况称为隐式提交,这些会导致事务隐式提交的语句包括:
定义或修改数据库对象的数据定义语言(Data definition language,缩写为:DDL)。
隐式使用或修改mysql数据库中的表
事务控制或关于锁定的语句
加载数据的语句·····
保存点
设计数据库的大叔们提出了一个保存点(英文:savepoint)的概念,就是在事务对应的数据库语句中打几个点,我们在调用ROLLBACK语句时可以指定会滚到哪个点,而不是回到最初的原点。设置保存点:SAVEPOINT 保存点名称; 回滚到指定保存点:ROLLBACK [WORK] TO [SAVEPOINT] 保存点名称; 删除保存点:RELEASE SAVEPOINT 保存点名称;
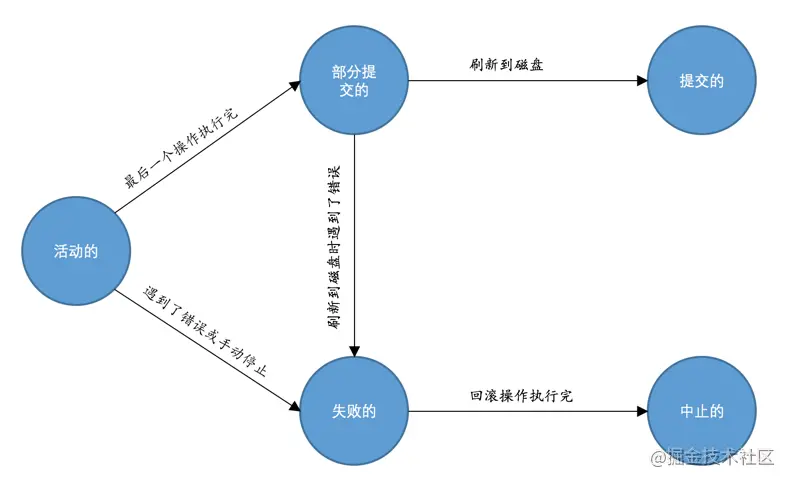
9.7.2 事务隔离级别和MVCC
MySQL是一个客户端/服务器架构的软件,对于同一个服务器来说,可以有若干个客户端与之连接,每个客户端与服务器连接上之后,就可以称之为一个会话(Session)。事务并发遇到的问题
脏写:一个事务修改了另一个事务修改单未提交的数据;
脏读:一个事务读取了另一个事务修改但未提交的数据;
不可重复读:一个事务在执行期间,多次读取同一数据时,在这期间如果有另一事务对该数据进行了修改,原事务每次都能读到最新值,那么就会产生不可重复读。
幻读:一个事务根据查询条件得到部分记录后,如果有另一事务插入了符合该条件的数据,此时原事务再根据相同条件进行查询会把另一事务新插入的记录也读取出来。四种隔离级别
READ UNCOMMITTED:未提交读。
READ COMMITTED:已提交读。
REPEATABLE READ:可重复读。
SERIALIZABLE:可串行化。
MySQL的默认隔离级别为REPEATABLE READ,我们可以手动修改一下事务的隔离级别。SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL SERIALIZABLE;MVCC
版本链
对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列(row_id并不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含row_id列):
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
小贴士: 实际上insert undo只在事务回滚时起作用,当事务提交后,该类型的undo日志就没用了,它占用的Undo Log Segment也会被系统回收(也就是该undo日志占用的Undo页面链表要么被重用,要么被释放)。虽然真正的insert undo日志占用的存储空间被释放了,但是roll_pointer的值并不会被清除,roll_pointer属性占用7个字节,第一个比特位就标记着它指向的undo日志的类型,如果该比特位的值为1时,就代表着它指向的undo日志类型为insert undo。所以我们之后在画图时都会把insert undo给去掉,大家留意一下就好了。
能不能在两个事务中交叉更新同一条记录呢?哈哈,这不就是一个事务修改了另一个未提交事务修改过的数据,沦为了脏写了么?InnoDB使用锁来保证不会有脏写情况的发生,也就是在第一个事务更新了某条记录后,就会给这条记录加锁,另一个事务再次更新时就需要等待第一个事务提交了,把锁释放之后才可以继续更新。
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,如下图所示:
对该记录每次更新后,都会将旧值放到一条
undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。ReadView
对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了;
