






目录
1 Flink简介
流式处理的特点:数据是一条一条地计算,把这种计算称之为数据流的计算
1.1 发展历史
2008年起源于欧洲柏林大学的一个研究性项目
2014年4月份,被捐赠给了Apache
2014年12月份,从Apache毕业(孵化成功)
2019年1月份,Flink的母公司被阿里巴巴收购,从此Flink就是阿里的了
目前的Flink最新版为1.17.1
特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
1.2 概述
Flink:基于数据流上有状态的计算。状态就是计算结果,有状态就是Flink会保存计算的中间结果。
数据流:流动的数据。
应用场景:
事件驱动:欺诈检测,监控告警等
流式管道:实时数仓
流批分析:用Flink进行实时指标分析
1.3 架构
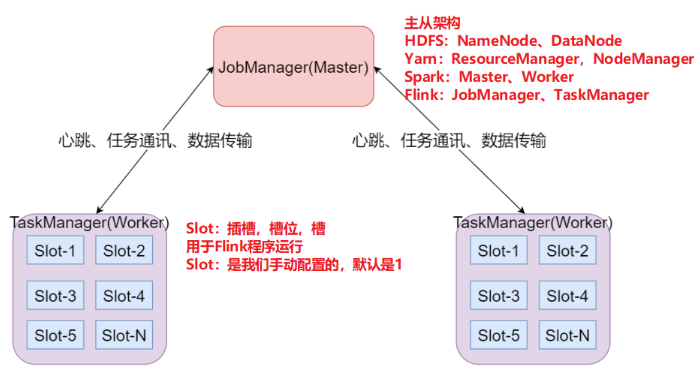
Flink的架构目前需要了解的如下:
JobManager:集群的主节点,负责集群管理等
TaskManager:集群的从节点,负责任务的执行
Slot:槽,或者叫插槽,是从节点的资源单位,Flink任务必须在Slot里运行。Slot的数量是人为设置的,默认是1。
一旦设置后,就无法更改。如果要更改,需要修改配置,然后重启集群。
2 Flink的安装部署
Flink可以运行在多种模式下:
Local(本地):一个进程模拟主节点和从节点。
Standalone(独立):主节点和从节点是两个进程,他们是独立的。
Flink on Yarn(生产使用)
2.1 Standalone
直接一台节点上部署配置,完成后bin/start-cluster.sh启动,Web页面在8081端口,启动后页面一直存在
2.2 Flink提交到yarn
Flink On Yarn有三种模式,分别是:
1、session模式:session,会话,因此也称之为会话模式。先初始化一个集群,所有任务都在该集群中,跑完后主节点不会消失,从节点消失,
优缺点:资源消耗小,任务运行时省时效率高,适合小任务场景
2、per-job模式:per每,job任务,Job分离模式,每个任务都会初始化一个Flink集群,跑完后主从都消失。类似于spark中的client模式,客户端在提交的节点上非集群
优缺点:资源丰富,单个任务运行在一个集群内,隔离性好,安全。但资源消耗过多。适合大任务大数据量场景
3、Application模式!:application,应用,也称之为应用模式。解决了前两种的弊端(客户端在本地启动),客户端在集群中任选一台闲置的节点非本地启动,每个任务都会创建一个集群,待任务结束后再销毁集群,与per-job模式一样
优缺点:适合大任务,非频繁提交任务,类似spark中的cluster模式,
session模式下两步走:① 初始化Flink会话集群:bin/yarn-session.sh
端口一直占用,随机分配一台节点上展示web页面
2023-08-20 12:05:54,487 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2023-08-20 12:05:59,525 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2023-08-20 12:05:59,526 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node3:43616 of application 'application_1692862956619_0006'.
