







KubeEdge简介
KubeEdge是面向边缘计算场景、专为边云协同设计的业界首个云原生边缘计算框架,在 Kubernetes 原生的容器编排调度能力之上实现了边云之间的应用协同、资源协同、数据协同和设备协同等能力,完整打通了边缘计算中云、边、设备协同的场景。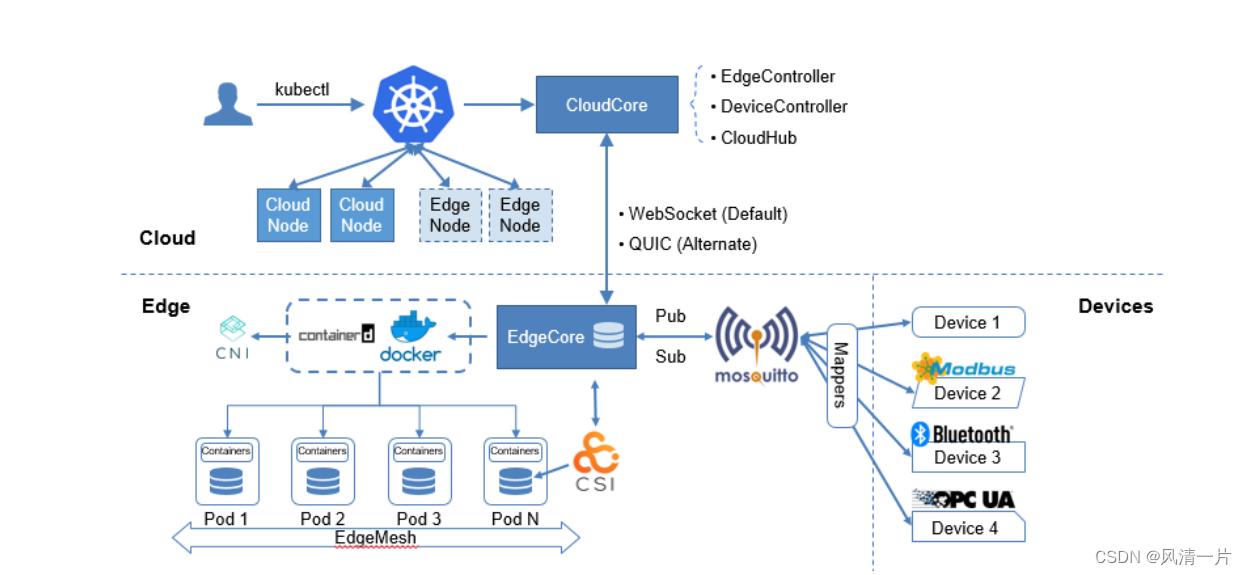
KubeEdge架构主要包含云边端三部分,云上是统一的控制面,包含原生的Kubernetes管理组件,以及KubeEdge自研的CloudCore组件,负责监听云端资源的变化,提供可靠和高效的云边消息同步。边侧主要是EdgeCore组件,包含Edged、MetaManager、EdgeHub等模块,通过接收云端的消息,负责容器的生命周期管理。端侧主要是device mapper和eventBus,负责端侧设备的接入。
kubeedge-arch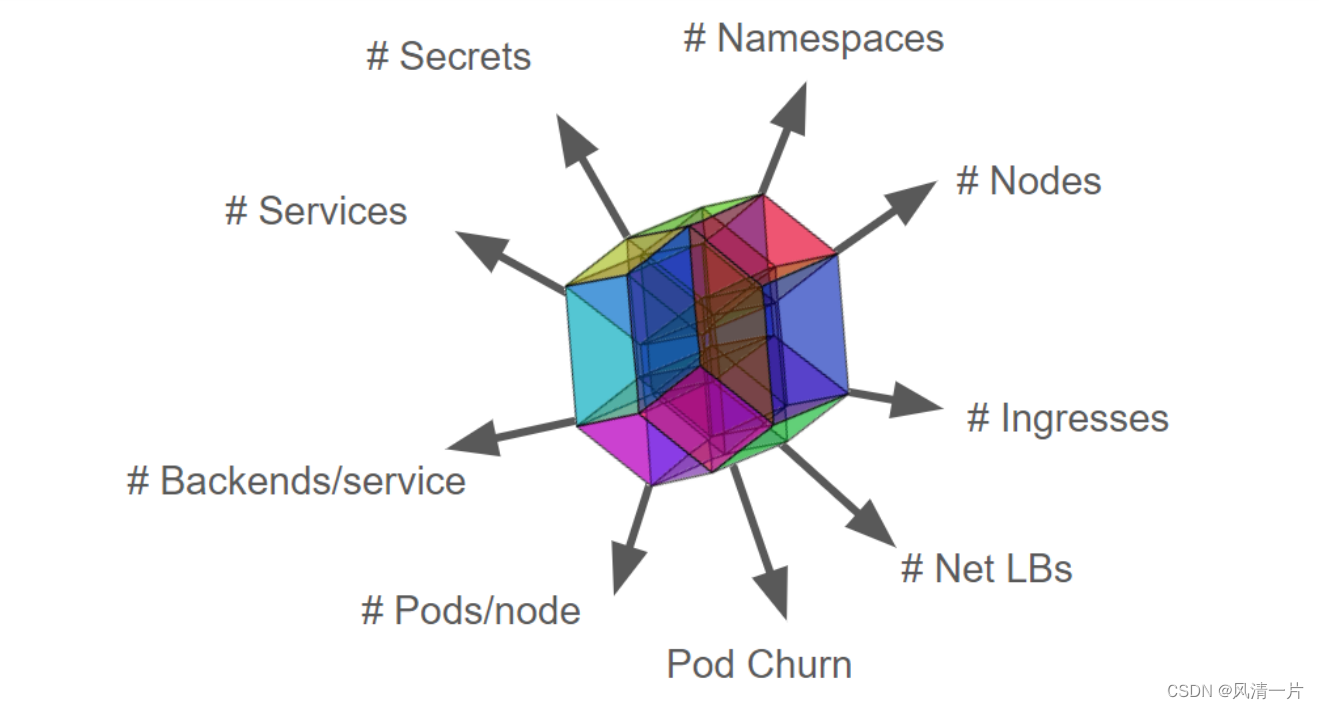
KubeEdge以Kubernetes管控面作为底座,通过将节点拉远的方式,扩展了边云之间的应用协同、资源协同、数据协同和设备协同等能力。 目前,Kubernetes社区官方支持的规模是5,000 个节点和150,000 个Pod,在边缘计算的场景,随着万物互联时代的到来,这种规模是远远不够的。大规模边缘设备的接入,对边缘计算平台的可扩展性和集中管理的需求将会增加,如何使用尽可能少的云端资源和集群,管理尽可能多的边缘设备,简化基础设施的管理和运维。KubeEdge在全面兼容Kubernetes原生能力的基础上,对云边消息通道和传输机制进行了优化,突破了原生Kubernetes的管理规模,支撑更大规模的边缘节点接入和管理。
SLIs/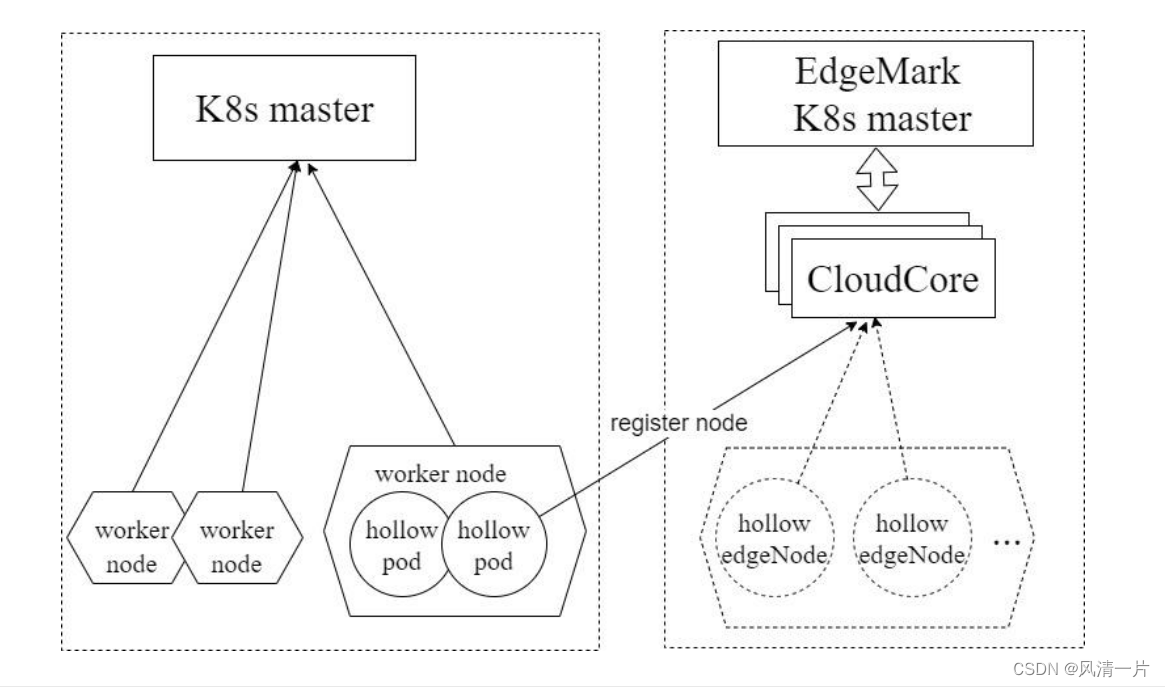
可扩展性和性能是Kubernetes集群的重要特性,作为K8s集群的用户,期望在以上两方面有服务质量的保证。在进行Kubernetes + KubeEdge大规模性能测试前,我们需要定义如何衡量集群大规模场景下服务指标。Kubernetes社区定义了以下几种SLIs(Service Level Indicator)/SLOs(service-level objective)指标项,我们将使用这些指标来衡量集群服务质量。
API Call Latency
Status SLI SLO
Official 最近5min的单个Object Mutating API P99 时延 除聚合API和CRD外,P99 <= 1s
Official 最近5min的non-streaming read-only P99 API时延 除聚合API和CRD外 Scope=resource, P99 <= 1s Scope=namespace, P99 <= 5s Scope=cluster, P99 <= 30s
