







大数据技术和 Spark 概述 64页
通过实例学习 DataFrame、SQL、Dataset 等 Spark 的核心 API
了解 Spark 的低级 API 实现,包括 RDD 以及 SQL 和 DataFrame 的执行过程
了解 Spark 如何在集群上运行
Spark 集群和应用程序的调试、监控、和调优
学习 Spark 强大的流处理引擎——结构化流处理
学习 MLlib 并了解如何应用它解决包括分类和推荐等多种实际问题
“这本书是所有 Spark 开发者的必读物,介绍了许多其他地方都找不到的技巧和窍门。”
例如,典型的机器学习算法可能需要对数据进行 10 或 20 次迭代处理,而在 MapReduce 中,每次迭代都必须通过一个 MapReduce 作业来完成,必须在分布式集群上重新读去全部数据 并单独启动一次作业。
数据分区:
为了让多个执行器并行地工作,Spark 将数据分解成多个数据块,每个数据块叫做一个分区。 分区是位于集群中的一台物理机上的多行数据的集合,DataFrame 的分区也说明了在执行过程 中,数据在集群中的物理分布。如果只有一个分区,即使拥有数千个执行器,Spark 也只有一 个执行器在处理数据。类似地,如果有多个分区,但只有一个执行器,那么 Spark 仍然只有那 一个执行器在处理数据,就是因为只有一个计算资源单位。 值得注意的是,当使用 DataFrame 时,(大部分时候)你不需要人工手动操作分区,你只需指 定数据的高级转换操作,然后 Spark 决定此工作将如何在集群上执行。较低级别的 API(通过 RDD 接口)也是存在的
Spark 是一个分布式编程模型,用户可以在其中指定转换操作 (transformation)。多次转换操作后建立起指令的有向无环图。指令 图的执行过程作为一个作业(job)由一个动作操作(action)触发, 在执行过程中一个作业被分解为多个阶段(stage)和任务(task)在 集群上执行。转换操作和动作操作操纵的逻辑结构是 DataFrame 和 Dataset, 执 行 一 次 转 换操 作 会 都 会 创 建 一 个 新 的 DataFrame 或 Dataset,而动作操作则会触发计算,或者将 DataFrame 和 Dataset 转 换成本地语言类型。
Spark 有几个核心抽象:
Dataset,DataFrame,SQL 表和弹性分布式数据集 (RDD)。这些不同的抽象都表示分布式数据集合,其中最简单和最有效的 是 DataFrame,它支持所有语言。
血统(lineage,即 Spark 是如何执行查询操作的)
我们讨论了转换和动作,以及 Spark 如何惰性执行转换 操作的 DAG 图以优化 DataFrame 上的物理执行计划。我们还讨论了如何将数据组织到分区中, 并为处理更复杂的转换设定多个阶段。
一.spark宽窄依赖
动作算子并没有实际的输出,仅仅指定了一个抽象的转换。在我们调用一个动作操 作(我们将在后面详细介绍动作)之前,Spark 不会真的执行转换操作。转换操作是使用 Spark 表达业务逻辑的核心,有两类转换操作:第一类是那些指定窄依赖关系的转换操作,第二类是 那些指定宽依赖关系的转换操作。
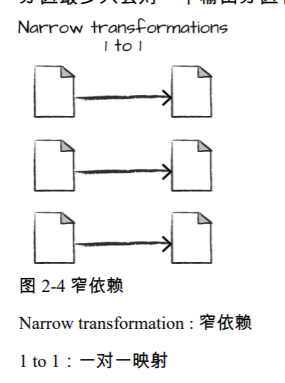
具有窄依赖关系(narrow dependency)的转换操作(我们称之为窄转换)是每个输入分区仅决 定一个输出分区的转换。
具有宽依赖关系(wide dependency)的转换(或宽转换)是每个输入分区决定了多个输出分区。这种宽依赖关系的转换经常被叫做洗牌(shuffle)操作,它会在整个集群中执行互相交换 分区数据的功能。 如果是窄转换,Spark 将自动执行流水线处理(pipelining),这意味着如果 我们在 DataFrame 上指定了多个过滤操作,它们将全部在内存中执行。而属于宽转换的 shuffle 操作不是这样,当我们执行 shuffle 操作时,Spark 将结果写入磁盘。图 2-5 中说明了宽转换操 作。

特点:
| 数据操作方式 | 输出/输入 | |||
|---|---|---|---|---|
| 窄依赖 | 在内存中计算 | 一对一 | ||
| 宽依赖 | 需要将结果写入磁盘,从磁盘读取计算 | 多对一 |
例子:
你可以通过名为 SparkSession 的驱动器来控制 Spark 应用程序,你需 要创建一个 SparkSession 实例来在群集中执行用户定义的操作,每一个 Spark 应用程序都需要 一个 SparkSession 与之对应。
1.创建一组固定范围的数字,就像电子表格的一个命名列一样:
val myRange = spark.range(1000).toDF("number")
刚刚已经运行了第一个 Spark 代码!我们创建了一个 DataFrame,其中一列包含 1000 行,值为 0 到 999。这些数字即是一个分布式集合,在集群上运行此命令时,这个集合的每一 部分都会被分配到不同的执行器上。这个集合就是一个 Spark DataFrame。
2.转换操作查找当前 DataFrame 中的所有偶数:(没有实际的输出)
val divisBy2 = myRange.where("number % 2 = 0")
where 语句指定了一个窄依赖关系,其中一个 分区最多只会对一个输出分区有影响,如图 2-4 所示。
dataFrames
宽依赖方法:
stor() 排序
窄依赖方法:
where() 过滤
read() 读入
二.惰性评估
惰性评估(lazy evaluation)的意思就是等到绝对需要时才执行计算。在 Spark 中,当用户表达 一些对数据的操作时,不是立即修改数据,而是建立一个作用到原始数据的转换计划。Spark 会首先将这个计划编译为可以在集群中高效运行的流水线式的物理执行计划,然后等待,直到 最后时刻才开始执行代码。这会带来很多好处,因为 Spark 可以优化整个从输入端到输出端的 数据流。
三.DataFrame Dataset
相同点:
存储的格式都是分布式数据集合,行和列相同类似于数据库表的格式。
异同点:
DataFrame 是一个分布式的类型为 Row 的对象集合,它可以 存储多种类型的表格数据
Dataset 是 Spark 结构化 API 的类型安全版本,用于在 Java 和 Scala 中编写静态类型的代码。
四.spark工具集介绍

最简单的分组是通过在 select 语句中执行聚合来汇总整个 DataFrame
“group by”指定一个或多个 key 也可以指定一个或多个聚合函数,来对包含 value 的列执行 转换操作
“window”指定一个或多个 key 也可以指定一个或多个聚合函数,来对包含 value 的列执行转 换操作。但是,输入到该函数的行与当前行有某种联系
" grouping set"可用于在多个不同级别进行聚合。grouping set 是 SQL 中的一个保留字,而 在 DataFrame 中需要使用 rollup 和 cube
·“rollup”指定一个或多个 key,也可以指定一个或多个聚合函数,来对包含 value 的列执行 转换操作,并会针对指定的多个 key 进行分级分组汇总。
·“cube”指定一个或多个 key,也可以指定一个或多个聚合函数,来对包含 value 的列执行转 换操作,并会针对指定的多个 key 进行全组合分组汇总。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









