






目录
1 Kafka介绍
官网:http://kafka.apache.org/
kafka是最初由linkedin公司开发的,使用scala语言编写,kafka是一个分布式,分区的,多副本的,多订阅者的日志系统(分布式MQ系统),可以用于搜索日志,监控日志,访问日志等
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的完整实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息
kakfa的特点:
可靠性:分布式、分区、复制和容错等
可扩展性: kakfa消息传递系统轻松缩放,无需停机
耐用性: kafka使用分布式提交日志,这个意味着消息会尽可能快速的保存在磁盘上,因此它是持久的
性能: kafka对于发布和订阅消息都具有高吞吐量,即使存储了许多TB的消息,他也爆出稳定的性能-kafka非常快:保证零停机和零数据丢失
kafka的主要应用场景:
① 指标分析:kafka通常用于操作监控数据,这设计聚合来自分布式应用程序和统计信息,以产生操作的数据集中反馈
② 日志聚合解决方法: kafka可用于跨组织从多个服务器收集日志,并使他们一标准的合适提供给多个服务器
③ 流式处理:流式的处理框架(spark, storm , flink)从主题中读取数据,对其进行处理,并将处理后的结果数据写入新的主题,供用户和应用程序使用, kafka的强耐久性在流处理的上下文中也非常的有用
Kafka的架构
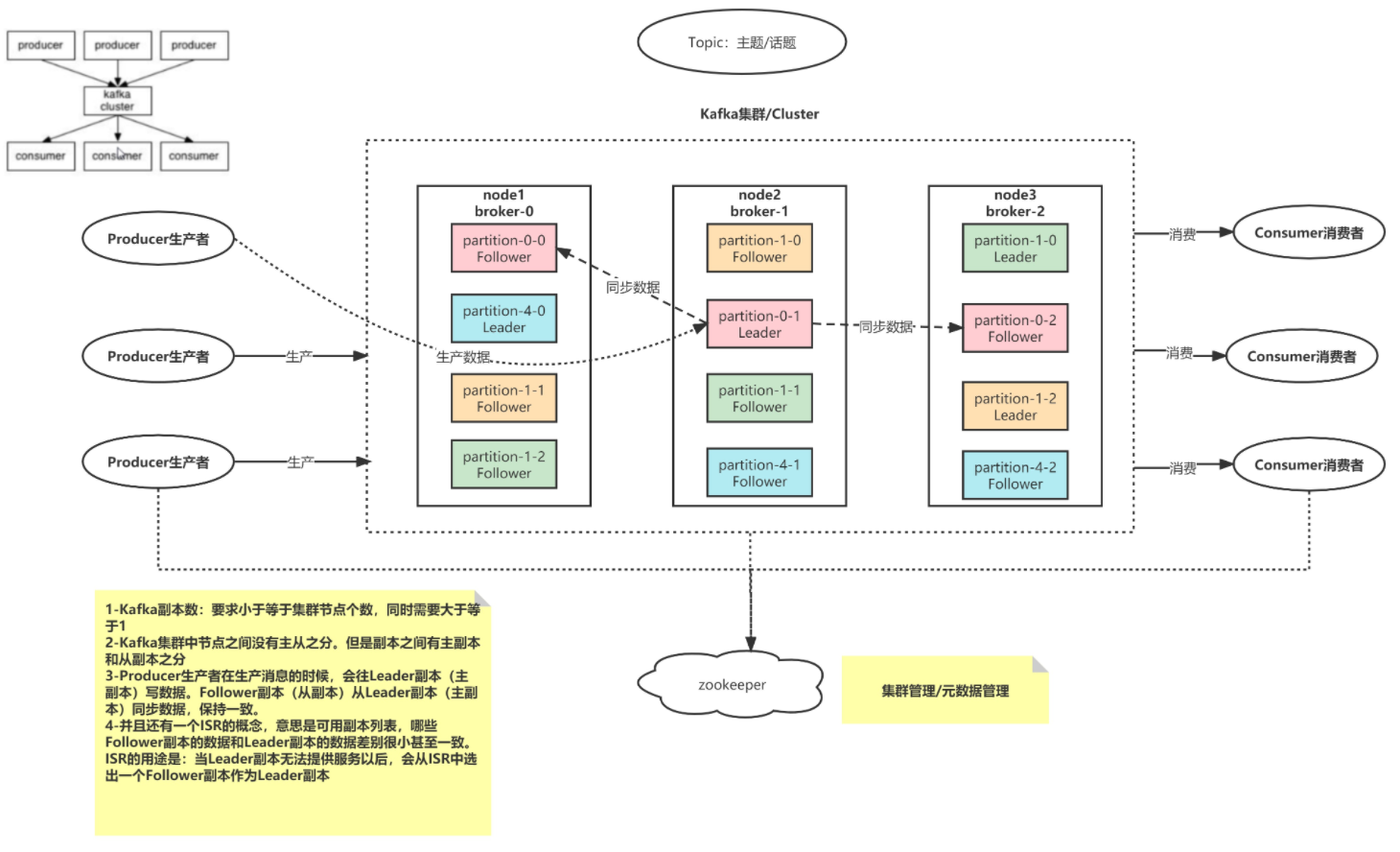
Kafka Cluster: Kafka 集群
broker: Kafka的节点
Topic: 主题/话题
partition: 分区,一个Topic会有多个Partition,建议是节点数量的2-3倍(保证扩容后负载均衡)
replication: 副本,副本个数不能够超过broker的个数
zookeeper: 负责Kafka集群管理,以及元数据管理
Producer: 生产者,负责生产数据
Consumer: 消费,负责消费数据
2 Kafka的使用
2.1 创建Topic
参数说明:
--create:操作类型。这里是创建
--bootstrap-server:指定Kafka集群的连接信息,就是在server.properties中配置的信息
--partitions 5:配置Topic的分区数量,数量只要大于等于1就可以
--replication-factor 2:配置每个分区的总的副本数。副本数不能超过集群的broker个数
--topic test01:指定新建的Topic名称
[root@node1 ~]# kafka-topics.sh --create --bootstrap-server node1:9092 --partitions 4 --replication-factor 2 --topic test03
2.2 查看所有Topic
参数说明:
--list:操作类型。这里是列出对应的Kafka集群上可用的Topic列表
--bootstrap-server:指定Kafka集群的连接信息,就是在server.properties中配置的信息
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092 --list
__consumer_offsets
test01
test02
test03
2.3 查看具体Topic
参数说明:
--describe:操作类型。查看具体Topic的信息
--bootstrap-server:指定Kafka集群的连接信息,就是在server.properties中配置的信息
--topic test01:指定需要查看的具体Topic名称。如果不加–topic该参数,会将集群中所有可用的Topic信息都输出出来