Pod Startup Latency
Status SLI SLO
Official 无状态Pod启动时间(不包含拉取镜像和Init Container),从pod createTimestamp到所有container都上报启动,并被watch观察到的P99时间 P99 <= 5s
WIP 有状态Pod启动时间(不包含拉取镜像和Init Container),从pod createTimestamp到所有container都上报启动,并被watch观察到的P99时间 TBD
社区还定义了In-Cluster Network Programming Latency(Service更新或者其Ready Pod变化最终反映到Iptables/IPVS规则的时延),In-cluster network latency,DNS Programming Latency( Service更新或者其Ready Pod 反映到dns server的时延), DNS Latency等指标,这些指标当前还尚未量化。满足所有SLO 为大规模集群测试的目标,因此本报告主要针对Official状态SLIs/SLOs进行测试。
Kubernetes 可伸缩性维度和阈值
Kubernetes的可伸缩特性不单指节点规模,即Scalability != #nodes,实际上Kubernetes可伸缩性包含很多维度的测量标准,包含namespaces的数量,Pod的数量,service的数量,secrets/configmap的数量等。下图是Kubernetes社区定义的描述集群可扩展性的重要维度(尚在持续更新中):
k8s-scalability
Kubernetes集群无限制扩展资源对象而且又满足SLIs/SLOs各项指标显然是不可能实现的,为此业界定义了Kubernetes多个维度资源上限。
- Pods/node 30
- Backends <= 50k & Services <= 10k & Backends/service <= 250
- Pod churn 20/s
- Secret & configmap/node 30
- Namespaces <= 10k & Pods <= 150k & Pods/namespace <= 3k
- ……
各个维度不是完全独立的,某个维度被拉伸相应的其他维度就要被压缩,可以根据使用场景进行调整。例如5k node 拉伸到10k node 其他维度的规格势必会受到影响。如果各种场景都进行测试分析工作量是非常巨大的,在本次测试中,我们会重点选取典型场景配置进行测试分析。在满足SLIs/SLOs的基础上,实现单集群支持100k边缘节点,1000k pod规模管理。