对于使用SERIALIZABLE隔离级别的事务来说,设计InnoDB的大叔规定使用加锁的方式来访问记录(加锁是啥我们后续文章中说哈);
对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,设计InnoDB的大叔提出了一个ReadView的概念,包含4个比较重要的内容:
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。小贴士: 注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。
creator_trx_id:表示生成该ReadView的事务的事务id。小贴士: 我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
有了这个
ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
如果被访问版本的
trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。如果被访问版本的
trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
如果被访问版本的
trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。如果被访问版本的
trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
READ COMMITTED —— 每次读取数据前都生成一个ReadView
REPEATABLE READ —— 在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。
9.7.3 锁
并发访问记录的三种情况:
- 读读:读操作不存在并发问题
- 写写
此种情况会产生脏写问题,任何一种隔离级别都不允许这种问题的发生,需要通过加锁来实现。
当一个事务想对这条记录做改动时,首先会看看内存中有没有与这条记录关联的锁结构,当没有的时候就会在内存中生成一个锁结构与之关联。比方说事务T1要对这条记录做改动,就需要生成一个锁结构与之关联:锁结构中,重要的两个信息是:
trx信息:代表这个锁结构是哪个事务生成的。is_waiting:代表当前事务是否在等待。
在事务T1提交之前,另一个事务T2也想对该记录做改动,那么先去看看有没有锁结构与这条记录关联,发现有一个锁结构与之关联后,然后也生成了一个锁结构与这条记录关联,不过锁结构的is_waiting属性值为true,表示当前事务需要等待,我们把这个场景就称之为获取锁失败。在事务
T1提交之后,就会把该事务生成的锁结构释放掉,然后看看还有没有别的事务在等待获取锁,发现了事务T2还在等待获取锁,所以把事务T2对应的锁结构的is_waiting属性设置为false,然后把该事务对应的线程唤醒,让它继续执行,此时事务T2就算获取到锁了。
读-写:也就是一个事务进行读取操作,另一个进行改动操作。
这种情况下可能发生脏读、不可重复读、幻读的问题。
小贴士: 幻读问题的产生是因为某个事务读了一个范围的记录,之后别的事务在该范围内插入了新记录,该事务再次读取该范围的记录时,可以读到新插入的记录,所以幻读问题准确的说并不是因为读取和写入一条相同记录而产生的,这一点要注意一下。
解决这些问题有两个方案:
方案一:读操作利用多版本并发控制(
MVCC),写操作进行加锁。
所谓的MVCC我们在前一章有过详细的描述,就是通过生成一个ReadView,然后通过ReadView找到符合条件的记录版本(历史版本是由undo日志构建的),其实就像是在生成ReadView的那个时刻做了一次时间静止(就像用相机拍了一个快照),查询语句只能读到在生成ReadView之前已提交事务所做的更改,在生成ReadView之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而写操作肯定针对的是最新版本的记录,读记录的历史版本和改动记录的最新版本本身并不冲突,也就是采用MVCC时,读-写操作并不冲突。