[root@node1 ~]# kafka-topics.sh --describe --bootstrap-server node1:9092 --topic test03
Topic: test03 PartitionCount: 4 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test03 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: test03 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: test03 Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test03 Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0

2.4 模拟生产者Producer
参数说明:
--broker-list:指定Kafka集群的连接信息,就是在server.properties中配置的信息
--topic test01:指定需要将数据发送到的Topic名称
[root@node1 ~]# kafka-console-producer.sh --broker-list node1.itcast.cn:9092,npde2 .itcast.cn:9092,node3.itcast.cn:9092 --topic test01
[2023-07-15 11:20:27,105] WARN Couldn't resolve server npde2.itcast.cn:9092 from b ootstrap.servers as DNS resolution failed for npde2.itcast.cn (org.apache.kafka.cl ients.ClientUtils)
>发送的消息1
>发送的消息2
2.5 模拟消费者Consumer
参数说明:
--bootstrap-server:指定Kafka集群的连接信息,就是在server.properties中配置的信息
--topic test01:指定需要消费消息的Topic名称
--from-beginning:从Topic最开始的消息进行消费
latest: 从Topic最新的消息进行消费
--group:指定消费组名称。一个消费组里面包含多个消费者,同一个Topic的同一条数据,只会被消费组中的某一个消费者所消费。
--max-messages:指定消费的消息的最大条数
在实际工作中,一般是latest和–max-messages配合使用。因为实际工作,一个Topic的数据量是非常大的,避免造成机器宕机。
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092 --topic test01 --partition 0
2.6 修改Topic
修改分区数: 只能增大分区数
修改副本数: 既不能增大,也不能减小副本数
[root@node2 ~]# kafka-topics.sh --alter --bootstrap-server node1.edu.cn:9092,node2.edu.cn:9092,node3.edu.cn:9092 --topic test02 --partitions 2
尝试减小分区的时候会报错:原因是只能增大分区不能减小分区,原先已经有6个分区不能改成5个
Error while executing topic command : org.apache.kafka.common.errors.InvalidPartitionsException: Topic currently has 6 partitions, which is higher than the requested 5.
