






目录
第一章 Spark框架概述
1 初识Spark
1.1简介
什么是spark:
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。Spark基于内存的计算引擎,加州伯克利大学教授发表论文,基于论文进行开发的。RDD弹性分布式数据集,是spark的核心
RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。
spark的思想:
分而治之的思想,把大的任务拆分成若干个小任务,解决后再进行合并,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度
Spark架构:
1)数据结构(编程模型):Spark框架核心
RDD:弹性分布式数据集,认为是列表List
Spark 框架将要处理的数据封装到集合RDD中,调用RDD中函数处理数据
RDD 数据可以放到内存中,内存不足可以放到磁盘中
2)Task任务运行方式:以线程Thread方式运行
MapReduce中Task是以进程Process方式运行,当时Spark Task以线程Thread方式运行。
线程Thread运行在进程Process中,启动和销毁是很快的(相对于进程来说)。
spark是使用Scala语言开发:
java
- xxx.java源代码
- xxx.class字节码文件
- xxx.jar文件(zip压缩文件)
- jvm(java virtual machine)把jar中class文件翻译成cpu可以执行的指令
scala,多范式编程语言,面向对象,函数式
- xxx.scala
- xxx.class
spark提供了python的接口,pyspark进行开发
spark执行效率高的原因:!
1 提供新的数据结构(编程模型)RDD使得程序员从原来的数据操作者变成规则定义者,规则定义完成后,所有的操作都是spark内部帮我们完成的。这些所有的计算都是基于RDD,有RDD后,迭代更加方法,可以基于内存进行运算
2 spark基于线程,mr基于进程,线程调度比进程的调度快。
hadoop基于进程计算和spark基于线程计算的优缺点:!
hadoop的mapreduce是基于进程,进程的好处是每个进程独享资源,任务之间不方便共享数据,导致执行效率低,多个任务都读取同一份数据,这个数据就被加载多次。基于线程是为了数据共享,和提高执行效率,会产生资源竞争。
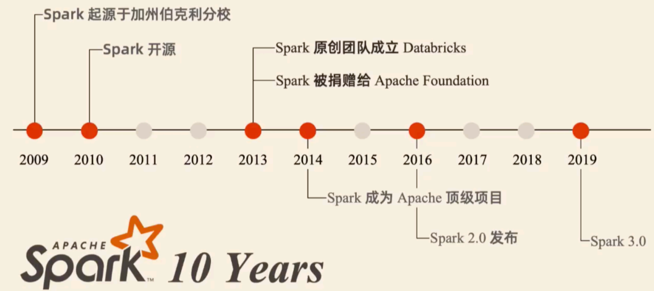
1.2 Spark的发展
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据出来框架。
Spark的发展历史,经历过几大重要阶段,如下图所示:
1.3 Spark的特点
1、速度快
原因1:spark基于内存,RDD数据结构,也可以基于磁盘进行运算,可以提供更加方便迭代计算,结果可以保存在内存中也可以存在磁盘中
原因2:spark基于线程,方便数据共享,线程启动 销毁 切换消耗的资源更少
2、易用性
1 提供多种编程语言的api:scala、java、Python、R、sql
2 提供更加高级的api:很多功能都定义好,比如:转换,遍历,排序,不同编程语言函数名字非常接近,便于阅读其他语言编写的代码
3、通用性
spark提供了多种组件,可以应对不同的场景
SparkCore spark的核心:学习spark的基础,其中最为重要的就是RDD
会了解各种语言的客户端,使用python语言操作RDD,操作的接口封装在sparkCore中
SparkSQL :DataFrame,可以使用sql语言进行数据分析处理,DSL语言(domain specified language),都是把代码翻译成对rdd的操作,从而执行
Spark Streaming:进行流式处理,现官方已放弃,了解
Machine Learning:MLlib 线性回归 逻辑回归 聚类算法
GraphX:图计算
Structrued Streaming :结构化流,进行流式处理
4、随处运行
spark可以在不同资源调度平台进行运行:local模式,Spark集群模式,yarn,mesos,可以在云服务中运行
spark和Hadoop大数据生态集成很完善了
2 Spark安装
2.1 安装spark
直接加压安装包到指定目录中,进入到spark/bin执行./pyspark(命令,可执行的脚本程序)