小贴士: 我们说过普通的SELECT语句在READ COMMITTED和REPEATABLE READ隔离级别下会使用到MVCC读取记录。在READ COMMITTED隔离级别下,一个事务在执行过程中每次执行SELECT操作时都会生成一个ReadView,ReadView的存在本身就保证了事务不可以读取到未提交的事务所做的更改,也就是避免了脏读现象;REPEATABLE READ隔离级别下,一个事务在执行过程中只有第一次执行SELECT操作才会生成一个ReadView,之后的SELECT操作都复用这个ReadView,这样也就避免了不可重复读和幻读的问题。方案二:读、写操作都采用
加锁的方式。
如果我们的一些业务场景不允许读取记录的旧版本,而是每次都必须去读取记录的最新版本,比方银行存款的事务。这样在读取记录的时候也就需要对其进行加锁操作,这样也就意味着读操作和写操作也像写-写操作那样排队执行。
小贴士: 我们说脏读的产生是因为当前事务读取了另一个未提交事务写的一条记录,如果另一个事务在写记录的时候就给这条记录加锁,那么当前事务就无法继续读取该记录了,所以也就不会有脏读问题的产生了。不可重复读的产生是因为当前事务先读取一条记录,另外一个事务对该记录做了改动之后并提交之后,当前事务再次读取时会获得不同的值,如果在当前事务读取记录时就给该记录加锁,那么另一个事务就无法修改该记录,自然也不会发生不可重复读了。我们说幻读问题的产生是因为当前事务读取了一个范围的记录,然后另外的事务向该范围内插入了新记录,当前事务再次读取该范围的记录时发现了新插入的新记录,我们把新插入的那些记录称之为幻影记录。采用加锁的方式解决幻读问题就有那么一丢丢麻烦了,因为当前事务在第一次读取记录时那些幻影记录并不存在,所以读取的时候加锁就有点尴尬 —— 因为你并不知道给谁加锁,没关系,这难不倒设计InnoDB的大叔的,我们稍后揭晓答案,稍安勿躁。一致性读(Consistent Reads)
事务利用MVCC进行的读取操作称之为一致性读,或者一致性无锁读,有的地方也称之为快照读。所有普通的SELECT语句(plain SELECT)在READ COMMITTED、REPEATABLE READ隔离级别下都算是一致性读,比方说:SELECT * FROM t; SELECT * FROM t1 INNER JOIN t2 ON t1.col1 = t2.col2一致性读并不会对表中的任何记录做加锁操作,其他事务可以自由的对表中的记录做改动。
锁定读(Locking Reads)
共享锁:Shared Locks,简称S锁。
独占锁:也常称排他锁,英文名:Exclusive Locks,简称X锁。语句加锁:
- 对读取的记录加
S锁:SELECT ... LOCK IN SHARE MODE;会为读取到的记录加
S锁,这样允许别的事务继续获取这些记录的S锁,但是不能获取这些记录的X锁。
- 对读取的记录加
X锁:SELECT ... FOR UPDATE;如果当前事务执行了该语句,那么它会为读取到的记录加
X锁,这样既不允许别的事务获取这些记录的S锁,也不允许获取这些记录的X锁。
DELETE:对一条记录做
DELETE操作的过程其实是先在B+树中定位到这条记录的位置,然后获取一下这条记录的X锁,然后再执行delete mark操作。我们也可以把这个定位待删除记录在B+树中位置的过程看成是一个获取X锁的锁定读。
UPDATE:在对一条记录做
UPDATE操作时分为三种情况:
如果未修改该记录的键值并且被更新的列占用的存储空间在修改前后未发生变化,则先在
B+树中定位到这条记录的位置,然后再获取一下记录的X锁,最后在原记录的位置进行修改操作。其实我们也可以把这个定位待修改记录在B+树中位置的过程看成是一个获取X锁的锁定读。如果未修改该记录的键值并且至少有一个被更新的列占用的存储空间在修改前后发生变化,则先在