JobManager Web Interface: http://node3:43616
② 向集群提交任务,可提交多个任务,每个任务执行完后自动销毁
命令与standalone模式提交命令一样:bin/flink run examples/batch/WordCount.jar
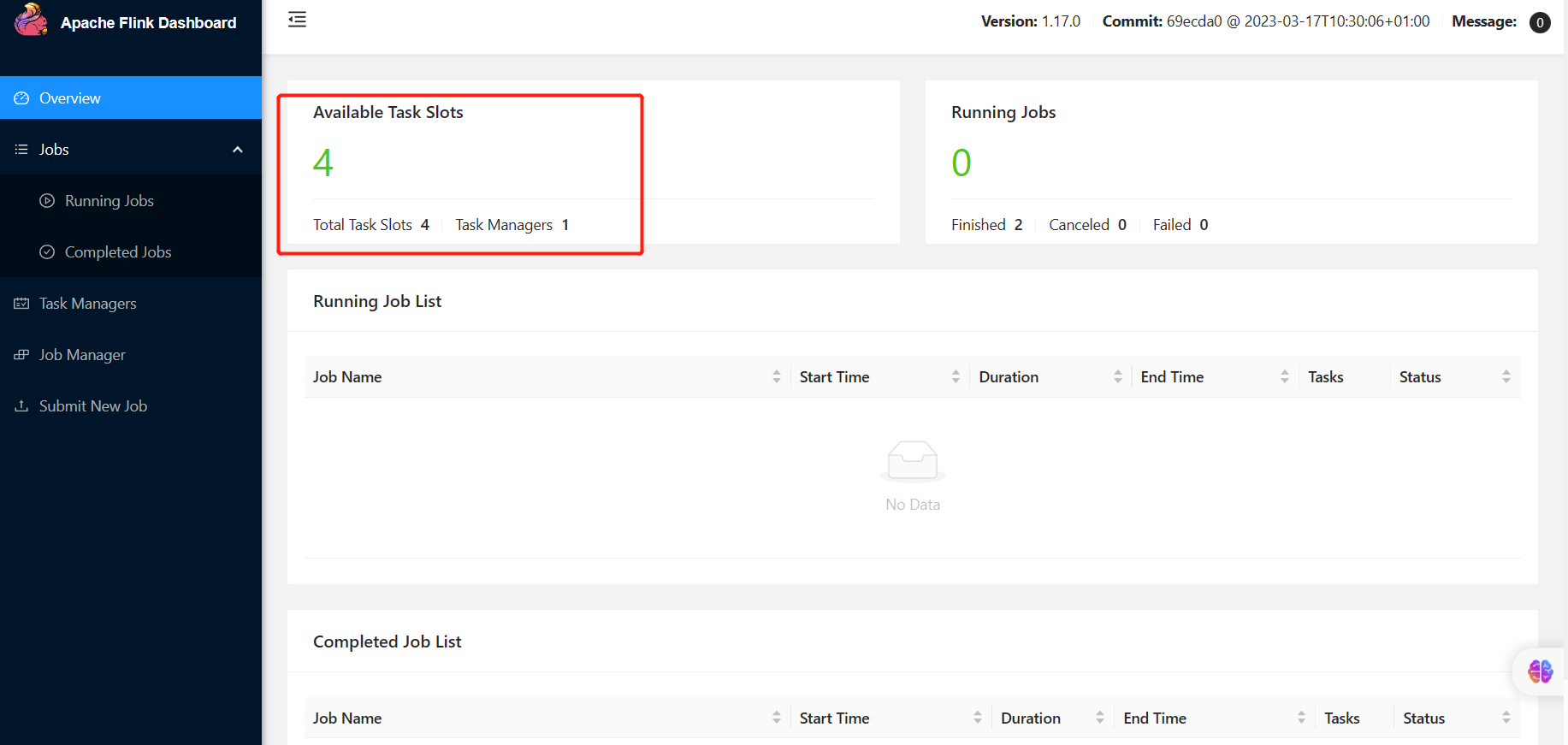
总结:Flink程序如何跑在Yarn
#1.加载兼容包
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
commons-cli-1.5.0.jar
#2.启动HDFS和Yarn
start-all.sh
#3.提交命令,提交方式有三种,分别是:
#(1)session模式
bin/yarn-session.sh
bin/flink run examples/batch/WordCount.jar
#(2)Per-job模式
bin/flink run -m yarn-cluster examples/batch/WordCount.jar
#(3)application模式
bin/flink run-application -t yarn-application examples/batch/WordCount.jar --input hdfs://node1:8020/flink/wordcount.txt --output hdfs://node1:8020/flink/output1
Yarn和Standalone的并行度区别
1、现象
(1)在Standalone模式下,如果slot槽不够用,则任务无法正常运行。因为这种模式下,没办法动态初始化slot资源。
(2)在Yarn模式下,如果slot槽不够用,则会动态初始化slot资源。因为Yarn能动态启动一些容器,并且把容器的资源以slot的形式给到任务。
2、结论
在生产上,使用Yarn模式,当然推荐使用Yarn的Application模式。
开发测试上,一般使用Standalone模式。
3 入门案例
分层API介绍:

Flink程序开发的一般流程:
1、构建流式执行环境
2、数据源(source)
3、数据处理(transformation)
4、数据输出(sink)
5、启动流式任务
eg:统计单词数:
3.1 DataStream API
import cn.hutool.core.lang.Tuple;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Demo02_WordCountStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
// 2.构建数据源:指定socket路径,获取数据
DataStreamSource<String > sourceDS=env.socketTextStream("node1",9999);
// 3.数据处理
// 3.1对数据经常flatMap扁平化,返回的是一个个单词
SingleOutputStreamOperator<String> flatMapDS = sourceDS.flatMap(new FlatMapFunction<String, String >() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String [] words=value.split(",");
for (String word:words){
out.collect(word);
}
}
});
// 3.2对扁平化的单词数据进行map转换(单词,1)
SingleOutputStreamOperator<Tuple2<String, Integer>> mapDS = flatMapDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value,1);
}
});
// 3.3对单词进行分组
KeyedStream<Tuple2<String, Integer>, String> keyByDS = mapDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
// 3.4对分组后的数据进行聚合reduce
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyByDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
result.print(); //4.数据输出
env.execute(); //5.启动流式任务
}
}
优化案例:DataStream lamdba表达式
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class Demo06_WordCountStream_02 {
public static void main(String[] args) throws Exception {
// 构建流式执行环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); //设置并行度
// 2.构建数据源:指定socket路径,获取数据
DataStreamSource<String > sourceDS=env.socketTextStream("node1",9999);
// 数据处理(transformation)
/**
* String[] words = value.split(",");
* for (String word : words) {
* out.collect(word);
* }
*/
SingleOutputStreamOperator<Tuple2<String, Integer>> result = sourceDS
.flatMap((String value, Collector<String> out)->Arrays.stream(value.split(",")).forEach(out::collect)).returns(Types.STRING)