[root@node1 spark]# tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/
[root@node1 spark]# /export/server/spark/bin/pyspark
安装成功后为了方便使用可以更名: (两种方式二选一即可, 推荐软连接方案),切换到安装路径下:cd /export/server
方法一: 软连接方案: ln -s spark-3.1.2-bin-hadoop3.2 spark
方法二: 直接重命名: mv spark-3.1.2-bin-hadoop3.2 spark
spark目录结构说明:
[root@node1 spark]# ll
总用量 124
drwxr-xr-x 2 1000 1000 4096 7月 4 11:27 bin ## 可行性文件
drwxr-xr-x 2 1000 1000 197 5月 24 2021 conf ## 配置文件
drwxr-xr-x 5 1000 1000 50 5月 24 2021 data ## 示例程序使用数据
drwxr-xr-x 4 1000 1000 29 5月 24 2021 examples ## 示例程序
drwxr-xr-x 2 1000 1000 12288 5月 24 2021 jars ## 依赖的jar包
drwxr-xr-x 4 1000 1000 38 5月 24 2021 kubernetes
-rw-r--r-- 1 1000 1000 23235 5月 24 2021 LICENSE
drwxr-xr-x 2 1000 1000 4096 5月 24 2021 licenses
-rw-r--r-- 1 1000 1000 57677 5月 24 2021 NOTICE
drwxr-xr-x 9 1000 1000 327 5月 24 2021 python ## Python API包
drwxr-xr-x 3 1000 1000 17 5月 24 2021 R
-rw-r--r-- 1 1000 1000 4488 5月 24 2021 README.md
-rw-r--r-- 1 1000 1000 183 5月 24 2021 RELEASE
drwxr-xr-x 2 1000 1000 4096 5月 24 2021 sbin ## 集群管理命令
drwxr-xr-x 2 1000 1000 42 5月 24 2021 yarn ## 整合yarn相关内容
测试查看是否安装成功
[root@node1 spark]# ./bin/spark-shell
如下所示界面安装成功
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = local[*], app id = local-1688474426263).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
2.2 安装Anaconda环境包
安装PySpark需要首先具备Python环境,这里使用Anaconda环境
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
在虚拟机上安装anaconda,下载好安装包后上传到虚拟机环境,在安装包存放路径下执行脚本安装
[root@node3 ~]# bash Anaconda3-2021.05-Linux-x86_64.sh
一路yes,安装成功后自动创建base沙箱环境,是anaconda的默认的初始环境,也可以构建更多的虚拟环境, 用于隔离各个Python环境操作, 如果不想到base里, 也可以选择直接退出即。执行conda deactivate退出base虚拟环境
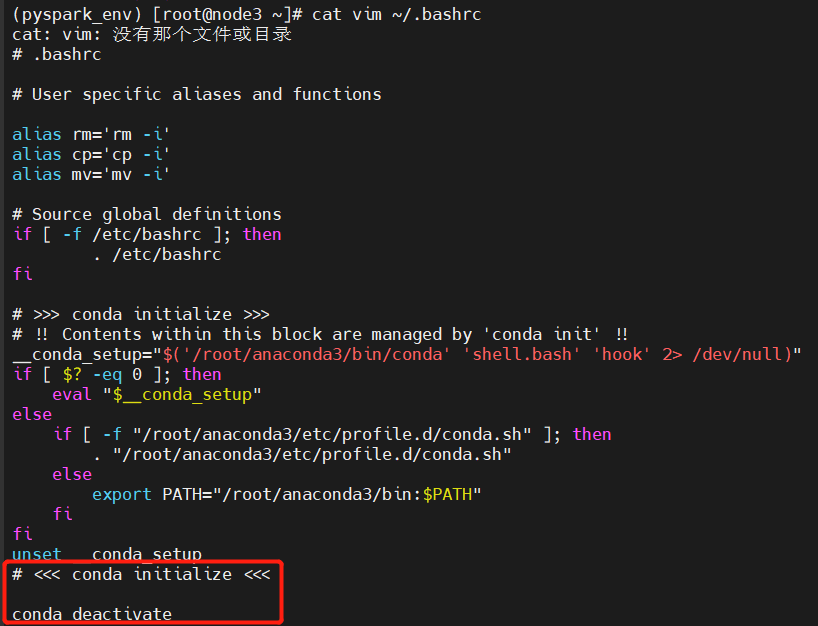
重新访问的时会重新进入了base,若让其默认不进去呢, 可以修改.bashrc这个配置文件
[root@node3 ~]# vim ~/.bashrc
在文件的末尾添加:conda deactivate
2.3 初体验Anaconda,安装pyspark
注:conda主要作用是创建和管理虚拟环境(沙箱sandbox环境);pip是安装卸载python的包的命令
eg:创建沙箱环境pyspark_env:conda create 虚拟环境名称 python=版本号