B+树中定位到这条记录的位置,然后获取一下记录的X锁,将该记录彻底删除掉(就是把记录彻底移入垃圾链表),最后再插入一条新记录。这个定位待修改记录在B+树中位置的过程看成是一个获取X锁的锁定读,新插入的记录由INSERT操作提供的隐式锁进行保护。如果修改了该记录的键值,则相当于在原记录上做
DELETE操作之后再来一次INSERT操作,加锁操作就需要按照DELETE和INSERT的规则进行了。
INSERT:一般情况下,新插入一条记录的操作并不加锁,设计
InnoDB的大叔通过一种称之为隐式锁的东东来保护这条新插入的记录在本事务提交前不被别的事务访问,更多细节我们后边看哈~多粒度锁
前边提到的锁都是针对记录的,也可以被称之为行级锁或者行锁,除此之外,还有表级锁。表级锁也存在S锁和X锁之分,与行锁类似。
我们在对教学楼整体上锁(表锁)时,怎么知道教学楼中有没有教室已经被上锁(行锁)了呢?依次检查每一间教室门口有没有上锁?那这效率也太慢了吧!遍历是不可能遍历的,这辈子也不可能遍历的,于是乎设计InnoDB的大叔们提出了一种称之为意向锁(英文名:Intention Locks)的东东:
意向共享锁,英文名:Intention Shared Lock,简称IS锁。当事务准备在某条记录上加S锁时,需要先在表级别加一个IS锁。
意向独占锁,英文名:Intention Exclusive Lock,简称IX锁。当事务准备在某条记录上加X锁时,需要先在表级别加一个IX锁。
IS、IX锁是表级锁,它们的提出仅仅为了在之后加表级别的S锁和X锁时可以快速判断表中的记录是否被上锁,以避免用遍历的方式来查看表中有没有上锁的记录,也就是说其实IS锁和IX锁是兼容的,IX锁和IX锁是兼容的。我们画个表来看一下表级别的各种锁的兼容性:
兼容性 XIXSISX不兼容 不兼容 不兼容 不兼容 IX不兼容 兼容 不兼容 兼容 S不兼容 不兼容 兼容 兼容 IS不兼容 兼容 兼容 兼容 其他存储引擎中的锁
对于MyISAM、MEMORY、MERGE这些存储引擎来说,它们只支持表级锁,而且这些引擎并不支持事务,所以使用这些存储引擎的锁一般都是针对当前会话来说的。比方说在Session 1中对一个表执行SELECT操作,就相当于为这个表加了一个表级别的S锁,如果在SELECT操作未完成时,Session 2中对这个表执行UPDATE操作,相当于要获取表的X锁,此操作会被阻塞,直到Session 1中的SELECT操作完成,释放掉表级别的S锁后,Session 2中对这个表执行UPDATE操作才能继续获取X锁,然后执行具体的更新语句。
小贴士: 因为使用MyISAM、MEMORY、MERGE这些存储引擎的表在同一时刻只允许一个会话对表进行写操作,所以这些存储引擎实际上最好用在只读,或者大部分都是读操作,或者单用户的情景下。InnoDB中的表级锁
- 表级别的S锁、X锁
在对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,InnoDB存储引擎是不会为这个表添加表级别的S锁或者X锁的。
另外,在对某个表执行一些诸如ALTER TABLE、DROP TABLE这类的DDL语句时,其他事务对这个表并发执行诸如SELECT、INSERT、DELETE、UPDATE的语句会发生阻塞,同理,某个事务中对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,在其他会话中对这个表执行DDL语句也会发生阻塞。这个过程其实是通过在server层使用一种称之为元数据锁(英文名:Metadata Locks,简称MDL)东东来实现的,一般情况下也不会使用InnoDB存储引擎自己提供的表级别的S锁和X锁。- 表级别的IS锁、IX锁
当我们在对使用InnoDB存储引擎的表的某些记录加S锁之前,那就需要先在表级别加一个IS锁,当我们在对使用InnoDB存储引擎的表的某些记录加X锁之前,那就需要先在表级别加一个IX锁。IS锁和IX锁的使命只是为了后续在加表级别的S锁和X锁时判断表中是否有已经被加锁的记录,以避免用遍历的方式来查看表中有没有上锁的记录。更多关于IS锁和IX锁的解释我们上边都唠叨过了,就不赘述了。- 表级别的AUTO-INC锁
