







最近两天自己写了一个网络爬虫的例子。
python版本: 3.5
IDE : pycharm 5.0.4
要用到的包可以用pycharm下载:
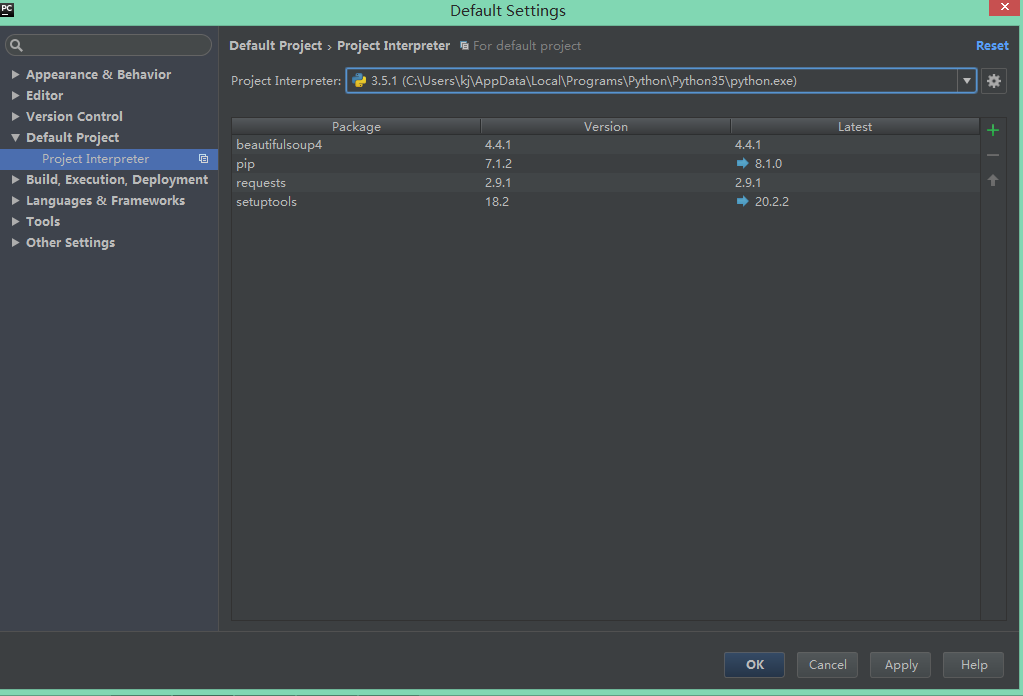
File->Default Settings->Default Project->Project Interpreter
选择python版本并点右边的加号安装想要的包
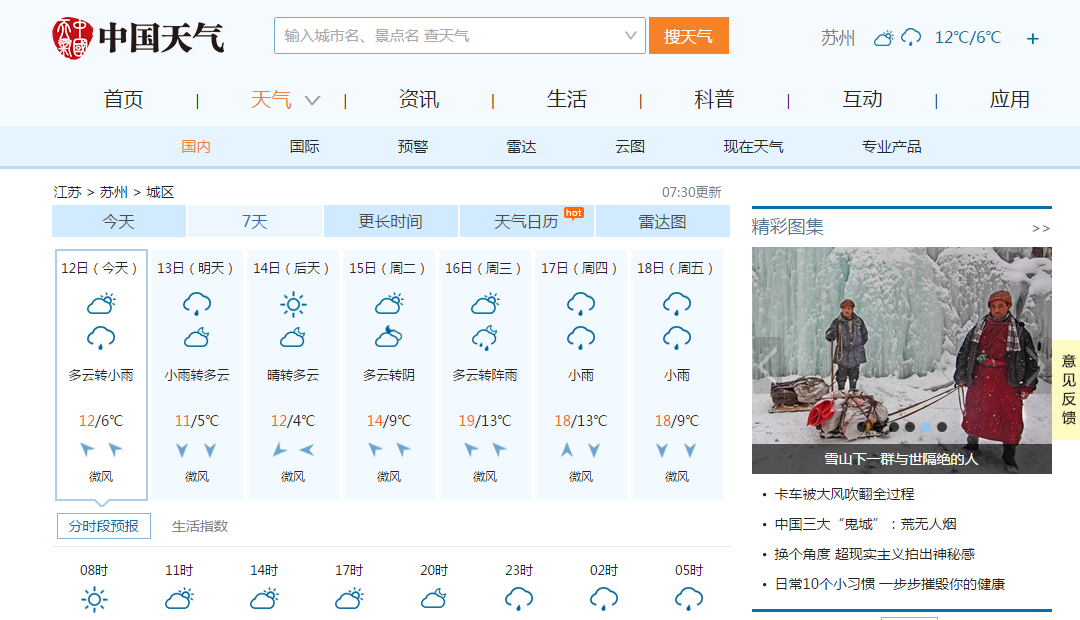
我选择的网站是中国天气网中的苏州天气,准备抓取最近7天的天气以及最高/最低气温
http://www.weather.com.cn/weather/101190401.shtml
程序开头我们添加:
# coding : UTF-8
这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文。
要引用的包:requests:用来抓取网页的html源代码
csv:将数据写入到csv文件中
random:取随机数
time:时间相关操作
socket和http.client 在这里只用于异常处理
BeautifulSoup:用来代替正则式取源码中相应标签中的内容
urllib.request:另一种抓取网页的html源代码的方法,但是没requests方便(我一开始用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7676
7676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