[root@node3 ~]# conda create -n pyspark_env python=3.8
eg:查看当前有那些虚拟环境: conda env list
[root@node3 ~]# conda env list
# conda environments:
#
base * /root/anaconda3
pyspark_env /root/anaconda3/envs/pyspark_env
eg:进入pyspark_env虚拟环境(激活),并安装pyspark(spark官方提供的使用python操作spark的一系列包库)
conda activate pyspark_env或source activate pyspark_env
[root@node3 ~]# conda activate pyspark_env
(pyspark_env) [root@node3 ~]# pip install pyspark==3.1.2 -i https://mirrors.ustc.edu.cn/pypi/web/simple
安装pyspark
方法一:上传pyspark-3.1.2.tar.gz到指定目录,注意这里安装时不需要解压缩
(pyspark_env) [root@node3 ~]# pip install /export/software/pyspark-3.1.2.tar.gz -i https://mirrors.ustc.edu.cn/pypi/web/simple
方法二:pip install pyspark==版本号 -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip list
查看安装列表,三台机安装成功都如下所示pyspark 3.1.2
(pyspark_env) [root@node3 ~]# pip list
Package Version
---------- -------
pip 23.1.2
py4j 0.10.9
pyspark 3.1.2
setuptools 67.8.0
wheel 0.38.4
eg:退出虚拟环境:conda deactivate 或 deactivate pyspark_env
方法一:
登录:source activate;退出:source deactivate
[root@node3 ~]# source activate pyspark_env
(pyspark_env) [root@node3 ~]# source deactivate pyspark_env
DeprecationWarning: 'source deactivate' is deprecated. Use 'conda deactivate'.
警告是在提醒source deactivate命令在conda中已被弃用,建议使用conda deactivate来替代
方法二:
登录:conda activate;退出:conda deactivate
[root@node3 ~]# conda activate pyspark_env
您在 /var/spool/mail/root 中有新邮件
(pyspark_env) [root@node3 ~]# conda deactivate
[root@node3 ~]#
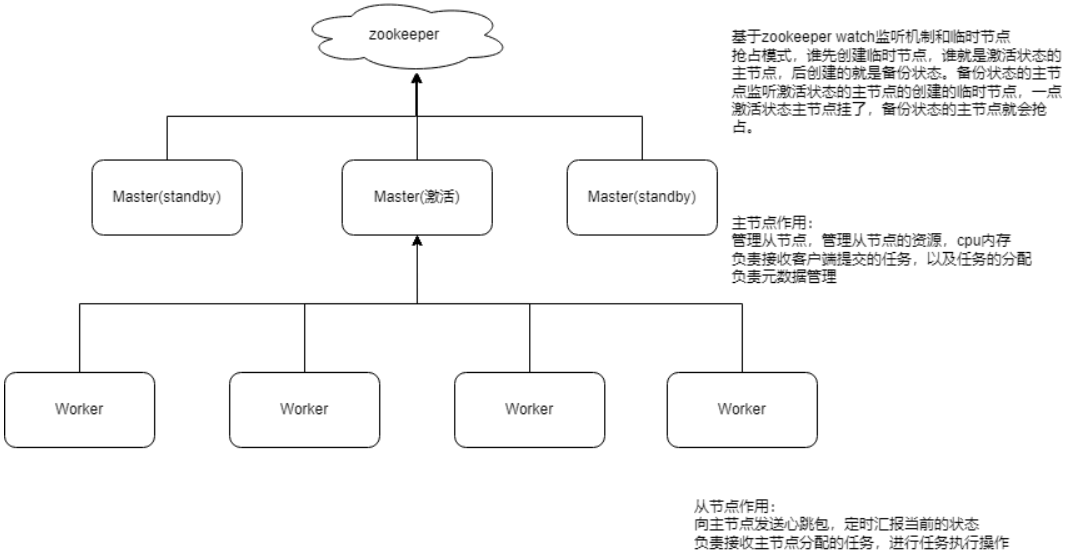
Spark集群模式架构
3 pycharm连接远程环境
在 PyCharm 中连接远程环境,你可以按照以下步骤操作:
1、打开 PyCharm 并进入项目。
2、点击菜单栏上的 “File”(文件),然后选择 “Settings”(设置)。
3、在弹出的窗口中,找到 “Project: <your_project_name>”(项目:<你的项目名称>)并展开。
4、选择 “Python Interpreter”(Python 解释器)。
5、点击右侧的设置按钮(齿轮图标),然后选择 “Add…”(新增)。
6、在弹出的 “Add Python Interpreter”(新增 Python 解释器)窗口中,选择 “SSH Interpreter”(SSH 解释器)。
7、输入远程服务器的连接信息,包括主机名、用户名和密码等。你还可以选择使用密钥文件进行认证。
8、点击 “Next”(下一步)按钮,PyCharm 将会连接到远程环境并检测可用的解释器。
9、选择你想要使用的远程解释器,然后点击 “Next”(下一步)按钮。