在使用MySQL过程中,我们可以为表的某个列添加AUTO_INCREMENT属性,之后在插入记录时,可以不指定该列的值,系统会自动为它赋上递增的值。InnoDB中的行级锁
- Record Locks:
我们前边提到的记录锁就是这种类型,也就是仅仅把一条记录锁上,我决定给这种类型的锁起一个比较不正经的名字:正经记录锁(请允许我皮一下,我实在不知道该叫个啥名好)。官方的类型名称为:LOCK_REC_NOT_GAP。比方说我们把number值为8的那条记录加一个正经记录锁的示意图如下:
正经记录锁是有S锁和X锁之分的,让我们分别称之为S型正经记录锁和X型正经记录锁吧(听起来有点怪怪的),当一个事务获取了一条记录的S型正经记录锁后,其他事务也可以继续获取该记录的S型正经记录锁,但不可以继续获取X型正经记录锁;当一个事务获取了一条记录的X型正经记录锁后,其他事务既不可以继续获取该记录的S型正经记录锁,也不可以继续获取X型正经记录锁;
Gap Locks:
我们说MySQL在REPEATABLE READ隔离级别下是可以解决幻读问题的,解决方案有两种,可以使用MVCC方案解决,也可以采用加锁方案解决。但是在使用加锁方案解决时有个大问题,就是事务在第一次执行读取操作时,那些幻影记录尚不存在,我们无法给这些幻影记录加上正经记录锁。不过这难不倒设计InnoDB的大叔,他们提出了一种称之为Gap Locks的锁,官方的类型名称为:LOCK_GAP,我们也可以简称为gap锁。比方说我们把number值为8的那条记录加一个gap锁的示意图如下:
如图中为
number值为8的记录加了gap锁,意味着不允许别的事务在number值为8的记录前边的间隙插入新记录,其实就是number列的值(3, 8)这个区间的新记录是不允许立即插入的。比方说有另外一个事务再想插入一条number值为4的新记录,它定位到该条新记录的下一条记录的number值为8,而这条记录上又有一个gap锁,所以就会阻塞插入操作,直到拥有这个gap锁的事务提交了之后,number列的值在区间(3, 8)中的新记录才可以被插入。
这个gap锁的提出仅仅是为了防止插入幻影记录而提出的,虽然有共享gap锁和独占gap锁这样的说法,但是它们起到的作用都是相同的。而且如果你对一条记录加了gap锁(不论是共享gap锁还是独占gap锁),并不会限制其他事务对这条记录加正经记录锁或者继续加gap锁,再强调一遍,gap锁的作用仅仅是为了防止插入幻影记录的而已。
为了实现阻止其他事务插入number值在(20, +∞)这个区间的新记录,我们可以给索引中的最后一条记录,也就是number值为20的那条记录所在页面的Supremum记录加上一个gap锁。
Next-Key Locks:
有时候我们既想锁住某条记录,又想阻止其他事务在该记录前边的间隙插入新记录,所以设计InnoDB的大叔们就提出了一种称之为Next-Key Locks的锁,官方的类型名称为:LOCK_ORDINARY,我们也可以简称为next-key锁。next-key锁的本质就是一个正经记录锁和一个gap锁的合体,它既能保护该条记录,又能阻止别的事务将新记录插入被保护记录前边的间隙。
Insert Intention Locks:
我们说一个事务在插入一条记录时需要判断一下插入位置是不是被别的事务加了所谓的gap锁(next-key锁也包含gap锁,后边就不强调了),如果有的话,插入操作需要等待,直到拥有gap锁的那个事务提交。但是设计InnoDB的大叔规定事务在等待的时候也需要在内存中生成一个锁结构,表明有事务想在某个间隙中插入新记录,但是现在在等待。设计InnoDB的大叔就把这种类型的锁命名为Insert Intention Locks,官方的类型名称为:LOCK_INSERT_INTENTION,我们也可以称为插入意向锁。隐式锁