.map((String value)->Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy((Tuple2<String, Integer> value)->value.f0).sum(1);
result.print(); //4.数据输出
env.execute(); //5.启动流式任务
}
}
错误记录:
The return type of function 'main(Demo05_WordCountStream_02.java:55)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
原因:flink时数据类型被擦除,解决方法:每个转换了数据类型的算子(flatMap、map算子)后面需要调用returns返回数据类型
3.2 Table API
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.concurrent.ExecutionException;
public class Demo07_WordCountTable {
public static void main(String[] args) throws Exception {
// 1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 通过流式环境构建流式表达式
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.getConfig().set("parallelism","1");
// 2.数据源
/**
* TableDescriptor.forConnector():连接器,可连接不同的数据源
* socket数据源需要flink-examples-table_2.12-1.17.0.jar包来支持
* socket=hostname+Post
* newBuilder(). 建造者模式,sparksession中类似
*/
tEnv.createTemporaryTable("source_table",TableDescriptor.forConnector("socket")
.schema(Schema.newBuilder()
.column("word", DataTypes.STRING()).build())//构建表的Schema信息
.option("hostname","node1")
.option("port","9999")
.option("format","csv")//format数据输入的格式
.build());//bulid构建整张表
// 3.数据输出sink,构建目标表:sink_table
//print连接器,不需要引入额外的jar包,也可以直接用,因为是内置的连接器
tEnv.createTemporaryTable("sink_table",TableDescriptor.forConnector("print")
.schema(Schema.newBuilder()
.column("word",DataTypes.STRING())
.column("count",DataTypes.BIGINT()).build())//构建两列
.build());//bulid构建整张表
// 4.数据处理
/**
* source_table
* 插入表数据
*/
tEnv.from("source_table")
.groupBy(Expressions.$("word"))
.select(Expressions.$("word"),Expressions.lit(1).count())
.executeInsert("sink_table").await();//阻塞执行,等待数据到达执行处理
// 5.启动流式任务
env.execute();
}
}
错误记录1:没有jar包依赖的错误
Cannot discover a connector using option: 'connector'='socket'
at org.apache.flink.table.factories.FactoryUtil.enrichNoMatchingConnectorError(FactoryUtil.java:736)
at org.apache.flink.table.factories.FactoryUtil.discoverTableFactory(FactoryUtil.java:710)
at org.apache.flink.table.factories.FactoryUtil.createDynamicTableSource(FactoryUtil.java:163)
... 44 more
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'socket' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
解决方法:在maven的pom.xml文件中加入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-examples-table_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
错误记录2:counts列类型不匹配错误:
Exception in thread "main" org.apache.flink.table.api.ValidationException: Column types of query result and sink for 'default_catalog.default_database.sink_table' do not match.
Cause: Incompatible types for sink column 'count' at position 1.
