







以当当网为例:
代码:
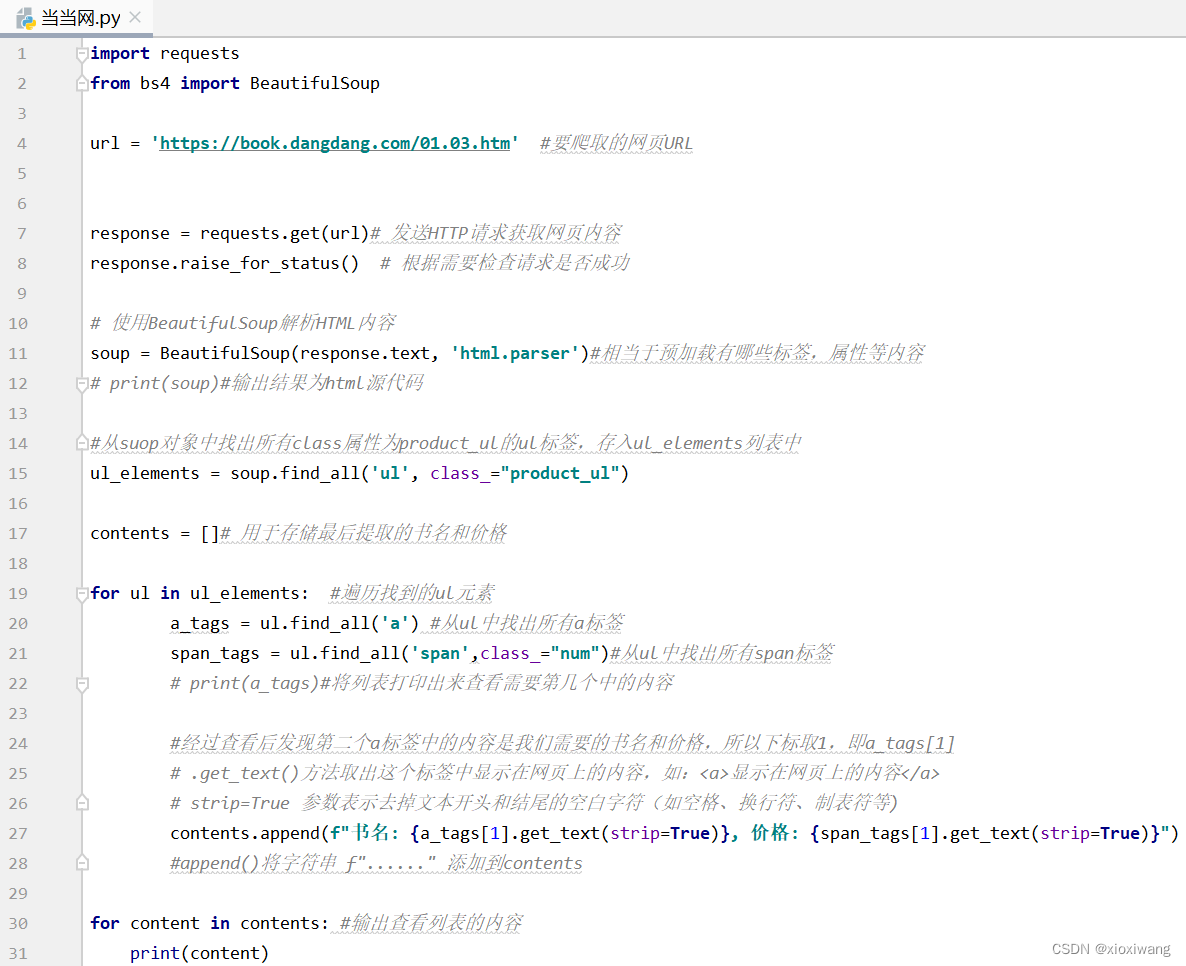
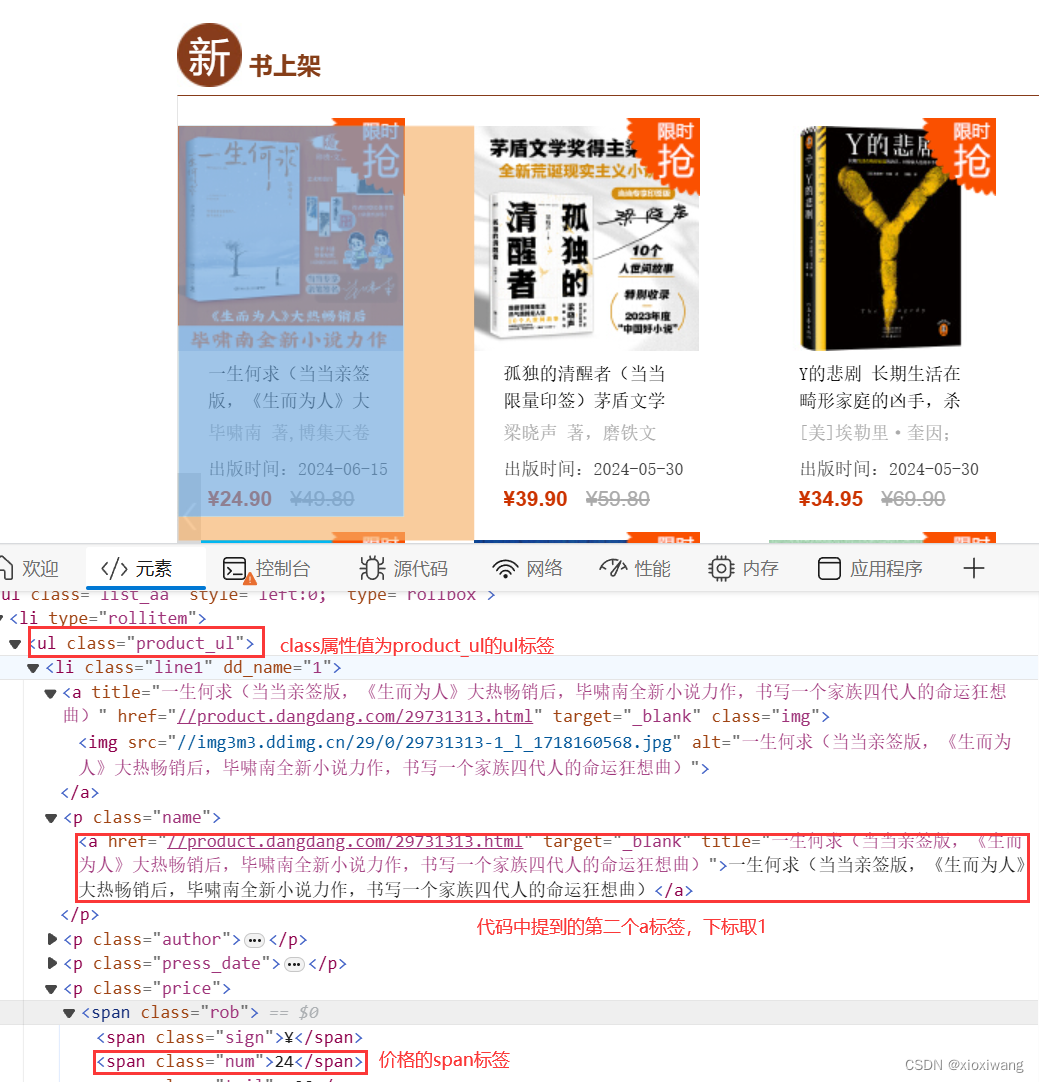
需要修改第一张图片中的第4行的url链接,第15行及后面查找标签的方式
import requests
from bs4 import BeautifulSoup
url = 'https://book.dangdang.com/01.03.htm' #要爬取的网页URL
response = requests.get(url)# 发送HTTP请求获取网页内容
response.raise_for_status() # 根据需要检查请求是否成功
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')#相当于预加载有哪些标签,属性等内容