我们前边说一个事务在执行INSERT操作时,如果即将插入的间隙已经被其他事务加了gap锁,那么本次INSERT操作会阻塞,并且当前事务会在该间隙上加一个插入意向锁,否则一般情况下INSERT操作是不加锁的。


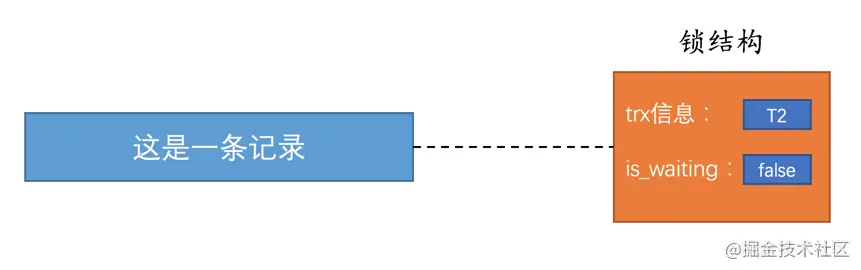
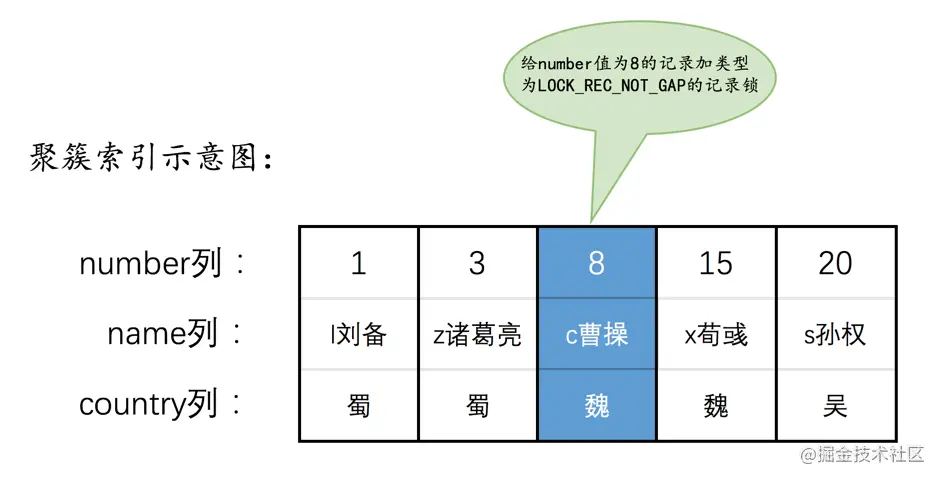
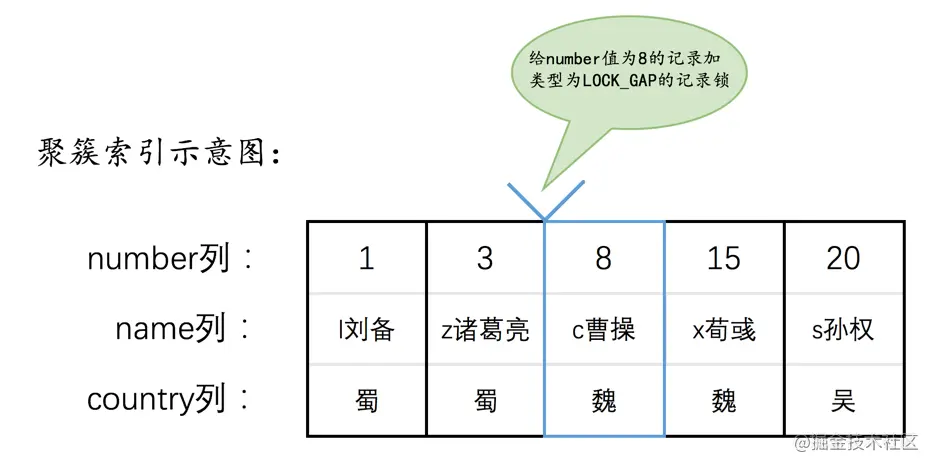
9.8 日志
9.8.1 redo日志
InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。我们前边唠叨Buffer Pool的时候说过,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。持久性:对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失。
一个很简单的做法就是在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘,但是这个简单粗暴的做法有些问题:
刷新一个完整的数据页太浪费了
有时候我们仅仅修改了某个页面中的一个字节,但是我们知道在
InnoDB中是以页为单位来进行磁盘IO的,也就是说我们在该事务提交时不得不将一个完整的页面从内存中刷新到磁盘,我们又知道一个页面默认是16KB大小,只修改一个字节就要刷新16KB的数据到磁盘上显然是太浪费了。随机IO刷起来比较慢
一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,倒霉催的是该事务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的
Buffer Pool中的页面刷新到磁盘时,需要进行很多的随机IO,随机IO比顺序IO要慢,尤其对于传统的机械硬盘来说。
redo日志本质上只是记录了一下事务对数据库做了哪些修改,将事务执行过程中产生的redo日志刷新到磁盘的好处如下:
redo日志占用的空间非常小
redo日志是顺序写入磁盘的在执行事务的过程中,每执行一条语句,就可能产生若干条
redo日志,这些日志是按照产生的顺序写入磁盘的,也就是使用顺序IO。redo日志格式
type:该条redo日志的类型。space ID:表空间ID。page number:页号。
data:该条redo日志的具体内容。MySQL 持久化保障机制-redo 日志_平头哥的技术博文-CSDN博客_mysql持久化
优势
在事务提交时将所有修改过的内存中的页面刷新到磁盘中相比,只将该事务执行过程中产生的 redo 日志刷新到磁盘的好处如下:
redo日志占用的空间非常小:存储表空间ID、页号、偏移量以及需要更新的值所需的存储空间是很小的。
redo日志是顺序写入磁盘的:在执行事务的过程中,每执行一条语句,就可能产生若干条redo日志,这些日志是按照产生的顺序写入磁盘的,也就是使用顺序IO。工作原理
redo 日志是循环写入的,因为 InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示:write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。redo日志缓冲区
redo 日志并不是直接写入磁盘的,而是先写入到缓存区,我们把这个缓冲区叫做 redo日志缓冲区。在服务器启动时就向操作系统申请了一大片称之为 redo log buffer 的连续内存空间,我们也可以简称为log buffer。这片内存空间被划分成若干个连续的 redo log block,如下图所示:向 log buffer 中写入 redo 日志的过程是顺序的,也就是先往前边的 block中写,当该 block 的空闲空间用完之后再往下一个 block 中写。
先写入缓冲区再写磁盘,就会碰到一个问题,这个问题在 redis AOF 持久化方式时也遇到过,就是缓冲区和磁盘之间的数据如何同步?
