- 正文前感谢昇腾各位工作人员,没有你们的辛勤就没有我们的进步
- 本文立意交流大赛LpNormV2算子编译过程
- 这个算子知识含量太高了,细节太多。简直做的我脑壳疼,还好最后做出来
- 数次想要放弃,毫不客气的讲,这题绝对的心机绿茶
- 初看美景如画,细品皆是险峰,出这道题的老师真是牛,考察知识点满满

- 这么看,公式分类很多,也很复杂,其实就是torch.norm函数
- 公式可以削减为以下,很简单是吧。我一开始就是这么想的,结果被虐的自备好久
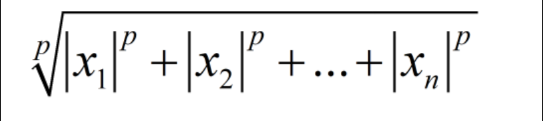
- 测试案例只测5个案例,4个P选项
- 但是我做了6个案例,6个P选项案例
- 做完这道题,总结有以下几个难点
- Attr有很多变量,其中有一个变量在aclnn里面需要做比较复杂修改
- 在AscendC文档里面找了很久list_int调用方式,不好找,而且Attr里面总共有多少类型,该怎么声明,也暂时没找到对应案例
- 最后在本源算子aclnnNorm中找到了调用方式
- https://www.hiascend.com/document/detail/zh/canncommercial/80RC1/apiref/appdevgapi/context/aclnnNorm.md
"attr": [
{
"name": "p",
"param_type": "required",
"type": "float",
"default_value": 2.0
},
{
"name": "axes",
"param_type": "required",
"type": "list_int"
},
{
"name": "keepdim",
"param_type": "required",
"type": "bool",
"default_value": "FALSE"
},
{
"name": "epsilon",
"param_type": "required",
"type": "float",
"default_value": 1e-12
}
]复制
- list_int调用如下,当然float 类型 我看标准案例应用用的是aclScalar类型,
- 可能需要在json设置类型为aclScalar对应类型,找不到相应文档
- 这里如果改成aclScalar会更好
aclOpExecutor *handle = nullptr;
aclIntArray* axes = nullptr;
std::vector<int64_t> axesData = {0};
axes = aclCreateIntArray(axesData.data(), 1);
CHECK_RET(axes != nullptr,return false);
float pValue = -1.0/0.0;
auto ret = aclnnLpNormV2GetWorkspaceSize(inputTensor_[0],pValue,axes,true,1e-12,outputTensor_[0],
&workspaceSize, &handle);复制
- 第二个难点,在于计算公式里面要求求最大,最小,求和
- 求最大最小,按照我原先的想法,最大,最小,那么只能把所有数据集合一起,以一大块进行求解方便
- 可是看案例[3, 4, 224, 224],就会发现当数据量变大时候,会造成UB不够用,严重超出设计,会爆507015错误