# print(soup)#输出结果为html源代码
#从suop对象中找出所有class属性为product_ul的ul标签,存入ul_elements列表中
ul_elements = soup.find_all('ul', class_="product_ul")
contents = []# 用于存储最后提取的书名和价格
for ul in ul_elements: #遍历找到的ul元素
a_tags = ul.find_all('a') #从ul中找出所有a标签
span_tags = ul.find_all('span',class_="num")#从ul中找出所有span标签
# print(a_tags)#将列表打印出来查看需要第几个中的内容
#经过查看后发现第二个a标签中的内容是我们需要的书名和价格,所以下标取1,即a_tags[1]
# .get_text()方法取出这个标签中显示在网页上的内容,如:<a>显示在网页上的内容</a>
# strip=True 参数表示去掉文本开头和结尾的空白字符(如空格、换行符、制表符等)
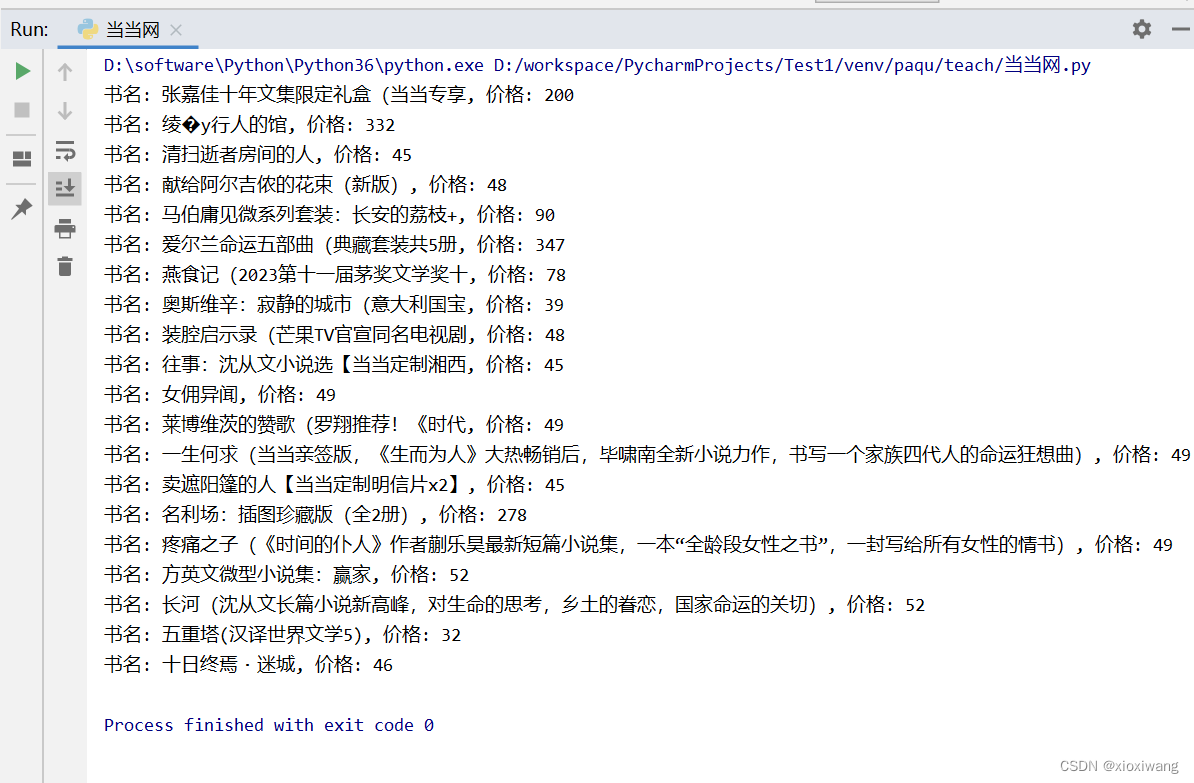
contents.append(f"书名: {a_tags[1].get_text(strip=True)}, 价格: {span_tags[1].get_text(strip=True)}")
#append()将字符串 f"......" 添加到contents
for content in contents: #输出查看列表的内容
print(content)
需要绘制图标或存入表格的也可以加入QQ群讨论:666347476
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