在 MySQL 的配置文件中提供了 innodb_flush_log_at_trx_commit 参数,这个可以用来控制缓冲区和磁盘之间的数据如何同步,这里有 0、1、2 三个选项,在我装的 MySQL 下默认的是 1,简单介绍一下这三个选项的区别:
0:表示当提交事务时,并不将缓冲区的 redo 日志写入磁盘的日志文件,而是等待主线程每秒刷新。
1:在事务提交时将缓冲区的 redo 日志同步写入到磁盘,保证一定会写入成功。
2:在事务提交时将缓冲区的 redo 日志异步写入到磁盘,即不能完全保证 commit 时肯定会写入 redo 日志文件,只是有这个动作。
我们使用默认值 1 就好,这样可以保证 MySQL 异常重启之后数据不丢失。
总结一下 redo 日志是 InnoDB 引擎特有的,有了 redo 日志 之后,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失。保证了事务的持久性。

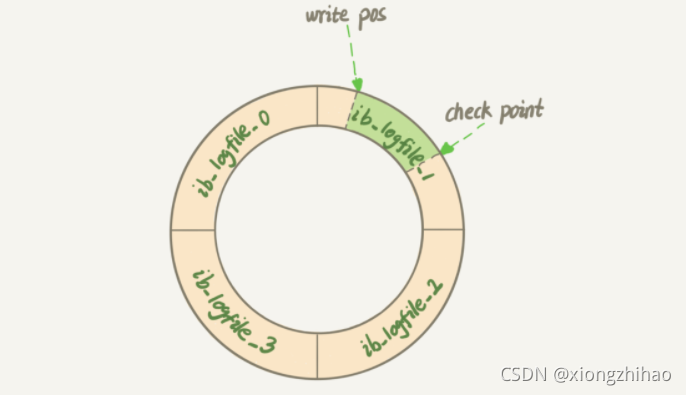
9.8.2 undo日志
MySQL中的三种日志的特点和作用介绍_test的博客-CSDN博客_mysql三种日志
保证了事务的一致性????