测试工具
ClusterLoader2
ClusterLoader2是一款开源Kubernetes集群负载测试工具,该工具能够针对Kubernetes 定义的SLIs/SLOs 指标进行测试,检验集群是否符合各项服务质量标准。此外Clusterloader2为集群问题定位和集群性能优化提供可视化数据。ClusterLoader2 最终会输出一份Kubernetes集群性能报告,展示一系列性能指标测试结果。
Clusterloader2性能指标:
APIResponsivenessPrometheusSimple
APIResponsivenessPrometheus
CPUProfile
EtcdMetrics
MemoryProfile
MetricsForE2E
PodStartupLatency
ResourceUsageSummary
SchedulingMetrics
SchedulingThroughput
WaitForControlledPodsRunning
WaitForRunningPods
Edgemark
Edgemark是类似于Kubemark的性能测试工具, 主要用于KubeEdge集群可扩展性测试中,用来模拟KubeEdge边缘节点,在有限资源的情况下构建超大规模Kubernetes+KubeEdge集群,目标是暴露只有在大规模集群情况下才会出现的集群管理面问题。Edgemark部署方式如下图:
edgemark-deploy
k8s master — Kubernetes物理集群主节点
edgemark master — Kubernetes模拟集群主节点
CloudCore — KubeEdge云端管理组件,负责边缘节点的接入
hollow pod — 在物理集群上启动的pod,通过在pod内启动edgemark向edgemark master注册成为一台虚拟边缘节点,edgemark master可以向该虚拟边缘节点上调度pod
hollow edgeNode — 模拟集群中可见的节点,为虚拟节点,由hollow pod注册获得
测试集群部署方案
deploy
Kubernetes底座管理面采用单master进行部署,ETCD、Kube-apiserver、Kube-Scheduler、Kube-Controller均为单实例部署,KubeEdge管理面CloudCore采用5实例部署,通过master节点IP连接Kube-apiserver,南向通过Load Balancer对外暴漏服务,边缘节点通过Load Balancer轮询策略随机连接到某一个CloudCore实例。
















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