10、完成设置,点击 “OK”(确定)按钮。
现在应该可以在 PyCharm 中使用远程环境进行开发了。请先确保远程服务器已经配置好了相应的 Python 环境,并且网络能通,可以通过 SSH 连接访问。
3.1 词频统计案例
import os
from pyspark import SparkContext,SparkConf
# 配置环境变量
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/envs/pyspark_env/bin/python'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/envs/pyspark_env/bin/python'
os.environ['JAVA_HOME'] = '/export/server/jdk1.8.0_241'
if __name__ == '__main__':
# 1、创建spark运行环境
sparkConf=SparkConf().setAppName('wordCount').setMaster('local[*]')
sc=SparkContext(conf=sparkConf)
# 2、读取文件(可以在本地磁盘linux,也可以在hdfs中)
# 获取本地磁盘linux下的hello.txt文件
rdd_file=sc.textFile("file:///root/pybigdata/day01/hello.txt")
# # 获取HDFS根目录下的hello.txt文件
# rdd_file=sc.textFile("hdfs://node1:8020/hello.txt")
print(rdd_file,rdd_file.collect())
# 3、对句子进行分割操作, flatMap()高阶函数:处理的每个元素,再进行拼接操作
rdd_flat=rdd_file.flatMap(lambda line:line.split())
print(rdd_flat,rdd_flat.collect())
# 4、把单词和1进行映射得到键值对
rdd_map=rdd_flat.map(lambda word:(word,1))
print(rdd_map,rdd_map.collect())
# 5、分组聚合,reduceByKey():默认使用下标为0的元素作为key进行分组,接收的函数进行聚合操作
result=rdd_map.reduceByKey(lambda agg,curr:agg+curr)
# 6、输出结果,惰性计算,不调用collect()不计算
print(result.collect())
# 将结果输出到HDFS根目录下result下
result.saveAsTextFile("hdfs://node1:8020/result")
排序相关的API:
1 sortBy(参数1,参数2):
- 参数1: 自定义函数,通过函数指定按照谁来进行排序操作
- 参数2: 可选的,boolean类型,表示是否为升序。默认为True,表示升序
2 sortByKey(参数1):
- 参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序
- 默认是根据key进行排序操作,需要将排序的字段放置到key上
3 top(N,函数):
- 参数1: 取前N个元素
- 参数2: 可选的。如果kv类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定
注意: 只能进行【降序】排序,而且直接将结果返回
相关其他API:
- flatMap(函数): 根据指定的函数对元素进行转换操作,支持将一个元素转换为多个元素
- map(函数): 根据指定的函数对元素进行转换操作,支持一对一的转换操作,传入一个返回一个
- reduceByKey(函数): 根据key进行分组操作,将同一分组内的value数据合并为一个列表,然后执行传入的函数。函数传入的参数有两个,参数1表示的是局部聚合结果,参数2表示遍历的每一个列表中value值
- collect(): 收集,将程序中全部的结果数据收集回来,形成一个列表返回















 8515
8515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