2.7 删除Topic
参数说明:
--delete:指定操作类型,这里是删除Topic
--bootstrap-server:指定Kafka集群的连接信息,就是在server.properties中配置的信息
--topic test01:指定需要将数据发送到的Topic名称
[root@node1 ~]# kafka-topics.sh --delete --bootstrap-server node1:9092 --topic test03
3 Kafka的核心原理!
3.1 Topic的分区和副本机制
分区的作用:
总体的目标保证负载均衡,
1-解决单台节点容量有限的问题: 每一台服务器的硬盘资源始终是有上限的。一个Topic分成多个分区之后,可以使用多个服务器节点的存储资源,提供更多的数据存放能力。
2-增加Topic对数据的吞吐量: 通过分区操作,将一个Topic分成了多个分区,多个分区分布在不同的节点上面,从而提供更加高效的数据读写请求
分区的数量有没有限制?
没有限制,和集群中Broker节点个数没有半毛钱关系。但是实际工作中,推荐分区数量不要超过集群总节点个数的3倍,这只是一个经验值。
副本的作用:
提高数据的可靠性: 副本越多,数据就越安全。冗余(相同)的数据就越多
副本的数量有没有限制?
有限制,最多和集群中Broker节点个数一致。但是实际工作中,根据数据的重要程度,推荐副本的数量在1-3之间。如果数据相对不太重要,可以配置少一些的副本数量;如果数据相对重要,可以配置多一些的副本数量。
3.2 消息存储和查询机制

1-Kafka中数据存放位置:
在server.properties中配置的log.dirs=/export/server/kafka/data
2-data目录下,文件夹的命名规则如下:
一个分区对应一个目录,Topic名称-分区编号;如果有副本,则对应分区的目录在其他节点会有一模一样的拷贝、
3-segment中文件名称命名规则如下:
文件名称中的数字,表示该文件中第一条数它的offset(偏移量)
分文件(不同的log文件)存储
分文存储原因,另一个原因,删除时只用检查log文件的最后修改时间,如果大于设置的阈值(7天),则直接删除该文件即可。就不用遍历整个文件删除符合条件数据
每个log文件都是使用该文件存储的第一个消息的偏移量,这样每个log文件的文件名称时有序的,这样在查找某条数据时可以使用二分查找法快速查询
Kafka是将数据存放在磁盘上面,磁盘的存放路径在server.properties中配置的log.dirs=/export/server/kafka/data来进行指定。
在对应的目录下,以 Topic名称-分区编号 创建一个目录。
在目录中放在消息数据,主要有两个核心文件,一个是xxx.index文件,另外一个是xxx.log文件
index文件: 存储索引数据,主要作用是加快查询log文件中数据的速度
log文件: 存放实际的消息数据
[root@node2 data]# pwd
/export/server/kafka/data
[root@node2 data]# cd test01-0
[root@node2 test01-0]# ll
总用量 0
-rw-r--r-- 1 root root 10485760 7月 14 18:17 00000000000000000000.index
-rw-r--r-- 1 root root 0 7月 14 18:17 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 7月 14 18:17 00000000000000000000.timeindex
-rw-r--r-- 1 root root 0 7月 14 18:17 leader-epoch-checkpoint
请问: 消息数据是一直不断的往一个log文件写呢,还是会分成多个文件来存储?
会分成多个文件存储。当log文件的大小达到1GB的时候,就会滚动形成新的文件。同时配套的index文件也会跟着滚动生成。
请问: 为什么要分成不同的文件存储?