Query schema: [word: STRING, EXPR$0: BIGINT NOT NULL]
Sink schema: [word: STRING, count: INT]
解决方法:将count列的类型改为BIGINT
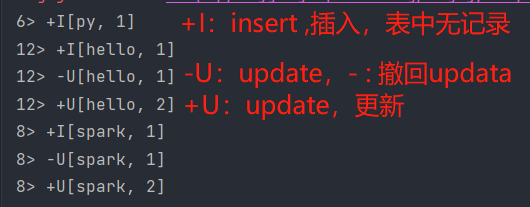
成功运行结果如下:
3.3 SQL API
public class Demo08_WordCountSQL {
public static void main(String[] args) throws Exception {
// 1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 通过流式环境构建流式表达式
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 设置并行度
tEnv.getConfig().set("parallelism.default","1");
// 2.数据源,构建数据源表:source_table,数据来源于9999端口的信息
tEnv.executeSql("create table source_table(" +
"word string) with (" +
"'connector'='socket'," +
"'hostname'='node1'," +
"'port'='9999'," +
"'format'='csv'" +
")");
// 3.输出sink,构建目标表sink_88table
tEnv.executeSql("create table sink_table(" +
"word string,counts bigint) with(" +
"'connector'='print'" +
")");
// 4.数据处理,将数据更新到sink_table目标表中。.await()阻塞执行,等待数据到达后执行处理
tEnv.executeSql("insert into sink_table " +
"select word,count(1) from source_table group by word").await();
// 5.启动流式任务
env.execute();
}
}
4 提交运行
通过maven 的package打包,生成瘦包跟胖包,后者包含jar包依赖

Flink支持两种方式的提交:
① 通过命令行的方式
[root@node1 ~]# /export/server/flink/bin/flink run -c day01.Demo05_WordCountStream_02 ./flinkbase-1.0-SNAPSHOT.jar
Job has been submitted with JobID 64b9d2e72d18219ee7b7b9c4b68f7cb5
② 通过WebUI界面提交
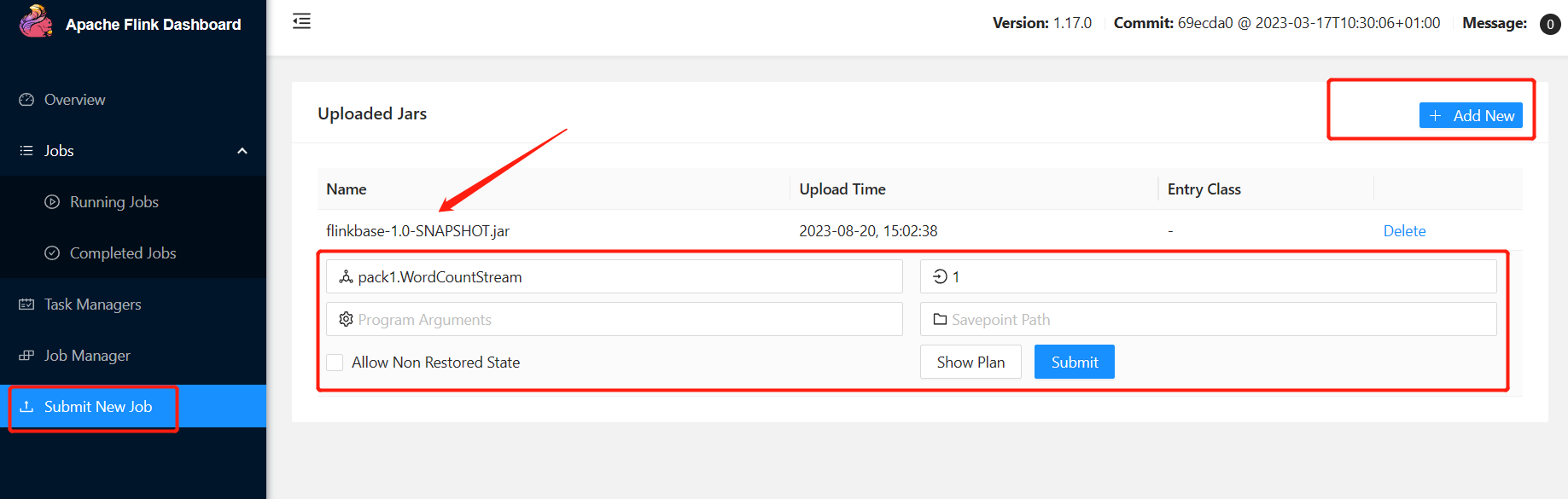















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