- 所以这里细想进行两层设计,多次计算,就是多次求最大最小求和,来削减数据硬性要求
- 这里以this->tileNum * BUFFER_NUM作为第二层数据归元数量,这里BUFFER_NUM为1
__aicore__ inline void Process() {
int32_t loopCount = this->tileNum * BUFFER_NUM ;//最后一次进行归元处理
this->copyLength = 0;
for (int32_t i = 0; i < loopCount; i++)
{
CopyIn(i);
Compute(i);//最后一次进行归元处理
}
Compute_final();
CopyOut();
}复制
- 要想完成这样的设计,tiling切分就很重要
- 这里沿用了sample仓中的ub分块设计,因为310B只有一个ai_core,所以GetBlockIdx只为1
- copyin也与sample仓中ub设计一致,分块tilenum.每一块长度 tileLength,最后一块大小lasttileLength
- 但是这里要提醒一点,就是ub设计中是有做对齐处理的,所以最后一块数据是包含了对齐可能补齐的数据的
- 在数据具体调用过程中要注意这个对齐数据占用空间
__aicore__ inline void CopyIn(int32_t progress) {
LocalTensor<DTYPE_X> inLocal = inQueueIN.AllocTensor<DTYPE_X>();
if (BUFFER_NUM == 1) {
if (progress == this->tileNum - 1) {
if (progress == 0) {
//如果只有一包,则搬运的起始地址为0,tileLength为实际分块的数据量
DataCopy(inLocal[0], xGm[0], this->tileLength);
} else {
//将最后一个分块的起始地址向前移动tileLength-lasttileLength
DataCopy(
inLocal[0],
xGm[(progress - 1) * this->tileLength + this->lasttileLength],
this->tileLength);
}
} else {
DataCopy(inLocal[0], xGm[progress * this->tileLength],
this->tileLength);
}
}复制
- 第三个难点,其实是两个注意点
- datacopy的数据count一定要以32Bytes对齐,否则虽然系统没报错,经过TPipe,初始化TQue,Tbuf, initbuffer出来的空间使用都会出现数据错误问题
- 使用initbuffer分配的空间可不是memset过的,数据可能是随机值,直接进行mul 等计算会出大问题
pipe.InitBuffer(inQueueIN, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X));
pipe.InitBuffer(outQueueOUT, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y));
this->calcQueueAlign = ((this->tileNum * sizeof(DTYPE_Y)-1)/32 + 1)*32 ;