1-一个文件过大,打开和关闭文件需要消耗大量的系统资源
2-一个文件过大,在里面查找具体数据的时候,非常耗时
3-Kafka只是对数据做临时的存储,而不是永久存储,所以Kafka会定时的将过期数据删除掉。当消息超过一定时间以后,Kafka会认为数据失效,就会被Kafka删除。数据默认的保留时间是168小时(7天),是在server.properties中通过log.retention.hours=168配置参数指定
查询的机制
查询步骤:
1-首先先确定要读取的这个Offset(偏移量)在哪个segment片段中
2-查询这个segment片段的index文件,根据offset确定这个消息在log文件的什么位置,也就是确定消息的物理偏移量
3-读取log文件,查询对应范围内的数据即可(底层是基于磁盘顺序查询)
4-获取最终的消息数据
扩展内容: 磁盘的读写中,有两种方案:随机读写 和 顺序读写。顺序读写的速度会更快
3.3 Kafka中生产者数据分发策略
生产者生产的数据到达Broker的某一个Topic之后,这个消息最终应该写入到Topic的哪一个分区上面,这就是数据的分发策略
分发策略如下:
1 随机分发策略:在Python的客户端支持,但是在Java中不支持
2 指定分区策略:发送数据的时候,直接明确指定要将数据发到哪个分区。支持
from kafka import KafkaProducer
from kafka.partitioner import murmur2
if __name__ == '__main__':
print('生产者')
producer=KafkaProducer(bootstrap_servers=['node1:9092','node2:9092','node3:9092'])
for i in range(10):
# 异步发送:指定分区分发策略
producer.send(topic='test01',
value=f'你好{i}'.encode('UTF-8'),
partition=1)
producer.flush()
3 Hash取模策略:对数据按照Key进行Hash取模,然后分发。支持
from kafka import KafkaProducer
from kafka.partitioner import murmur2
if __name__ == '__main__':
print('生产者')
producer=KafkaProducer(bootstrap_servers=['node1:9092','node2:9092','node3:9092'])
for i in range(10):
# 异步发送:hash值确定分发策略
producer.send(topic='test01',
value='hhh'.encode('UTF-8'),
key=b'hhh')
producer.flush()
4 轮询策略:在2.4及以上版本,已经更改为粘性分发策略。在Python的客户端不支持,但是在Java中支持
5 自定义分区策略:支持
if __name__ == '__main__':
# 1 创建sparksql
spark = SparkSession \
.builder.master('local[*]') \
.appName('SoarkSession') \
.getOrCreate()
sc: SparkSession = spark.sparkContext
spark.conf.set('spark.sql.shuffle.partitions', 20)
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)
df:DataFrame=spark.readStream\
.format('socket')\
.option('host','node1')\
.option('port','55555').load()
df.writeStream\
.format('console')\
.outputMode('complete')\
.start()\
.awaitTermination()
4 Structured Streaming
Structured Streaming 是基于 Spark SQL 引擎构建的可扩展和容错流处理引擎. 基于Structured Streaming可以像对静态数据的批处理一样的进行流式计算操作. Spark SQL 引擎将负责以增量和连续的方式运行它,并随着流数据的不断到达而更新最终结果. 可以使用 Scala、Java、Python 或 R 中的Dataset/DataFrame API来表示流聚合、事件时间窗口、流到批处理连接等
计算在同一个优化的 Spark SQL 引擎上执行。最后,系统通过检查点和预写日志确保端到端的精确一次容错保证。简而言之,结构化流式处理提供快速、可扩展、容错、端到端的一次性流处理,用户无需对流式处理进行推理。
在内部,默认情况下,结构化流查询使用微批处理引擎处理,该引擎将数据流作为一系列小批量作业处理,从而实现低至 100 毫秒的端到端延迟和一次性容错保证. 但是,从 Spark 2.3 开始,Spark引入了一种新的低延迟处理模式,称为Continuous Processing,它可以实现低至 1 毫秒的端到端延迟,并保证至少一次。在不更改查询中的 Dataset/DataFrame 操作的情况下,能够根据应用程序要求选择对应的模式。
数据源部分(Source)
结构化流默认提供了多种数据源,从而可以支持不同的数据源的处理工作。目前提供了如下数据源:
1、File Source:文件源,一般用于测试。作用是对接文件系统,监听某个目录下的所有文件,如果有新的文件产生,就会立即进行处理操作
2、 Kafka Source:Kafka的数据源,一般用于生产。作用是对接Kafka,相当于是Kafka的消费者,从Kafka中获取数据
3、Socket Source:套接字数据源,一般用于测试。作用是可以监听服务器上某个端口的数据