事务执行过程如果异常中断,为了保证事务的原子性,我们需要把东西改回原先的样子,这个过程就称之为
回滚(英文名:rollback),同时也提供了多版本并发控制下的读(MVCC),也即非锁定读。
为了实现事务的原子性,InnoDB存储引擎在实际进行增、删、改一条记录时,都需要先把对应的undo日志记下来。一般每对一条记录做一次改动,就对应着一条undo日志,但在某些更新记录的操作中,也可能会对应着2条undo日志,这个我们后边会仔细唠叨。一个事务在执行过程中可能新增、删除、更新若干条记录,也就是说需要记录很多条对应的undo日志,这些undo日志会被从0开始编号,也就是说根据生成的顺序分别被称为第0号undo日志、第1号undo日志、...、第n号undo日志等,这个编号也被称之为undo no。
9.8.3 bin log
9.9 主从复制,分库分表
小结:
使用limit要注意,下图两个查询语句结果一样,但效果差别很大,第一个查询用了15s,第二个查询0.38s。这是因为val是二级索引,查询到后需要回表,如果不进行处理直接回表会进行30005次回表查询,因为回表查记录是随机I/O,二级索引查记录是顺序I/O,所以先在二级索引的查询中找出目标ID,在进行回表查询。
select * from a where val = 1 limit 30000, 5
select * from a inner join (select id from a where val = 1 limit 30000,5) b on a.id=b.id十、分布式
10.1.1 CAP
10.1.2 一致性hash
10.1.3 分布式锁
十一、Spring Security
11.1.1 Cors、Csrf
11.1.2 security
SpringBoot集成Spring Security(1)——入门程序_Jitwxs-CSDN博客_springboot集成springsecurity
springboot+security实现权限管理_zhaoxichen_10的博客-CSDN博客_springboot权限管理
SpringBoot集成Spring Security(7)——认证流程_Jitwxs-CSDN博客_springsecurity认证流程
Spring-Security登录认证授权原理_abcwanglinyong的博客-CSDN博客_springsecurity如何判断是否已认证
所有提交给AuthenticationManager的认证请求都会被封装成一个Token的实现,比如最容易理解的UsernamePasswordAuthenticationToken。
Spring Security中会提交一个token给AuthenticationManager(用户认证的管理类)的authenticate()方法来进行验证。ProviderManager是AuthenticationManager的一个默认实现,但它并不用来处理身份认证,而是委托给配置好的AuthenticationProvider,
AuthenticationProvider是认证的具体实现类。比如提交的用户名密码我是通过和DB中查出的user记录做比对实现的,那就有一个DaoProvider;如果我是通过CAS请求单点登录系统实现,那就有一个CASProvider。按照Spring一贯的作风,主流的认证方式它都已经提供了默认实现,比如DAO、LDAP、CAS、OAuth2等。每个provider通过实现一个support方法来表示自己支持那种Token的认证。
用户认证通过Provider来做,所以Provider需要拿到系统已经保存的认证信息,获取用户信息的接口spring-security抽象成UserDetailService。
当用户通过认证之后,就会为这个用户生成一个唯一的SecurityContext,里面包含用户的认证信息Authentication(在认证时,如果认证成功,用户的权限也将被返回到authentication中)。通过SecurityContext我们可以获取到用户的标识Principle和授权信息GrantedAuthrity。在系统的任何地方只要通过SecurityHolder.getSecruityContext()就可以获取到SecurityContext。
自定义拦截器,实现对访问地址的拦截、禁止csrf(跨域访问)、认证成功跳转等逻辑。(权限管理可以在此配置类中做,如果需要更细粒度的权限管理,也可以在弃用security注解,注释掉配置类中的地址拦截,再在每个方法前添加@PreAuthorize("hasRole('ADMIN')") )
11.1.3 security JWT
11.1.4 SSO
十二、面试
幂等性
i++的线程安全性
并发的两个工具类
lxt:
设计原则:java开发六大基本原则_rainjm的博客-CSDN博客_开发原则
设计模式:自己项目中的具体设计模式应用场景
代码重构:tbjk:
i++:java 线程安全性_i++是线程安全的吗?如何解决线程安全性?_悦舟的博客-CSDN博客
AtomicInteger (计数器)的用法 - 简书
juc包下的工具类:Java并发工具类详解:CountDownLatch、CyclicBarrier、Semaphore和Exchanger_凡是过往,皆为序章-CSDN博客
幂等性:java实现接口幂等_java接口的幂等性_weixin_39843338的博客-CSDN博客
java幂等性的解决方案 - jason.bai - 博客园
kafka:bank:
final:深入理解final关键字以及一些建议 - 陈先生丶 - 博客园lm:
注解生效:Spring注解是如何生效的? - 走看看
Mybatis:Java面试题 (4) Mybatis中一级缓存 和 二级缓存的区别?_不负年华-CSDN博客_mybatis一级缓存和二级缓存面试
Mybatis的一级缓存和二级缓存的理解以及用法 - 全me村的希望 - 博客园hs:
什么情况会引起内存泄漏
springboot:Spring Boot 完整讲解_可乐的博客-CSDN博客_springboot详解
以上内容总结自网络,大部分均已注明出处。部分内容太琐碎,来源太多,全附上链接影响阅读。如有侵权,请告知,立即删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