pipe.InitBuffer(calcQueue,BUFFER_NUM, this->calcQueueAlign);
pipe.InitBuffer(calcBuf1, this->tileLength *BUFFER_NUM* sizeof(DTYPE_X));//this->totalLength
uint32_t calcBufAlign2 = ((this->finalWorkLocalNeedSize* sizeof(DTYPE_X) -1)/ 32 + 1)*32;
pipe.InitBuffer(calcBuf2, calcBufAlign2);
if(this->p == 0)
{
uint32_t calcBufAlign3 = ((this->tileLength *BUFFER_NUM /8* sizeof(uint8_t) -1)/ 32 + 1)*32;
pipe.InitBuffer(calcBuf3, calcBufAlign3);
}
uint32_t calcBufAlign4 = ((this->tileLength *BUFFER_NUM /8* sizeof(uint8_t) -1)/ 32 + 1)*32;
pipe.InitBuffer(calcBuf4, calcBufAlign4);复制
Muls(tempTensor1,tempTensor1,static_cast<DTYPE_X>(0),this->tileLength);复制
- 第四个难点,如何进行数据的归元,这里用到了一个 TQue<QuePosition::VECCALC, BUFFER_NUM> calcQueue;
- 在compute里面进行入队,出队,修改数据,再入队操作,直到最后一个数据完成入队
- 最后在compute_final中数据出队,再 calcQueue.FreeTensor(calcLocal);
- 下面就贴出compute里面的一个小思路,注意AllocTensor只能注册一次,后面只用入队出队操作就好
- 求Max ,Min就用ReduceMin.ReduceMax就好,不贴了
if(progress == 0)
{
if(this->p == 2)
{
LocalTensor<DTYPE_Y> calcLocal = calcQueue.AllocTensor<DTYPE_Y>();//tilenum*BUFFER_NUM
Muls(calcLocal,calcLocal,static_cast<DTYPE_X>(0),this->calcQueueAlign);
Abs(tempTensor1, xLocal, this->tileLength);
Mul(tempTensor1, tempTensor1, tempTensor1, this->tileLength);
ReduceSum<DTYPE_X>(tempTensor1, tempTensor1, tempTensor2, this->tileLength);
calcLocal.SetValue(progress,tempTensor1.GetValue(0));
calcQueue.EnQue<DTYPE_Y>(calcLocal);
}
}
else if((progress == (this->tileNum * BUFFER_NUM - 1))&&(this->tileLength != this->lasttileLength))
{
if(this->p == 2)
{