4、Rate Source:速率数据源,一般用于测试。作用是可以实现自动生成数据源,主要是用于测试工作。
4.1 Sink输出操作
在结构化流中定义好DataFrame或者处理好DataFrame之后,调用writeStream()方法完成数据的输出操作。在输出的过程中,我们可以设置一些相关的属性,然后启动结构化流程序运行。
4.1.1 输出模式
Spark提供了以下几种类型的输出模式:
① append mode(默认):增量模式,这是默认模式,
作用:当结构化流处理的时候,如果有了新数据,才会触发输出。只支持追加,不支持聚合。如果执行聚合操作,会直接报错。而且也不支持对数据排序操作。如果排序,会直接报错。
例如,只有select, where, map, flatMap, filter,join等的查询将支持追加模式。
if __name__ == '__main__':
# 1 创建sparksql
spark = SparkSession.builder.master('local[*]') \
.appName('append').getOrCreate()
# 接收加载实时数据
df:DataFrame=spark.readStream.format('socket')\
.option('host','node1').option('port','55555').load()
# 数据处理
result=df.select(F.split('VALUE',' ')[0].alias('id'),
F.split('value',' ')[1].alias('name'))
# 结果控制台输出
result.writeStream.format('console')\
.outputMode('append')\
.start().awaitTermination()
常见报错:
pyspark.sql.utils.AnalysisException: Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark;
Append不能在流式处理数据没有聚合的情况下使用
② Complete mode:完全(全量)输出模式
每次触发后, 整个结果表都将输出到接收器,只支持聚合操作
if __name__ == '__main__':
# 1 创建spark
spark = SparkSession.builder.master('local[*]') \
.appName('Complete').getOrCreate()
# 接收加载实时数据
df:DataFrame=spark.readStream.format('socket')\
.option('host','node1').option('port','55555').load()
# 数据清洗,如果不进行格式化输出,数据只有value一列
result=df.select(F.split('value',' ')[0].alias('id'),
F.split('value',' ')[1].alias('name'))
# 数据按照name分组聚合计算
result1:DataFrame=result.groupby('name').count()
# 数据输出到控制台
result1.writeStream.format('console')\
.outputMode('complete')\
.start().awaitTermination()
常见报错:
pyspark.sql.utils.AnalysisException: Complete output mode not supported when there are no streaming aggregations on streaming DataFrames/Datasets; socket
Complete不能在没有聚合的情况下使用
③ Update mode:更新模式,2.1.1版本后支持
作用:在数据处理阶段中没有聚合操作的时候,该模式和append模式效果基本一致。如果有了聚合操作,只会输出变更和新增的数据,但是不支持排序操作。
if __name__ == '__main__':
# 1 创建sparksql
spark = SparkSession.builder.master('local[*]') \
.appName('Update').getOrCreate()
df:DataFrame=spark.readStream.format('socket')\
.option('host','node1').option('port','55555').load()
# 数据清洗
result=df.select(F.split('value',' ')[0].alias('id'),
F.split('value',' ')[1].alias('name'))
# 进行聚合操作
result1:DataFrame=result.groupby('name').count()
# update在有聚合时,和complete区别:complete无论数据有无变化都会输出,update只在数据有变化的时候输出
result1.writeStream.format('console')\
.outputMode('update')\
.start().awaitTermination()
常见错误如下:解决方法是重启端口nc -lk 55555
pyspark.sql.utils.StreamingQueryException: at 0 deleting 3
=== Streaming Query ===
Identifier: [id = 910c95e8-8f03-4820-b4a0-23012a43eb23, runId = e08b92d1-3d35-4761-acb6-18da08c77c2a]
Current Committed Offsets: {TextSocketV2[host: node1, port: 55555]: 2}
Current Available Offsets: {TextSocketV2[host: node1, port: 55555]: -1}
Current State: ACTIVE
Thread State: RUNNABLE
Logical Plan:
Project [split(value#0, , -1)[0] AS id#2, split(value#0, , -1)[1] AS name#3]
+- StreamingDataSourceV2Relation [value#0], org.apache.spark.sql.execution.streaming.sources.TextSocketTable$$anon$1@464389b8, TextSocketV2[host: node1, port: 55555]
pyspark.sql.utils.AnalysisException: Queries with streaming sources must be executed with writeStream.start(); socket
错误原因:Structured Streaming不能使用show()进行输出,必须使用writeStream.start()输出
4.1.2 输出终端/位置
默认情况下,Spark的结构化流支持多种输出方案:
① console sink:将结果数据输出到控制台。主要是用在测试中,并且支持3种输出模式
② File sink:输出到文件。将结果数据输出到某个目录下,形成文件数据。只支持append模式,每个批次一个小文件,最终小文件很多,常用于测试
③ foreach sink 和 foreachBatch sink:将数据进行遍历处理。遍历后输出到哪里,取决于自定义函数。并且支持3种输出模式
④ memory sink:将结果数据输出到内存中。主要目的是进行再次的迭代处理。数据大小不能过大。支持append模式和complete模式
⑤ Kafka sink:将结果数据输出到Kafka中。类似于Kafka中的生产者角色。并且支持3种输出模式
4.1.3 设置触发器Trigger
触发器Trigger:决定多久执行一次操作并且输出结果。也就是在结构化流中,处理完一批数据以后,等待一会,再处理下一批数据
if __name__ == '__main__':
# 1 创建sparksql
spark = SparkSession.builder.master('local[*]').appName('trigger').getOrCreate()
df:DataFrame=spark.readStream.format('socket')\
.option('host','node1').option('port','55555').load()
result=df.select(F.split('value',' ')[0].alias('id'),
F.split('value',' ')[1].alias('name'))
result.writeStream\
.format('console').outputMode('append')\
.trigger(processingTime='5 seconds')\
.start().awaitTermination()
result.writeStream\ AttributeError: 'StreamingQuery' object has no attribute 'trigger'错误原因:trigger需要放在start()前面
4.1.4 CheckPoint检查点目录设置
设置检查点,目的是为了提供容错性。当程序出现失败了,可以从检查点的位置,直接恢复处理即可。避免出现重复处理的问题
1-偏移量offsets: 记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据。在处理数据之前会将offset信息写入到该目录
2-提交记录commits: 记录已经处理完成的批次。重启任务的时候会检查完成的批次和offsets目录中批次的记录进行对比。确定接下来要处理的批次
3-元数据文件metadata: 和整个查询关联的元数据信息,目前只保留当前的job id
4-数据源sources: 是数据源(Source)各个批次的读取的详情
5-数据接收端sinks: 是数据接收端各个批次的写出的详情
6-状态state: 当有状态操作的时候,例如:累加、聚合、去重等操作场景,这个目录会用来记录这些状态数据。根据配置周期性的生成。snapshot文件用于记录状态
如何设置检查点:
方式一: 基于DataFrame来进行设置
df.writeStream.option('checkpointLocation','checkpoint数据存放路径')
方式二: 基于SparkSession进行设置
SparkSession.conf.set("spark.sql.streaming.checkpointLocation", 'checkpoint数据存放路径')
路径设置,推荐使用HDFS的文件系统。如果程序是local模式运行,也可以使用本地路径进行存储
常见错误:
pyspark.sql.utils.AnalysisException: checkpointLocation must be specified either through option("checkpointLocation", ...) or SparkSession.conf.set("spark.sql.streaming.checkpointLocation", ...)
这个错误提示是关于 Spark 的流处理(streaming)的一个设置:checkpointLocation。Spark 流处理中checkpointLocation 是一个必需的设置。它用于保存流处理应用程序的状态和元数据,包括偏移量信息、批次处理记录。解决方法加上检查点目录设置。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