LocalTensor<DTYPE_Y> calcLocal = calcQueue.DeQue<DTYPE_Y>();//tilenum*BUFFER_NUM
}
}
else
{
} 复制
- 第五个难点在于[3, 4, 5 , 7]如果有lasttileLength怎么办,如何处理数据,这个还需要考虑前面说的对齐数据
- 在求MIN的时候,因为部分数据是0,可能会被求成最小值,直接将最后一个lasttileLength重叠部分数据置为inf
- 这样就可以顺利求解出MIN值
else if(this->p == this->neginf)
{
LocalTensor<DTYPE_Y> calcLocal = calcQueue.DeQue<DTYPE_Y>();//tilenum*BUFFER_NUM
xxxxxxxxx
for(int32_t i = 0 ;i < (this->tileLength - this->lasttileLength- this->LengthAlignedDt);i++)
{
tempTensor1.SetValue(i,static_cast<DTYPE_X>(this->posinf));
}
ReduceMin<DTYPE_X>(tempTensor1, tempTensor1, tempTensor2, (this->tileLength - this->LengthAlignedDt),false);
xxxxxxxx
}复制
- 第六个难点在于p other int or float 选项
- 坑的是虽然文档里面有Power求多次方的API,但是不支持200 DK A2
- 所以求多次方可通过Mul来完成,求多次根号只能用近似算法
- [(99+ 封私信 / 82 条消息) 开 2 次方可以手算,但开 n(n>2,n∈Z) 次方有手算的方法吗? - 知乎 (zhihu.com)](https://www.zhihu.com/question/23750565)

ReduceSum<DTYPE_Y>(outLocal, calcLocal, tempTensor4, this->tileNum * BUFFER_NUM);
Ln(outLocal, outLocal, this->tileLength);
Muls(outLocal,outLocal,static_cast<DTYPE_Y>(this->p_inv),this->tileLength);
Exp(outLocal, outLocal, this->tileLength); 复制
- 还有很多细节注意点,只有自己手揉代码才能感受出来,还是希望大家自己动手试试
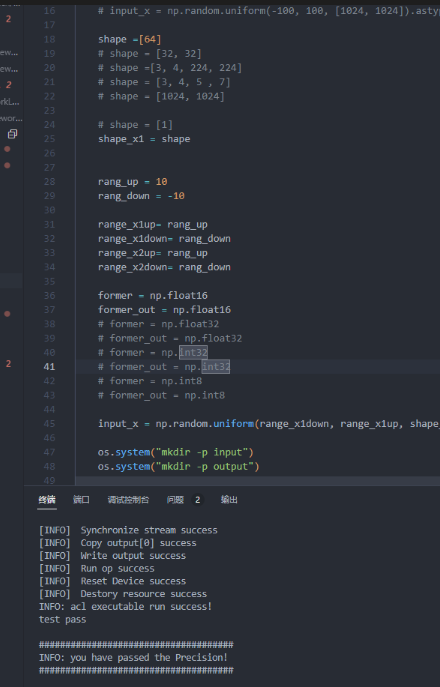
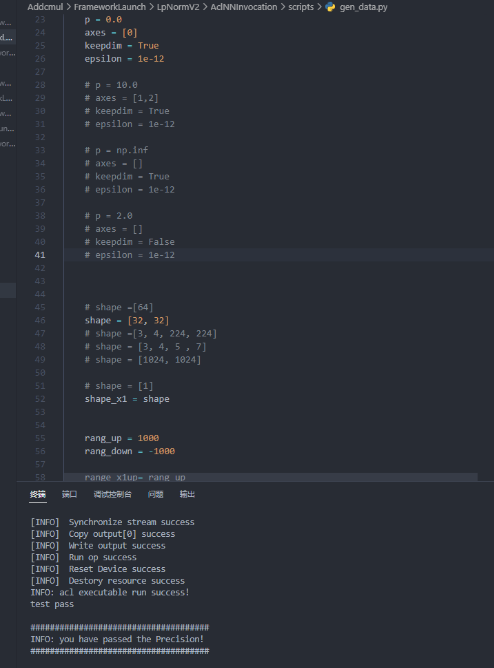
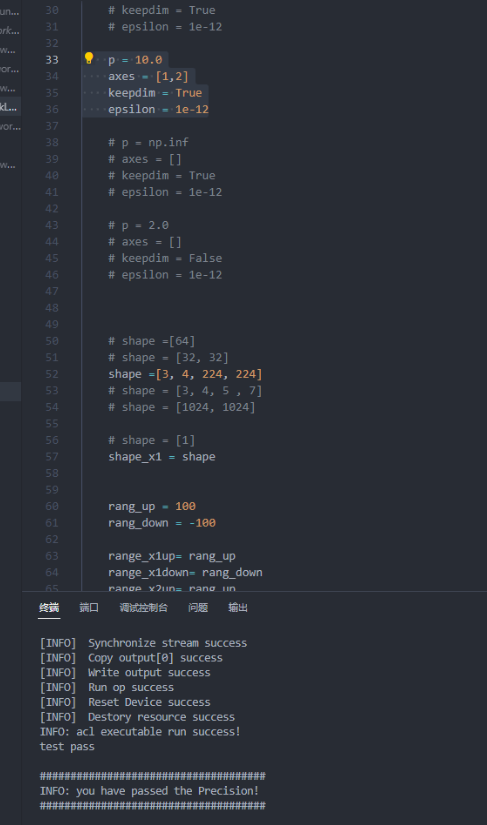
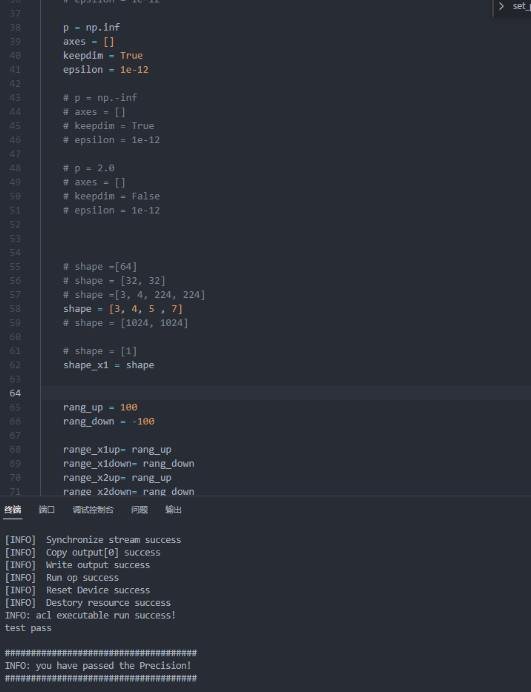
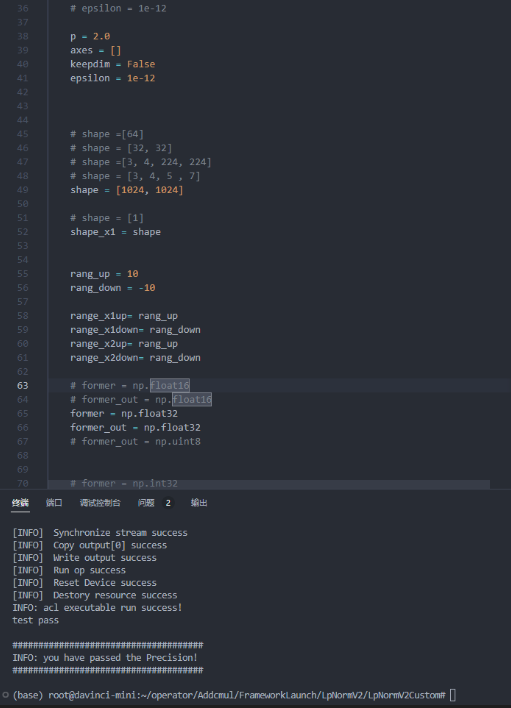
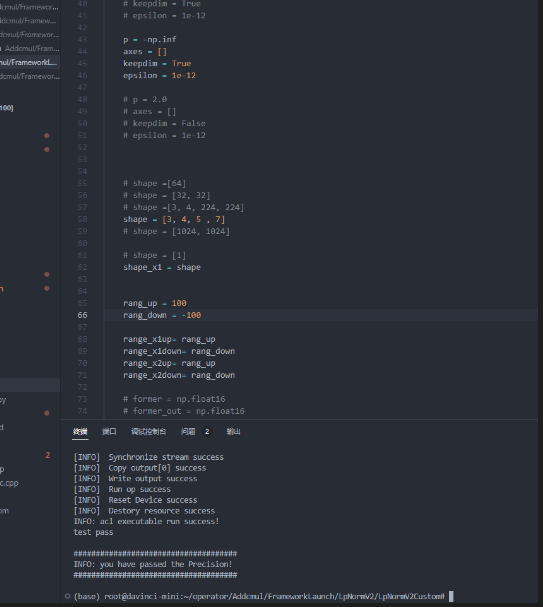
- 最后贴出测试案例图
- 第一个测试案例






















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









